YashanDB 对象管理(进阶篇)
表管理
表是YashanDB中数据存储基本单元。每个表都是由列和行组成的。
创建表时,需要指定表类型。
表上可以有约束用于确保数据的有效性
表的存储结构
- 存储结构-Segment
表 ——> 表段
索引 ——> 索引段
- 延迟段的创建
USER_TABLES
USER_SEGMENTS
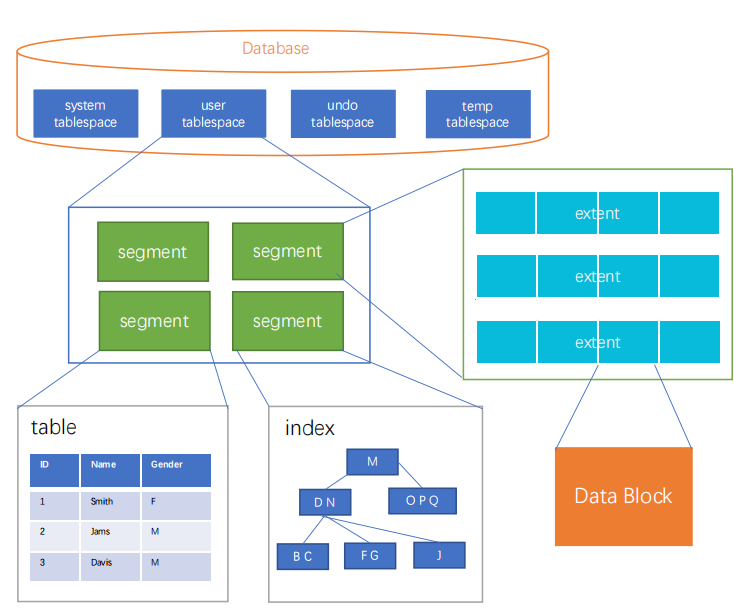
- ROWID
ROWID的特性
是一个伪列,用来确认表中行的唯一性。
存储需要16 字节。
可以作为列字段来使用,但必须被显式指定,比如通过SELECT *语句无法查询到ROWID的值。
SQL> select * from area;
01 华东 Shanghai
SQL> selet rowid, * from area;
2310:4:0:156:0 01 华东 Shanghai
ROWID的数据格式为:dataoid:spaceId:fileId:blockId:dir
dataoid:data object id,行所在的Segment的ID,该值可从user_objects等视图中查询获得。
spaceId:space id,行所在的表空间的ID,该值可从v$tablespace等视图中查询获得。
fileId:file id,行所在数据文件在对应表空间中的数据文件ID,该值可从v$datafile等视图中查询获得。
blockId:block id,行所在数据块在对应文件中的块ID。
dir:dir,行在数据块上的槽位。

存储参数和属性
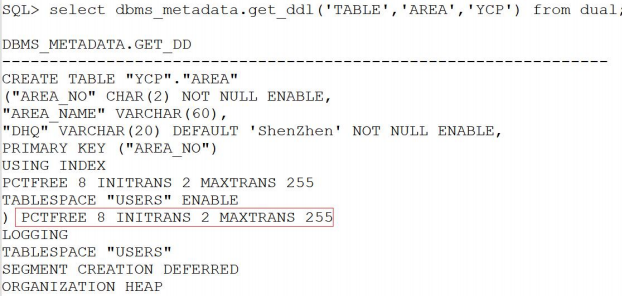
- DB_BLOCK_SIZE:数据块的大小。默认8K。建库之后不可修改。
SQL> show parameter db_block_size;
8192
- PCTFREE|PCTUSED|INITRANS|MAXTRANS
PCTFREE:表示数据块为数据库对象进行UPDATE保留的空间百分比,当可用空间低于该百分比时无法进行INSERT,只能进行UPDATE。默认是8。
PCTUSED:表示数据块为数据库对象保留的最小已用空间百分比,当数据所占空间低于该百分比时可进行INSERT。默认为NULL。
INITRANS:表示每个数据块中初始并发事务项的数量。默认为2。
MAXTRANS:表示每个数据块中并发事务项数量的最大值。默认为255。
大对象类型
LOB大对象型用于在数据库中存储较大二进制或较大文本的可变长度数据。
YashanDB的LOB类型包括 BLOB(Binary Large Object)和CLOB(Character Large Object)。
YashanDB对大对象类型的存储包含行内存储和行外存储两种方式:
当一行的LOB列的数据小于4000字节时,LOB数据将存储在行内。
当超过4000字节时,LOB数据存入单独的大对象数据空间(可为其指定表空间),行内存储的则是指向LOB数据的指针。
- 大对象使用限制:
不能作为索引列
不能修改LOB列的数据类型
不能作为分区键
不能与其他数据类型进行四则运算和取余运算
BLOB
BLOB表示二进制大对象,例如照片、视频、音频等文件。
最大存储长度4G*DB_BLOCK_SIZE。
除与RAW类型的隐式数据转换外,该数据类型在SQL中不参与其他任何类型转换及运算。
RAW类型是一种与VARCHAR类似的可变长度数据类型,可以表述二进制数据或者字节字符串。
RAW最大8000字节。
定义格式为RAW(Size),Size表示最大字节长度。
可以通过DBMS_LOB.COMPARE实现与BLOB/RAW类型数据的比较。
- 案例:插入图片
