1.直接插入排序
基本思想:把待排序的数按照大小逐个插入到前面已经排序好的有序序列中,直到所有的都插入完为止,得到一个新的有序序列。
如图所示,当插入第i个(i>=1)元素的时候,前面的arr[0],arr[1]......arr[i-1]已经排好序,此时用arr[i]的元素与前面的元素进行比较,找到插入的位置将arr[i]插入,将原来的元素顺序后移。
void InsertSort(int* a, int n)//插入排序
{
// [0,end]区间有序,将a[end+1]的值插入
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])//a[end+1]<a[end]数据往后移 end向前走
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}直接插入排序的特性总结:
1.元素集合越接近有序,直接插入排序算法的时间效率越高
2.最坏时间复杂度:O(N^2)
最好时间复杂度:O(N)
3.空间复杂度:O(1)
4.稳定性:稳定
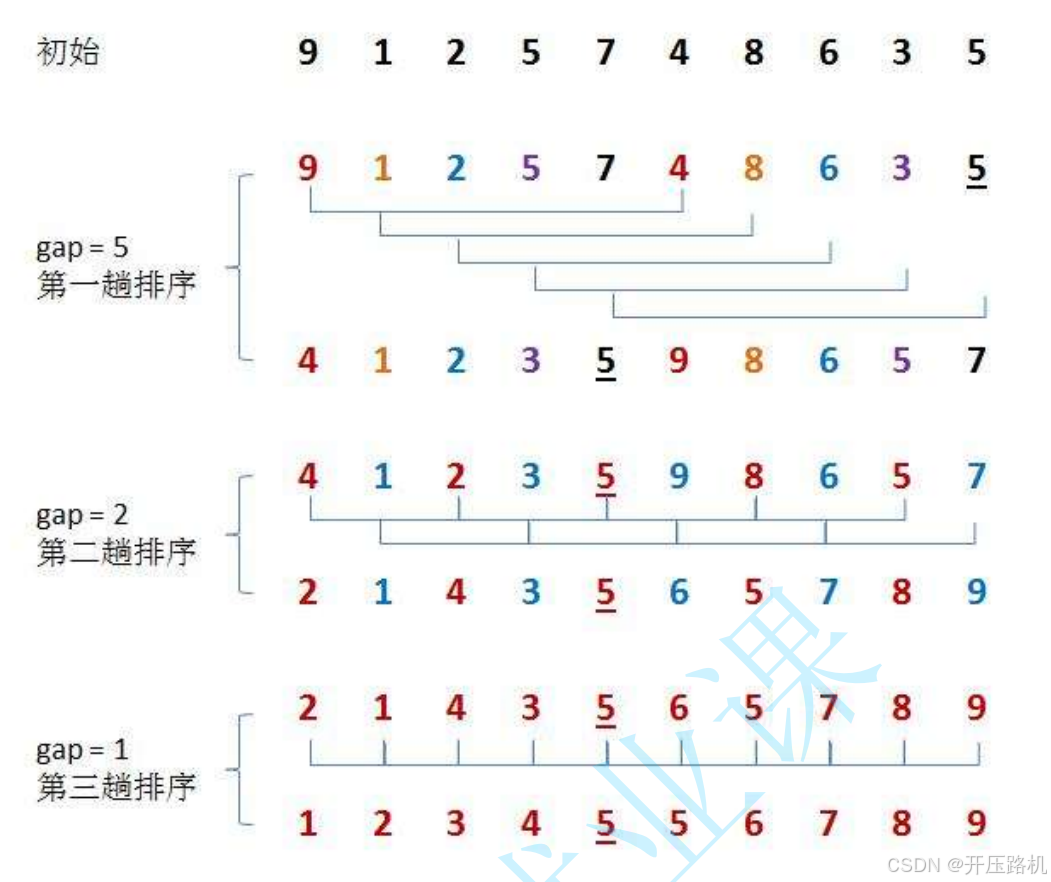
2.希尔排序
希尔排序又称缩小增量法。希尔排序的基本思想:采用分组插入的方法,先将待排序记录序列分割成几组(希尔对记录的分组不是简单的“逐段分割”,而是将相隔gap增量的记录分成一组),这样当经过几次分组排序后,整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
void ShellSort(int* a, int n)//希尔排序
