文章目录
划分数据集
我们当然希望把所有数据都用来优化模型,然而数据是有限的,我们要追求最大化数据的效用,用最少的数据训练出最好的效果。
训练集和测试集
通常,我们会将数据集划分一部分出来,用来测试模型在未出现过的数据中的能力(泛化能力)。
训练误差
训练误差(Training Error)指模型在训练数据集上的预测误差。它衡量的是模型对已知数据的拟合程度。可以用来判断是否欠拟合
测试误差
测试误差(Test Error)是指模型在未见过的测试数据集上的预测误差。它衡量的是模型的泛化能力,即模型在新数据上的表现。可以用来判断是否过拟合
交叉验证测试集
交叉验证(Cross-Validation)是一种评估机器学习模型性能和选择模型参数的方法,通过将数据集分为多个子集来进行。交叉验证的主要目标是减少过拟合的风险,并提供模型在未知数据上的性能评估。其中常用的是一种称为K折交叉验证(K-fold Cross-Validation)的方法。
在K折交叉验证中,数据集被随机划分为K个子集(或称为“折”)。然后,模型被训练K次,每次使用K-1个子集作为训练数据,剩下的一个子集作为验证数据(或测试集)。这样,每个子集都会在验证过程中被用作一次测试集,而其余部分的子集会被用作训练集。模型的性能通常通过这K次训练和验证过程中的平均表现来评估。
优点:数据资源有效利用
缺点:算力资源要求较高
此外,对于某些数据(如时间序列数据),标准的K折交叉验证可能并不适用,因为它假设数据是独立同分布的,而时间序列数据通常具有顺序依赖性。
偏差与方差
偏差
偏差(Bias)是指模型预测值的期望与真实值之间的差异,高偏差模型在拟合训练数据时存在“欠拟合”
方差
方差(Variance)是模型预测值的差异程度,即预测值在不同数据集上的变动性。它可以用预测值的方差来表示。方差过大表示模型存在“过拟合”
表现基准
注意,模型具有较高的偏差或方差不一定意味着模型不好,通常会将人类做相同任务所产生的偏差与方差作为表现基准。此外,也可以在其他竞争算法的基础上作优化。
学习曲线