创建测试表
大对象类型
CREATE TABLE customer_img (id INT, logo BLOB);
java代码
大对象类型
1.图片路径
FileInputStream fileInputStream = new FileInputStream( "C:\\Users\\limy\\Desktop\\scripts\\logo.png" );
2.连接信息
String url = " jdbc : yasdb: / /192.168.3.186:1688/ yasdb" ;
String user = " ycp" ;
String pas sword = " ycp" ;
编译&执行
javac . \Yashan_ image. java
java - cp " . ;C: \User s \ l imy \Desktop\ s c ript s \ yashandb- jdbc -1.4.4. jar " Yashan_ image
查询
SELECT * FROM customer_img;
CLOB
CLOB表示可变长度文本,与VARCHAR类型类似,而VARCHAR类型的最大存储规格为8000字节。
最大存储长度4G*DB_BLOCK_SIZE。
可以通过DBMS_LOB.COMPARE实现CLOB与CLOB/CHAR/VARCHAR类型数据的比较。
CLOB类型支持大部分字符型函数,也可以在执行数据转换后参与运算。
案例:CLOB数据参与字符型运算
CREATE TABLE customer_intro (id INT, intro CLOB);
INSERT INTO customer_intro VALUES (1, 'It gives me great pleasure to introduce our company.');
SELECT SUBSTRING(intro, 3,5) FROM customer_intro WHERE id = 1;
give
高级包DBMS_LOB
DBMS_LOB包提供了一组内置的函数,用于LOB类型(或可与LOB进行隐式转换的类型)相关的运算。
- GET_LENGTH
用于获取指定LOB数据的长度,返回一个BIGINT类型的数值。
输入参数为BLOB/RAW类型时,函数返回的是按字节的长度;输入参数为CLOB/CHAR/VARCHAR时,函数返回的是按字符的长度。
--创建测试表t_lob并插入数据
create table t_lob (a varchar(100),b blob,c clob);
insert into t_lob values ('aaa','aaa','aaa');
--查询
select dbms_lob.get_length(b) as b_len,dbms_lob.get_length(c) as c_len from t_lob;
2 3
DBMS_LOB包提供了一组内置的函数,用于LOB类型(或可与LOB进行隐式转换的类型)相关的运算。
- COMPARE
用于比较两个LOB数据的大小,返回一个值为0、-1或者1的INTEGER类型数据。
DBMS_ LOB.COMPARE
( LOB_1, LOB_2,AMOUNT,OFFSET_1,OFFSET_2)
LOB_1:用于比较的第一个LOB数据,类型可以为BLOB/CLOB/CHAR/VARCHAR/RAW。
LOB_2:用于比较的第二个LOB数据,类型可以为BLOB/CLOB/CHAR/VARCHAR/RAW。
AMOUNT:用于比较的数据长度,函数从偏移位置开始获取该长度的字节数(对于BLOB/RAW)或字符数(对于CLOB/CHAR/VARCHAR)进行比较。缺省取LOB_1与LOB_2数据长度的较大值。
