contos7.9 部署3节点 hadoop3.4 高可用集群
- contos7.9 部署3节点 hadoop3.4 高可用集群
- 环境信息
- Hadoop与Zookeeper的版本对应关系
- 服务器角色分配
- 使用端口
- 服务器配置
- hadoop 安装环境配置
- 启动 hadoop 集群
- 关闭 hadoop 集群
- 补充不使用 works 文件的单独启动
- 补充不使用 works 文件的单独关闭
- 集群扩容
- 缩容集群
contos7.9 部署3节点 hadoop3.4 高可用集群
环境信息
| 服务器 | IP地址 | 配置 | 系统 | jdk | hadoop | zookeeper | 备注 |
|---|---|---|---|---|---|---|---|
| hadoop-0001 | 192.168.0.141 | 2C4G | CentOS 7.9 64bit | jdk-8u421-linux-x64.tar.gz | hadoop-3.4.0.tar.gz | apache-zookeeper-3.8.4-bin.tar.gz | hadoop和zookeeper均为写文档时的最高版本 |
| hadoop-0002 | 192.168.0.222 | 2C4G | CentOS 7.9 64bit | jdk-8u421-linux-x64.tar.gz | hadoop-3.4.0.tar.gz | apache-zookeeper-3.8.4-bin.tar.gz | hadoop和zookeeper均为写文档时的最高版本 |
| hadoop-0003 | 192.168.0.252 | 2C4G | CentOS 7.9 64bit | jdk-8u421-linux-x64.tar.gz | hadoop-3.4.0.tar.gz | apache-zookeeper-3.8.4-bin.tar.gz | hadoop和zookeeper均为写文档时的最高版本 |
Hadoop与Zookeeper的版本对应关系
| Hadoop版本 | Zookeeper版本 |
|---|---|
| 2.7.x | 3.4.6 |
| 2.8.x | 3.4.6 |
| 3.0.x | 3.5.1 |
| 3.1.x | 3.5.3 |
| 3.2.x | 3.5.6或3.4.14 |
| 3.3.x | 3.5.9或3.7.0 |
(注意:表格中的版本对应关系可能因具体发布时间和官方更新而有所变化,建议在实际使用时参考Apache官方文档或相关社区的最新信息。)
服务器角色分配
| 服务器角色 | hadoop-0001 | hadoop-0002 | hadoop-0003 |
|---|---|---|---|
| zookeeper | √ | √ | √ |
| NameNode | √ | √ | |
| ResourceManager | √ | √ | |
| DataNode | √ | √ | √ |
| NodeManager | √ | √ | √ |
| JournalNode | √ | √ | √ |
比较Hadoop基础集群规划,将Secondary NameNode改为NameNode,最终为双NameNode,双ResourceManager,三个zookeeper三个JournalNode。
JournalNode负责存储NameNode的编辑日志,这些日志记录了HDFS的所有更改。在NameNode故障时,新的NameNode需要这些日志来恢复文件系统的状态。
ZooKeeper和JournalNode在HDFS的HA配置中各自承担着不同的责任。ZooKeeper负责状态管理和故障转移,而JournalNode负责存储和复制编辑日志。这两者的结合使得HDFS能够在出现单点故障时实现快速且可靠的恢复,从而提高了整个集群的高可用性。
使用端口
| 服务进程 | 端口号 | 端口号用途 | 访问方式 | 使用者 |
|---|---|---|---|---|
| NameNode | 50070 | NameNode HTTP UI | 浏览器 | 管理员、客户端 |
| NameNode | 9870 | NameNode HTTPS UI(如果启用) | 浏览器 | 管理员、客户端 |
| DataNode | 50010 | DataNode RPC 服务 | 接口调用 | 内部通信 |
| DataNode | 50020 | DataNode HTTP UI | 浏览器 | 管理员、客户端 |
| DataNode | 50075 | DataNode IPC 服务 | 接口调用 | 内部通信 |
| DataNode | 9864 | DataNode HTTPS UI(如果启用) | 浏览器 | 管理员、客户端 |
| Secondary NameNode | 50090 | Secondary NameNode HTTP UI | 浏览器 | 管理员 |
| ResourceManager | 8088 | ResourceManager HTTP UI | 浏览器 | 管理员、客户端 |
| ResourceManager | 8090 | ResourceManager Scheduler UI | 浏览器 | 管理员 |
| ResourceManager | 9090 | ResourceManager HTTPS UI(如果启用) | 浏览器 | 管理员、客户端 |
| NodeManager | 8040 | NodeManager HTTP UI | 浏览器 | 管理员、客户端 |
| NodeManager | 8042 | NodeManager Localizer HTTP UI | 浏览器 | 管理员 |
| NodeManager | 9042 | NodeManager HTTPS UI(如果启用) | 浏览器 | 管理员、客户端 |
| HistoryServer | 19888 | HistoryServer HTTP UI | 浏览器 | 管理员、客户端 |
| ZooKeeper | 2181 | ZooKeeper 客户端端口 | 接口调用 | 内部通信、客户端 |
| ZooKeeper | 2888 | ZooKeeper 服务器间通信端口 | 接口调用 | 内部通信 |
| ZooKeeper | 3888 | ZooKeeper 选举端口 | 接口调用 | 内部通信 |
服务器配置
配置免密登录
root 对所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
[root@hadoop-0001 ~]# ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""
[root@hadoop-0001 ~]# for i in 192.168.0.141 192.168.0.222 192.168.0.252; do ssh-copy-id $i; done
服务器配置初始化 init_server.sh
所有节点执行 (hadoop-0001, hadoop-0002, hadoop-0003)
#!/bin/bash
# 清理旧的YUM源
rm -rf /etc/yum.repos.d/*.repo
# 下载华为云内部使用的YUM源文件
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.myhuaweicloud.com/repo/CentOS-Base-7.repo
# 清理YUM缓存并重新生成
yum clean all
yum makecache
# 安装常用软件包
yum install -y net-tools lftp rsync psmisc vim-enhanced tree vsftpd bash-completion createrepo lrzsz iproute
# 停止不需要的服务
systemctl stop postfix atd tuned
# 卸载不需要的软件包
yum remove -y postfix at audit tuned kexec-tools firewalld-*
# 修改cloud配置文件,注释掉manage_etc_hosts: localhost这一行
sed -i '/manage_etc_hosts: localhost/s/^/#/' /etc/cloud/cloud.cfg
# 检查SELinux状态,确保其为Disabled
SELINUX_STATUS=$(getenforce)
if [ "$SELINUX_STATUS" != "Disabled" ]; then
echo "SELinux is not disabled. Please disable SELinux before running this script."
exit 1
fi
# 检查防火墙状态,确保firewalld未启用
FIREWALLD_STATUS=$(systemctl is-active --quiet firewalld)
if [ "$FIREWALLD_STATUS" == "active" ]; then
echo "Firewalld is active. Please stop and disable firewalld before running this script."
exit 1
fi
# 重启服务器
echo "Rebooting the server..."
reboot
[root@hadoop-0001 ~]# vim init_server.sh
[root@hadoop-0001 ~]# for i in 192.168.0.141 192.168.0.222 192.168.0.252; do scp init_server.sh $i:/root; done
[root@hadoop-0001 ~]# bash init_server.sh
[root@hadoop-0002 ~]# bash init_server.sh
[root@hadoop-0003 ~]# bash init_server.sh
配置主机名映射
