
abstract
多模态情感分析(MSA)旨在通过文本、视觉和声音线索识别情感类别。然而,在现实生活中,由于各种原因,可能会缺少一到两种模式。当文本情态缺失时,由于文本情态比视觉和听觉情态包含更多的语义信息,因此会出现明显的退化。
为此,我们提出了多模态重构和对齐网络(MRAN)来解决情态缺失问题,特别是缓解由于文本情态缺失而导致的衰退。我们首先提出了多模态嵌入和缺失索引嵌入来指导缺失模态特征的重建。然后,将视觉和听觉特征投射到文本特征空间中,三种模态的特征都被学习到与其对应情感类别的词嵌入接近,使视觉和听觉特征与文本特征对齐。在这种以文本为中心的方式下,视觉和听觉形式受益于更具信息性的文本形式。从而提高了网络在不同情态缺失情况下的鲁棒性,特别是在文本情态缺失的情况下。
在两个多模态基准IEMOCAP和CMU-MOSEI上进行的实验结果表明,我们的方法优于基线方法,在不同的模态缺失条件下获得了更好的结果。
intro
随着社交媒体的普及,多模态情感分析(MSA)引起了越来越多的关注[9,21,24]。近年来,研究者通过探索多种模式之间的融合策略,在MSA任务中取得了很大的成功[9,14,21,24]。然而,在现实场景中,由于硬件条件不佳或网络问题,例如传感器故障或与网络断开,可能会导致部分输入模态丢失。这使得传统的MSA方法不适用,因为它们大多数要求所有模态都可用。
解决模态缺失问题的方法主要有两组,第一组是基于数据输入的方法[3,20],其目的是通过矩阵补全或生成网络来恢复缺失的模态。另一类是基于联合表示的方法,它学习不完整输入模态的融合表示,是近年来研究的首选方法。
例如,MMIN[27]提出了一种缺失模态想象网络,该网络通过级联残差自编码器和循环一致性学习,通过跨模态想象学习鲁棒联合多模态表示。它通过训练不完全模态输入来模拟模态缺失情况,从而使其在测试阶段成为MMP的鲁棒模型。
此外,在CTFN[19]中,将三对Transformer编码器作为翻译器,在任意两个模态之间进行双向转换,在测试时,将现有源模态生成缺失模态作为目标模态,并利用Transformer层的潜在向量作为联合表示进行最终预测。该方法对三种模态的权值进行平等处理,对不同模态进行并行处理。
例如,在MMIN中,三种模态的输入顺序连接形成融合特征,然后馈送到网络中。然而,也有研究[17,21,22]表明情态之间存在不平衡,而文本情态发挥着最重要的作用,因为它比音频或视觉情态包含更多的语义信息。可以解释的是,情感倾向对文本情态的影响更为明显,因为句子中的某些词(如fun, hate等)往往是情感分析的关键因素。相反,音频信号或视觉帧有时可能是冗余或隐含的。但这一特性并没有体现在上述方法的设计中。因此,需要一个专门设计的网络,利用文本形态的优势出现。
在本文中,我们提出了多模态重构和对齐网络(MRAN)来解决模态缺失问题。
为了增强缺失模态的重建过程,我们将三个模态的特征进行拼接编码,得到多模态嵌入,并将模态缺失索引编码为先验知识,称为缺失索引嵌入。
此外,设计了以文本为中心的多模态对齐模块,将文本特征空间中的三个模态特征进行分组,将三个模态特征拉向其对应情感类别的词嵌入,使视觉和听觉特征与文本特征对齐。
最后,计算三种模态特征与所有情感类别词嵌入之间的加权相似度,进行最终预测。通过以文本为中心的对齐过程,视觉和声学特征受益于文本特征空间中文本模态语义信息的丰富,从而提高了在测试期间只有非文本模态可用时模型的鲁棒性
简而言之,我们的贡献如下:
(1)我们提出了一个新的网络,利用文本情态的优势来增加多情态分析中缺失情态问题(MMP)的鲁棒性。