OFFSET_1:LOB_1用于比较的偏移量。缺省为1,即从第1个字节(对于BLOB/RAW)或字符(对于CLOB/CHAR/VARCHAR)开始获取AMOUNT长度的数据进行比较。
OFFSET_2: LOB_2用于比较的偏移量。缺省为1,即从第1个字节(对于BLOB/RAW)或字符(对于CLOB/CHAR/VARCHAR)开始获取AMOUNT长度的数据进行比较。
索引管理
Ø 索引是与表关联的可选数据库对象。
Ø 索引是用来快速访问数据的一种数据库对象。
Ø 可以在表的一个列或者多个列创建索引。
Ø 索引会占用存储空间。
索引类型
B-Tree索引
-
l默认的索引类型。
-
可以是单列索引,也可以是多列(组合索引)。组合索引最多可以包含32列。
-
降序索引
DESC代表降序,ASC 代表升序。默认是升序索引 。
反向索引
-
REVERSE代表反向,NOREVERSE代表非反向。默认是NOREVERSE。
-
在存入数据时反转每个索引键的字节。
-
优缺点
优点:降低索引叶子块的争用问题,提升系统性能。
缺点:对于范围检索,例如:between,>,<时,反向索引无法引用,进而导致全表扫面的产生,降低系统性能。
- 应用场景
索引块成为热点块
函数索引
l基于表达式创建的索引。
USER_IND_EXPRESSIONS/USER_INDEXES
SQL> create index idx_name on area (length(area_name)) ;
#查看索引相关信息
SQL> select index_owner, index_name,table_name, column_expression from user_ind_expressions ;
YCP IDX_ NAME AREA length(area_name)
SQL> select table_name, index_name, index_type from user _indexes where index _name like '%NAME%' ;
AREA IDX_NAME FUNCTION-BASED NORMAL
SQL> set autotrace on; #开启autotrace
SQL> select length(area_name) from area;
SQL> alter index idx_name invisible; #设置索引不可见
索引扫描方式
索引全扫描 Index Full Scan
需要扫描目标索引的所有叶子块。
执行结果是有序的。
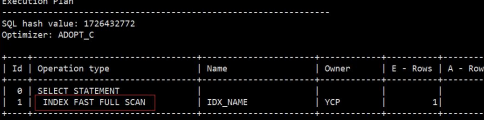
索引快速全扫描 Index Fast Full Scan
-
需要扫描目标索引的所有叶子块。
-
与索引全扫描的区别:
可以使用多块读,也可以并行执行。
执行结果不一定是有序的。
索引唯一扫描 Index Unique Scan
是针对唯一索引(UNIQUE INDEX)的扫描,它仅仅适用于where条件里是等值查询的目标sql。
返回的结果至多只有一条。
索引范围扫描 Index Range Scan
如果是唯一索引,where条件一定是范围查询(BETWEEN…AND,大于,小于等)。
如果是非唯一索引,where条件没有限制(可以是等值,也可是是范围查询)。
返回结果可以是多条。
索引跳跃扫描 Index Skip Scan
组合索引。
where条件中没有对目标索引前导列制定查询条件但是又对该索引非前导列指定了查询条件。
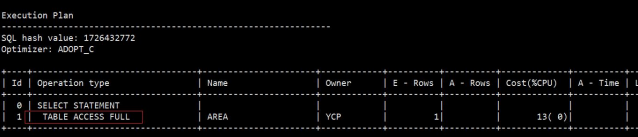
数据库是怎么通过索引查询到表数据的?