所有节点配置 hosts文件
(hadoop-0001, hadoop-0002, hadoop-0003)
[root@hadoop-0001 ~]# cat /etc/hosts
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
# 把127.0.0.1对应的 主机名这行删掉
192.168.0.141 hadoop-0001
192.168.0.222 hadoop-0002
192.168.0.252 hadoop-0003
[root@hadoop-0001 ~]# vim /etc/hosts
[root@hadoop-0001 ~]# for i in 192.168.0.141 192.168.0.222 192.168.0.252; do scp /etc/hosts $i:/etc/hosts; done
hadoop 安装环境配置
下载安装包
华为镜像站点:华为开源镜像站_软件开发服务_华为云
下载 jdk1.8
hadoop支持的jdk版本:Hadoop Java 版本 - Hadoop - Apache Software Foundation
支持的 Java 版本
Apache Hadoop 3.3 及更高版本支持 Java 8 和 Java 11(仅限运行时)
请使用 Java 8 编译 Hadoop。不支持使用 Java 11 编译 Hadoop: 哈多普-16795 - Java 11 编译支持 打开
Apache Hadoop 从 3.0.x 到 3.2.x 现在仅支持 Java 8
从 2.7.x 到 2.10.x 的 Apache Hadoop 同时支持 Java 7 和 8
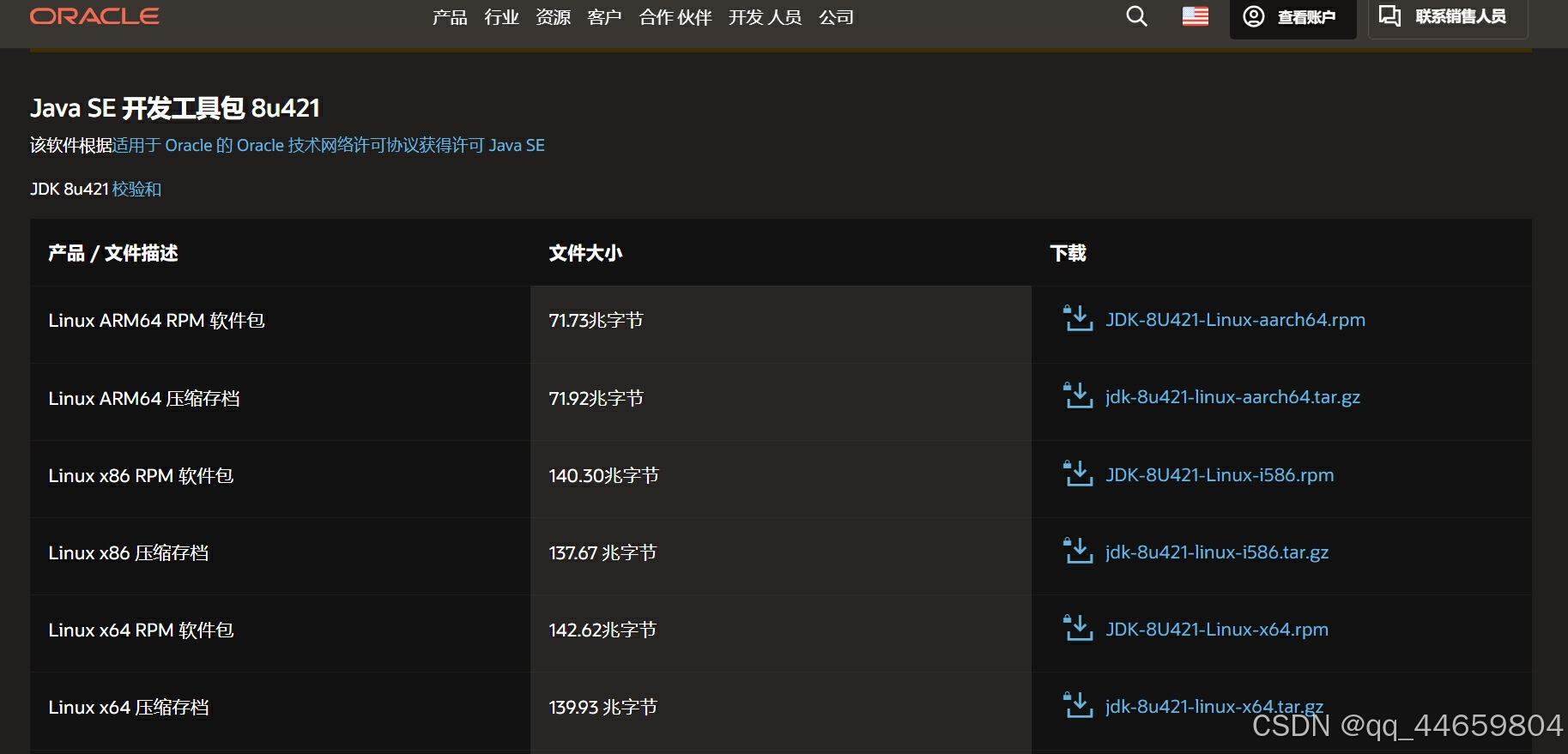
hadoop3.4
下载二进制包
https://dlcdn.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
| Linux x64 Compressed Archive | 139.93 MB | jdk-8u421-linux-x64.tar.gz |
|---|---|---|
| hadoop-3.4.0.tar.gz |
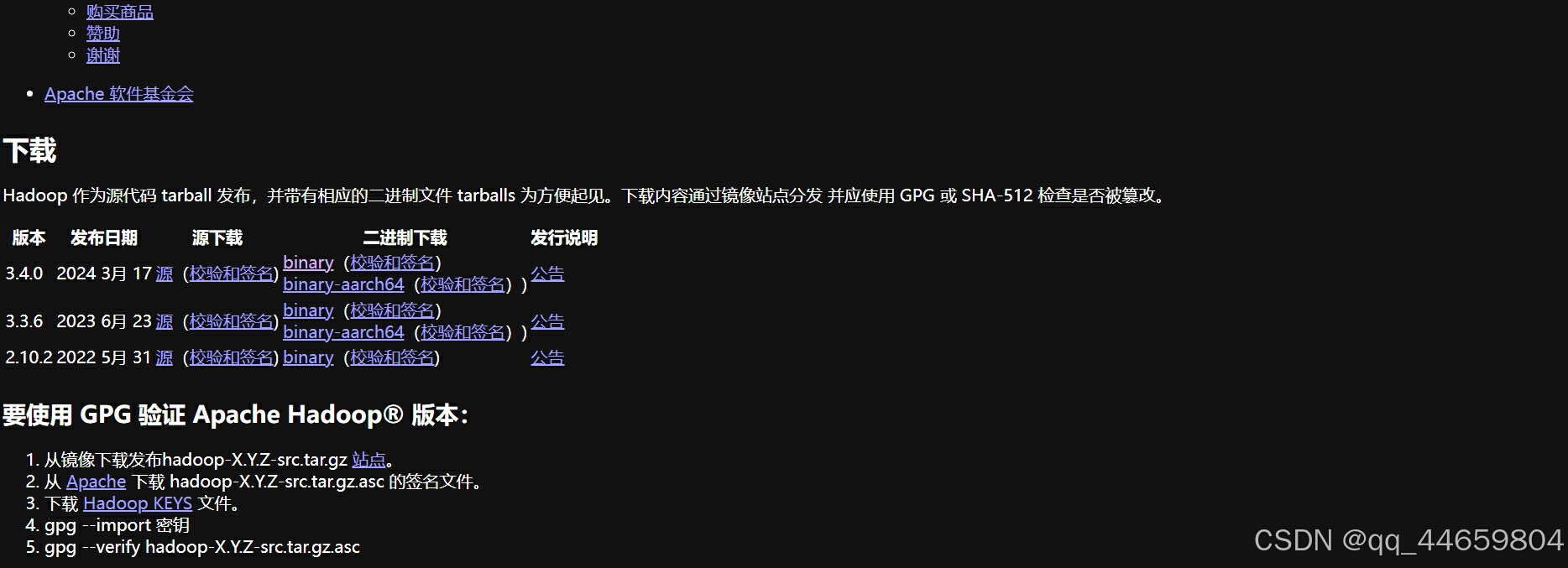
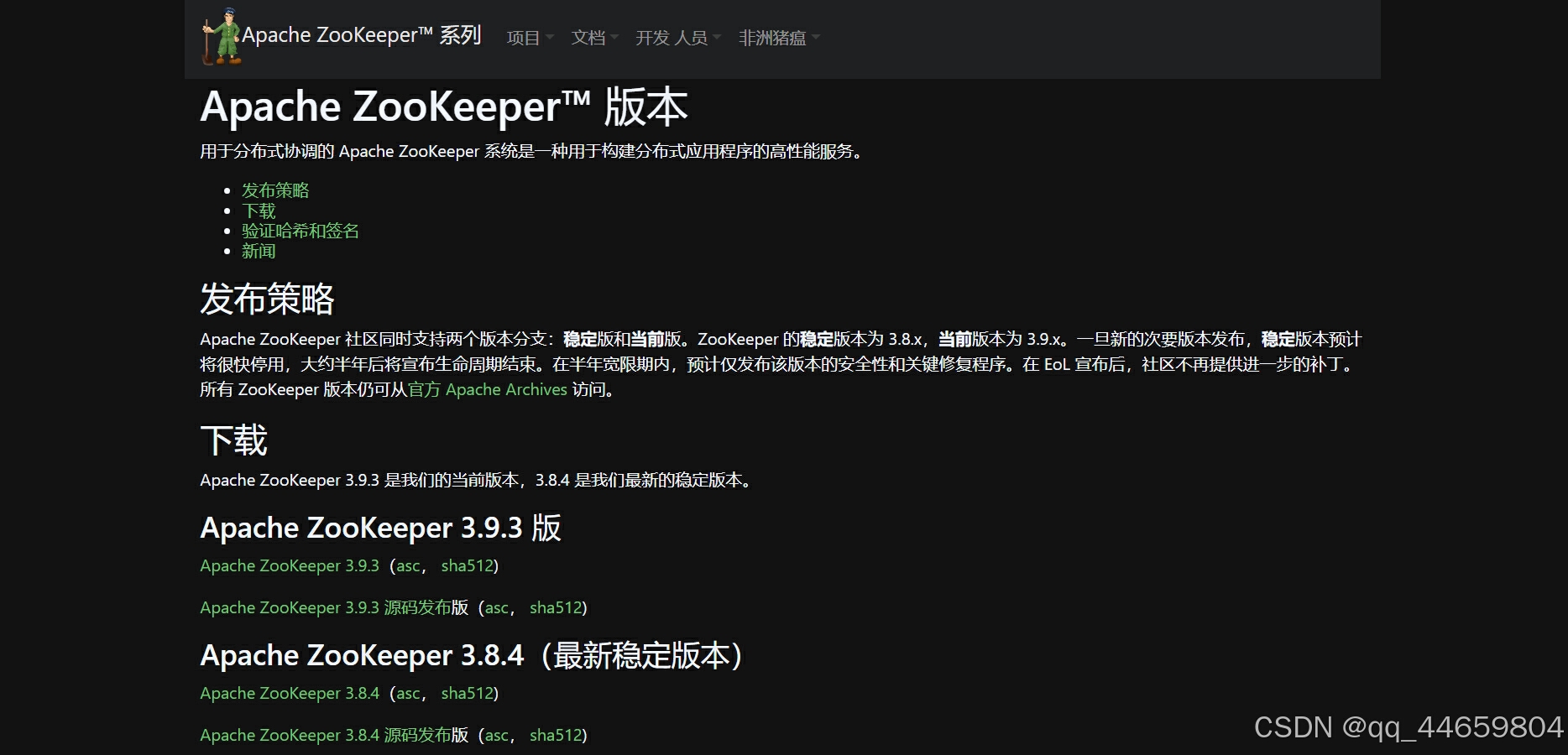
zookeeper3.8.4
https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
分发安装包
所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
[root@hadoop-0001 ~]# curl -o hadoop-3.4.0.tar.gz https://dlcdn.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
[root@hadoop-0001 ~]# curl -o apache-zookeeper-3.8.4-bin.tar.gz https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
[root@hadoop-0001 ~]# for i in 192.168.0.222 192.168.0.252; do scp hadoop-3.4.0.tar.gz jdk-8u421-linux-x64.tar.gz apache-zookeeper-3.8.4-bin.tar.gz install_jdk.sh root@$i:/root/; done
安装jdk1.8 install_jdk.sh
所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
#!/bin/bash
# 定义变量
JDK_TAR_GZ="$1"
PROFILE_BACKUP="/etc/profile.bak.$(date +%F-%H%M%S)"
JDK_INSTALL_DIR=""
INSTALLED_JDK_VERSION=""
# 错误处理逻辑
handle_error() {
echo "[ERROR] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1" >&2
exit 1
}
# 提示信息处理逻辑
handle_info() {
echo "[INFO] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1"
}
handle_warning() {
echo "[WARNING] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1"
}
# 检查是否传入了参数
if [[ -z "$JDK_TAR_GZ" ]]; then
handle_error "未传入JDK安装包的文件名作为参数。用法:$0 jdk-文件名.tar.gz"
fi
# 检查JDK安装包是否在当前目录
if [[ ! -f "$JDK_TAR_GZ" ]]; then
handle_error "未在当前目录找到JDK安装包 $JDK_TAR_GZ。"
fi
# 检查是否已经安装了JDK并获取版本
if command -v java &> /dev/null; then
INSTALLED_JDK_VERSION=$(java -version 2>&1 | head -n 1 | awk -F'[ "]+' '{print $3}')
INSTALLED_JDK_VERSION_MAJOR_MINOR=$(echo "$INSTALLED_JDK_VERSION" | cut -d. -f1-2)
handle_info "已安装的JDK版本信息如下:"
java -version
if [[ "$INSTALLED_JDK_VERSION_MAJOR_MINOR" != "1.8" ]]; then
handle_info "警告:已安装的JDK版本不是1.8,而是 $INSTALLED_JDK_VERSION。"
# 提供卸载非JDK 1.8版本的指导
if rpm -qa | grep -q "jdk|java"; then
handle_info "发现通过rpm安装的JDK,可以使用以下命令卸载:"
handle_info "rpm -e --nodeps $(rpm -qa | grep -E 'jdk|java')"
elif yum list installed | grep -q "jdk|java"; then
handle_info "发现通过yum安装的JDK,可以使用以下命令卸载:"
handle_info "yum remove $(yum list installed | grep -E 'jdk|java' | awk '{print $1}')"
else
handle_info "无法确定JDK的安装方式,可能需要手动卸载。请查找相关安装文档。"
fi
read -p "是否继续安装新版本的JDK?(y/n): " choice
if [[ "$choice" != "y" && "$choice" != "Y" ]]; then
handle_info "取消安装。"
exit 0
fi
fi
else
handle_info "未检测到JDK安装。"
fi
# 备份/etc/profile
handle_info "开始备份/etc/profile到$PROFILE_BACKUP"
cp /etc/profile "$PROFILE_BACKUP" || handle_error "Failed to create backup of /etc/profile."
handle_info "备份/etc/profile完成"
# 解压JDK安装包
handle_info "开始解压JDK安装包 $JDK_TAR_GZ 到 /usr/local/"
tar -xzf "$JDK_TAR_GZ" -C /usr/local/ || handle_error "Failed to extract $JDK_TAR_GZ file."
handle_info "解压JDK安装包完成"
# 获取解压后的JDK目录名(使用find命令提高健壮性)
JDK_DIRS=($(find /usr/local/ -maxdepth 1 -type d -name "jdk[0-9]*.[0-9]*.[0-9]*_[0-9]*" 2>/dev/null))
if [[ ${#JDK_DIRS[@]} -eq 0 ]]; then
handle_error "未找到解压后的JDK目录。"
elif [[ ${#JDK_DIRS[@]} -gt 1 ]]; then
handle_warning "警告:发现多个可能的JDK目录,选择第一个(${JDK_DIRS[0]}):"
for dir in "${JDK_DIRS[@]}"; do
handle_warning " $dir"
done
fi
JDK_INSTALL_DIR="${JDK_DIRS[0]}"
# 将环境变量写入/etc/profile
handle_info "开始将环境变量写入/etc/profile"
{
echo ""
echo "export JAVA_HOME=$JDK_INSTALL_DIR"
echo "export PATH=\$JAVA_HOME/bin:\$PATH"
} >> /etc/profile
handle_info "环境变量写入/etc/profile完成"
# 为了使更改立即生效,对当前会话加载新的环境变量(对后续登录用户无效)
handle_info "/etc/profile 是在用户登录时由系统读取的,因此任何对 /etc/profile 的更改都需要用户重新登录或手动重新加载(如使用 source /etc/profile)才能生效。"
source /etc/profile || handle_error "Failed to source /etc/profile."