(2)我们提出了多模态嵌入和缺失索引嵌入来辅助缺失模态特征的重建,前者在模态重建时提供了多模态数据的整体视图,后者使重建过程更有针对性地针对缺失的模态。
(3)在多模态情感分析基准IEMOCAP和CMU-MOSEI上进行了实验。我们的方法在大多数情态缺失情况下优于基线方法,在文本情态缺失情况下显著优于基线方法
related work
多模态情感分析
目前,多模态情感分析的研究主要集中在多源模态的联合表征学习上。
为了捕捉跨模态的相互作用,TFN[24]提出了张量融合,通过笛卡尔积来模拟单峰、双峰和三峰相互作用。MulT[21]将transformer扩展到MSA域,通过直接关注其他模态中的低级特征来融合多模态信息。同样,cLSTM-MMA[14]提出了一种混合融合模型,其特征是模态之间的平行定向关注,而不是简单的串联。此外,MISA[9]学习了跨模态的模态不变和模态特定特征,以获得多模态数据的整体视图,从而有助于融合过程。然而,MSA的方法通常是在假设所有模态都可用的情况下进行的,这对缺少模态的情况很敏感。
缺失模态问题
解决缺失模态问题的方法主要分为两条线[13,26],数据输入和学习联合多模态表示。
基于数据输入的方法旨在恢复丢失的部分数据。例如,SoftImputeALS[8]侧重于在假设已完成的矩阵具有低秩结构的基础上,对部分观测矩阵的缺失项进行输入。CRA[20]提出了一种级联残差自编码器框架来拟合不完整数据和完整数据之间的差异。
另一项工作旨在从不完全多模态输入中学习鲁棒联合多模态表示。TFR-Net[23]采用了一种跨模态变压器模块,提取包含模态间互补性的有效联合表示。MCTN[16]提出了一种基于翻译的seq2seq模型,在源模态和多个目标模态之间进行循环翻译,使源模态编码器能够同时从源模态和目标模态捕获信息。此外,MMIN[27]利用级联残差自编码器基于可用模态来想象缺失模态,并将隐藏向量的连接视为联合表示。CTFN[19]提出借助Transformer编码器在模态对之间进行转换,并从Transformer的隐藏输出中获得联合表示。此外,TATE[26]利用输入标签编码来帮助缺失模态的恢复,并学习了一个鲁棒模型。
然而,上述方法很少探讨语篇情态之间的不平衡性,忽视了语篇情态的首要地位,从而可能导致次优解。
方法
问题定义
让我们定义包含音频、文本和视觉模态的帧级原始多模态数据集为。其中,|N|为样本总数,a, t, v分别为audio, text, vision模态,s∈{a, v, t}表示模态s在帧级原始数据集中的序列长度和特征维数,yi∈{0,1,…, |C|−1}为样本i的真实情感类别,|C|为数据集的情感类别号。
为了模拟真实场景中的缺失模态设置,我们按照前人[27]的做法,在原始全模态多模态数据集D的基础上,手工构建一个新的缺失版本数据集,记为Dmiss。
具体来说,给出一个示例在D上,我们可以扩展它六个可能的缺失模式
,一旦模态表示失踪,其对应的帧级顺序输入将被0个向量掩盖。例如,如果缺少文本模态,则文本输入为
。新的缺失版本数据集可以表示为
。我们的任务是在
中给出一个数据样本来预测情绪类别。
特征提取模块
我们使用长短期记忆[10](LSTM)网络和TextCNN[12]从帧级多模态输入中提取话语级特征,如图1所示。LSTM隐藏状态的最大池化被用作最终的话语级特征。提取的特征记为
,其中ds为不同模态的话语级特征维数。
特征重构模块
特征重构模块的目的有两个方面,一是对缺失的情态特征进行重构,二是对已有的情态语义信息进行增强。具体模态s的重构特征描述如下:
Q:fs,fm,fi都是谁?