error - train set size
这里是选定模型后,增加数据集大小的情况。随着数据集大小增大,交叉验证误差减小,泛化能力增强;同时训练误差增大,这是因为固定的模型(如
f
w
,
b
(
x
)
=
w
1
x
+
w
2
x
2
+
b
f_{w,b}(x)=w_{1}x + w_{2}x^{2}+b
fw,b(x)=w1x+w2x2+b)会越来越难以完美拟合所有样本点。
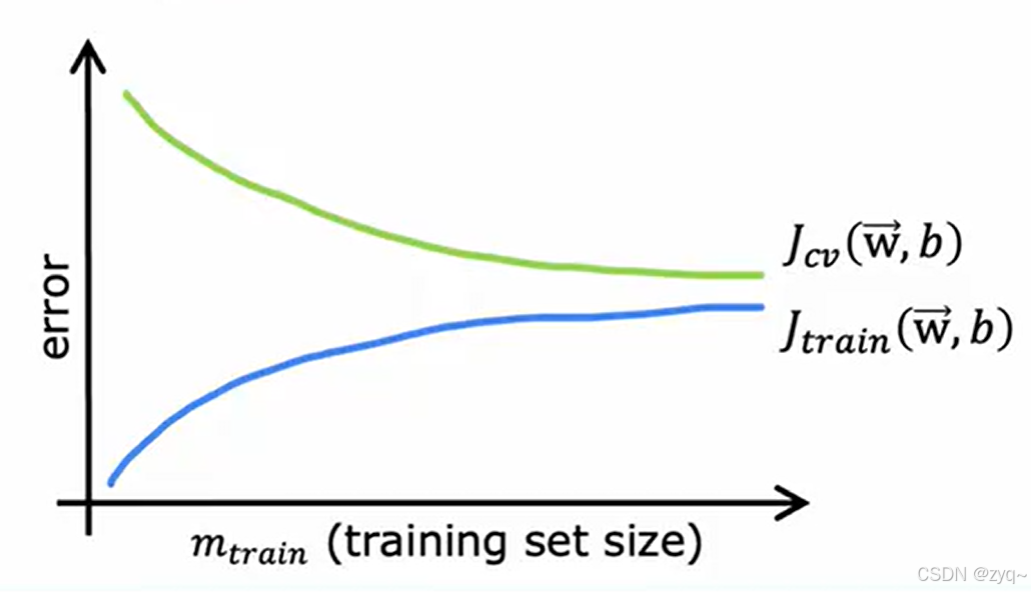
数据集足够大时,曲线会趋于平坦。这可能是由于当前的模型过于简单,无法继续拟合出更好的效果了,这时候就可以考虑更换或优化模型,而不仅仅是向它输入更多的数据。
而如果出现交叉验证误差远高于训练误差的情况,可能就是数据量不足或模型设计过于复杂。有时,正则化可以很好解决问题。
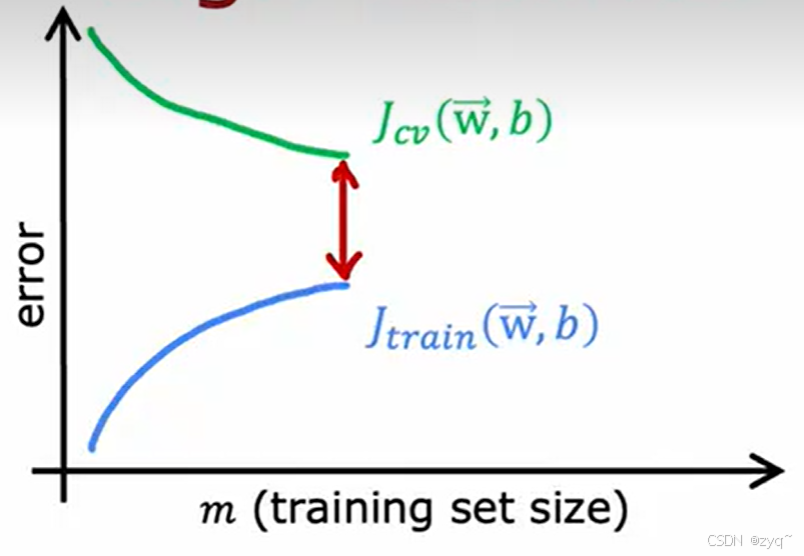
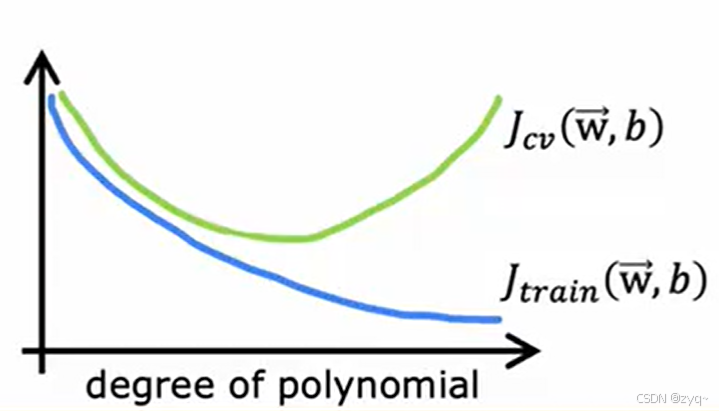
error - degree of polynomial
这是误差与模型复杂度的图线,这里采用多项式函数,所以复杂度就是多项式的维度。
数据增强
在数据不足或数据特征过于单一时,可以用一些手段从已有的数据中生成额外的数据,从而实现数据增强。比如,现在你有一张写有字母A的图片,你可以对它进行旋转、模糊、放缩等一系列操作,并保持标签 A A A不变,那么,你就成功将数据集扩充了若干倍,模型的泛化能力也能得到提升。类似的,我们还可以在音频中混入不相干的噪音,或在文本中加入少量不相干的字符,来人为地为数据集添加噪声。
迁移学习
迁移学习是指在机器学习领域中,利用一个神经网络在源任务上学习到的知识,帮助解决另一个相关但不同的目标任务。这一过程可以显著减少目标任务所需的训练时间、数据量和计算资源。
(1)微调(Fine-tuning):将预训练的神经网络模型应用到新的任务上,并对模型的部分或全部参数进行微调。通常,预训练模型是在大规模数据集(如ImageNet)上训练的,这些模型已经学习到了丰富的特征表示。在新的任务上,通过微调模型的最后几层或所有层,可以快速适应新的数据集。