# 验证JDK安装是否成功
if java -version 2>&1; then
handle_info "JDK安装成功,版本信息如下:"
java -version
handle_info "安装和配置已完成。环境变量已写入/etc/profile。"
handle_info "对于当前用户,为了使更改立即生效,请执行'source /etc/profile'。"
handle_info "对于后续登录的用户,新的环境变量将在他们登录时自动生效。"
else
handle_error "JDK安装验证失败。请检查JDK是否正确安装以及环境变量设置是否正确。"
fi
[root@hadoop-0001 ~]# bash install_jdk.sh jdk-8u421-linux-x64.tar.gz
[root@hadoop-0002 ~]# bash install_jdk.sh jdk-8u421-linux-x64.tar.gz
[root@hadoop-0003 ~]# bash install_jdk.sh jdk-8u421-linux-x64.tar.gz
# 退出再登陆,加载环境变量,也可以执行source /etc/profile使变量在当前会话生效
安装 zookeeper-3.8.4
所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
部署zookeeper-3.8.4 运行环境 env_zookeeper_intall.sh
#!/bin/bash
# 错误处理逻辑
handle_error() {
echo "[ERROR] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1" >&2
exit 1
}
# 提示信息处理逻辑
handle_info() {
echo "[INFO] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1"
}
# 检查并获取 zookeeper tar.gz 文件参数
check_zookeeper_tar_gz() {
local ZOOKEEPER_TAR_GZ="$1"
if [ -z "$ZOOKEEPER_TAR_GZ" ]; then
handle_error "No zookeeper tar.gz file provided!"
elif [ ! -f "$ZOOKEEPER_TAR_GZ" ]; then
handle_error "$ZOOKEEPER_TAR_GZ file not found!"
fi
}
# 创建必要的目录
create_directories() {
mkdir -p /data/zookeeper/{zookeeper_soft,zookeeper_data}
for dir in /data/zookeeper/{zookeeper_soft,zookeeper_data}; do
handle_info "Created directory: $dir"
done
}
# 解压 zookeeper tar.gz 文件并获取解压后的目录名
extract_zookeeper_and_get_basename() {
local ZOOKEEPER_TAR_GZ="$1"
tar -xf "$ZOOKEEPER_TAR_GZ" -C /data/zookeeper/zookeeper_soft/ || handle_error "Failed to extract $ZOOKEEPER_TAR_GZ file."
# 假设解压后的目录名格式为 apache-zookeeper-<version>-bin,获取该目录名
local ZOOKEEPER_DIR_FULLPATH=$(ls -d /data/zookeeper/zookeeper_soft/apache-zookeeper-* | head -n 1)
handle_info "$ZOOKEEPER_TAR_GZ extracted successfully to $ZOOKEEPER_DIR_FULLPATH"
}
# 更新 /etc/profile
update_profile() {
local BACKUP_FILE="/etc/profile.bak.$(date +%F-%H%M%S)"
cp /etc/profile "$BACKUP_FILE" || handle_error "Failed to create backup of /etc/profile."
cat << EOF >> /etc/profile
export ZOOKEEPER_HOME=$(ls -d /data/zookeeper/zookeeper_soft/apache-zookeeper-* | head -n 1)
export PATH=\$PATH:\$ZOOKEEPER_HOME/bin
EOF
source /etc/profile || handle_error "Failed to source /etc/profile."
if [ -z "${ZOOKEEPER_HOME-}" ]; then
handle_error "ZOOKEEPER_HOME environment variable not set!"
fi
handle_info "ZooKeeper environment variables have been set."
}
# 配置 zoo.cfg
zoo_config() {
local CONF_DIR="$(ls -d /data/zookeeper/zookeeper_soft/apache-zookeeper-* | head -n 1)/conf" # 假设 conf 目录在解压后的根目录下
# 检查 conf 目录是否存在
if [[ ! -d "$CONF_DIR" ]]; then
handle_error "Configuration directory $CONF_DIR not found!"
fi
cat << EOF > "$CONF_DIR/zoo.cfg"
tickTime=2000
dataDir=/data/zookeeper/zookeeper_data/
clientPort=2181
initLimit=5
syncLimit=2
server.1=hadoop-0001:2888:3888
server.2=hadoop-0002:2888:3888
server.3=hadoop-0003:2888:3888
EOF
handle_info "ZooKeeper configuration file $CONF_DIR/zoo.cfg created successfully."
}
# 主流程
check_zookeeper_tar_gz "$1"
create_directories
extract_zookeeper_and_get_basename "$1"
update_profile
zoo_config
handle_info "ZooKeeper environment setup completed successfully."
[root@hadoop-0001 ~]# vim env_zookeeper_intall.sh
[root@hadoop-0001 ~]# for i in 192.168.0.222 192.168.0.252; do scp env_zookeeper_intall.sh root@$i:/root/; done
[root@hadoop-0001 ~]# bash env_zookeeper_intall.sh apache-zookeeper-3.8.4-bin.tar.gz
[root@hadoop-0002 ~]# bash env_zookeeper_intall.sh apache-zookeeper-3.8.4-bin.tar.gz
[root@hadoop-0003 ~]# bash env_zookeeper_intall.sh apache-zookeeper-3.8.4-bin.tar.gz
# 退出再登陆,加载环境变量,也可以执行source /etc/profile使变量在当前会话生效
所有节点创建myid文件,分别写入1 2 3
(hadoop-0001, hadoop-0002, hadoop-0003)
myid
[root@hadoop-0001 ~]# echo "1" > /data/zookeeper/zookeeper_data/myid
[root@hadoop-0002 ~]# echo "2" > /data/zookeeper/zookeeper_data/myid
[root@hadoop-0003 ~]# echo "3" > /data/zookeeper/zookeeper_data/myid
所有节点启动 zookeeper
(hadoop-0001, hadoop-0002, hadoop-0003)
[root@hadoop-0001 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop-0002 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@hadoop-0003 ~]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看zookeeper状态
所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
# 日志正常
[root@hadoop-0001 ~]# less /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/logs/zookeeper-root-server-hadoop-0001.out
[root@hadoop-0002 ~]# less /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/logs/zookeeper-root-server-hadoop-0002.out
[root@hadoop-0003 ~]# less /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/logs/zookeeper-root-server-hadoop-0003.out
# 状态正常 1个 leader 2个 follower
[root@hadoop-0001 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@hadoop-0002 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@hadoop-0003 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/zookeeper_soft/apache-zookeeper-3.8.4-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
节点关闭的命令 zookeeper
不进行关闭
[root@hadoop-0001 ~]# zkServer.sh stop
[root@hadoop-0002 ~]# zkServer.sh stop
[root@hadoop-0003 ~]# zkServer.sh stop
安装 hadoop3.4
所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
部署 hadoop3.4 运行环境 env_hadoop_intall.sh
#!/bin/bash
# 错误处理逻辑
handle_error() {
echo "[ERROR] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1" >&2
exit 1
}
# 提示信息处理逻辑
handle_info() {
echo "[INFO] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1"
}
# 检查并获取 Hadoop tar.gz 文件参数
check_hadoop_tar_gz() {
local HADOOP_TAR_GZ="$1"
if [ -z "$HADOOP_TAR_GZ" ]; then
handle_error "No Hadoop tar.gz file provided!"
elif [ ! -f "$HADOOP_TAR_GZ" ]; then
handle_error "Hadoop tar.gz file not found!"
fi
}
# 创建必要的目录
create_directories() {
mkdir -p /data/hadoop/{hadoop_soft,hadoop_data/{tmp,hdfs/{namenode,datanode,journalnode}}}
# 输出创建的目录
for dir in /data/hadoop/{hadoop_soft,hadoop_data/{tmp,hdfs/{namenode,datanode,journalnode}}}; do
handle_info "Created directory: $dir"
done
handle_info "Directories created successfully."
}
# 解压 Hadoop tar.gz 文件
extract_hadoop() {
local HADOOP_TAR_GZ="$1"
tar -xf "$HADOOP_TAR_GZ" -C /data/hadoop/hadoop_soft/ || handle_error "Failed to extract $HADOOP_TAR_GZ file."
handle_info "Hadoop extracted successfully."
}
# 更新 /etc/profile
update_profile() {
local BACKUP_FILE="/etc/profile.bak.$(date +%F-%H%M%S)"
cp /etc/profile "$BACKUP_FILE" || handle_error "Failed to create backup of /etc/profile."
cat << EOF >> /etc/profile
export HADOOP_HOME=$(ls -d /data/hadoop/hadoop_soft/hadoop-* | head -n 1)
export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop
export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin
EOF
source /etc/profile || handle_error "Failed to source /etc/profile."
# 检查环境变量是否设置成功(可选)
if [ -z "${HADOOP_HOME-}" ]; then
handle_error "HADOOP_HOME environment variable not set!"
fi
handle_info "Hadoop environment variables have been set."
}
# 备份并更新 Hadoop 配置文件
backup_and_update_hadoop_config() {
cd $(ls -d /data/hadoop/hadoop_soft/hadoop-* | head -n 1)/etc/hadoop || handle_error "Failed to change directory to Hadoop config directory."
for file in core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml; do
cp "$file" "${file}.$(date +%F-%H%M%S).bak" || handle_error "Failed to backup $file."
done
cp hadoop-env.sh hadoop-env.sh.$(date +%F-%H%M%S).bak || handle_error "Failed to backup hadoop-env.sh."
cat << EOF >> hadoop-env.sh
export HDFS_NAMENODE_USER="hadoop"
export HDFS_DATANODE_USER="hadoop"
export HDFS_SECONDARYNAMENODE_USER="hadoop"
export JAVA_HOME=/usr/local/jdk1.8.0_421
EOF
# 检查 hadoop 用户是否存在
if ! id "hadoop" &>/dev/null; then
# 用户不存在,创建用户并设置密码
useradd hadoop || handle_error "Failed to create hadoop user."
# 注意:出于安全考虑,不建议在脚本中直接设置简单密码。
echo "hadoop:hadoop" | chpasswd || handle_error "Failed to set password for hadoop user."
handle_info "Hadoop user created and password set."
else
handle_info "Hadoop user already exists."
fi
# 更新 Hadoop 配置文件
handle_info "Hadoop configuration files have been updated."
}
# 警告信息处理逻辑
handle_warning() {
echo "[WARNING] - [$(date +'%Y-%m-%d %H:%M:%S')] - $1"
}
# 主流程
check_hadoop_tar_gz "$1"
create_directories
extract_hadoop "$1"
update_profile
backup_and_update_hadoop_config
handle_info "Hadoop environment setup completed successfully."