A:
是重建的特征,由原始特征fs,多模态嵌入fm和缺失指数嵌入fi的和构成
多模态嵌入fm是通过将所有模态的特征串联并通过多层感知机MLP处理得到的,它提供了一个融合的模态视图,有助于填补缺失的模态信息。
缺失指数嵌入fi是根据输入样本的缺失模态编码生成,指示哪些模态是缺失的,这有助于模型在特征重建时考虑到哪些信息是不可用的。
其中s∈a, t, v,利用均方误差(Mean Squared Error, MSE)损失计算重构特征与预训练特征之间的重构损失。
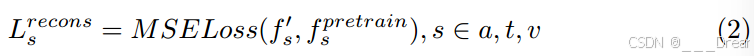
其中表示用于监督的预训练特征。它们是通过预先训练的特征提取器(与3.2节中描述的结构相同)获得的,这些特征提取器是用全模态多模态输入进行训练的。
注意,我们学习了两个特殊的嵌入来辅助重建过程,我们将在下面描述它们:
多模态嵌入fm
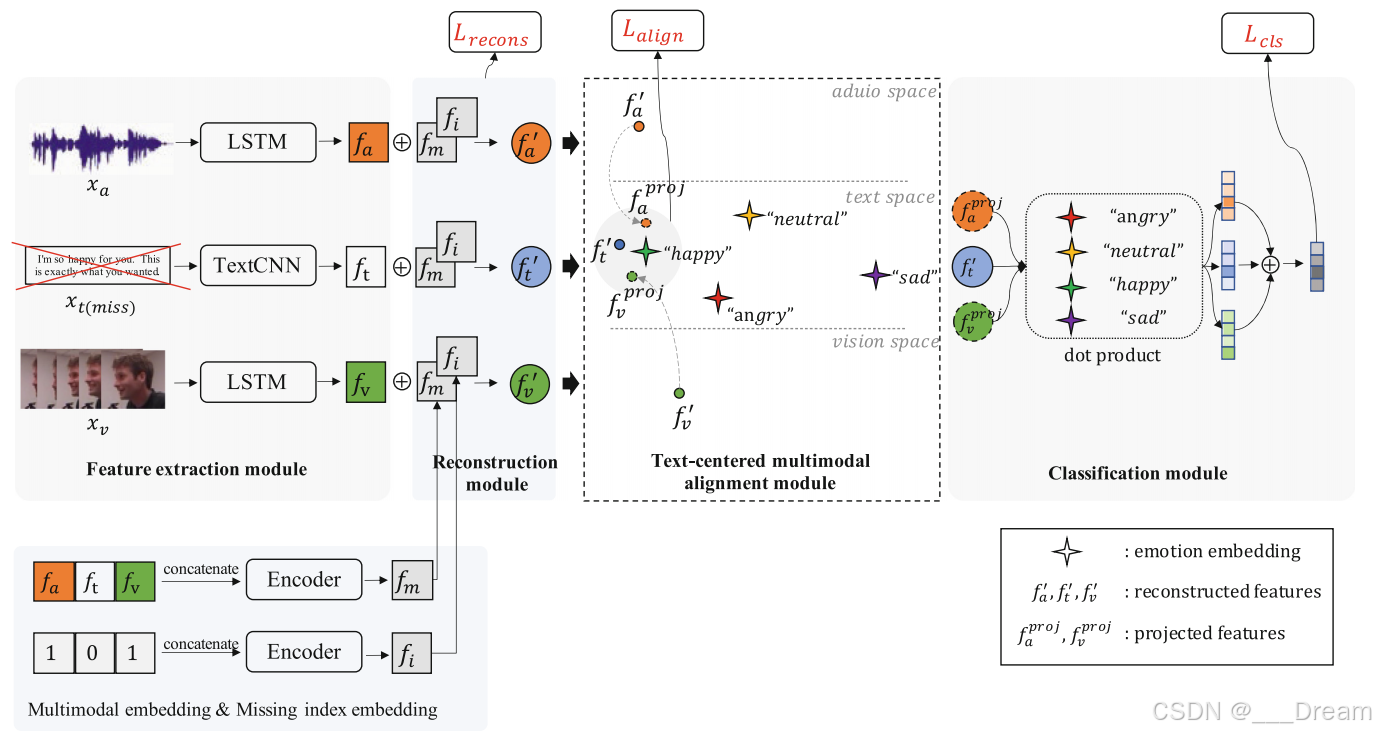
如图1所示,将提取的不同模态{fa, ft, fv}的话语级特征通过简单的全连接层进行连接编码,得到多模态融合表示fm:
然后分别在单模态特征中加入调频,辅助特征重构过程。所提出的多模态嵌入的直观之处在于,它聚合了来自所有输入模态的信息,从而使一个模态意识到其余的。这样,在重构某一模态特征时,就可以考虑到三模态的交互信息
缺失索引嵌入fi
输入样本的缺失索引是某缺失模式的数字编码,0表示缺失,1表示缺失。例如,如果样本的文本模态缺失,则缺失索引可记为“101”。我们还通过完全连接的层对其进行编码,以获得缺失索引嵌入fi:
其中,。将缺失的模式信息作为先验知识手工注入到模型中,使特征重构更有针对性。
以文本为中心的多模态对齐模块
如上所述,语篇语义分析方法通常平等对待不同的语态,但由于语篇语态具有丰富的语义,其贡献最大。我们可以通过将非语篇情态与语篇情态对齐来利用这一特性。我们首先将音频和视觉模态的特征维度投影为与文本模态相同的特征维度:
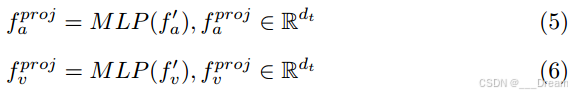
然后,按照[4]的做法,我们对情感类别进行编码(例如:“快乐”,“悲伤”,“中性”和“愤怒”(IEMOCAP数据集)使用预训练的GloVe[15]词嵌入。这些嵌入表示为情感嵌入E∈R|C|×dt,其中|C|表示数据集的情感类别号。
在训练阶段,情感嵌入E保持冻结状态,并通过以下约束将文本特征空间中的三种模态特征聚类为锚点:
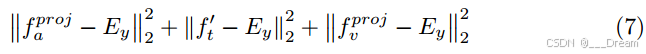
作为文本特征空间中情态特征与情感嵌入之间的距离。对于特定的输入样本,y∈{0,1,…, |C|−1}为基础真情感类别,
为其对应的基础真情感嵌入。
在训练阶段,三种模态的特征都被拉向其对应情感类别的词嵌入。通过这一过程,将弱语义的视觉和听觉特征定位到文本特征空间中的信息文本特征上。从而提高听觉和视觉模态的判别能力,即提高模型对文本模态缺失的鲁棒性。
Q:文本中心模块是怎么起作用的?
A:改模块主要用于处理多模态数据处理任务中的一个常见问题:不同模态的信息量和语义丰富度不均。在许多情况下,文本数据因其丰富的语义内容对于整体任务至关重要。该模块的设计目的是利用文本数据的这一优势,通过将其他模态的特征对齐到文本特征的维度,增强模型在处理语义信息时的能力,尤其是当文本模态缺失时。
首先,非文本模态的特征通过MLP被投影到与文本特征相同的特征维度,这一步骤使得所有模态的特征可以在相同的特征空间内进行比较和融合。
接着,进行了一个情绪嵌入,即根据预训练的GloVe词嵌入来编码不同的情绪类别,生成对应的情绪嵌入。这些情绪嵌入在训练阶段作为锚点,用于帮助聚集不同模态的特征。
在训练阶段,使用下面的公式来最小化每个模态特征和对应情绪嵌入之间的距离:
通过这种方式,该模块不仅对齐了来自不同来源的数据,还强化了模型处理缺失文本数据时的鲁棒性。当文本数据缺失时,模型可以依靠音频和视觉数据中的语义信息,这些信息通过与文本数据的对齐变得更加丰富和有意义。此外,通过减少模态之间的语义距离,该对齐策略还有助于提高音频和视觉模态的判别能力,使模型在多模态情境中更加有效。
分类模块
最后,我们通过计算每个模态特征与所有情感嵌入E的点积相似度的加权和来预测最终的情感类别概率分布p:
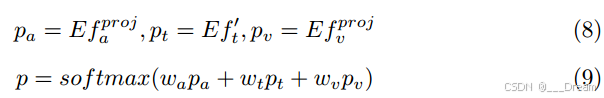
其中,wa, wt, wv∈R为不同模态的权重参数。
模型训练
总体训练目标可表示为:
其中λ1,λ2是损失权值。损失函数详细如下:
重建损失(Lrecons)
仅计算缺失模态的重构损失,通过掩模s∈{a, t, v}将损失函数项归零来实现:
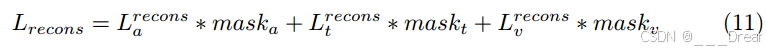
这里,如果输入样本中的模态s缺失,则mask为1,反之为0。
Q:mask干啥的?