select area_name from area where area_no=‘01’;
构造测试环境
#建表
CREATE TABLE area
(area_no CHAR(2) NOT NULL PRIMARY KEY,
area_name VARCHAR2(60),
DHQ VARCHAR2(20) DEFAULT 'ShenZhen' NOT NULL );
\#插入数据
INSERT INTO area VALUES ('01' , '华东' , 'Shanghai ');
INSERT INTO area VALUES ('02' , '华西' , 'Chengdu');
INSERT INTO area VALUES ('03' , '华南' , 'Guangzhou');
INSERT INTO area VALUES ('04' , '华北' , 'Bei jing');
INSERT INTO area VALUES ('05' , '华中' , 'Wuhan');
commit;
分区管理
分区概述
-
在YashanDB中,分区通常是指将非常大的表和索引分解为更小的、更易于管理的部分。
-
每个分区都必须具有相同的逻辑属性,如列名、数据类型和约束。每个分区都是一个独立的对象,具有它自己的名称和可选择的它自己的存储特性。
-
可以创建分区表和分区索引。但不能为临时表创建分区。
-
常见分区表的应用场景
大数据量的表
查询特征非常明显的表
需要维护历史数据的表
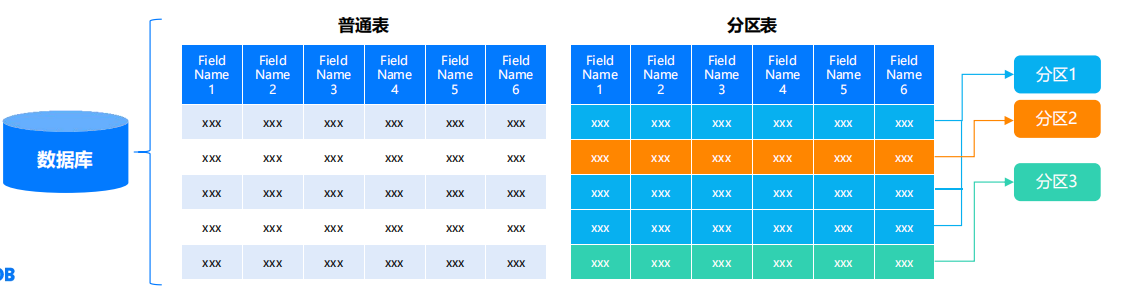
- 分区键
分区键是一组一个或多个列,它决定分区表中的每行应该所在的分区。每一行都被明确地分配给一个分区。
- 分区策略
YashanDB提供了几种分区策略,来控制数据库如何将数据放到分区中。基本的策略是范围(range)、列表(list)和哈希(hash)分区。
范围分区
在范围分区中,数据库根据分区键的值的范围将行映射到分区。
范围分区键值确定指定分区的上限值(但是不包含该上限值)。
在定义了MAXVALUE的分区后,不能再增加新的分区。
分区键必须是字符串、时间和数值类型
假设使用以下SQL语句将orders_info创建为分区表,其中id列作为分区键:
#范围分区
create user ycp identified by ycp;
grant dba to ycp;
conn ycp/ycp;
CREATE TABLE sales_info_range
(year CHAR(4) NOT NULL,
month CHAR(2) NOT NULL,
branch CHAR(4),
product CHAR(5),
quantity NUMBER DEFAULT 0 NOT NULL,
amount NUMBER(10,2) DEFAULT 0 NOT NULL,
salsperson CHAR(10))
PARTITION BY RANGE(year)
(PARTITION p_sales_info_range_1 VALUES LESS THAN('2011'),
PARTITION p_sales_info_range_2 VALUES LESS THAN('2021'),
PARTITION p_sales_info_range_3 VALUES LESS THAN('2031'),
PARTITION p_sales_info_range_4 VALUES LESS THAN(MAXVALUE)
);
insert into SALES_INFO_RANGE(year,month) values ('2011','1');
insert into SALES_INFO_RANGE(year,month) values ('2020','1');
insert into SALES_INFO_RANGE(year,month) values ('2021','1');
insert into SALES_INFO_RANGE(year,month) values ('2040','1');
EXEC DBMS_STATS.GATHER_TABLE_STATS('YCP', 'SALES_INFO_RANGE','', 0.2, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'AUTO', TRUE);
select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='SALES_INFO_RANGE';
----
insert into SALES_INFO_RANGE(year,month) values ('aa','1');
insert into SALES_INFO_RANGE(year,month) values ('!','1');
间隔分区
间隔分区是范围分区的扩展。
间隔分区键值确定指定分区的上限值(但是不包含该上限值)。
如果插入的数据超出现有范围分区,则数据库会自动创建指定间隔的分区。新分区由系统自动命名。
与普通范围分区的差异
• 间隔分区分区键只能是时间或者数值类型
• 间隔分区新增分区由系统自动完成,不能手动添加新分区
#间隔分区
CREATE TABLE orders_info (
order_no CHAR(14) NOT NULL,
order_desc VARCHAR2(100),
area CHAR(2),