比如,如果你想实现一个0~9数字识别的模型,而已经有了识别小猫小狗等各种类别的模型,可以只修改这个模型的输出层,来快速实现任务。
(2)特征提取:预训练模型的前几层通常学习到的是低级特征(如边缘、纹理等),这些特征在许多任务中都是通用的。因此,可以将这些层作为特征提取器,直接用于新的任务。
(3)冻结层:在新的任务中,可以冻结预训练模型的前几层,只训练新的分类层或其他特定任务的层,这样可以减少计算资源的消耗,同时利用预训练模型的泛化能力。
(4)…
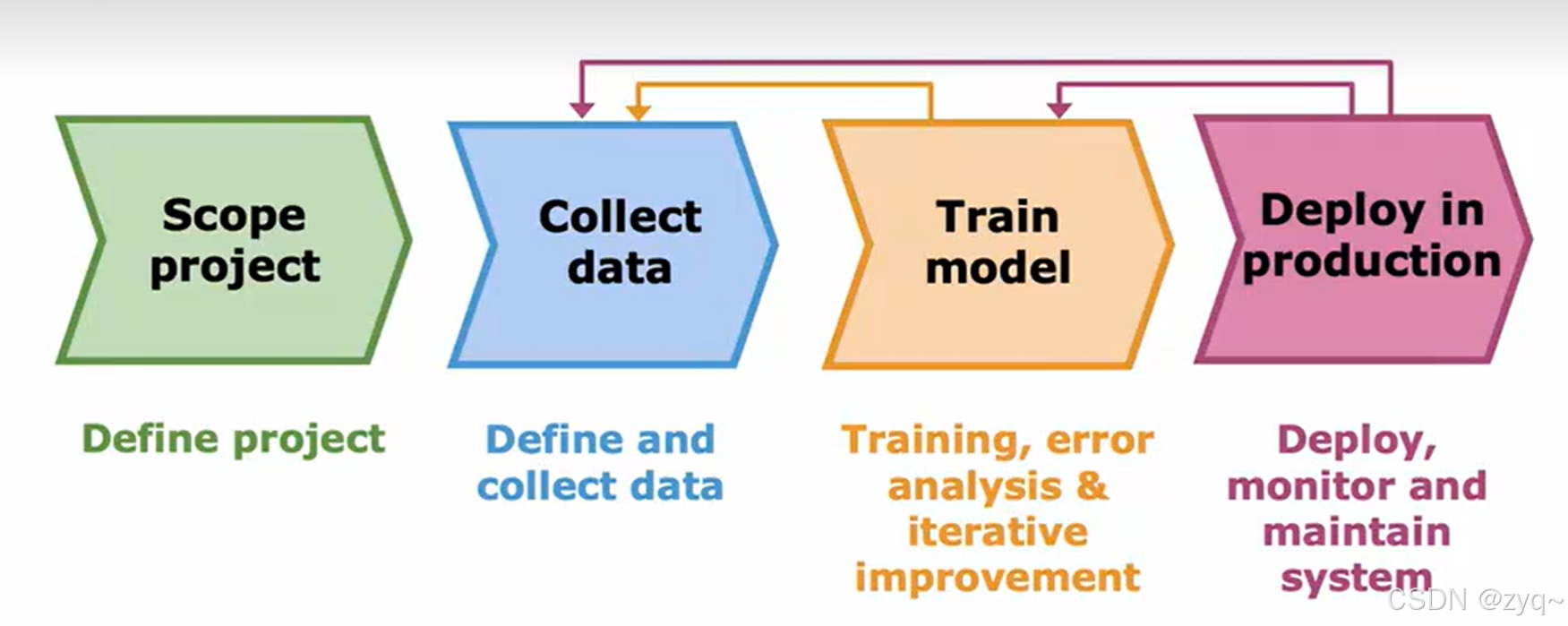
项目的完整周期
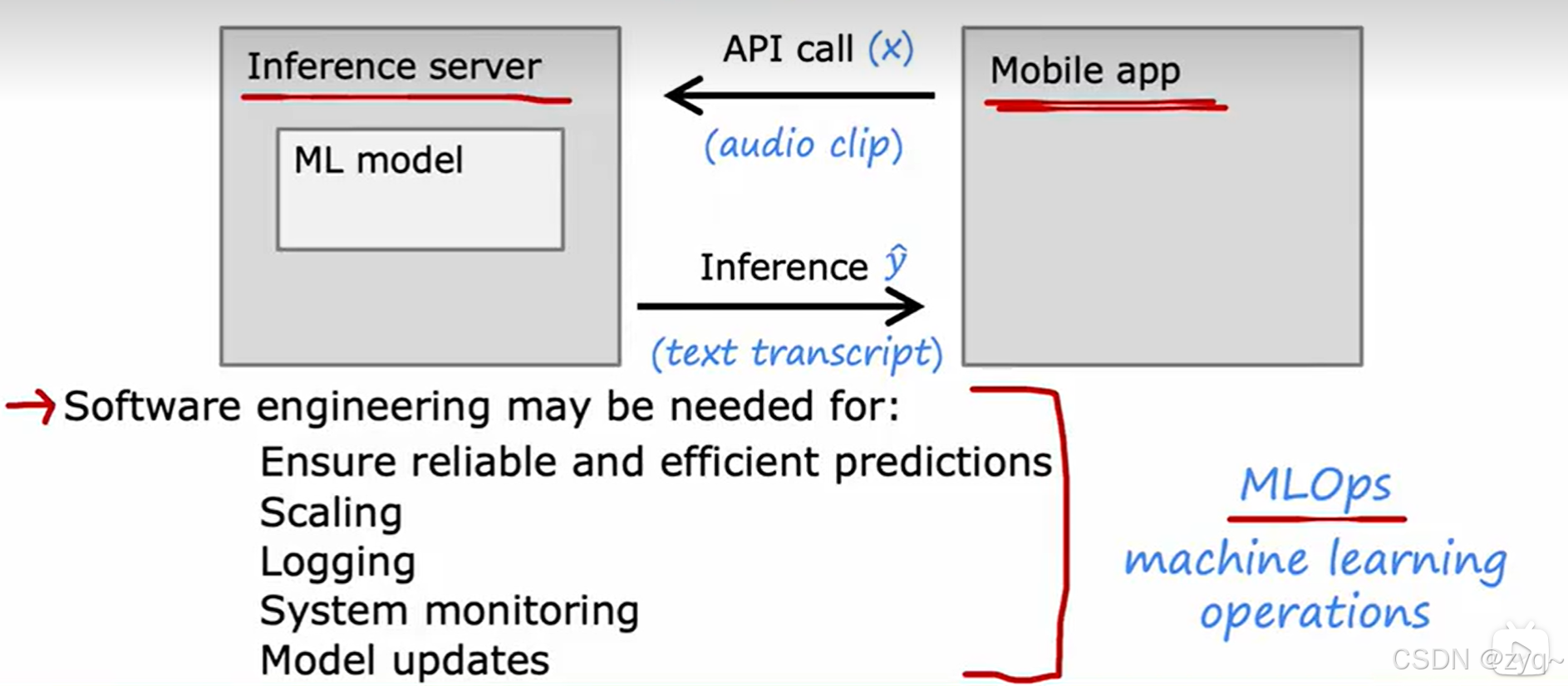
样本不平衡问题
当样本中某一标签数量远大于其余种类时,模型会表现出倾向该标签的特征,从而达到虚假的高准确率。
预测正确标记为
T
r
u
e
True
True,预测错误标记为
F
a
l
s
e
False
False,标签为1标记为
p
o
s
i
t
i
v
e
positive
positive,标签为0标记为
n
e
g
a
t
i
v
e
negative
negative。

精确率和召回率
则引入两个比值来评估这个模型:
(1)精确率:
P
o
c
i
s
i
o
n
=
T
r
u
e
p
o
s
i
t
i
v
e
s
P
r
e
d
i
c
t
e
d
p
o
s
i
t
i
v
e
s
Pocision = \frac{True \ positives} {Predicted \ positives}
Pocision=Predicted positivesTrue positives
(2)召回率:
R
e
c
a
l
l
=
T
r
u
e
p
o
s
i
t
i
v
e
s
A
c
t
r
u
a
l
p
o
s
i
t
i
v
e
s
