目录
假如遇到kafka崩了,你重启kafka之后,想要继续消费,应该怎么办?
- 首先确定要消费的主题是哪几个
- 其次使用命令或者其他的组件查看 __consumer_offset 主题下的偏移量信息,找到我们关心的主题在崩溃之前消费到了哪里。
- 最后使用 java 代码,里面有一个非常重要的方法 seek,指定需要消费的主题,分区以及偏移量,就可以继续消费了。
下面是解决这个问题的具体步骤!!!
一、怎么寻找我们关心的主题在崩溃之前消费到了哪里?
因为__consumer_offset 主题下记录了主题的偏移量信息,所以提交offset之后,消费__consumer_offset 主题便可查看所有主题的偏移量信息
1、一个问题:
__consumer_offset 主题下的数据是不能查看的,怎么解决?
解决方案:
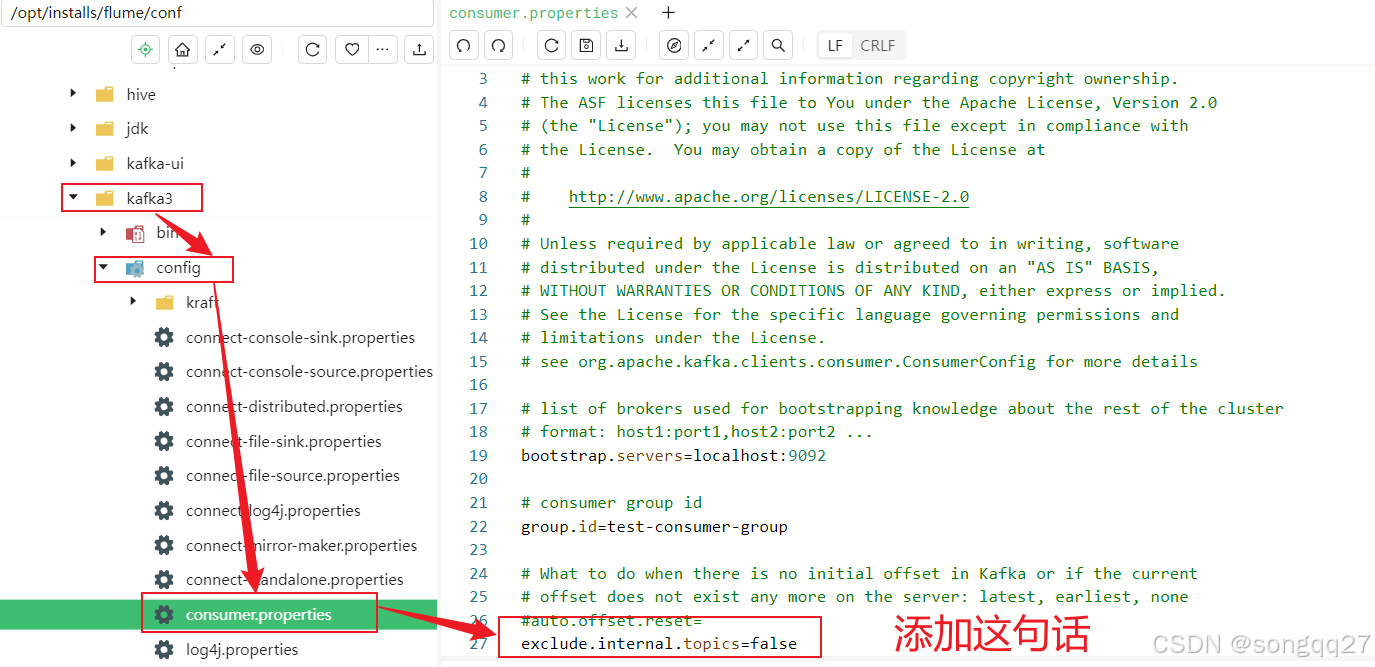
在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false。然后分发一下
分发:(这里我使用了脚本)
xsync.sh /opt/installs/kafka3/config/consumer.properties注意:修改之前要先关闭kafka和zookeeper,修改完毕后再开启!
说明:默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false。如果不修改是无法查看offset的值的,因为这些都是加密数据。
2、查看消费者消费主题__consumer_offsets
kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server bigdata01:9092 --consumer.config /opt/installs/kafka3/config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" 查询结果如下:
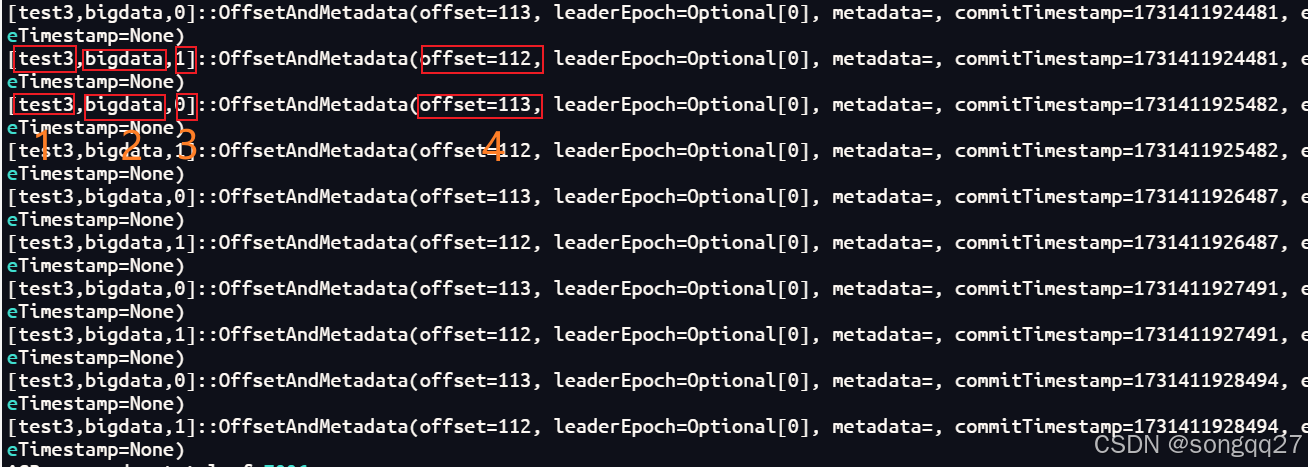
图中:1是消费者组名;2是Topic主题名;3是分区;4是偏移量,说明该主题崩溃前消费到了这里
此时便查询到了偏移量信息!!!
