添加层级(Adding Layers)
引言
我们构建的神经网络变得越来越受人尊敬,但目前我们只有一层。当神经网络具有两层或更多隐藏层时,它们变成了“深度”网络。目前我们只有一层,实际上是一个输出层。为什么我们想要两层或更多隐藏层的原因将在后面的章节中变得明显。目前,我们没有隐藏层。隐藏层不是输入层或输出层;作为科学家,你看到的数据是输入到输入层的数据以及来自输出层的结果数据。这些端点之间的层具有我们不一定处理的值,因此得名“隐藏”。不过,别让这个名字让你认为你不能访问这些值。你通常会使用它们来诊断问题或改进你的神经网络。为了探索这个概念,让我们给这个神经网络增加另一层,并且,现在,让我们假设我们将要拥有的这两层是隐藏层,我们还没有编写我们的输出层。
在我们添加另一层之前,让我们思考一下即将到来的内容。对于第一层,我们可以看到我们有一个包含4个特征的输入:
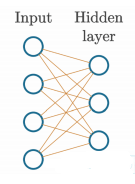
样本(特征集数据)通过输入传递,输入本身不会以任何方式改变它,传递到我们的第一个隐藏层,我们可以看到这一层有3组权重,每组包含4个值。
这3组独特的权重集与它们各自的神经元相关联。因此,由于我们有3组权重,这第一个隐藏层就有3个神经元。每个神经元都有一组独特的权重,我们有4个(因为这一层有4个输入),这就是为什么我们的初始权重有一个形状为 ( 3 , 4 ) (3,4) (3,4) 的原因。
现在,我们希望增加另一层。为此,我们必须确保该层的预期输入与前一层的输出匹配。我们通过设置每层有多少组权重和偏差来设定层中的神经元数量。前一层对当前层的权重集的影响是每个权重集需要有每个输入的单独权重。这意味着前一层的每个神经元(或如果我们谈论输入的话,每个特征)都有一个独特的权重。前一层有3组权重和3个偏差,所以我们知道它有3个神经元。这意味着,对于下一层,我们可以有尽可能多的权重集(因为这是这个新层将拥有的神经元数量),但这些权重集中的每一个都必须有3个独立的权重。
为了创建这个新层,我们将复制并粘贴我们的权重和偏差到 weights2 和 biases2,并将它们的值改为新的假设集。这里有一个例子:
import numpy as np
inputs = [[1, 2, 3, 2.5],
[2., 5., -1., 2],
[-1.5, 2.7, 3.3, -0.8]]
weights = [[0.2, 0.8, -0.5, 1],
[0.5, -0.91, 0.26, -0.5],
[-0.26, -0.27, 0.17, 0.87]]
biases = [2, 3, 0.5]
weights2 = [[0.1, -0.14, 0.5],
[-0.5, 0.12, -0.33],
[-0.44, 0.73, -0.13]]
biases2 = [-1, 2, -0.5]
接下来,我们将调用输出 layer1_ouputs:
layer1_outputs = np.dot(inputs, np.array(weights).T) + biases
print("layer1_outputs:", layer1_outputs)
>>>
layer1_outputs: [[ 4.8 1.21 2.385]
[ 8.9 -1.81 0.2 ]
[ 1.41 1.051 0.026]]
正如之前所述,层的输入要么是来自您正在训练的实际数据集的输入,要么是来自前一层的输出。这就是为什么我们定义了两个版本的权重和偏差,但只有一个输入的原因 —— 因为第二层的输入将是前一层的输出:
layer2_outputs = np.dot(layer1_outputs, np.array(weights2).T) + biases2
print("layer2_outputs:", layer2_outputs)
>>>
layer2_outputs: [[ 0.5031 -1.04185 -2.03875]
[ 0.2434 -2.7332 -5.7633 ]
[-0.99314 1.41254 -0.35655]]
完整:
import numpy as np
inputs = [[1, 2, 3, 2.5],
[2., 5., -1., 2],
[-1.5, 2.7, 3.3, -0.8]]
weights = [[0.2, 0.8, -0.5, 1],
[0.5, -0.91, 0.26, -0.5],
[-0.26, -0.27, 0.17, 0.87]]
biases = [2, 3, 0.5]
weights2 = [[0.1, -0.14, 0.5],
[-0.5, 0.12, -0.33],
[-0.44, 0.73, -0.13]]
biases2 = [-1, 2, -0.5]
layer1_outputs = np.dot(inputs, np.array(weights).T) + biases
print("layer1_outputs:", layer1_outputs)
layer2_outputs = np.dot(layer1_outputs, np.array(weights2).T) + biases2