A:
重建损失是用来优化模型在重建缺失模态数据时的性能。当处理多模态数据时,通常某些模态可能不完整或丢失。重建损失确保在这种情况下模型能有效地填补或重建缺失的模态特征。

对齐损失(Lalign)
我们计算模态特征与其相应的情感嵌入之间的L2距离作为对齐度量:
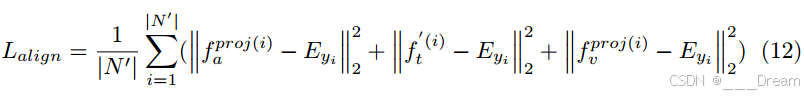
其中为数据集Dmiss的总样本数。Yi∈{0,1,…, |C|−1}为样本i的基础真情感类别,
为其对应的基础真情感嵌入。
分类损失(Lcls)
我们采用交叉熵损失H(p, q)作为分类损失:
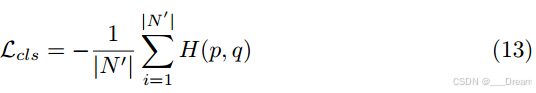
其中p为预测概率分布,q为one-hot标签的真值分布。
experiments
datasets
在这项工作中,我们在两个多模态情感分析数据集IEMOCAP和CMU-MOSEI上评估了我们的模型。
IEMOCAP[2]。交互式情绪二元动作捕捉(IEMOCAP)是一个动作多模态数据集,包含5个会话会话和10K视频,用于人类情绪识别。标注的标签是中性的、沮丧、愤怒、悲伤、快乐、兴奋、惊讶、恐惧、失望等等。根据[27]的建议,我们将这些类别分为4类(快乐、悲伤、愤怒和中性)。由于标签分布不平衡,我们在IEMOCAP数据集上采用了未加权平均召回率(UAR)和未加权准确率(ACC)。
CMU-MOSEI[25]。它由23454个来自YouTube的电影评论视频剪辑组成。每个视频片段都用-3到3的情感评分手工注释。我们报告了两类(阴性:[-3,0],阳性:(0,3])分类精度和F1分数在CMU-MOSEI数据集上。
data preprocess
我们按照前人[27]的指导对原始数据进行处理:对于IEMOCAP,使用配置为“IS13_Com parE”的OpenSMILE工具包[7]提取声帧级特征。使用预训练的BERT大模型[6]对词嵌入进行编码。首先对视频帧中的人脸区域进行检测,然后使用在面部表情识别+ (FER+)语料库[1]上预训练的DenseNet[11]对面部表情特征进行编码。a, t, v的原始特征维数分别为130,768,342。
对于CMU-MOSEI,使用COVAREP提取声学特征[5]。GloVe word嵌入用于对文本输入进行编码。使用Facet[18]提取面部表情特征。a, t, v的原始特征维分别为74,300,35。
实施细节
我们在模态缺失设置下进行实验,即给定多模态数据集D,我们首先构建新的缺失版本数据集Dmiss,如3.1节所述。在训练或测试阶段,可能会有一个或两个输入模态缺失,缺失的输入被零向量代替。
由于CMU-MOSEI数据集是作为二元分类标签设置进行处理的,因此我们使用单词“Negative”和“Positive”作为CMU-MOSEI数据集的情感类别,即我们在以文本为中心的多模态对齐模块中使用预训练的GloVe词嵌入对单词“Negative”和“Positive”进行编码。我们在验证集上选择最佳超参数,并在测试集上报告最终结果,我们重复实验五次,以获得IEMOCAP和CUM-MOSEI数据集的平均结果(表1)。
