项目背景 甲方提供一台三卡4080显卡 需要进行qwen2.5 7b Instruct模型进行微调。以下为整体设计。
要使用 LLaMA-Factory 对 Qwen2.5 7B Instruct模型 进行 LoRA(Low-Rank Adapters)微调,流程与之前提到的 Qwen2 7B Instruct 模型类似。LoRA 微调是一种高效的微调方法,通过低秩适配器层来调整预训练模型的权重,而不是全量训练整个模型。
环境准备
确保你已经安装了必要的依赖,包括 LLaMA-Factory、DeepSpeed 和 transformers 库。如果尚未安装,可以使用以下命令安装:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
如果使用量化 gptq 需要安装以下环境
pip install auto_gptq optimum
如果使用量化 awq 需要安装以下环境
pip install autoawq
获取 Qwen2.5 7B Instruct 模型 权重
确保你已经获取了 Qwen2.5 7B Instruct 模型 的预训练权重。如果没有,你可以从 Hugging Face 或其他平台上下载该模型,或者根据需要联系模型发布者获取相应的模型文件。这里采用魔搭社区下载qwen2.5 7b Instruct模型。
原模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')
int 8 量化模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct-GPTQ-Int8')
int 4 量化模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct-AWQ')
3配置 LoRA 微调
在 LLaMA-Factory 中,LoRA 微调通常需要对模型进行一些配置,以下是实现 LoRA 微调的关键步骤:
编辑llama factory训练参数
新建llama factory 训练配置文件
examples/train_lora/qwen2.5_7b_lora_sft.yaml
加载 Qwen2.5 7B Instruct 模型 和 数据集,并设置 LoRA 训练范围。
### model
model_name_or_path: Qwen/Qwen2.5-7B-Instruct-AWQ
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/qwen2.5-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
这段配置文件主要用于 LoRA 微调 Qwen2.5-7B-Instruct-AWQ 模型,并且进行了具体的参数设置。每个部分都涉及模型、方法、数据集、输出、训练、评估等配置。以下是对每个部分的详细解读:
模型配置 (model)
model_name_or_path: Qwen/Qwen2.5-7B-Instruct-AWQ
model_name_or_path:指定了要微调的预训练模型的名称或路径。在这里,它指向了 Qwen2.5-7B-Instruct-AWQ 模型。你可以通过指定这个模型的路径或者从 Hugging Face 之类的模型库中加载该模型。
方法配置 (method)
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