print("layer2_outputs:", layer2_outputs)
此时,我们的神经网络可以直观地表示为:
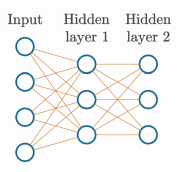
1. Training Data
训练数据
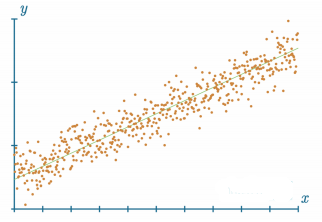
接下来,我们将使用一个可以创建非线性数据的函数,而不是手工输入随机数据。什么叫非线性数据?线性数据可以用直线拟合或表示。
非线性数据无法用直线很好地表示:
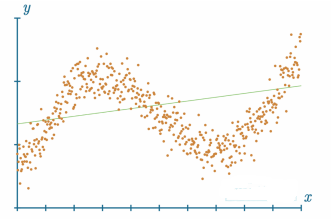
如果你要绘制形式为 ( x , y ) (x, y) (x,y) 的数据点,其中 y = f ( x ) y = f(x) y=f(x),并且看起来像是一条具有明显趋势或斜率的线,那么很可能,这些是线性数据!线性数据可以非常容易地被比神经网络简单得多的机器学习模型近似。其他机器学习算法不容易近似的是非线性数据集。为了简化这一点,我们创建了一个可以通过 pip 安装的Python包,名为 nnfs:
pip3 install nnfs
nnfs 软件包包含一些函数,我们可以用它们来创建数据。例如:
from nnfs.datasets import spiral_data
螺旋数据(spiral_data)函数是从 https://cs231n.github.io/neural-networks-case-study/ 上稍加修改的,它是本主题的一个很好的补充资源。
通常你不会为你的神经网络从函数生成训练数据。你会有一个实际的数据集。这种方式生成数据集纯粹是为了目前阶段的便利性。我们还将使用这个包来确保每个人的重复性,使用 nnfs.init(),在导入NumPy之后:
import numpy as np
import nnfs
nnfs.init()
nnfs.init()执行三件事:它将随机种子设置为0(默认情况下),创建一个 float32 数据类型的默认值,并覆盖NumPy的原始点积函数。所有这些都是为了确保后续操作的可重复结果。
spiral_data函数允许我们创建一个数据集,可以有我们想要的任意多的类别。该函数有参数可以选择类别数和每个类别中点/观测的数量,来生成结果中的非线性数据集。例如:
import numpy as np
import nnfs
from nnfs.datasets import spiral_data
import matplotlib.pyplot as plt
nnfs.init()
X, y = spiral_data(samples=100, classes=3)
plt.scatter(X[:,0], X[:,1])
plt.show()
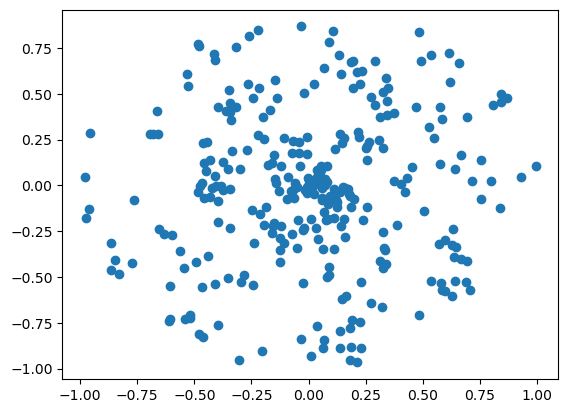
如果从中心开始追踪,就可以分别确定所有 3 个类别,但对于机器学习分类器来说,这是一个非常具有挑战性的问题。在图表中添加颜色可以让这一点更加清晰:
import numpy as np
import nnfs
from nnfs.datasets import spiral_data
import matplotlib.pyplot as plt
nnfs.init()
X, y = spiral_data(samples=100, classes=3)
plt.scatter(X[:,0], X[:,1])
plt.show()
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='brg')
plt.show()
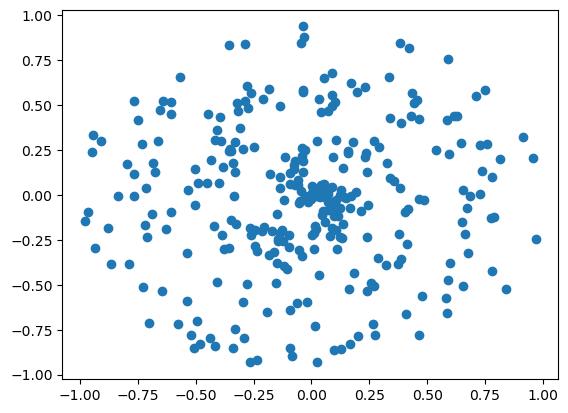
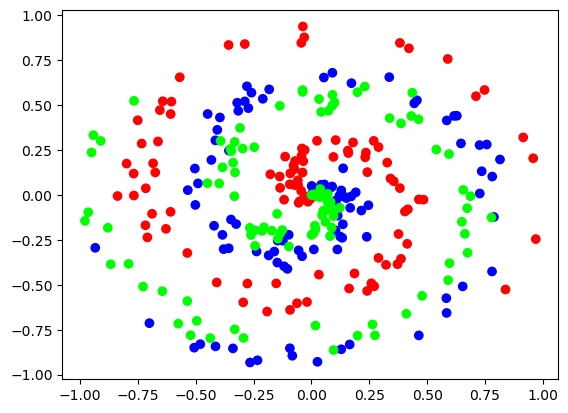
请记住,神经网络不会意识到颜色的差异,因为数据没有类别编码。这只是作为对读者的一种指导。在上述数据中,每个点都是特征,其坐标是构成数据集的样本。该点的 “分类 ”与它属于哪种螺旋有关,如上图中的蓝色、绿色或红色。然后,这些颜色将被分配一个类别编号,供模型拟合,如 0,1和2。
2. Dense Layer Class
密集层级
既然我们不再需要手工输入数据,我们就应该为各种类型的神经网络层创建类似的功能。到目前为止,我们只使用了所谓的密集层或全连接层。这些层在论文、文献和代码中通常被称为 “密集 ”层,但你偶尔也会在代码中看到它们被称为全连接层,简称 “FC”。我们的密集层类将以两个方法开始:
class Layer_Dense:
# Layer initialization
def __init__(self, n_inputs, n_neurons):
# Initialize weights and biases
pass # using pass statement as a placeholder
# Forward pass
def forward(self, inputs):
# Calculate output values from inputs, weights and biases
pass # using pass statement as a placeholder