3、一个重要前提:消费时要提交offset
能查询到偏移量的前提是消费时要自动提交 offset(默认开启)或者手动提交 offset
一般不用管,因为自动提交会默认开启!!!
二、指定 Offset 消费
kafka提供了seek方法,可以让我们从分区的固定位置开始消费。
seek (TopicPartition Partition,offset offset):指定分区和偏移量
package com.bigdata._03offsetTest;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.Set;
public class _03CustomConsumerSeek {
public static void main(String[] args) {
Properties properties = new Properties();
//连接kafka setProperty和put都行
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
// 字段反序列化 key 和 value
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test5");
// 是否自动提交 offset 通过这个字段设置
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 消费者消费的是kafka集群的数据,消费哪个主题的数据呢?
List<String> topics = new ArrayList<>();
topics.add("bigdata");// list可以设置多个主题的名称
kafkaConsumer.subscribe(topics);
// 执行计划
// 此时的消费计划是空的,因为没有时间生成
Set<TopicPartition> assignment = kafkaConsumer.assignment();
while(assignment.size() == 0){
// 这个本身是拉取数据的代码,此处可以帮助快速构建分区方案出来
kafkaConsumer.poll(Duration.ofSeconds(1));
// 一直获取它的分区方案,什么时候有了,就什么时候跳出这个循环
assignment = kafkaConsumer.assignment();
}
// 获取分区0的offset =100 以后的数据
kafkaConsumer.seek(new TopicPartition("bigdata",0),100);
// 因为消费者是不停的消费,所以是while true
while(true){
// 每隔一秒钟,从kafka 集群中拉取一次数据,有可能拉取多条数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
// 循环打印每一条数据
for (ConsumerRecord record:records) {
// 打印一条数据
System.out.println(record);
// 打印数据中的值
System.out.println(record.value());
}
}
}
}
执行这个java代码就可以从精确的指定位置继续消费了!!!
结果如下:
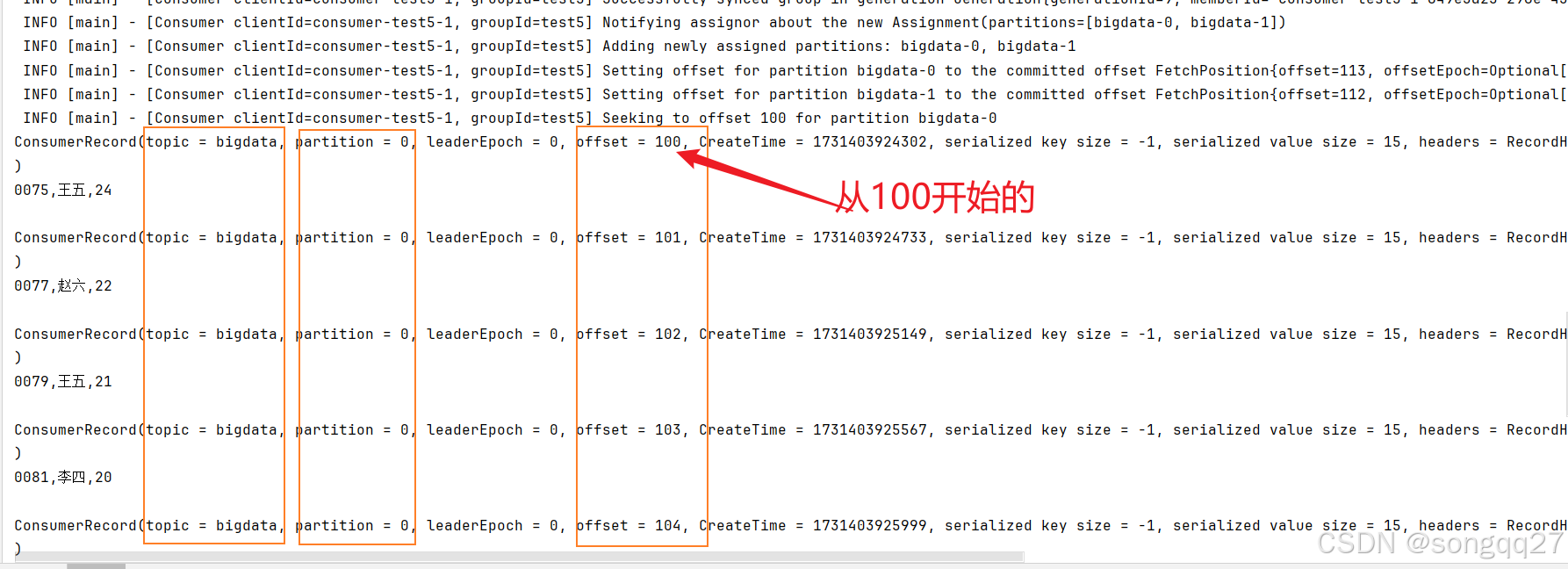
从上图可以看出,确实是从指定的主题、分区、偏移量开始消费的!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【快速解决】kafka崩了,重启之后,想继续消费,怎么做?

发表评论 取消回复