[root@hadoop-0001 ~]# vim env_hadoop_intall.sh
[root@hadoop-0001 ~]# for i in 192.168.0.222 192.168.0.252; do scp env_hadoop_intall.sh root@$i:/root/; done
[root@hadoop-0001 ~]# bash env_hadoop_intall.sh hadoop-3.4.0.tar.gz
[root@hadoop-0002 ~]# bash env_hadoop_intall.sh hadoop-3.4.0.tar.gz
[root@hadoop-0003 ~]# bash env_hadoop_intall.sh hadoop-3.4.0.tar.gz
# 退出再登陆,加载环境变量,也可以执行source /etc/profile使变量在当前会话生效
配置 Hadoop3.4 核心文件
在所有节点上配置 core-site.xml 、 hdfs-site.xml、 yarn-site.xml、 mapred-site.xml
core-site.xml
所有节点上配置 (hadoop-0001, hadoop-0002, hadoop-0003)
文件包含了集群使用的核心配置,包括文件系统的默认设置和 I/O 缓冲区大小。
<?xml version="1.0" encoding="UTF-8"?>
<!-- 引入用于格式化输出的XSL样式表(可选) -->
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--
指定Hadoop文件系统的默认URI。
这是HDFS(Hadoop分布式文件系统)的逻辑名称,通常指向NameNode。
在HDFS高可用(HA)配置中,这个URI应该指向NameNode的集群。组成集群的配置写在 hdfs-site.xml
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value> <!-- 指定NameNode所在的集群名和端口号 即HDFS 集群的名称-->
</property>
<!--
设置Hadoop临时文件的存储目录。
这个目录用于存储Hadoop守护进程(如NameNode、DataNode等)的临时文件。
请确保这个目录在您的文件系统中存在,并且Hadoop进程有权限写入。
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/hadoop_data/tmp</value> <!-- 临时文件存储的本地目录 -->
</property>
<!--
配置ZooKeeper集群的地址。
在Hadoop的高可用配置中,ZooKeeper用于存储配置信息、集群状态和协调NameNode的故障转移。
请列出所有ZooKeeper节点的地址,每个节点用逗号分隔。
-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-0001:2181,hadoop-0002:2181,hadoop-0003:2181</value> <!-- ZooKeeper节点地址 -->
</property>
<!--
设置文件I/O操作的缓冲区大小。
这个值决定了Hadoop在进行文件读写操作时使用的内存缓冲区大小。
较大的缓冲区可以提高性能,但也会增加内存使用。
默认值可能因Hadoop版本而异,这里设置为4096字节(4KB)。
-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value> <!-- 以字节为单位,根据需要调整 -->
</property>
<!--
(可选)其他Hadoop核心配置属性
根据您的需求和环境,您可能还需要添加其他配置属性。
例如,您可以配置网络拓扑脚本、垃圾回收选项、Java堆大小等。
-->
</configuration>
[root@hadoop-0001 hadoop]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0001 hadoop]# vim core-site.xml
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp core-site.xml root@$i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop; done
hdfs-site.xml
所有节点,但是NameNode节点 和 DataNode 节点有区别
文件包含了 HDFS 的特定配置,包括 NameNode,DataNode,journalnode的存储目录以及数据复制的策略。
在namenode节点上配置(hadoop-0001, hadoop-0002):
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HDFS 基本配置 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value> <!-- HDFS 集群的名称 -->
</property>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 每个文件块在HDFS中的副本数 -->
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value> <!-- 列出集群中所有 NameNode 的名称或 ID -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop-0001:8020</value> <!-- nn1 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop-0002:8020</value> <!-- nn2 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop-0001:50070</value> <!-- nn1 的 HTTP 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop-0002:50070</value> <!-- nn2 的 HTTP 地址 -->
</property>
<!-- NameNode 配置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/namenode</value> <!-- NameNode 存储元数据的本地目录 -->
</property>
<!-- DataNode 配置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/datanode</value> <!-- DataNode 存储数据块的本地目录 -->
</property>
<!-- JournalNode 配置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/journalnode</value> <!-- JournalNode 存储编辑日志的本地目录 -->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-0001:8485;hadoop-0002:8485;hadoop-0003:8485/mycluster</value>
<!-- 指定 JournalNode 集群的地址 -->
</property>
<!-- HDFS 高可用性配置 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value> <!-- 开启 NameNode 失败自动切换 -->
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- 配置 NameNode 失败后自动切换实现方式 -->
</property>
<!-- 故障转移配置 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value> <!-- 故障转移期间使用的屏蔽方法 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value> <!-- hadoop 用户的私钥文件 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value> <!-- SSH 连接超时时间,单位为毫秒 -->
</property>
<!-- 可选配置 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value> <!-- HDFS 垃圾回收站保留时间,单位为分钟 -->
</property>
<!-- 注意:客户端故障转移的配置不在服务器 hdfs-site.xml 中设置,
而是在客户端的 Hadoop 配置 core-site.xml 文件中设置 fs.defaultFS 为当前集群 hdfs://mycluster。
确保您的客户端配置也已正确设置以支持 HDFS 高可用性。 -->
</configuration>
注意:在 HA 配置中,dfs.namenode.rpc-address 可能会被自动故障转移框架管理,因此通常不需要在 hdfs-site.xml 中为每个 NameNode 明确设置。但是,在某些情况下,您可能需要为管理目的提供一个逻辑名称和端口。上面的配置假设您没有使用自动配置的 RPC 地址。
[root@hadoop-0001 hadoop]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0001 hadoop]# vim hdfs-site.xml
[root@hadoop-0001 hadoop]# scp hdfs-site.xml root@192.168.0.222:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop
在datanode节点上配置(hadoop-0003):
datanode 的文件比 namenode 的文件减掉了关于 namenode 的配置 dfs.namenode.name.dir
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HDFS 基本配置 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value> <!-- HDFS 集群的名称 -->
</property>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 每个文件块在HDFS中的副本数 -->
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value> <!-- 列出集群中所有 NameNode 的名称或 ID -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop-0001:8020</value> <!-- nn1 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop-0002:8020</value> <!-- nn2 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop-0001:50070</value> <!-- nn1 的 HTTP 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop-0002:50070</value> <!-- nn2 的 HTTP 地址 -->
</property>
<!-- DataNode 配置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/datanode</value> <!-- DataNode 存储数据块的本地目录 -->
</property>
<!-- JournalNode 配置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/journalnode</value> <!-- JournalNode 存储编辑日志的本地目录 -->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-0001:8485;hadoop-0002:8485;hadoop-0003:8485/mycluster</value>
<!-- 指定 JournalNode 集群的地址 -->
</property>
<!-- HDFS 高可用性配置 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value> <!-- 开启 NameNode 失败自动切换 -->
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- 配置 NameNode 失败后自动切换实现方式 -->
</property>
<!-- 故障转移配置 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value> <!-- 故障转移期间使用的屏蔽方法 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value> <!-- hadoop 用户的私钥文件 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value> <!-- SSH 连接超时时间,单位为毫秒 -->
</property>
<!-- 可选配置 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value> <!-- HDFS 垃圾回收站保留时间,单位为分钟 -->
</property>
<!-- 注意:客户端故障转移的配置不在服务器 hdfs-site.xml 中设置,
而是在客户端的 Hadoop 配置 core-site.xml 文件中设置 fs.defaultFS 为当前集群 hdfs://mycluster。
确保您的客户端配置也已正确设置以支持 HDFS 高可用性。 -->
</configuration>
[root@hadoop-0003 ~]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0003 hadoop]# vim hdfs-site.xml
yarn-site.xml
在所有 resourcemanager 节点和 nodemanager 节点上: (hadoop-0001, hadoop-0002, hadoop-0003)
<?xml version="1.0"?>
<configuration>
<!-- YARN ResourceManager 高可用配置 -->
<!-- 启用 ResourceManager 的高可用模式 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 开启ResourceManager失败自动切换 -->
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 设置 YARN 集群的唯一标识符 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<!-- 指定 ResourceManager 的 ID 列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop-0001</value>
</property>
<!-- 配置 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop-0002</value>
</property>
<!-- YARN ResourceManager 服务地址配置 -->
<!-- rm1 的 Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop-0001:8088</value>
</property>
<!-- rm1 的 HTTPS Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>hadoop-0001:8090</value>
</property>
<!-- rm2 的 Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop-0002:8088</value>
</property>
<!-- rm2 的 HTTPS Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>hadoop-0002:8090</value>
</property>
<!-- 使用 ZooKeeper 集群进行故障转移 -->
<!-- 配置 ZooKeeper 的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-0001:2181,hadoop-0002:2181,hadoop-0003:2181</value>
</property>
<property>
<!-- 启用RM重启的功能,默认为false -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- YARN NodeManager 配置 -->
<!-- 配置 NodeManager 的辅助服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 用于状态存储的类 -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<!-- NodeManager启用server使用算法的类 -->
<name>yarn-nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!-- 启用日志聚合功能 -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 聚集的日志在HDFS上保存最长的时间 -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<!-- 聚集的日志在HDFS上保存最长的时间 -->
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/hadoopHA/logs</value>
</property>
<!-- YARN 调度器配置 -->
<!-- 配置 ResourceManager 使用的调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- yarn.nodemanager.hostname 和 yarn.nodemanager.address 这样的配置项可以来直接设置 NodeManager 的主机名和地址。但不是必须的。NodeManager 的主机名和地址通常是通过启动 NodeManager 服务的机器的主机名和配置的网络接口来自动确定的。NodeManager 会自动注册到 ResourceManager 上,并报告其可用的资源(如 CPU、内存和磁盘空间)。这个注册过程是基于 NodeManager 所在机器的主机名和配置的端口进行的。 -->
<!-- 其他 YARN 相关配置 -->
<!-- 可以根据需要添加其他属性,例如资源限制、队列配置等 -->
</configuration>
[root@hadoop-0001 hadoop]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0001 hadoop]# vim yarn-site.xml
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp yarn-site.xml root@$i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop; done
mapred-site.xml
在所有节点上(因为MapReduce客户端需要在任何节点上运行) (hadoop-0001, hadoop-0002, hadoop-0003):
<configuration>
<!-- 设置MapReduce框架的名称,这里指定为YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> <!-- 指定MapReduce运行在YARN上 -->
</property>
<!-- (可选)设置MapReduce JobHistory Server的地址,通常与ResourceManager集成,因此这些配置可能不是必需的 -->
<!-- 如果你的集群需要单独配置JobHistory Server,可以取消以下注释并根据需要修改 -->
<!-- <property>-->
<!-- <name>mapreduce.jobhistory.address</name>-->
<!-- <value>historyserver-hostname:10020</value> <!– JobHistory Server的主机名和端口号 –>-->
<!-- </property>-->
<!-- <property>-->
<!-- <name>mapreduce.jobhistory.webapp.address</name>-->
<!-- <value>historyserver-hostname:19888</value> <!– JobHistory Server Web应用的主机名和端口号 –>-->
<!-- </property>-->
<!-- (可选)设置MapReduce作业完成后JobHistory文件的存储位置 -->
<!-- <property>-->
<!-- <name>mapreduce.jobhistory.done.dir</name>-->
<!-- <value>/user/history/done</value> <!– 存储完成作业的JobHistory文件的HDFS路径 –>-->
<!-- </property>-->
<!-- (可选)设置MapReduce作业的中间输出目录 -->
<!-- <property>-->
<!-- <name>mapreduce.task.io.sort.mb</name>-->
<!-- <value>100</value> <!– 设置排序缓冲区大小为100MB –>-->
<!-- </property>-->
<!-- <property>-->
<!-- <name>mapreduce.task.io.sort.factor</name>-->
<!-- <value>10</value> <!– 设置排序时合并的文件数 –>-->
<!-- </property>-->
<!-- 其他可能的自定义配置 -->
<!-- 根据你的具体需求添加或修改 -->
</configuration>
[root@hadoop-0001 hadoop]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0001 hadoop]# vim mapred-site.xml
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp mapred-site.xml root@$i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop; done
写入works文件
指定哪些主机运行DataNode和NodeManager
方便使用 start-dfs.sh脚本管理集群,需配合配置 ssh 免密登录,下方会有设置
在所有节点(hadoop-0001, hadoop-0002, hadoop-0003)上配置:
写入works文件,workers 文件用于列出所有参与集群运行的工作节点
[root@hadoop-0001 hadoop-3.4.0]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop
cat workers
hadoop-0001
hadoop-0002
hadoop-0003
[root@hadoop-0001 hadoop]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0001 hadoop-3.4.0]# vim workers
[root@hadoop-0001 hadoop-3.4.0]# for i in 192.168.0.222 192.168.0.252; do scp workers root@$i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop; done
注意:关于mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address的注释,实际上在Hadoop 3.x中,你可能不需要单独配置这些属性,因为JobHistory Server的功能通常已经集成到ResourceManager中。这里的注释是为了解释这些属性在旧版本中的作用,并在实际配置中可能不需要。如果你的集群确实需要单独的JobHistory Server,那么你需要确保它正确配置并运行。
启动 hadoop 集群
给 hadoop 用户授权
在所有节点(hadoop-0001, hadoop-0002, hadoop-0003)
[root@hadoop-0001 ~]# chown -R hadoop:hadoop /data/hadoop/
[root@hadoop-0002 ~]# chown -R hadoop:hadoop /data/hadoop/
[root@hadoop-0003 ~]# chown -R hadoop:hadoop /data/hadoop/
故障转移配置sshfence
设置免密登录
在所有节点(hadoop-0001, hadoop-0002, hadoop-0003)
配置所有节点的 hadoop 用户都对所有节点免密登录,sshfence 故障转移期间要求,Hadoop 服务的运行用户它必须能够在不提供密码的情况下通过 SSH 连接到目标节点
[root@hadoop-0001 ~]# su hadoop
[hadoop@hadoop-0001 hadoop]$ ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""
[hadoop@hadoop-0001 hadoop]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252; do ssh-copy-id $i; done
[root@hadoop-0002 ~]# su hadoop
[hadoop@hadoop-0002 hadoop]$ ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""
[hadoop@hadoop-0002 hadoop]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252; do ssh-copy-id $i; done
[root@hadoop-0003 ~]# su hadoop
[hadoop@hadoop-0003 hadoop]$ ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""
[hadoop@hadoop-0003 hadoop]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252; do ssh-copy-id $i; done
# 如果 hdfs-site.xml 文件和 core-site.xml文件配置了故障转移的相关配置,但是没有配置自动开启,即如果 hdfs-site.xml文件的 dfs.ha.automatic-failover.enabled没有设置或者设置为false,没有把dfs.ha.automatic-failover.enabled设置为true。则需要在启动集群 start-dfs.sh 前,在每台NameNode节点手动启动 ZKFC 守护进程,当 ZKFC 启动时,它们将自动选择其中一个 NameNode 变为活动状态。
# 手动开启命令
# [hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start zkfc
# 当前 hdfs-site.xml 配置文件的 dfs.ha.automatic-failover.enabled设置为true,部署完成后可直接使用 start-dfs.sh 启动
使用用户 hadoop
在所有节点(hadoop-0001, hadoop-0002, hadoop-0003)
格式化 ZooKeeper
在其中一个 NameNode 节点(hadoop-0001)
在 ZooKeeper 中初始化 required 状态。您可以通过从其中一个 NameNode 主机运行以下命令来执行此操作
这将在 ZooKeeper 中创建一个 znode,自动故障转移系统将在其中存储其数据。
[hadoop@hadoop-0001 root]$ hdfs zkfc -formatZK
WARNING: /data/hadoop/hadoop_soft/hadoop-3.4.0/logs does not exist. Creating.