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}1.希尔排序是对直接插入排序的优化。
2.当gap>1时都是预排序,目的是让数组更接近有序,当gap==1时,数组已经接近有序的了。
3.时间复杂度:O(N^1.3)。
4.稳定性:不稳定
3.选择排序
每一次从待排序的数据元素中选出最小或最大元素,存放在序列的起始位置,直到待排序的数据元素排完。
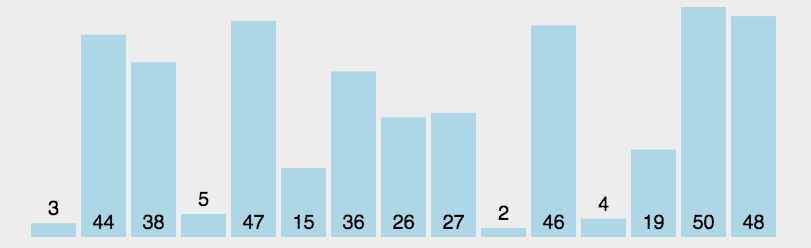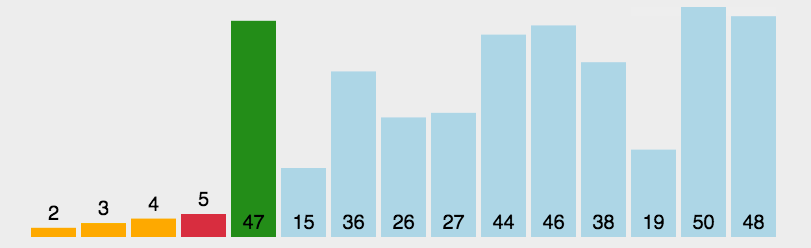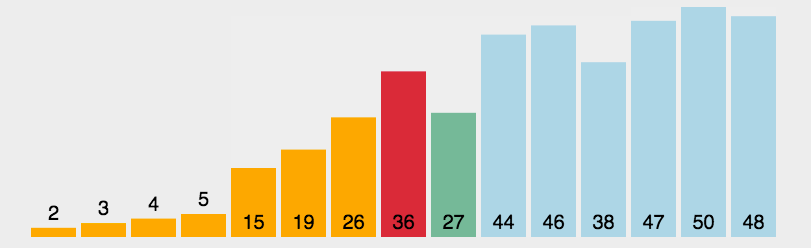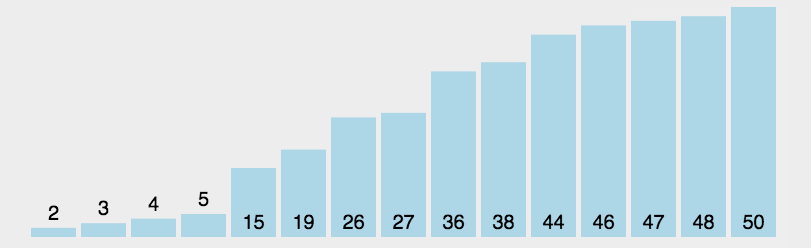
遍历一般数组,找出最大的数和最小的数,将最大的数和end交换,将最小的数和begin交换,当最小的数和begin重合时需要将最小的数换的前面。
void SelectSort(int* a, int n)//选择排序
{
int begin = 0, end = n-1;
while (begin < end)
{
int min = begin;
int max = begin;
for (int i = begin + 1; i <= end; i++)
{
if (a[i] > a[max])
{
max = i;
}
if (a[i] < a[min])
{
min = i;
}
}
Swap(&a[begin], &a[min]);
if (a[begin] == a[max])
{
max = min;
}
Swap(&a[end], &a[max]);