stage: sft:表示当前的训练阶段是 SFT(Supervised Fine-Tuning) 阶段,意味着模型将在特定的标注数据集上进行监督学习。do_train: true:表示进行训练。finetuning_type: lora:指定了微调的类型是 LoRA(Low-Rank Adapter),意味着通过低秩适配器层来进行微调,而不是全量训练整个模型。lora_target: all:表示在模型的所有层上应用 LoRA 微调。你也可以选择特定的层,如attention或ffn,但这里设置为all,意味着所有的层都会应用 LoRA。
数据集配置 (dataset)
dataset: identity,alpaca_en_demo
template: qwen
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataset: identity,alpaca_en_demo:指定了要使用的数据集,这里列出了两个数据集:identity和alpaca_en_demo。你需要确保这两个数据集已经准备好并且路径正确。identity可能是一个自定义数据集,alpaca_en_demo是一个英文数据集。template: qwen:指定了数据集的模板,这个模板通常用于数据预处理过程,它可能包括对文本的格式化或特殊的标注。cutoff_len: 2048:指定了最大输入长度(单位为token)。如果输入文本超过这个长度,它将会被截断。这个长度与模型的最大接受长度有关,通常需要根据具体模型的设置调整。max_samples: 1000:指定了使用的数据集样本的最大数量,这里设置为1000,意味着将只使用最多1000个样本进行训练。overwrite_cache: true:如果缓存目录存在,则覆盖缓存。这个选项通常用于确保每次训练时使用最新的数据。preprocessing_num_workers: 16:指定了数据预处理时使用的工作线程数,16个线程可以加速数据加载和预处理过程。
输出配置 (output)
output_dir: saves/qwen2-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
output_dir: saves/qwen2-7b/lora/sft:指定了训练过程中保存模型和日志的输出目录。在此路径下,将保存微调后的模型、检查点等文件。logging_steps: 10:每10步记录一次日志。save_steps: 500:每500步保存一次模型检查点。这样你可以在训练过程中定期保存模型的状态,避免意外中断时丢失训练进度。plot_loss: true:在训练过程中,启用损失值可视化(例如通过TensorBoard或其他工具)。这有助于监控训练过程中模型的表现。overwrite_output_dir: true:如果输出目录已存在,则覆盖它。确保训练过程中不会因为目录存在而出现错误。
训练配置 (train)
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