branch CHAR(4),
order_date DATE DEFAULT SYSDATE NOT NULL,
salesperson CHAR(10),
id NUMBER
)
PARTITION BY RANGE (id )
INTERVAL (1000)
(PARTITION p_orders_info_1 VALUES LESS THAN (500),
PARTITION p_orders_info_2 VALUES LESS THAN (1000)
);
insert into ORDERS_INFO values ('20230811123456','测试1','02','aaaa',sysdate,'Tom',1500);
EXEC DBMS_STATS.GATHER_TABLE_STATS('YCP', 'ORDERS_INFO','', 0.2, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'AUTO', TRUE);
select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='ORDERS_INFO';
列表分区
在列表分区中,数据库使用一个离散值的列表作为每个分区的分区键。
#列表分区
CREATE TABLE list_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY LIST (channel_id)
( PARTITION even_channels VALUES ('2','4'),
PARTITION odd_channels VALUES ('3','9')
);
INSERT INTO LIST_SALES VALUES (1,2,sysdate,'2',20,10,10.5);
select * from LIST_SALES;
EXEC DBMS_STATS.GATHER_TABLE_STATS('YCP', 'LIST_SALES','', 0.2, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 4, 'AUTO', TRUE);
select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='LIST_SALES';
哈希分区
在哈希分区中,数据库基于数据库应用于用户指定的分区键的哈希算法将行映射到分区。
不能手动指定该行要放置的分区。
#哈希分区
CREATE TABLE hash_sales
( prod_id NUMBER(6)
, cust_id NUMBER
, time_id DATE
, channel_id CHAR(1)
, promo_id NUMBER(6)
, quantity_sold NUMBER(3)
, amount_sold NUMBER(10,2)
)
PARTITION BY HASH (prod_id)
PARTITIONS 4;
select PARTITION_NAME,num_rows from user_tab_partitions where table_name ='HASH_SALES';
几种分区的常用场景

添加分区
范围分区
增加范围类型的分区,只能在当前最大分区界值之上建立分区,如表的最大分区界值被设为MAXVALUE,则不允许增加分区。
可以分区指定所属表空间(缺省为表所属表空间)。
可以定义PCTFREE/PCTUSED/INITRANS/MAXTRANS等属性。
间隔分区,其分区由系统自动维护,不能通过SQL语句添加分区。
假如sales_info_range为一张范围分区表,已有p_sales_info_range_1(VALUES LESS THAN(‘2011’))、
p_sales_info_range_2(VALUES LESS THAN(‘2021’))和p_sales_info_range_3(VALUES LESSTHAN(‘2031’))三个分区。添加第四个分区:
ALTER TABLE sales_info_range ADD PARTITION p_sales_info_range_4 VALUES LESSTHAN('2041');
列表分区
可以指定所属表空间(缺省为表所属表空间)。
可以定义PCTFREE/PCTUSED/INITRANS/MAXTRANS等属性。
ALTER TABLE list_sales ADD PARTITION p_list_sales_3 VALUES (('5'),('7')) tablespace yashan_idx ;
l哈希分区
可以分区指定所属表空间(缺省为表所属表空间)。
新增分区的PCTFREE/PCTUSED/INITRANS/MAXTRANS等属性从表上继承,不允许指定。
ALTER TABLE hash_sales ADD PARTITION p_hash_sales_3;
删除分区
语法
ALTER TABLE table_name DROP PARTITION partition_name;
- 约束限制
同时删除多个分区用逗号(,)分隔。
删除分区时,不支持将表上的所有分区都删除。
不支持删除哈希类型分区。
在表的分区被删除时,对应的索引分区也会被删除。