begin++;
end--;
}
}1.时间复杂度:O(N^2)
2.空间复杂度:O(1)
3.稳定性:不稳定
4.堆排序
void AdjustUp(int* a, int child)//向上调整算法
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int* a, int n, int parent)//向下调整算法:n为数组的大小
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)//堆排序
{
// for (int i = 1; i < n; i++)
// {
// AdjustUp(a, i);//向上调整建堆建为大堆,时间复杂度为O(N*logN)
// }
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);//先下调整算法,从叶子节点开始调整,时间复杂度为O(N)
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);//交换堆顶和最后一个数
AdjustDown(a, end, 0);//end是元素个数
end--;
}
}选用向下调整算法建堆是因为时间复杂度比向上调整算法建堆小。
1.时间复杂度:O(N*logN)
2.稳定性:不稳定。
5.快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序算法,其基本思想为:任取待排元素序列中的某元素为基准值,按照排序码将排序分为两个子序列,左子序列中的所以元素小于基准值,右子序列中的所以元素均大于基准值,然后重复这个过程,直到所以元素都排列在相应的位置上。
1.hoare版本
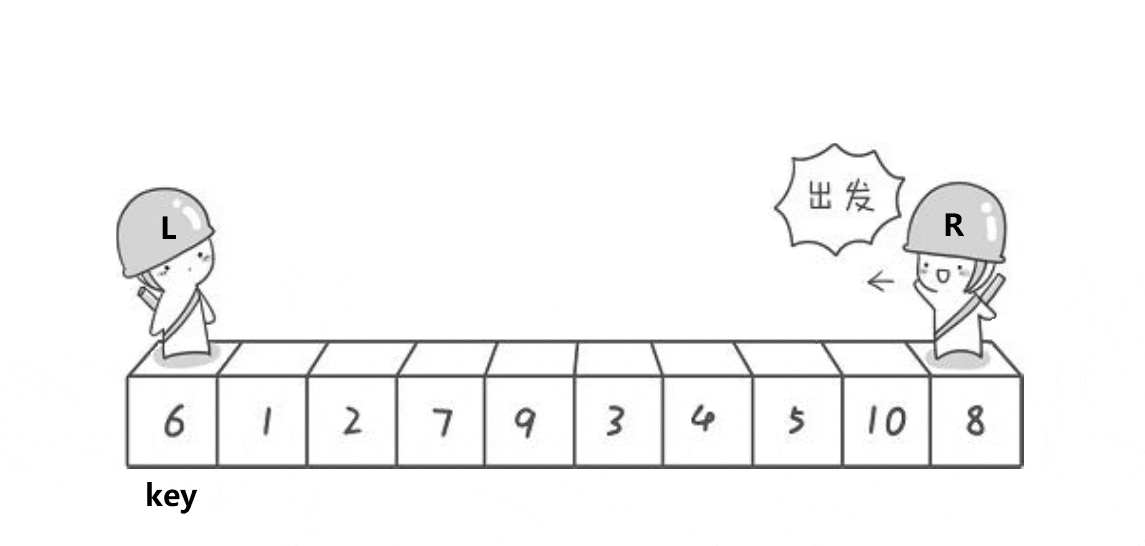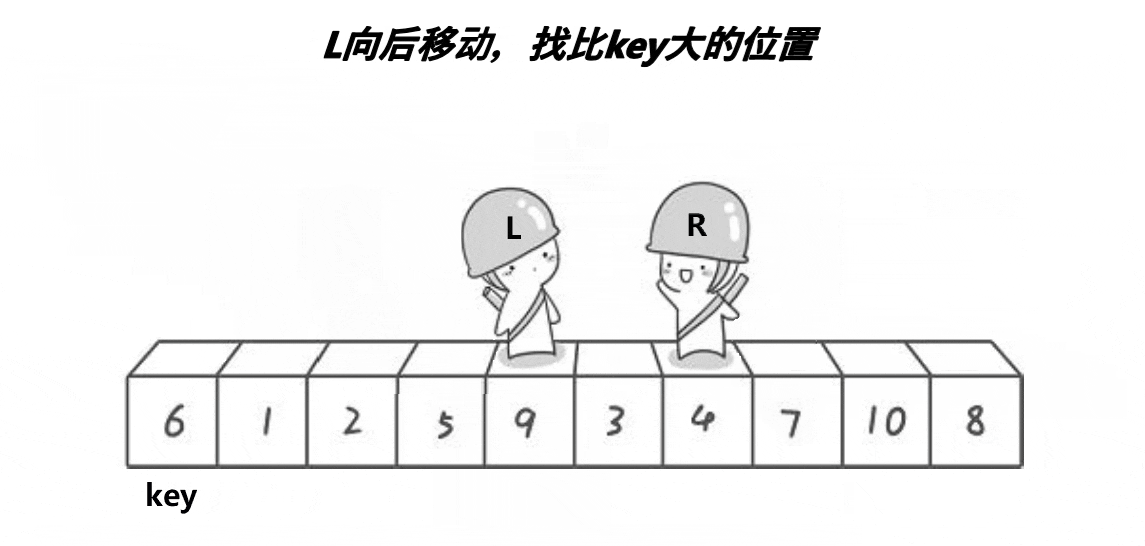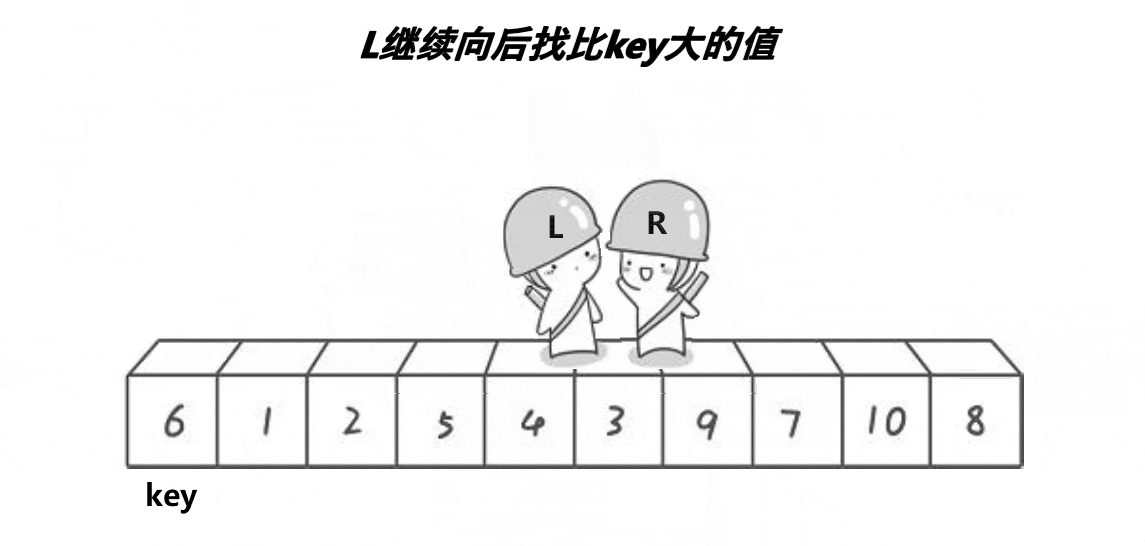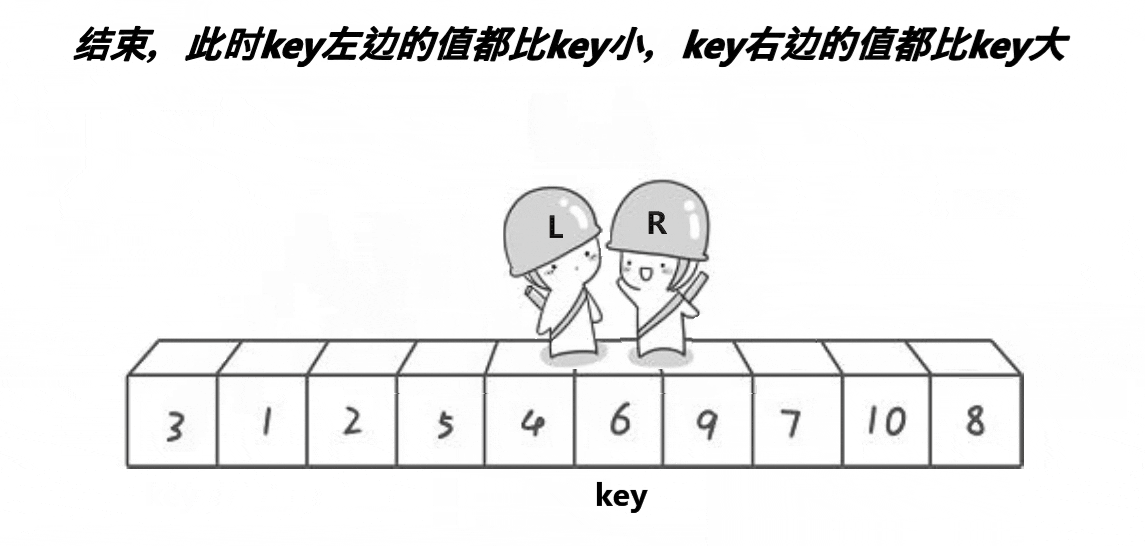
将左面的值设为key,R先走,R找小,L找大,交换L与R,当L与R相遇时再与key交换。
int GetMid(int* a, int left, int right)//三数取中
{
int mid = (left + right) / 2;
if (a[left] < a[right])
{
if (a[right] < a[mid])
{
return right;
}
else if (a[mid] < a[left])
{
return left;
}
else
{
return mid;
}
}
else//a[left] > a[right]
{
if (a[right] < a[mid])
{
return right;
}
else if (a[left] < a[mid])
{
return left;
}
else
{
return mid;
}
}
}
void QuickSort(int* a, int left, int right)//快速排序
{
if (left >= right)
{
return;
}
if ((right - left + 1) < 10)//小区间优化
{
InsertSort(a + left, right - left + 1);