2024-11-14 10:13:34,101 INFO tools.DFSZKFailoverController: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting DFSZKFailoverController
STARTUP_MSG: host = hadoop-0001/192.168.0.141
STARTUP_MSG: args = [-formatZK]
STARTUP_MSG: version = 3.4.0
....
....
2024-11-14 10:13:34,511 INFO ha.ActiveStandbyElector: Session connected.
2024-11-14 10:13:34,527 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
2024-11-14 10:13:34,631 INFO zookeeper.ZooKeeper: Session: 0x300001eed630000 closed
2024-11-14 10:13:34,632 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x300001eed630000
2024-11-14 10:13:34,632 INFO zookeeper.ClientCnxn: EventThread shut down for session: 0x300001eed630000
2024-11-14 10:13:34,633 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DFSZKFailoverController at hadoop-0001/192.168.0.141
************************************************************/
启动 journalnode服务
-
新集群需要在 NameNode 节点格式化 HDFS(对于新集群或重新格式化)前启动
journalnode服务 -
不需要格式化 HDFS的,start-dfs.sh 会连带把 journalnode 启动起来
从所有节点运行以下命令来执行此操作 (hadoop-0001, hadoop-0002, hadoop-0003)
[hadoop@hadoop-0001 hadoop]$ hdfs --daemon start journalnode
[hadoop@hadoop-0002 hadoop]$ hdfs --daemon start journalnode
[hadoop@hadoop-0003 hadoop]$ hdfs --daemon start journalnode
# JournalNode 进程均已启动
# 日志无报错
# hadoop-hadoop-journalnode-hadoop-0001.log
# hadoop-hadoop-journalnode-hadoop-0002.log
# hadoop-hadoop-journalnode-hadoop-0003.log
[hadoop@hadoop-0001 root]$ jps | grep -vi jps
3496 JournalNode
[hadoop@hadoop-0001 root]$ ss -utnlp | grep 8485
tcp LISTEN 0 256 *:8485 *:* users:(("java",pid=3496,fd=346))
[hadoop@hadoop-0002 root]$ jps | grep -vi jps
3059 JournalNode
[hadoop@hadoop-0002 root]$ ss -utnlp | grep 8485
tcp LISTEN 0 256 *:8485 *:* users:(("java",pid=3059,fd=346))
[hadoop@hadoop-0003 root]$ jps | grep -vi jps
3103 JournalNode
[hadoop@hadoop-0003 root]$ ss -utnlp | grep 8485
tcp LISTEN 0 256 *:8485 *:* users:(("java",pid=3103,fd=346))
格式化 namenode
NameNode 一个格式化另一个不格式化而是同步格式化的 namenode 的数据
在 NameNode 节点在(hadoop-0001,hadoop-0002)上
首次启动 HDFS 时,必须对其进行格式化。将新的分布式文件系统格式化为 hdfs
格式化 NameNode 节点 hadoop-0001
#[hadoop@hadoop-0001 hadoop-3.4.0]$ source /etc/profile
[hadoop@hadoop-0001 logs]$ hdfs namenode -format
2024-11-14 10:19:47,841 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop-0001/192.168.0.141
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.4.0
....
....
2024-11-14 10:19:49,304 INFO common.Storage: Storage directory /data/hadoop/hadoop_data/hdfs/namenode has been successfully formatted.
2024-11-14 10:19:49,383 INFO namenode.FSImageFormatProtobuf: Saving image file /data/hadoop/hadoop_data/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
2024-11-14 10:19:49,448 INFO namenode.FSImageFormatProtobuf: Image file /data/hadoop/hadoop_data/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 401 bytes saved in 0 seconds .
2024-11-14 10:19:49,452 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2024-11-14 10:19:49,474 INFO blockmanagement.DatanodeManager: Slow peers collection thread shutdown
2024-11-14 10:19:49,482 INFO namenode.FSNamesystem: Stopping services started for active state
2024-11-14 10:19:49,482 INFO namenode.FSNamesystem: Stopping services started for standby state
2024-11-14 10:19:49,496 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2024-11-14 10:19:49,496 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-0001/192.168.0.141
************************************************************/
------------------------------------------------------------------------------------------------
# 这部分是删除数据重新格式化
## 删除 datanode 数据
#[hadoop@hadoop-0001 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/datanode/current/
#[hadoop@hadoop-0002 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/datanode/current/
#[hadoop@hadoop-0003 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/datanode/current/
## 删除 namenode 数据
#[hadoop@hadoop-0001 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/namenode/current/VERSION
#[hadoop@hadoop-0002 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/namenode/current/VERSION
#[hadoop@hadoop-0003 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/namenode/current/VERSION
#
## 删除 journalnode 数据
#[hadoop@hadoop-0001 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/journalnode/mycluster
#[hadoop@hadoop-0002 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/journalnode/mycluster
#[hadoop@hadoop-0003 hadoop]$ rm -rf /data/hadoop/hadoop_data/hdfs/journalnode/mycluster
---------------------------------------------------------------------------------------------------------
启动 namenode 在 hadoop-0001
# 格式化之后启动 namenode
[hadoop@hadoop-0001 logs]$ hdfs --daemon start namenode
[hadoop@hadoop-0001 logs]$ jps | grep -vi jps
3860 NameNode
3496 JournalNode
[hadoop@hadoop-0001 logs]$ ss -utnlp | grep 50070
tcp LISTEN 0 500 192.168.0.141:50070 *:* users:(("java",pid=3860,fd=341))
# 日志无报错
同步数据
第二个 namenode 同步第一个 namenode 的数据
hadoop-0002 的 namenode 同步 hadoop-0001 的 namenode 的数据
在第二个namenode节点 同步 第一个namenode节点数据
在备用NameNode上执行hdfs namenode -bootstrapStandby命令,这会将主NameNode的状态同步到备用NameNode。
[hadoop@hadoop-0002 logs]$ hdfs namenode -bootstrapStandby
2024-11-14 10:22:39,769 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop-0002/192.168.0.222
STARTUP_MSG: args = [-bootstrapStandby]
STARTUP_MSG: version = 3.4.0
....
....
************************************************************/
2024-11-14 10:22:39,775 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2024-11-14 10:22:39,842 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
2024-11-14 10:22:40,005 INFO ha.BootstrapStandby: Found nn: nn1, ipc: hadoop-0001/192.168.0.141:8020
2024-11-14 10:22:40,270 INFO common.Util: Assuming 'file' scheme for path /data/hadoop/hadoop_data/hdfs/namenode in configuration.
2024-11-14 10:22:40,271 INFO common.Util: Assuming 'file' scheme for path /data/hadoop/hadoop_data/hdfs/namenode in configuration.
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://hadoop-0001:50070
Other NN's IPC address: hadoop-0001/192.168.0.141:8020
Namespace ID: 1218448573
Block pool ID: BP-822883281-192.168.0.141-1731550789288
Cluster ID: CID-fe96f3bb-9828-4028-8aa1-b987907213ad
Layout version: -67
Service Layout version: -67
isUpgradeFinalized: true
isRollingUpgrade: false
=====================================================
2024-11-14 10:22:40,582 INFO common.Storage: Storage directory /data/hadoop/hadoop_data/hdfs/namenode has been successfully formatted.
2024-11-14 10:22:40,594 INFO common.Util: Assuming 'file' scheme for path /data/hadoop/hadoop_data/hdfs/namenode in configuration.
2024-11-14 10:22:40,595 INFO common.Util: Assuming 'file' scheme for path /data/hadoop/hadoop_data/hdfs/namenode in configuration.
2024-11-14 10:22:40,613 INFO namenode.FSEditLog: Edit logging is async:true
2024-11-14 10:22:40,672 INFO namenode.TransferFsImage: Opening connection to http://hadoop-0001:50070/imagetransfer?getimage=1&txid=0&storageInfo=-67:1218448573:1731550789288:CID-fe96f3bb-9828-4028-8aa1-b987907213ad&bootstrapstandby=true
2024-11-14 10:22:40,774 INFO common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /data/hadoop/hadoop_data/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 took 0.00s.
2024-11-14 10:22:40,774 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 401 bytes.
2024-11-14 10:22:40,779 INFO ha.BootstrapStandby: Skipping InMemoryAliasMap bootstrap as it was not configured
2024-11-14 10:22:40,783 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-0002/192.168.0.222
************************************************************/
启动第二个 namenode 在 hadoop-0002
# 启动第二个 namenode
[hadoop@hadoop-0002 root]$ hdfs --daemon start namenode
[hadoop@hadoop-0002 logs]$ jps | grep -vi jps
3059 JournalNode
3557 NameNode
[hadoop@hadoop-0002 logs]$ ss -utnlp | grep 50070
tcp LISTEN 0 500 192.168.0.222:50070 *:* users:(("java",pid=3557,fd=341))
# 查看namenode状态,此时未开启 ZKFC 守护进程均为 standby
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn2
standby
开启 ZKFC 守护进程
ZKFC 守护进程运行在 NameNode 节点 (hadoop-0001, hadoop-0002)
# 运行 hadoop-0001 的 datanode 和 ZKFC
# 开启 ZKFC 守护程序,这是启动zookeeper选举制度
[hadoop@hadoop-0001 logs]$ hdfs --daemon start zkfc
[hadoop@hadoop-0002 logs]$ hdfs --daemon start zkfc
# 查看namenode状态,一个active 一个standby
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn1
active
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn2
standby
启动 HDFS 守护进程 和
逐个启动 datanode 守护进程 和 ZKFC 守护进程
datanode 守护进程运行在所有节点 (hadoop-0001, hadoop-0002, hadoop-0003)
# 开启 datanode 守护进程 hadoop-0001
[hadoop@hadoop-0001 logs]$ hdfs --daemon start datanode
[hadoop@hadoop-0001 logs]$ jps | grep -vi jps
3496 JournalNode
26296 DataNode
25787 DFSZKFailoverController
24812 NameNode
# 开启 datanode 守护进程 hadoop-0002
[hadoop@hadoop-0002 logs]$ hdfs --daemon start datanode
[hadoop@hadoop-0002 logs]$ jps | grep -vi jps
3059 JournalNode
25668 DataNode
24184 NameNode
25341 DFSZKFailoverController
# 开启 datanode 守护进程 hadoop-0003
[hadoop@hadoop-0003 root]$ hdfs --daemon start datanode
[hadoop@hadoop-0003 root]$ jps | grep -vi jps
22086 DataNode
3103 JournalNode
# 查看日志无报错
启动 YARN 守护进程
# 在 namenode 进程所在其中一个节点 hadoop-0001 执行
[hadoop@hadoop-0001 logs]$ start-yarn.sh
Starting resourcemanagers on [ hadoop-0001 hadoop-0002]
hadoop-0001: Warning: Permanently added 'hadoop-0001' (ECDSA) to the list of known hosts.
hadoop-0002: Warning: Permanently added 'hadoop-0002' (ECDSA) to the list of known hosts.
Starting nodemanagers
hadoop-0003: Warning: Permanently added 'hadoop-0003' (ECDSA) to the list of known hosts.