如前所述,模型的权重通常是随机初始化的,但不总是这样。如果你希望加载一个预训练的模型,你将把参数初始化为预训练模型完成时的状态。也有可能即使是对于一个新模型,你也有一些除了随机之外的其他初始化规则。现在,我们将坚持使用随机初始化。接下来,我们有前向方法。当我们从头到尾通过模型传递数据时,这被称为前向传递。然而,就像其他一切一样,这并不是唯一的做事方式。你可以让数据回环并做其他有趣的事情。我们将保持通常的做法,执行一个常规的前向传递。
为了继续 Layer_Dense 类的代码,让我们添加权重和偏置的随机初始化:
import numpy as np
class Layer_Dense:
# Layer initialization
def __init__(self, n_inputs, n_neurons):
# Initialize weights and biases
self.weights = 0.01 * np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
# Forward pass
def forward(self, inputs):
# Calculate output values from inputs, weights and biases
pass # using pass statement as a placeholder
在这里,我们将权重设置为随机,偏置设置为0。请注意,我们将权重初始化为(输入,神经元),而不是(神经元,输入)。我们提前这样做,而不是每次执行前向传递时都转置,如上一章所解释的。为什么偏置为零?在特定情况下,例如当许多样本包含0值时,偏置可以确保神经元最初被激活。有时将偏置初始化为某个非零数可能是合适的,但偏置最常见的初始化是0。然而,在这些情况下,你可能会发现以另一种方式做事会成功。这将根据你的用例而有所不同,并且只是你在尝试改进结果时可以调整的许多事情之一。一个你可能想尝试其他方法的情况是所谓的死神经元。我们还没有在实践中讨论激活函数,但想象一下我们之前提到的阶跃函数:
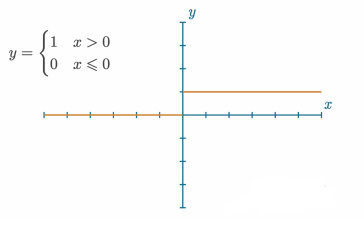
当权重 · 输入 + 偏置没有达到阶跃函数的阈值时,可能会导致神经元输出0。单独来看,这不是一个大问题,但如果每一个输入样本都导致这个神经元发生这种情况,就会成为一个问题(一旦我们讲解反向传播,这将变得清晰)。因此,这个神经元的0输出就成为另一个神经元的输入。任何与零相乘的权重都将是零。随着输出0的神经元数量增加,更多的输入将传递给下一个神经元这些0,使得网络基本上无法训练,或者“死亡”。
接下来,让我们更详细地探讨 np.random.randn 和 np.zeros 这些方法。这些方法是初始化数组的便捷方式。np.random.randn 产生一个均值为0和方差为1的高斯分布,这意味着它将生成以0为中心的随机数,正负都有,平均值接近0。一般来说,神经网络在 -1 到 +1 之间的值下工作最好,我们将在即将到来的章节中讨论这一点。因此,np.random.randn 生成围绕这些数字的值。我们将乘以 0.01 的高斯分布用于权重,以生成比较小的数值。否则,模型在训练过程中将需要更多时间来适应数据,因为开始的值与训练过程中进行的更新相比过大。这里的想法是用足够小的非零值开始一个模型,这些值不会影响训练。这样,我们就有一堆值可以开始使用,但希望没有太大或为零的值。如果你愿意,可以尝试除0.01之外的其他值。最后,np.random.randn 函数接受维度大小作为参数,并创建具有此形状的输出数组。
这里的权重将是第一维度的输入数量和第二维度的神经元数量。这类似于我们之前虚构的权重数组,只是随机生成的。每当有一个你不确定的函数或代码块时,你总是可以打印它出来。例如:
import numpy as np
import nnfs
nnfs.init()
random_test = np.random.randn(2,5)
zero_array = np.zeros((2,5))
print("random_test:", random_test)
print("zero_array:", zero_array)
>>>
random_test: [[ 1.7640524 0.4001572 0.978738 2.2408931 1.867558 ]
[-0.9772779 0.95008844 -0.1513572 -0.10321885 0.41059852]]
zero_array: [[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
np.random.randn(2,5)函数调用返回了一个2x5的数组(我们也可以说它的“形状是
(
2
,
5
)
(2,5)
(2,5)”),数据是从均值为0的高斯分布中随机抽样得到的。
在调用
np.random.randn(2, 5)时:参数 2 和 5 指定了生成数组的形状。 2 表示数组有两行。 5 表示数组有五列。
接下来,np.zeros 函数接受一个期望的数组形状作为参数,并返回一个填充了零的该形状数组。
