【大语言模型】ACL2024论文-14 任务:不可能的语言模型
目录
任务:不可能的语言模型
摘要
本文探讨了大型语言模型(LLMs)是否能够学习人类认为可能和不可能的语言。尽管有观点认为LLMs无法区分这两者,但目前缺乏实验证据支持这一论断。研究者们开发了一系列不同复杂度的合成不可能语言,通过系统地改变英语数据的词序和语法规则来设计这些语言。这些语言构成了一个不可能性的连续体,从本质上不可能的语言(例如随机且不可逆的英语单词洗牌)到在语言学中常被认为不可能的语言(尤其是基于词数位置的规则)。研究者们报告了一系列评估,以测试GPT-2小型模型学习这些无可争议的不可能语言的能力,并在训练过程中的不同阶段进行这些评估,以比较每种语言的学习过程。核心发现是,与作为对照的英语相比,GPT-2在学习不可能的语言时遇到困难,挑战了核心主张。更重要的是,研究者们希望他们的方法能够开启一条富有成效的调查线,测试不同的LLM架构在各种不可能语言上的表现,以了解如何将LLM用作这些认知和类型学调查的工具。
研究背景
在自然语言处理(NLP)领域,大型语言模型(LLMs)如GPT-2、BERT等已经成为研究和应用的热点。这些模型通过在大量文本数据上进行预训练,能够捕捉到语言的复杂模式和结构,从而在各种NLP任务上取得了显著的性能。然而,关于LLMs是否能够学习人类认为不可能的语言,学术界一直存在争议。Chomsky等人认为LLMs无法区分可能和不可能的语言,这一观点对语言学方法论和LLMs作为稳健语言能力的基石的可行性具有重要影响。然而,这一观点缺乏广泛的正式分析和实验证据的支持。
问题与挑战
本研究面临的主要问题和挑战包括:
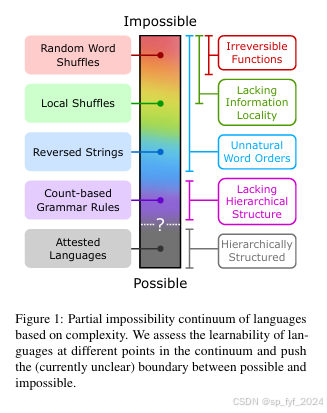
- 定义不可能的语言:在语言学中,对于什么是可能的语言,什么是不可能语言,缺乏共识。
- 设计实验:如何设计实验来测试LLMs学习不可能语言的能力。
- 评估模型性能:如何评估LLMs在这些不可能语言上的性能,并与学习自然语言的能力进行比较。
- 解释结果:如何解释模型在这些任务上的表现,以及这些表现对于理解LLMs的能力和局限性意味着什么。
如何解决
研究者们通过以下步骤来解决上述问题和挑战:
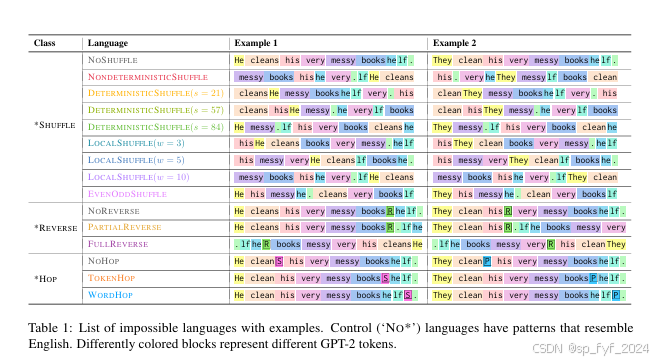
- 构建不可能的语言:通过系统地改变英语数据的词序和语法规则,创建了一系列不同复杂度的合成不可能语言。
- 训练和评估模型:使用GPT-2小型模型在这些不可能语言上进行训练,并在训练过程中的不同阶段评估模型的性能。
- 比较学习过程:比较模型在不同不可能语言上学习过程,以及与学习自然语言(英语)的对比。
- 分析和解释结果:深入分析实验结果,探讨LLMs在学习和理解不可能语言方面的能力和局限性。
创新点
本研究的创新点包括:
- 不可能语言的构建:提出了一种系统的方法来构建不同复杂度的不可能语言,为研究LLMs提供了新的实验平台。
- 多阶段评估:在训练过程中的不同阶段评估模型性能,提供了对模型学习动态的深入理解。
- 对比分析:将模型在不可能语言上的表现与自然语言进行对比,揭示了LLMs在处理不同类型语言时的差异。
- 认知和类型学研究:为使用LLMs作为工具进行认知和类型学研究提供了新的视角和方法。
算法模型
本研究使用的算法模型是GPT-2小型模型,这是一种基于Transformer架构的自回归语言模型。GPT-2通过在大量文本数据上进行预训练,学习语言的复杂模式和结构。在本研究中,研究者们使用GPT-2小型模型来学习构建的不可能语言,并在训练过程中的不同阶段评估模型的性能。
实验效果
实验结果表明,与作为对照的英语相比,GPT-2在学习不可能的语言时遇到困难。具体来说:
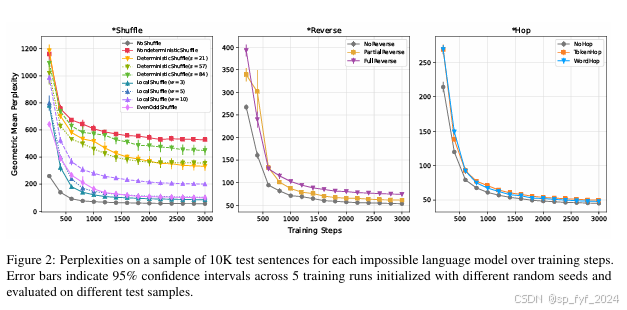
- 实验1:通过测试集的困惑度(perplexity)来评估模型学习效率,发现在可能语言上训练的模型比在不可能语言上训练的模型学习得更高效。
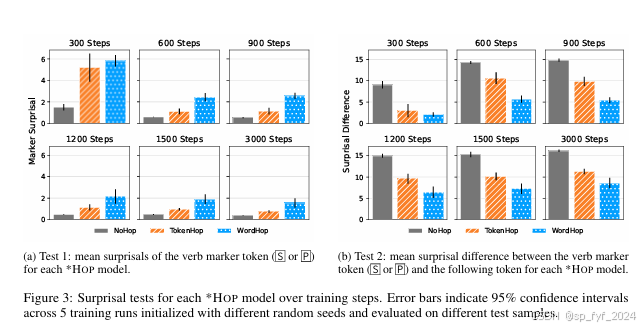
- 实验2:使用惊奇度(surprisal)比较来更仔细地检查表现出基于计数的动词标记规则的语言,发现在可能语言上训练的GPT-2对不合语法的构造更感到惊讶,表明模型更倾向于自然语法规则。
- 实验3:通过因果抽象分析深入研究模型可能发展出的学习此类基于计数的语法规则的内部机制,发现模型发展出类似人类的解决方案来处理非人类语法模式。
这些结果挑战了Chomsky等人的观点,即LLMs无法区分可能和不可能的语言,并为进一步讨论LLMs作为语言学习模型以及人类语言的可能/不可能区别铺平了道路。
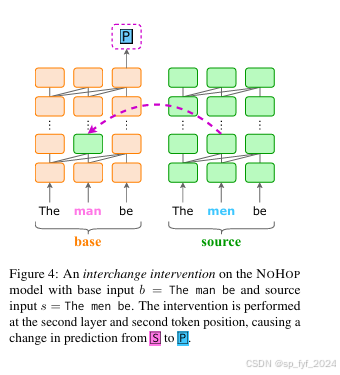
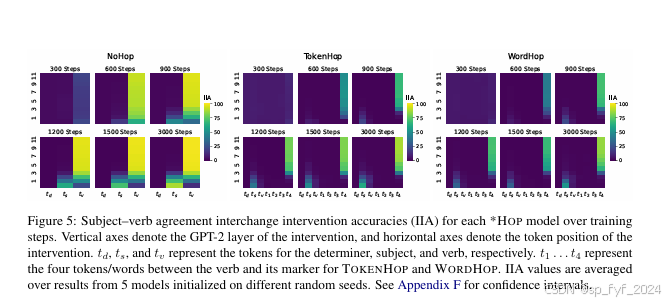
重要数据与结论
实验中的关键数据和结论包括:
- 困惑度:在可能语言上训练的模型比在不可能语言上训练的模型具有更低的困惑度,表明前者学习得更高效。
- 惊奇度比较:在可能语言上训练的GPT-2对不合语法的构造更感到惊讶,表明模型更倾向于自然语法规则。
- 因果抽象分析:模型发展出类似人类的解决方案来处理非人类语法模式,表明GPT-2能够学习并适应非自然的语言结构。
推荐阅读指数和推荐理由
4.5
后记
如果您对我的博客内容感兴趣,欢迎三连击 (***点赞、收藏和关注 ***)和留下您的评论,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【大语言模型】ACL2024论文-14 任务:不可能的语言模型

发表评论 取消回复