对于范围类型的分区,删除分区后其分区界值将会向相邻大一级分区合并,这样符合此被删除分区界值范围的新增表数据将进入相邻分区中,如不存在相邻大一级分区则数据无法再插入成功。
分区表相关系统视图
Ø DBA_TAB_PARTITIONS
#查看视图
select table_name ,tablespace_name ,partition_name ,num_rows,high_value from user_tab_partitions where table_name='SALES_INFO_RANGE';
SALES_ INFO_RANGE USERS P_SALES_INFO_RANGE_4 2 MAXVALUE
SALES_ INFO_RANGE USERS P_SALES_INFO_RANGE_3 1 '2031'
SALES_ INFO_RANGE USERS P_SALES_INFO_RANGE_2 1 '2021'
SALES_ INFO_RANGE USERS P_SALES_INFO_RANGE_1 1 '2011'
序列管理
序列是一种数据库对象,它可以生成一组数值。
通常用作主键和其他唯一标识符。
序列号生成器的数据类型只能为整数。
YashanDB支持升序序列号生成器(即生成的序列号为正数)和降序序列号生成器(即生成的序列号为负数)
对于升序序列号生成器,生成的序列号不能小于1;对于降序序列号生成器,生成的序列号不能大于-1。
创建序列
SQL> CREATE SEQUENCE seq_yashan1;
SQL> SELECT seq_yashan1.NEXTVAL FROM DUAL ;
1
SQL> SELECT seq_ yashan1.NEXTVAL FROM DUAL ;
2
SQL> CREATE SEQUENCE seq_yashan2 INCREMENT BY 10 -- 可循环创建
MAXVALUE 20 CYCLE NOCACHE;
SQL> SELECT seq_ yashan2.NEXTVAL FROM DUAL ;
1
SQL> SELECT seq_ yashan2.NEXTVAL FROM DUAL ;
11
SQL> SELECT seq_ yashan2.NEXTVAL FROM DUAL ;
1
修改序列语法
ALTER SEQUENCE用于修改序列号生成器的各项参数。
规则同CREATE SEQUENCE。
SQL> alter sequence seq_ yashan2 nocycle;
SQL> SELECT seq_ yashan2.NEXTVAL FROM DUAL ;
SQL> SELECT seq_ yashan2.NEXTVAL FROM DUAL ;
YAS-02035 sequence SEQ _YASHAN2.NEXTVAL ex ceeds MAXVALUE and cannot be instantiated
SQL> alter sequence seq_ yashan2 nomax value;
SQL> SELECT seq_ yashan2.NEXTVAL FROM DUAL ;
21
删除序列
语法
DROP SEQUENCE [ schema.] sequence_name;
示例
DROP SEQUENCE seq_yashan1;
同义词管理
- 概述
同义词是数据库对象的别名。例如,可以为表、视图、序列、其他同义词创建一个同义词。因为同义词只是一个别名,所以它除了在数据字典中的定义外,不需要其他存储空间。
- 作用
多用户协同开发中,屏蔽对象的名称及其属主。
简化对象名称。
- 分类
私有同义词:位于特定用户的模式中,该用户可以控制其对他人的可用性。
公共同义词:每个数据库用户都可以访问。
创建同义词
CREATE PUBLIC SYNONYM sy_seq_ yashan1 FOR seq_ yashan1;
CREATE PUBLIC SYNONYM sales.sy_seq_yashan1 FOR seq_ yashan1; --报错YAS-04115CREATE SYNONYM sales.sy_seq_ yashan1 FOR seq_ yashan1;
查看同义词信息
SQL> select owner,objec t_name,objec t_type from dba_objects where object_type='SYNONYM' and
object_name='SY_SEQ _YASHAN1' ;
删除同义词
同义词管理
DROP [PUBLIC] SYNONYM synonym_name;
public:删除一个公共同义词时,必须指定public。
synonym_name:指定要删除的同义词的名称。
同义词相关视图
select owner, synonym_name,table_owner,table_name from dba_synonyms where owner='SALES' ;
案例:删除同义词引用的对象
SQL> select seq_ yashan1.nextval from dual ;
2
SQL> drop sequence seq_ yashan1;
SQL> select sy_seq_ yashan1.nextval from dual ;
YAS-02155 synonym trans lation is nolonger valid
SQL> create sequence seq_yashan1;
Succeed.