# 查看 hadoop-0001
[hadoop@hadoop-0001 logs]$ jps | grep -vi jps
26951 NodeManager
3496 JournalNode
26296 DataNode
26824 ResourceManager
25787 DFSZKFailoverController
24812 NameNode
# 查看 hadoop-0002
[hadoop@hadoop-0002 logs]$ jps | grep -vi jps
26098 NodeManager
3059 JournalNode
25668 DataNode
24184 NameNode
25341 DFSZKFailoverController
25999 ResourceManager
# 查看 hadoop-0003
[hadoop@hadoop-0003 logs]$ jps | grep -vi jps
22086 DataNode
22376 NodeManager
3103 JournalNode
# 查看日志无报错
启动 MapReduce JobHistory Server,在指定的 mapred 服务器上(可选)
提供作业历史的查询接口
# 开启
[hadoop@hadoop-0001 hadoop]$ mapred --daemon start historyserver
# 关闭
[hadoop@hadoop-0001 hadoop]$ mapred --daemon stop historyserver
查看集群状态
# 最重要看日志有没有报错
#日志 namenode
#日志 datanode
#日志 resourcemanager
#日志 nodemanager
#日志 journalnode
#日志 zkfc
# 网页查看
http://121.36.222.173:8088/cluster
# 查看接口
[hadoop@hadoop-0001 logs]$ curl -s "http://hadoop-0001:8088/ws/v1/cluster/info"
{"clusterInfo":{"id":1731567290015,"startedOn":1731567290015,"state":"STARTED","haState":"STANDBY","rmStateStoreName":"org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore","resourceManagerVersion":"3.4.0","resourceManagerBuildVersion":"3.4.0 from bd8b77f398f626bb7791783192ee7a5dfaeec760 by root source checksum 934da0c5743762b7851cfcff9f8ca2","resourceManagerVersionBuiltOn":"2024-03-04T06:54Z","hadoopVersion":"3.4.0","hadoopBuildVersion":"3.4.0 from bd8b77f398f626bb7791783192ee7a5dfaeec760 by root source checksum f7fe694a3613358b38812ae9c31114e","hadoopVersionBuiltOn":"2024-03-04T06:35Z","haZooKeeperConnectionState":"CONNECTED"}}[hadoop@hadoop-0001 logs]$
# 命令行查看
# 查看 HDFS 的状态,包括数据节点、存储使用情况等信息。
[hadoop@hadoop-0001 logs]$ hdfs dfsadmin -report
Configured Capacity: 126421143552 (117.74 GB)
Present Capacity: 95679483904 (89.11 GB)
DFS Remaining: 95679397888 (89.11 GB)
DFS Used: 86016 (84 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (3):
Name: 192.168.0.141:9866 (hadoop-0001)
Hostname: hadoop-0001
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8407486464 (7.83 GB)
DFS Remaining: 31890853888 (29.70 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.68%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Nov 14 15:04:16 CST 2024
Last Block Report: Thu Nov 14 14:50:01 CST 2024
Num of Blocks: 0
Name: 192.168.0.222:9866 (hadoop-0002)
Hostname: hadoop-0002
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8405856256 (7.83 GB)
DFS Remaining: 31892484096 (29.70 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.68%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Nov 14 15:04:16 CST 2024
Last Block Report: Thu Nov 14 14:50:04 CST 2024
Num of Blocks: 0
Name: 192.168.0.252:9866 (hadoop-0003)
Hostname: hadoop-0003
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 28672 (28 KB)
Non DFS Used: 8402280448 (7.83 GB)
DFS Remaining: 31896059904 (29.71 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.69%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Nov 14 15:04:16 CST 2024
Last Block Report: Thu Nov 14 14:50:07 CST 2024
Num of Blocks: 0
# 查看 YARN 节点的状态。
[hadoop@hadoop-0001 logs]$ yarn node -list
2024-11-14 15:04:51,798 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop-0001:42957 RUNNING hadoop-0001:8042 0
hadoop-0002:39030 RUNNING hadoop-0002:8042 0
hadoop-0003:43300 RUNNING hadoop-0003:8042 0
# 关于默认队列的一些关键信息,如队列容量、最大容量等
[hadoop@hadoop-0001 logs]$ yarn queue -status default
2024-11-14 15:05:16,927 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Queue Information :
Scheduler Name : CapacityScheduler
Queue Name : default
Queue Path : root.default
State : RUNNING
Capacity : 100.00%
Current Capacity : .00%
Maximum Capacity : 100.00%
Weight : -1.00
Maximum Parallel Apps : 2147483647
Default Node Label expression : <DEFAULT_PARTITION>
Accessible Node Labels : *
Preemption : disabled
Intra-queue Preemption : disabled
# 查看 YARN 应用程序的状态,包括应用程序的状态、用户、队列、启动时间等
# 这个输出表明您的 YARN 集群目前没有任何正在运行、已提交或已接受的应用。这是一个正常的状态,特别是如果您刚刚启动集群或者还没有提交任何作业。
[hadoop@hadoop-0001 logs]$ yarn application -list
2024-11-14 15:06:15,823 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):0
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
测试故障转移
测试 namenode 故障转移
# 查看活跃节点 活跃节点为 nn2
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn2
active
# 测试故障转移
# hdfs haadmin -failover <sourceNN> <destNN>,其中 <sourceNN> 是当前的活跃NameNode,而 <destNN> 是您希望成为新的活跃NameNode。
# 在不活跃的 namenode 节点运行 hadoop-0001执行
# 将活跃的 nn2 置为不活跃,把不活跃的 nn1 置为活跃
[hadoop@hadoop-0001 logs]$ hdfs --config /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/ haadmin -failover nn2 nn1
Failover to NameNode at hadoop-0001/192.168.0.141:8020 successful
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn1
active
[hadoop@hadoop-0001 logs]$ hdfs haadmin -getServiceState nn2
standby
# Hadoop HA管理工具拒绝了这个操作,因为它检测到自动故障转移已经启用。Hadoop为了防止可能的脑裂(split-brain)场景或其他不正确的状态,不允许手动管理HA状态,除非使用 --forcemanual 标志。
hdfs --config /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/ haadmin -transitionToStandby nn2
[hadoop@hadoop-0002 logs]$ hdfs --config /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/ haadmin -transitionToStandby nn2
Automatic failover is enabled for NameNode at hadoop-0002/192.168.0.222:8020
Refusing to manually manage HA state, since it may cause
a split-brain scenario or other incorrect state.
If you are very sure you know what you are doing, please
specify the --forcemanual flag.
测试 ResourceManager 故障转移
[hadoop@hadoop-0001 logs]$ yarn rmadmin -getServiceState rm1
standby
[hadoop@hadoop-0001 logs]$ yarn rmadmin -getServiceState rm2
active
# 测试故障转移 关闭活跃的 resourcemanager rm2 在hadoop-0002
[hadoop@hadoop-0002 logs]$ yarn --daemon stop resourcemanager
# 查看 active 切换到 rm1 hadoop-0001
[hadoop@hadoop-0002 logs]$ yarn rmadmin -getServiceState rm1
active
[hadoop@hadoop-0002 logs]$
[hadoop@hadoop-0002 logs]$ yarn rmadmin -getServiceState rm2
2024-11-14 17:06:10,370 INFO ipc.Client: Retrying connect to server: hadoop-0002/192.168.0.222:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From hadoop-0002/192.168.0.222 to hadoop-0002:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
# 开启关闭的 rm2
[hadoop@hadoop-0002 logs]$ yarn --daemon start resourcemanager
# 活跃节点正常
[hadoop@hadoop-0002 logs]$ yarn rmadmin -getServiceState rm1
active
[hadoop@hadoop-0002 logs]$ yarn rmadmin -getServiceState rm2
standby
部署hadoop HA 集群顺序:
安装配置 `java` 环境
安装和配置 `ZooKeeper`
启动 `ZooKeeper` 服务
安装配置 `hadoop`
格式化 `ZooKeeper`
启动 `journalnode`服务
格式化第一个 `namenode`
启动第一个 `namenode`
第二个 `namenode` 同步第一个`namenode` 数据
启动第二个 `namenode`
启动 `ZKFC` 守护进程
启动 `HDFS` 守护进程
启动 `YARN` 守护进程
后续可以用 `start-dfs.sh` 脚本管理集群
关闭 hadoop 集群
关闭后再打开,再打开时不是新的集群了,不需要执行格式化操作
先停止 YARN 守护进程
[hadoop@hadoop-0001 hadoop]$ stop-yarn.sh
再停止 HDFS 守护进程
[hadoop@hadoop-0001 hadoop]$ stop-dfs.sh
再次启动可用 start-dfs.sh
[hadoop@hadoop-0001 logs]$ start-dfs.sh
Starting namenodes on [hadoop-0001 hadoop-0002]
Starting datanodes
Starting journal nodes [hadoop-0001 hadoop-0003 hadoop-0002]
Starting ZK Failover Controllers on NN hosts [hadoop-0001 hadoop-0002]
[hadoop@hadoop-0001 logs]$ jps | grep -vi jps
24240 DFSZKFailoverController
24017 JournalNode
23655 NameNode
23786 DataNode
[hadoop@hadoop-0001 logs]$ start-yarn.sh
Starting resourcemanagers on [ hadoop-0001 hadoop-0002]
Starting nodemanagers
[hadoop@hadoop-0001 logs]$ jps | grep -vi jps
24240 DFSZKFailoverController
24736 ResourceManager
24017 JournalNode
23655 NameNode
23786 DataNode
24875 NodeManager
补充不使用 works 文件的单独启动
对于hdfs节点
使用以下命令在指定为 hdfs 的节点上启动 HDFS NameNode:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start namenode
使用以下命令在每个指定为 hdfs 的节点上启动 HDFS DataNode:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon start datanode
对应yarn节点
使用以下命令启动 YARN,在指定的 ResourceManager 上作为 yarn 运行:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start resourcemanager
运行脚本以 yarn 形式在每个指定的主机上启动 NodeManager:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start nodemanager
WebAppProxy 服务器
启动独立的 WebAppProxy 服务器。在 WebAppProxy 服务器上以 yarn 形式运行。如果多个服务器与负载均衡一起使用,则应在每个服务器上运行:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon start proxyserver
MapReduce JobHistory Server
使用以下命令启动 MapReduce JobHistory Server,在指定的 mapred 服务器上运行:
[mapred]$ $HADOOP_HOME/bin/mapred --daemon start historyserver
补充不使用 works 文件的单独关闭
对于hdfs节点
使用以下命令停止 NameNode,在指定的 NameNode 上运行 hdfs:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop namenode
运行脚本以停止 hdfs 形式的 DataNode:
[hdfs]$ $HADOOP_HOME/bin/hdfs --daemon stop datanode
对应yarn节点
使用以下命令停止 ResourceManager,在指定的 ResourceManager 上运行 yarn:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop resourcemanager
运行脚本以 yarn 形式停止 worker 上的 NodeManager:
[yarn]$ $HADOOP_HOME/bin/yarn --daemon stop nodemanager
停止 WebAppProxy 服务器
停止 WebAppProxy 服务器。在 WebAppProxy 服务器上以 yarn 形式运行。如果多个服务器与负载均衡一起使用,则应在每个服务器上运行:
[yarn]$ $HADOOP_HOME/bin/yarn stop proxyserver
MapReduce JobHistory Server
使用以下命令停止 MapReduce JobHistory Server,并在指定的服务器上运行,如 mapred:
[mapred]$ $HADOOP_HOME/bin/mapred --daemon stop historyserver
集群扩容
新增一台 datanode 节点
| 服务器 | IP地址 | 配置 | 系统 | jdk | hadoop | 角色 |
|---|---|---|---|---|---|---|
| hadoop-0004 | 192.168.0.170 | 2C4G | CentOS 7.9 64bit | jdk-8u421-linux-x64.tar.gz | hadoop-3.4.0.tar.gz | 都作为 DataNode 和 NodeManager |
服务器配置
配置对新节点 hadoop-0004 免密登录
[root@hadoop-0001 ~]# ssh-copy-id 192.168.0.100
上传文件到新节点 hadoop-0004
[root@hadoop-0001 ~]# scp hadoop-3.4.0.tar.gz jdk-8u421-linux-x64.tar.gz install_jdk.sh init_server.sh env_hadoop_intall.sh 192.168.0.100:/root
服务器配置初始化
[root@hadoop-0004 ~]# bash init_server.sh
所有节点配置 hosts文件
(hadoop-0001, hadoop-0002, hadoop-0003, hadoop-0004)
[root@hadoop-0001 ~]# vim /etc/hosts
# 把127.0.0.1对应的 主机名这行删掉
192.168.0.141 hadoop-0001
192.168.0.222 hadoop-0002
192.168.0.252 hadoop-0003
192.168.0.100 hadoop-0004
[root@hadoop-0001 ~]# for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do scp /etc/hosts $i:/etc/hosts; done
安装jdk
[root@hadoop-0004 ~]# bash install_jdk.sh jdk-8u421-linux-x64.tar.gz
# 退出再登陆,加载环境变量,也可以执行source /etc/profile使变量在当前会话生效
安装 hadoop
[root@hadoop-0004 ~]# bash env_hadoop_intall.sh hadoop-3.4.0.tar.gz
# 退出再登陆,加载环境变量,也可以执行source /etc/profile使变量在当前会话生效
配置hadoop
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- 引入用于格式化输出的XSL样式表(可选) -->
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--
指定Hadoop文件系统的默认URI。
这是HDFS(Hadoop分布式文件系统)的逻辑名称,通常指向NameNode。