Recall = \frac{True \ positives} {Actrual \ positives}
Recall=Actrual positivesTrue positives
高的精确率意味着模型误判率低,高的召回率意味着模型漏判率低
精确率与召回率的平衡
精确率和召回率之间通常存在权衡关系。提高精确率往往会降低召回率,反之亦然。
我们引入
F1 Score
=
2
×
Precision
×
Recall
Precision
+
Recall
\text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}
F1 Score=2×Precision+RecallPrecision×Recall在精确率和召回率之间寻求平衡,特别是在两者都重要的情况下。
更一般的则有
Fβ Score
=
(
1
+
β
2
)
×
Precision
×
Recall
(
β
2
×
Precision
)
+
Recall
\text{Fβ Score} = (1 + \beta^2) \times \frac{\text{Precision} \times \text{Recall}}{(\beta^2 \times \text{Precision}) + \text{Recall}}
Fβ Score=(1+β2)×(β2×Precision)+RecallPrecision×Recall
(1)当
β
=
1
β=1
β=1 时,
Fβ Score
\text{Fβ Score}
Fβ Score等同于
F1 Score
\text{F1 Score}
F1 Score,可以根据需求灵活调整参数
β
β
β。
(2)当
β
<
1
β<1
β<1 时,精确率的权重更高。
(3)当
β
>
1
β>1
β>1 时,召回率的权重更高。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【自学笔记】神经网络(2) -- 模型评估和优化

发表评论 取消回复