我们将以行向量的形式初始化偏置,其形状为 ( 1 , n _ n e u r o n s ) (1, n\_{neurons}) (1,n_neurons),这将使我们能够在以后轻松地将其加到点积的结果上,无需进行转置等额外操作。
看一个我们方法初始化权重和偏置的例子:
import numpy as np
import nnfs
nnfs.init()
n_inputs = 2
n_neurons = 4
weights = 0.01 * np.random.randn(n_inputs, n_neurons)
biases = np.zeros((1, n_neurons))
print("weights:", weights)
print("biases:", biases)
>>>
weights: [[ 0.01764052 0.00400157 0.00978738 0.02240893]
[ 0.01867558 -0.00977278 0.00950088 -0.00151357]]
biases: [[0. 0. 0. 0.]]
接下来是我们的正演方法——我们需要用点积+偏差计算来更新它:
import numpy as np
class Layer_Dense:
# Layer initialization
def __init__(self, n_inputs, n_neurons):
# Initialize weights and biases
self.weights = 0.01 * np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
# Forward pass
def forward(self, inputs):
# Calculate output values from inputs, weights and biases
self.output = np.dot(inputs, self.weights) + self.biases
我们已经准备好使用这个新类来代替硬编码计算,因此让我们使用讨论过的数据集创建方法生成一些数据,然后使用我们的新层来执行前向传递:
import numpy as np
import nnfs
from nnfs.datasets import spiral_data
nnfs.init()
class Layer_Dense:
# Layer initialization
def __init__(self, n_inputs, n_neurons):
# Initialize weights and biases
self.weights = 0.01 * np.random.randn(n_inputs, n_neurons)
self.biases = np.zeros((1, n_neurons))
# Forward pass
def forward(self, inputs):
# Calculate output values from inputs, weights and biases
self.output = np.dot(inputs, self.weights) + self.biases
# Create dataset
X, y = spiral_data(samples=100, classes=3)
# Create Dense layer with 2 input features and 3 output values
dense1 = Layer_Dense(2, 3)
# Perform a forward pass of our training data through this layer
dense1.forward(X)
# Let's see output of the first few samples:
print(dense1.output[:5])
>>>
[[ 0.0000000e+00 0.0000000e+00 0.0000000e+00]
[-1.0475188e-04 1.1395361e-04 -4.7983500e-05]
[-2.7414842e-04 3.1729150e-04 -8.6921798e-05]
[-4.2188365e-04 5.2666257e-04 -5.5912682e-05]
[-5.7707680e-04 7.1401405e-04 -8.9430439e-05]]
在输出结果中,你可以看到我们有 5 行数据,每行有 3 个值。这 3 个值中的每一个都是dense1层中 3 个神经元输入每个样本后的值。好极了!我们有了一个神经元网络,所以我们的神经网络模型几乎名副其实了,但我们还缺少激活函数,所以接下来让我们完成激活函数!
本章的章节代码、更多资源和勘误表:https://nnfs.io/ch3
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 用 Python 从零开始创建神经网络(三):添加层级(Adding Layers)

发表评论 取消回复