SQL> select sy_seq_yashan1.nextval from dual ;
1
存储过程管理
- PL/SQL概述
PL/SQL全称为Procedural Language/Structured Query Language,过程化SQL语言,它是一种建立在普通SQL语言之上的编程语言。
PL/SQL 程序由三个块组成,即声明部分(可选)、执行部分、异常处理部分(可选)。
DECLARE
/* 声明部分: 在此声明 PL/SQL 用到的变量,类型及游标,以及局部的存储过程和函数 */
BEGIN
/* 执行部分: 过程及 SQL 语句 , 即程序的主要部分 */
EXCEPTION
/* 执行异常部分: 错误处理 */
END;
- PL/SQL 可以分为三类
匿名块:动态构造,只能执行一次。
子程序:存储在数据库中的存储过程、函数及包等。
触发器:当数据库发生操作时,会触发一些事件,从而自动执行相应的程序。
存储过程概述
存储过程是数据库里的一种PL/SQL对象。
存储过程是一种预定义的可重用的程序。
存储过程是由一组SQL语句和控制流程语句的组合,可以接受参数输入,并返回结果。
存储过程通常用于执行特定的数据库操作或任务,比如插入、删除、更新数据以及执行复杂的业务逻辑。
存储过程的优点:
可重用性:存储过程是预定义的,可以在多个应用程序或模块中重复使用,减少代码的复制和维护成本。
安全性:存储过程可以提供更好的安全措施,比如只允许授权用户执行存储过程,并且可以使用参数化查询来防止SQL注入。
提高性能:存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,减少编译语句所花的时间。
案例:存储过程的创建和调用
#存储过程
CREATE OR REPLACE PROCEDURE ya_proc(i INT) IS
BEGIN
CASE i
WHEN 1 THEN
DBMS_OUTPUT.PUT_LINE('the number is 1.');
WHEN 2 THEN
DBMS_OUTPUT.PUT_LINE('the number is 2.');
ELSE
DBMS_OUTPUT.PUT_LINE('a wrong number!');
END CASE;
END ;
/
-- SQL语句(CALL/EXEC)调用
SQL> set serveroutput on
SQL> EXEC ya_proc (1);
the number is 1.
SQL> CALL ya_proc (3);
a wrong number!