在HDFS高可用(HA)配置中,这个URI应该指向NameNode的集群。组成集群的配置写在 hdfs-site.xml
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value> <!-- 指定NameNode所在的集群名和端口号 即HDFS 集群的名称-->
</property>
<!--
设置Hadoop临时文件的存储目录。
这个目录用于存储Hadoop守护进程(如NameNode、DataNode等)的临时文件。
请确保这个目录在您的文件系统中存在,并且Hadoop进程有权限写入。
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/hadoop_data/tmp</value> <!-- 临时文件存储的本地目录 -->
</property>
<!--
配置ZooKeeper集群的地址。
在Hadoop的高可用配置中,ZooKeeper用于存储配置信息、集群状态和协调NameNode的故障转移。
请列出所有ZooKeeper节点的地址,每个节点用逗号分隔。
-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-0001:2181,hadoop-0002:2181,hadoop-0003:2181</value> <!-- ZooKeeper节点地址 -->
</property>
<!--
设置文件I/O操作的缓冲区大小。
这个值决定了Hadoop在进行文件读写操作时使用的内存缓冲区大小。
较大的缓冲区可以提高性能,但也会增加内存使用。
默认值可能因Hadoop版本而异,这里设置为4096字节(4KB)。
-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value> <!-- 以字节为单位,根据需要调整 -->
</property>
<!--
(可选)其他Hadoop核心配置属性
根据您的需求和环境,您可能还需要添加其他配置属性。
例如,您可以配置网络拓扑脚本、垃圾回收选项、Java堆大小等。
-->
</configuration>
[root@hadoop-0004 ~]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0004 ~]# vim core-site.xml
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HDFS 基本配置 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value> <!-- HDFS 集群的名称 -->
</property>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 每个文件块在HDFS中的副本数 -->
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value> <!-- 列出集群中所有 NameNode 的名称或 ID -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop-0001:8020</value> <!-- nn1 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop-0002:8020</value> <!-- nn2 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop-0001:50070</value> <!-- nn1 的 HTTP 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop-0002:50070</value> <!-- nn2 的 HTTP 地址 -->
</property>
<!-- DataNode 配置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/datanode</value> <!-- DataNode 存储数据块的本地目录 -->
</property>
<!-- JournalNode 配置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/journalnode</value> <!-- JournalNode 存储编辑日志的本地目录 -->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-0001:8485;hadoop-0002:8485;hadoop-0003:8485/mycluster</value>
<!-- 指定 JournalNode 集群的地址 -->
</property>
<!-- HDFS 高可用性配置 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value> <!-- 开启 NameNode 失败自动切换 -->
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- 配置 NameNode 失败后自动切换实现方式 -->
</property>
<!-- 故障转移配置 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value> <!-- 故障转移期间使用的屏蔽方法 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value> <!-- hadoop 用户的私钥文件 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value> <!-- SSH 连接超时时间,单位为毫秒 -->
</property>
<!-- 可选配置 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value> <!-- HDFS 垃圾回收站保留时间,单位为分钟 -->
</property>
<!-- 注意:客户端故障转移的配置不在服务器 hdfs-site.xml 中设置,
而是在客户端的 Hadoop 配置 core-site.xml 文件中设置 fs.defaultFS 为当前集群 hdfs://mycluster。
确保您的客户端配置也已正确设置以支持 HDFS 高可用性。 -->
</configuration>
[root@hadoop-0004 ~]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0004 ~]# vim hdfs-site.xml
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- YARN ResourceManager 高可用配置 -->
<!-- 启用 ResourceManager 的高可用模式 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 开启ResourceManager失败自动切换 -->
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 设置 YARN 集群的唯一标识符 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<!-- 指定 ResourceManager 的 ID 列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop-0001</value>
</property>
<!-- 配置 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop-0002</value>
</property>
<!-- YARN ResourceManager 服务地址配置 -->
<!-- rm1 的 Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop-0001:8088</value>
</property>
<!-- rm1 的 HTTPS Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>hadoop-0001:8090</value>
</property>
<!-- rm2 的 Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop-0002:8088</value>
</property>
<!-- rm2 的 HTTPS Web 应用地址 -->
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>hadoop-0002:8090</value>
</property>
<!-- 使用 ZooKeeper 集群进行故障转移 -->
<!-- 配置 ZooKeeper 的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop-0001:2181,hadoop-0002:2181,hadoop-0003:2181</value>
</property>
<property>
<!-- 启用RM重启的功能,默认为false -->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- YARN NodeManager 配置 -->
<!-- 配置 NodeManager 的辅助服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 用于状态存储的类 -->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<!-- NodeManager启用server使用算法的类 -->
<name>yarn-nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!-- 启用日志聚合功能 -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!-- 聚集的日志在HDFS上保存最长的时间 -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<property>
<!-- 聚集的日志在HDFS上保存最长的时间 -->
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/hadoopHA/logs</value>
</property>
<!-- YARN 调度器配置 -->
<!-- 配置 ResourceManager 使用的调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- yarn.nodemanager.hostname 和 yarn.nodemanager.address 这样的配置项可以来直接设置 NodeManager 的主机名和地址。但不是必须的。NodeManager 的主机名和地址通常是通过启动 NodeManager 服务的机器的主机名和配置的网络接口来自动确定的。NodeManager 会自动注册到 ResourceManager 上,并报告其可用的资源(如 CPU、内存和磁盘空间)。这个注册过程是基于 NodeManager 所在机器的主机名和配置的端口进行的。 -->
<!-- 其他 YARN 相关配置 -->
<!-- 可以根据需要添加其他属性,例如资源限制、队列配置等 -->
</configuration>
[root@hadoop-0004 ~]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0004 ~]# vim yarn-site.xml
mapred-site.xml
<configuration>
<!-- 设置MapReduce框架的名称,这里指定为YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> <!-- 指定MapReduce运行在YARN上 -->
</property>
<!-- (可选)设置MapReduce JobHistory Server的地址,通常与ResourceManager集成,因此这些配置可能不是必需的 -->
<!-- 如果你的集群需要单独配置JobHistory Server,可以取消以下注释并根据需要修改 -->
<!-- <property>-->
<!-- <name>mapreduce.jobhistory.address</name>-->
<!-- <value>historyserver-hostname:10020</value> <!– JobHistory Server的主机名和端口号 –>-->
<!-- </property>-->
<!-- <property>-->
<!-- <name>mapreduce.jobhistory.webapp.address</name>-->
<!-- <value>historyserver-hostname:19888</value> <!– JobHistory Server Web应用的主机名和端口号 –>-->
<!-- </property>-->
<!-- (可选)设置MapReduce作业完成后JobHistory文件的存储位置 -->
<!-- <property>-->
<!-- <name>mapreduce.jobhistory.done.dir</name>-->
<!-- <value>/user/history/done</value> <!– 存储完成作业的JobHistory文件的HDFS路径 –>-->
<!-- </property>-->
<!-- (可选)设置MapReduce作业的中间输出目录 -->
<!-- <property>-->
<!-- <name>mapreduce.task.io.sort.mb</name>-->
<!-- <value>100</value> <!– 设置排序缓冲区大小为100MB –>-->
<!-- </property>-->
<!-- <property>-->
<!-- <name>mapreduce.task.io.sort.factor</name>-->
<!-- <value>10</value> <!– 设置排序时合并的文件数 –>-->
<!-- </property>-->
<!-- 其他可能的自定义配置 -->
<!-- 根据你的具体需求添加或修改 -->
</configuration>
[root@hadoop-0004 ~]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0004 ~]# vim mapred-site.xml
配置 works文件
[root@hadoop-0001 hadoop]# cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[root@hadoop-0001 hadoop]# vim workers
hadoop-0001
hadoop-0002
hadoop-0003
hadoop-0004
[root@hadoop-0001 hadoop]# for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do scp workers $i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/; done
启动 hadoop
配置用户 hadoop 免密登录所有节点
# 设置hadoop免密登录所有节点
[root@hadoop-0001 ~]# su hadoop
[hadoop@hadoop-0001 hadoop]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do ssh-copy-id $i; done
[root@hadoop-0002 ~]# su hadoop
[hadoop@hadoop-0002 root]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do ssh-copy-id $i; done
[root@hadoop-0003 ~]# su hadoop
[hadoop@hadoop-0003 root]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do ssh-copy-id $i; done
[root@hadoop-0004 ~]# su hadoop
[hadoop@hadoop-0004 root]$ ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""
[hadoop@hadoop-0004 root]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do ssh-copy-id $i; done
新节点设置 hadoop 权限
# 新节点设置 hadoop 权限
[root@hadoop-0004 ~]# chown -R hadoop:hadoop /data/hadoop/
使用用户 hadoop
启动 hdfs 守护进程(datanode)
[hadoop@hadoop-0004 sbin]$ hdfs --daemon start datanode
[hadoop@hadoop-0004 logs]$ jps | grep -vi jps
2229 DataNode
# 日志无报错
启动 yarn 守护进程(启动 NodeManager)
[hadoop@hadoop-0004 sbin]$ yarn --daemon start nodemanager
[hadoop@hadoop-0004 logs]$ jps | grep -vi jps
2418 NodeManager
2229 DataNode
# 日志无报错
查看集群状态
# 看到 4 个节点
[hadoop@hadoop-0001 hadoop]$ yarn node -list
2024-11-15 09:42:15,121 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Total Nodes:4
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop-0001:39482 RUNNING hadoop-0001:8042 0
hadoop-0004:34567 RUNNING hadoop-0004:8042 0
hadoop-0003:42690 RUNNING hadoop-0003:8042 0
hadoop-0002:43629 RUNNING hadoop-0002:8042 0
[hadoop@hadoop-0001 hadoop]$ curl -s "http://hadoop-0001:8088/ws/v1/cluster/info"
{"clusterInfo":{"id":1731632262766,"startedOn":1731632262766,"state":"STARTED","haState":"STANDBY","rmStateStoreName":"org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore","resourceManagerVersion":"3.4.0","resourceManagerBuildVersion":"3.4.0 from bd8b77f398f626bb7791783192ee7a5dfaeec760 by root source checksum 934da0c5743762b7851cfcff9f8ca2","resourceManagerVersionBuiltOn":"2024-03-04T06:54Z","hadoopVersion":"3.4.0","hadoopBuildVersion":"3.4.0 from bd8b77f398f626bb7791783192ee7a5dfaeec760 by root source checksum f7fe694a3613358b38812ae9c31114e","hadoopVersionBuiltOn":"2024-03-04T06:35Z","haZooKeeperConnectionState":"CONNECTED"}}[hadoop@hadoop-0001 hadoop]$
缩容集群
减少一台 datanode 节点
在 Hadoop 集群中移除一个节点通常不会直接导致数据丢失,因为 Hadoop 的 HDFS 设计为高度冗余的分布式文件系统。每个数据块默认会有多个副本(通常是3个),分布在不同的节点上。
确认数据副本
确保所有数据块都有足够数量的副本分布在剩余的节点上。您可以使用以下命令来检查集群的副本分布情况:
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -report
Configured Capacity: 168561524736 (156.99 GB)
Present Capacity: 127591596032 (118.83 GB)
DFS Remaining: 127591251968 (118.83 GB)
DFS Used: 344064 (336 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (4):
Name: 192.168.0.100:9866 (hadoop-0004)
Hostname: hadoop-0004
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 8348692480 (7.78 GB)
DFS Remaining: 31949651968 (29.76 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.82%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Nov 15 09:45:49 CST 2024
Last Block Report: Fri Nov 15 09:37:22 CST 2024
Num of Blocks: 0
Name: 192.168.0.141:9866 (hadoop-0001)
Hostname: hadoop-0001
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 106496 (104 KB)
Non DFS Used: 8421670912 (7.84 GB)