per_device_train_batch_size: 1:每个设备的训练批次大小设置为1。这通常与GPU的显存大小相关,如果显存较小,批次大小可以设置为1。gradient_accumulation_steps: 2:梯度累积的步数。如果批次大小设置为1,但需要更多的梯度累积,可以通过此设置实现。learning_rate: 1.0e-4:设置学习率为 0.0001,这是训练时调整权重的步长。num_train_epochs: 3.0:训练的总周期数,这里设置为3轮。通常需要根据训练集大小和收敛速度来调整这个值。lr_scheduler_type: cosine:学习率调度器类型,使用 cosine 调度策略,通常能在训练后期逐渐减小学习率。warmup_ratio: 0.1:学习率的预热比例,设置为 0.1 表示前10%的训练步骤中,学习率将逐步增加到初始值。bf16: true:启用 bfloat16 精度进行训练,以减少显存消耗并加速训练。这通常需要支持 bfloat16 的硬件(如TPU)。ddp_timeout: 180000000:设置 Distributed Data Parallel(DDP) 模式下的超时。这个值通常是为了防止分布式训练过程中发生超时错误。
评估配置 (eval)
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
val_size: 0.1:指定验证集的大小为训练数据的 10%,即从训练数据集中划分出10%作为验证集。per_device_eval_batch_size: 1:评估时每个设备的批次大小为1。eval_strategy: steps:评估策略设置为按步数评估,即每训练一定步数后进行评估。eval_steps: 500:每500步进行一次评估。
微调过程
配置好训练参数和数据集后,你可以开始微调模型:
llamafactory-cli train examples/train_lora/qwen2.5_7b_lora_sft.yaml
原生显存占用
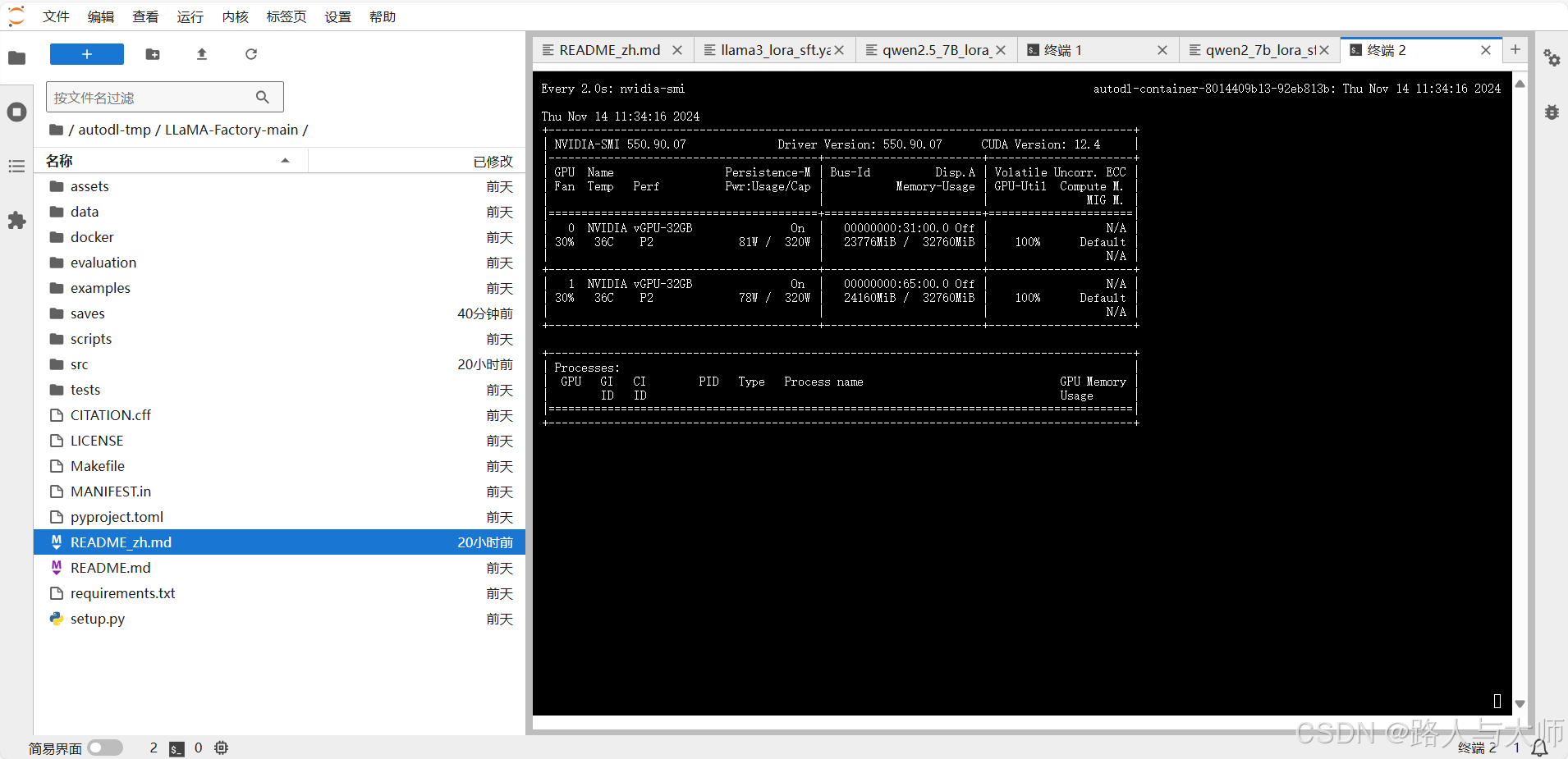
int 8 显存占用
| NVIDIA-SMI 550.90.07 Driver Version: 550.90.07 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA vGPU-32GB On | 00000000:31:00.0 Off | N/A |
| 30% 40C P2 168W / 320W | 16894MiB / 32760MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA vGPU-32GB On | 00000000:65:00.0 Off | N/A |
| 30% 40C P2 182W / 320W | 16892MiB / 32760MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
int 4 显存占用
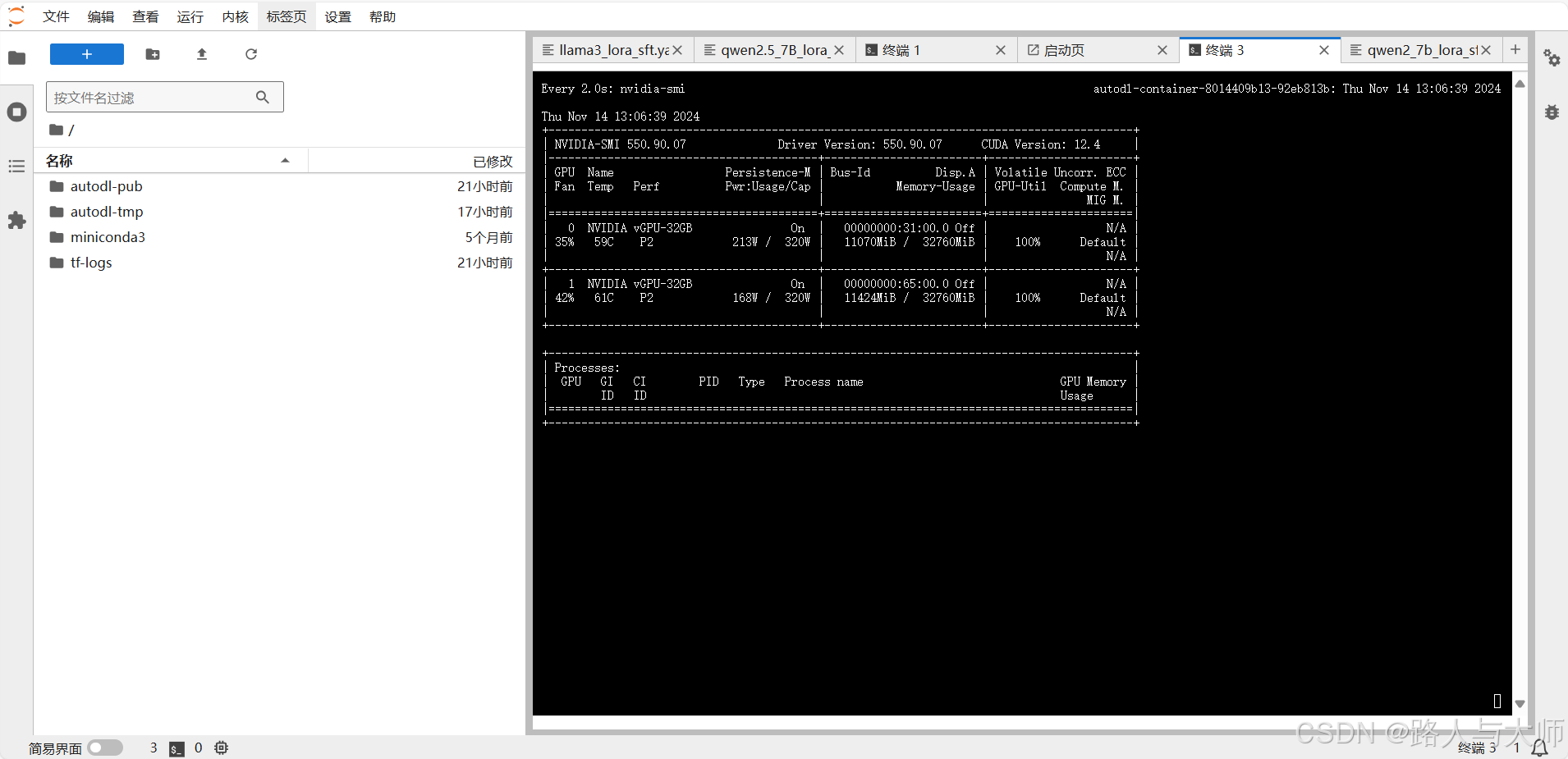
根据测试环境显存占用预估 int8 与 int4量化可以在3卡4080环境中进行qwen2.5 7B Instruct 模型的训练任务
小结
通过以上步骤,你可以使用 LoRA 方法对 Qwen2.5 7B Instruct 模型 进行高效的微调。使用 LoRA 可以显著减少训练过程中所需的计算资源和存储需求,同时依然能够获得出色的微调效果。确保在训练过程中使用合适的数据集,并根据实际需要调整 LoRA 的参数(如秩 r 和 lora_alpha)。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » llama factory lora 微调 qwen2.5 7B Instruct模型

发表评论 取消回复