-- 过程体调用
BEGIN
ya_proc(1);
ya_proc(2);
ya_proc(3);
END;
/
重编译存储过程
ALTER PROCEDURE sales.ya_proc COMPILE;
删除存储过程
DROP PROCEDURE IF EXISTS ya_proc ;
视图DBA_PROCEDURES
SQL> SELECT object_name,object_type FROM dba_procedures WHERE owner='SALES' ;
自定义函数管理
自定义函数是数据库里的一种PL/SQL对象,简称UDF(User Defined Function)。
函数必须返回一个值,包含返回结果的类型。
通过return语句返回值。
函数体可以有多条return语句,但只能有一条被执行。
案例:创建函数&函数调用
#自定义函数
CREATE OR REPLACE FUNCTION ya_func(i INT) RETURN VARCHAR
IS
BEGIN
CASE i
WHEN 1 THEN
RETURN 'the number is 1.';
WHEN 2 THEN
RETURN 'the number is 2.';
ELSE
RETURN 'a wrong number!';
END CASE;
END ;
/
-- SQL语句调用
SQL> SELECT ya_func (3) FROM dual ;
-- 过程体调用
DECLARE
a VARCHAR(50);
b VARCHAR(50);
BEGIN
a := ya_func(1);
b := ya_func(2);
DBMS_OUTPUT.PUT_LINE(a||' '||b);
END;
/
重编译自定义函数
ALTER FUNCTION sales.ya_func COMPILE;
删除自定义函数
DROP FUNCTION IF EXISTS ya_func ;
视图DBA_PROCEDURES
SQL> SELECT object_name,object_type FROM DBA_PROCEDURES WHERE owner='SALES' AND object_type='UDF' ;
触发器管理
触发器(Trigger)是数据库里的一种PL/SQL对象。创建一个触发器即创建了一个可执行的过程体,但与存储过程和函数不同的是,触发器过程体不可以被用户显式调用,而是由系统依据某个事件来触发执行。
一个触发器包含如下要素:
触发操作:触发执行的内容,为一个过程体。
触发事件:可以由系统判断的触发过程体执行的事件,即对表的INSERT/UPDATE/DELETE等DML操作。 可以定义单个触发事件,也可以定义多个触发事件的组合 。
触发时机: 触发过程体执行的时间点,包括BEFORE(触发事件发生前执行)和AFTER(触发事件发生后执行)两种。
触发对象:触发事件所基于的对象,即某张表。
触发类型:包括语句级触发(触发事件发生时,执行一次过程体)和行级触发(触发事件发生时,对其影响的每一行数据均执行一次过程体)两种类型。
触发条件:对于行级触发器,可以由WHEN语句指定一个条件表达式,在触发事件发生且条件表达式结果为true时,过程体才会被执行。
创建trigger案例:使用trigger实现日志记录
#触发器
CREATE TABLE product(product_no CHAR(5) PRIMARY KEY,product_name VARCHAR2(30),cost NUMBER,price NUMBER); -- 创建日志表
CREATE TABLE product_log (product_no CHAR(5), update_date DATE,newprice NUMBER, oldprice NUMBER);
INSERT INTO product VALUES ('11002','product002',13,16);
-- 创建trigger
CREATE OR REPLACE TRIGGER tri_log_product
BEFORE
UPDATE
ON product
FOR EACH ROW
DECLARE
PRAGMA autonomous_transaction;
BEGIN
INSERT INTO product_log VALUES (:old.product_no, SYSDATE, :NEW.price, :old.price);
COMMIT;
END;
/
UPDATE product SET price=20 where product_no='11002';
SELECT price FROM product WHERE product_no=11002;
SELECT * FROM product_log WHERE product_no=11002;
修改触发器案例
显式重编译tri_log_product触发器
ALTER TRIGGER tri_log_product COMPILE;
禁用tri_log_product触发器
ALTER TRIGGER tri_log_product DISABLE;
查看tri_log_product触发器状态
SELECT trigger_name, s tatus FROM user_triggers ;
课后习题
1.判断题:分区表的每个分区可以具有不同的逻辑属性,如列名、数据类型和约束等。
参考答案:错误
2.多选题:YashanDB支持以下哪些分区方式(ABCD)
A.范围分区 B.间隔分区 C.列表分区 D.哈希分区
3.判断题:自定义函数必须要通过return返回值。
参考答案:正确
4.创建序列dept_id_seq,开始值为200,每次增长10,最大值为10000。
create sequence dept_id_seq start with 200 increment by 10 maxvalue 10000;
5.使用trigger和sequence实现表的主键自增,表结构可以参考 create table test (id number primary key, name varchar(50),age number);
参考答案:
#创建序列
create sequence seq_test_id ;
#创建触发器
create or replace trigger tri_test
before insert on test
for each row
begin
select seq_test_id.nextval into :new.id from dual;
end tri_test;
/
#测试插入
insert into test(name,age) values ('Skye','28');
select * from test;
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 第三章:YashanDB 对象管理(进阶篇)

发表评论 取消回复