DFS Remaining: 31876591616 (29.69 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.64%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Nov 15 09:45:47 CST 2024
Last Block Report: Fri Nov 15 08:55:11 CST 2024
Num of Blocks: 4
Name: 192.168.0.222:9866 (hadoop-0002)
Hostname: hadoop-0002
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 139264 (136 KB)
Non DFS Used: 8418676736 (7.84 GB)
DFS Remaining: 31879553024 (29.69 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.65%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Nov 15 09:45:50 CST 2024
Last Block Report: Fri Nov 15 08:55:11 CST 2024
Num of Blocks: 6
Name: 192.168.0.252:9866 (hadoop-0003)
Hostname: hadoop-0003
Decommission Status : Normal
Configured Capacity: 42140381184 (39.25 GB)
DFS Used: 73728 (72 KB)
Non DFS Used: 8412839936 (7.84 GB)
DFS Remaining: 31885455360 (29.70 GB)
DFS Used%: 0.00%
DFS Remaining%: 75.66%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Fri Nov 15 09:45:50 CST 2024
Last Block Report: Fri Nov 15 08:55:11 CST 2024
Num of Blocks: 2
进入安全模式
安全模式的特点:
- 只读访问:在安全模式下,HDFS 只允许读操作,不允许执行写操作。这意味着用户可以读取数据,但不能写入或删除文件。
- 保护数据完整性:安全模式确保在集群状态不稳定或正在恢复时,不会进行任何可能破坏数据一致性的操作。
- 自动进入和退出:HDFS 可以在启动时自动进入安全模式,直到满足一定的条件(如达到一定的 block 报告比例)后自动退出。管理员也可以手动将 HDFS 设置为安全模式。
安全模式对集群工作的影响:
- 不影响 MapReduce 作业:在安全模式下,HDFS 仍然可以服务于读操作,因此 MapReduce 作业可以继续运行,只要它们不需要写入 HDFS。
- 影响写操作:任何需要写入 HDFS 的操作(如新的 MapReduce 作业、HDFS 文件写入等)将被阻塞,直到安全模式被解除。
- 不影响 YARN 资源管理:ResourceManager 可以继续调度作业,但作业可能会因为 HDFS 的写入限制而无法完成。
在执行缩容操作之前,您可以将 HDFS 设置为安全模式,以防止数据丢失:
# 进入安全模式
[hadoop@hadoop-0001 hadoop]$ [hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -safemode enter
Safe mode is ON in hadoop-0001/192.168.0.141:8020
Safe mode is ON in hadoop-0002/192.168.0.222:8020
# 查看安全模式状态
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -safemode get
Safe mode is ON in hadoop-0001/192.168.0.141:8020
Safe mode is ON in hadoop-0002/192.168.0.222:8020
修改配置添加黑名单
namenode 节点 hdfs-site.xml
[hadoop@hadoop-0001 hadoop]$ cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop
[hadoop@hadoop-0001 hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- HDFS 基本配置 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value> <!-- HDFS 集群的名称 -->
</property>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 每个文件块在HDFS中的副本数 -->
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value> <!-- 列出集群中所有 NameNode 的名称或 ID -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop-0001:8020</value> <!-- nn1 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop-0002:8020</value> <!-- nn2 的 RPC 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop-0001:50070</value> <!-- nn1 的 HTTP 地址 -->
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop-0002:50070</value> <!-- nn2 的 HTTP 地址 -->
</property>
<!-- DataNode 配置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/datanode</value> <!-- DataNode 存储数据块的本地目录 -->
</property>
<!-- JournalNode 配置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/hadoop_data/hdfs/journalnode</value> <!-- JournalNode 存储编辑日志的本地目录 -->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-0001:8485;hadoop-0002:8485;hadoop-0003:8485/mycluster</value>
<!-- 指定 JournalNode 集群的地址 -->
</property>
<!-- HDFS 高可用性配置 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value> <!-- 开启 NameNode 失败自动切换 -->
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- 配置 NameNode 失败后自动切换实现方式 -->
</property>
<!-- 故障转移配置 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value> <!-- 故障转移期间使用的屏蔽方法 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value> <!-- hadoop 用户的私钥文件 -->
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value> <!-- SSH 连接超时时间,单位为毫秒 -->
</property>
<!-- 可选配置 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value> <!-- HDFS 垃圾回收站保留时间,单位为分钟 -->
</property>
<!-- 注意:客户端故障转移的配置不在服务器 hdfs-site.xml 中设置,
而是在客户端的 Hadoop 配置 core-site.xml 文件中设置 fs.defaultFS 为当前集群 hdfs://mycluster。
确保您的客户端配置也已正确设置以支持 HDFS 高可用性。 -->
<!-- 不需要白名单注释掉-->
<!-- <!– 白名单配置:指定哪些DataNode被允许连接到NameNode –>-->
<!-- <property>-->
<!-- <name>dfs.hosts</name>-->
<!-- <value>/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/hosts</value>-->
<!-- <description>HDFS白名单文件路径,该文件包含允许连接到NameNode的主机名或IP地址。</description>-->
<!-- </property>-->
<!-- 黑名单配置:指定哪些DataNode被禁止连接到NameNode -->
<property>
<name>dfs.hosts.exclude</name>
<value>/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/hosts.exclude</value>
<description>HDFS黑名单文件路径,该文件包含禁止连接到NameNode的主机名或IP地址。</description>
</property>
</configuration>
[hadoop@hadoop-0001 hadoop]$ cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop
[hadoop@hadoop-0001 hadoop]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do scp hdfs-site.xml $i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/; done
配置黑名单文件 hosts.exclude
黑白名单介绍
- dfs.hosts 文件
- 白名单文件:确实,
dfs.hosts文件是一个白名单文件,用于指定哪些主机(或DataNode)被允许连接到NameNode。 - 文件不存在:如果
dfs.hosts文件不存在,则默认行为是允许所有主机连接到NameNode,因为没有明确的白名单限制。 - 文件存在且空白:这里有一点需要纠正。如果
dfs.hosts文件存在但为空白(即没有列出任何主机),这并不意味着不允许任何主机连接到NameNode。相反,它仍然意味着没有明确的白名单限制,因此默认情况下,所有主机都可以连接到NameNode。白名单为空和不存在白名单在效果上是相同的,即不施加任何限制。
- 白名单文件:确实,
- dfs.hosts.exclude 文件
- 黑名单文件:确实,
dfs.hosts.exclude文件是一个黑名单文件,用于指定哪些主机被禁止连接到NameNode。 - 文件不存在:如果
dfs.hosts.exclude文件不存在,则默认行为是不禁止任何主机连接到NameNode,因为没有明确的黑名单限制。 - 文件存在且空白:如果
dfs.hosts.exclude文件存在但为空白(即没有列出任何主机),这确实意味着不禁止任何主机连接到NameNode。因为没有明确的黑名单项,所以所有主机都可以连接。
- 黑名单文件:确实,
[hadoop@hadoop-0001 hadoop]$ cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/
[hadoop@hadoop-0001 hadoop]$ vim hosts.exclude
192.168.0.100
[hadoop@hadoop-0001 hadoop]$ for i in 192.168.0.141 192.168.0.222 192.168.0.252 192.168.0.100; do scp hosts.exclude $i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop/; done
刷新集群
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful for hadoop-0001/192.168.0.141:8020
Refresh nodes successful for hadoop-0002/192.168.0.222:8020
[hadoop@hadoop-0001 hadoop]$ yarn rmadmin -refreshNodes
2024-11-15 09:58:50,980 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
确认退役状态
您可以使用以下命令检查退役状态:
# 如果节点已经成功退役,您将看到该节点的状态为“Decommissioned”。
# 当一个DataNode显示为 "Decommissioned" 状态时,这意味着该节点已经完全退役,并且其上的数据已经被重新分配到了集群中的其他节点。这是一个最终状态,表明退役过程已经完成。
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -report | grep -B 1 Decommission
Hostname: hadoop-0004
Decommission Status : Decommissioned
--
Hostname: hadoop-0001
Decommission Status : Normal
--
Hostname: hadoop-0002
Decommission Status : Normal
--
Hostname: hadoop-0003
Decommission Status : Normal
停止 DataNode 和 nodemanager
在确认数据安全后,您可以在要移除的节点上停止 DataNode 服务:
# 停止 DataNode
[hadoop@hadoop-0004 hadoop]$ hdfs --daemon stop datanode
[hadoop@hadoop-0004 hadoop]$ jps | grep -vi jps
2418 NodeManager
# 停止 nodemanager
[hadoop@hadoop-0004 logs]$ yarn --daemon stop nodemanager
# 查看 yarn 节点情况
[hadoop@hadoop-0001 hadoop]$ yarn node -list
2024-11-15 10:07:45,670 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop-0001:39482 RUNNING hadoop-0001:8042 0
hadoop-0003:42690 RUNNING hadoop-0003:8042 0
hadoop-0002:43629 RUNNING hadoop-0002:8042 0
从配置中移除节点 hadoop-0004
移除 hosts 文件
[root@hadoop-0001 hadoop]# vim /etc/hosts
192.168.0.141 hadoop-0001
192.168.0.222 hadoop-0002
192.168.0.252 hadoop-0003
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp /etc/hosts root@$i:/etc/hosts; done
移除 works 文件
cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop
[root@hadoop-0001 hadoop]# vim workers
hadoop-0001
hadoop-0002
hadoop-0003
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp workers root@$i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop; done
清理节点
如果您确定不再需要该节点上的数据,可以清理该节点上的 Hadoop 数据目录甚至释放节点。
退出安全模式
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -safemode leave
Safe mode is OFF in hadoop-0001/192.168.0.141:8020
Safe mode is OFF in hadoop-0002/192.168.0.222:8020
Balancer 操作(可选)
如果集群在移除节点后出现数据不平衡(即某些节点的存储使用率远高于其他节点),您可能需要运行 HDFS Balancer 工具来重新分配数据,使数据在集群中更加均匀分布。使用以下命令启动 Balancer:
[hadoop@hadoop-0001 hadoop]$ hdfs balancer
Nodes
Refresh nodes successful for hadoop-0001/192.168.0.141:8020
Refresh nodes successful for hadoop-0002/192.168.0.222:8020
[hadoop@hadoop-0001 hadoop]$ yarn rmadmin -refreshNodes
2024-11-15 09:58:50,980 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
### 确认退役状态
您可以使用以下命令检查退役状态:
```shell
# 如果节点已经成功退役,您将看到该节点的状态为“Decommissioned”。
# 当一个DataNode显示为 "Decommissioned" 状态时,这意味着该节点已经完全退役,并且其上的数据已经被重新分配到了集群中的其他节点。这是一个最终状态,表明退役过程已经完成。
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -report | grep -B 1 Decommission
Hostname: hadoop-0004
Decommission Status : Decommissioned
--
Hostname: hadoop-0001
Decommission Status : Normal
--
Hostname: hadoop-0002
Decommission Status : Normal
--
Hostname: hadoop-0003
Decommission Status : Normal
停止 DataNode 和 nodemanager
在确认数据安全后,您可以在要移除的节点上停止 DataNode 服务:
# 停止 DataNode
[hadoop@hadoop-0004 hadoop]$ hdfs --daemon stop datanode
[hadoop@hadoop-0004 hadoop]$ jps | grep -vi jps
2418 NodeManager
# 停止 nodemanager
[hadoop@hadoop-0004 logs]$ yarn --daemon stop nodemanager
# 查看 yarn 节点情况
[hadoop@hadoop-0001 hadoop]$ yarn node -list
2024-11-15 10:07:45,670 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop-0001:39482 RUNNING hadoop-0001:8042 0
hadoop-0003:42690 RUNNING hadoop-0003:8042 0
hadoop-0002:43629 RUNNING hadoop-0002:8042 0
从配置中移除节点 hadoop-0004
移除 hosts 文件
[root@hadoop-0001 hadoop]# vim /etc/hosts
192.168.0.141 hadoop-0001
192.168.0.222 hadoop-0002
192.168.0.252 hadoop-0003
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp /etc/hosts root@$i:/etc/hosts; done
移除 works 文件
cd /data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop
[root@hadoop-0001 hadoop]# vim workers
hadoop-0001
hadoop-0002
hadoop-0003
[root@hadoop-0001 hadoop]# for i in 192.168.0.222 192.168.0.252; do scp workers root@$i:/data/hadoop/hadoop_soft/hadoop-3.4.0/etc/hadoop; done
清理节点
如果您确定不再需要该节点上的数据,可以清理该节点上的 Hadoop 数据目录甚至释放节点。
退出安全模式
[hadoop@hadoop-0001 hadoop]$ hdfs dfsadmin -safemode leave
Safe mode is OFF in hadoop-0001/192.168.0.141:8020
Safe mode is OFF in hadoop-0002/192.168.0.222:8020
Balancer 操作(可选)
如果集群在移除节点后出现数据不平衡(即某些节点的存储使用率远高于其他节点),您可能需要运行 HDFS Balancer 工具来重新分配数据,使数据在集群中更加均匀分布。使用以下命令启动 Balancer:
[hadoop@hadoop-0001 hadoop]$ hdfs balancer
官方文档: Apache Hadoop 3.4.1 – 使用 Quorum Journal Manager 实现 HDFS 高可用性
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 集群搭建高可用

发表评论 取消回复