实验结果
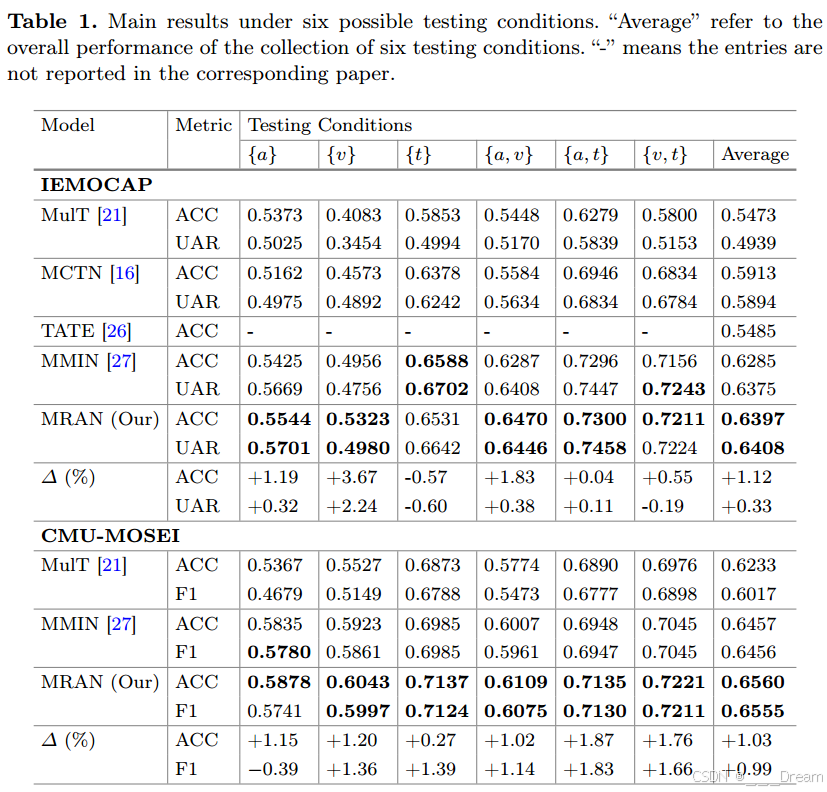
对于IEMOCAP数据集,6个可能缺失模态测试条件(列“average”)的平均准确率高于所有基线,证明了我们的方法的整体优势。对于每种缺失模态测试条件,与IEMOCAP数据集上的SOTA模型MMIN[27]相比,我们提出的模型在文本模态缺失(列{a}, {v}, {a, v})的情况下取得了显著的改进,这表明我们的模型可以更有效地抵抗最强大的文本模态缺失。对于其他可能的测试条件(列{t}, {a, t}, {v, t}),我们的方法也实现了竞争性或更高的性能。请注意,我们的模型在case {t}上表现不佳,这可以解释为在以文本为中心的多模态对齐模块的对齐过程中,弱模态(音频和视觉)特征和强模态(文本)特征都被强制接近其相应情感类别的词嵌入,这可能会对文本模态的语义属性产生负面影响。对于CMU-MOSEI数据集,我们提出的模型在每个可能的缺失模态测试条件下都优于基线方法,这表明我们的模型对其他数据集具有良好的泛化能力。
消融实验
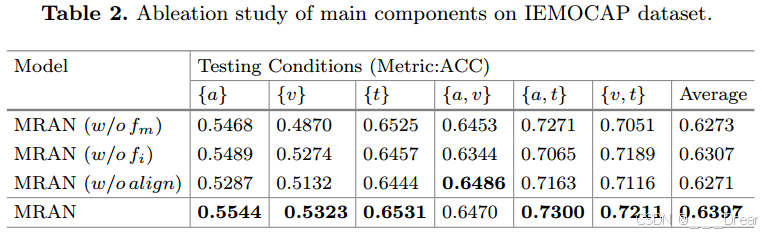
我们研究了我们提出的方法的主要成分的影响,消融结果如表2所示。
重构模块的效果
在重构模块中,我们提出了多模态嵌入和缺失索引嵌入来辅助缺失模态特征的重构。通过考虑多模态嵌入,任何缺失的模态都具有感知其他模态的能力,这将从多模态数据的整体角度改进特征重建过程。未经多模态嵌入的模型在表2中表示为,我们可以看到,与我们的基本模型相比,有明显的下降。此外,提出了缺失索引嵌入,利用输入的缺失模式这一被忽略的先验知识,没有缺失索引嵌入的模型记为
,结果表明缺失索引嵌入也作为模块的一部分做出了贡献。
文本为中心的多模态对齐模块的效果
我们通过移除该模块并将的串联输入到线性分类器中来构建一个新模型。这个新模型表示为w/o align。去掉该模块后,{a}、{v}下的模型性能明显下降,分别为-2.57%和-1.91%,说明通过在文本特征空间中对齐不同的模态特征,弱模态(音频和视觉)可以受益于强模态(文本)的分类能力。请注意,{a, v}条件下的性能出乎意料地更高,这可能是因为在对齐模块中引入的词嵌入在某些情况下可能会导致误导效果。
conclusion
本文提出了多模态对齐和重构网络(MARN)模型,该模型主要解决多模态情感分析中的缺失模态问题(MMP)。我们提出了多模态嵌入和缺失索引嵌入的概念,以帮助缺失模态的特征重建。为了利用文本模态的语义优先级,我们提出了一个以文本为中心的多模态对齐模块,该模块利用数据集情感类别的词嵌入来对齐文本特征空间中的不同模态特征。
我们在两个多模态基准IEMOCAP和CMU-MOSEI上比较了我们的方法,并在六种可能的缺失模态条件下进行了实验。实验结果表明,我们的模型在大多数缺失情态条件下优于基线方法,并且在最强大的文本情态缺失的情况下获得了显着的改进。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【MRAN】情感分析中情态缺失问题的多模态重构和对齐网络

发表评论 取消回复