}
int mid = GetMid(a, left, right);//三数取中
Swap(&a[left], &a[mid]);
int key = left;
int begin = left, end = right;
while (begin < end)
{
while (begin < end && a[end] >= a[key])//右先走
{
end--;
}
while (begin < end && a[begin] <= a[key])
{
begin++;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[key], &a[begin]);//key还在左,要将key放到相遇的位置
key = begin;
//[left key-1] key [key+1,right]
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}为什么要右先走:左边做key,右边先走可以保证相遇位置比key小
L遇R:R先走,停下来,R停下来的条件是遇到比key小的值,R停的位置一定比key小,L没有找到大,遇见R就停下来了。
R遇L:R先走,找下,没有找到比key小的,直接根L相遇。L停留的位置是上一轮交换的位置,上一轮交换,把比key小的值换到了L的位置。
相反:如果让右边做key,左边先走,可以保证相遇的位置比key大。
2.前后指针法
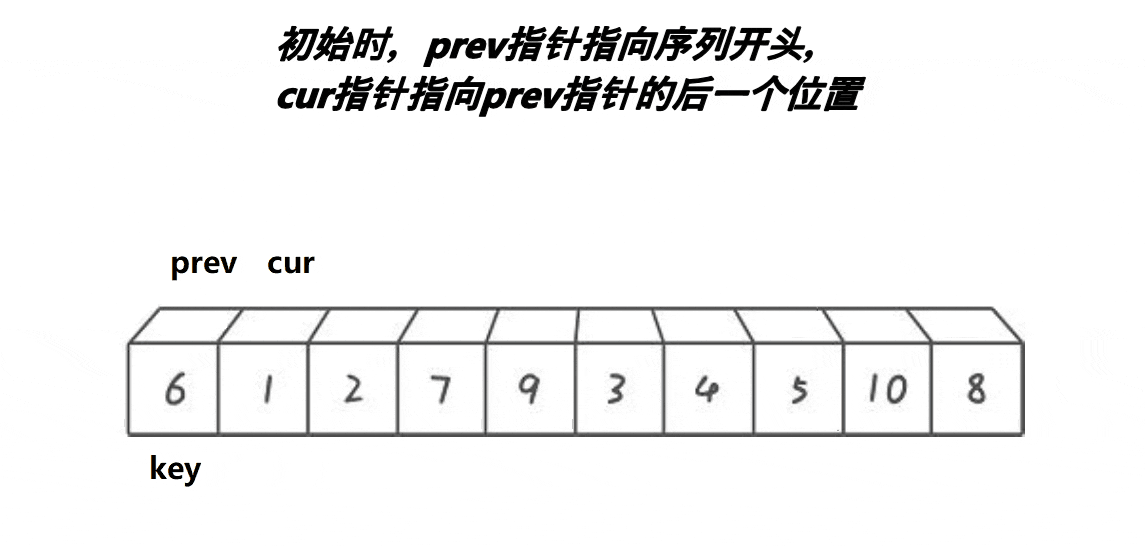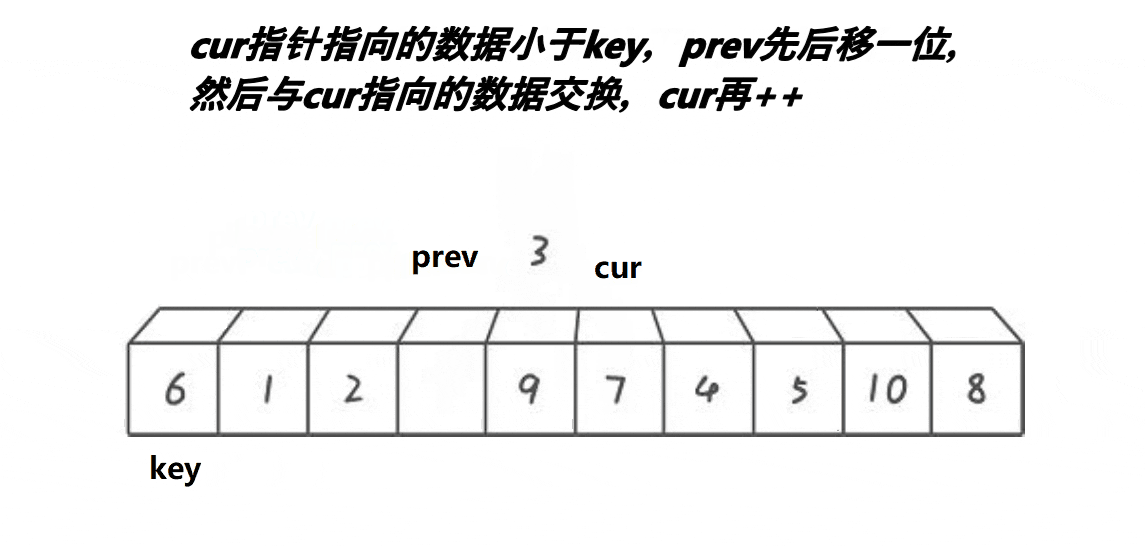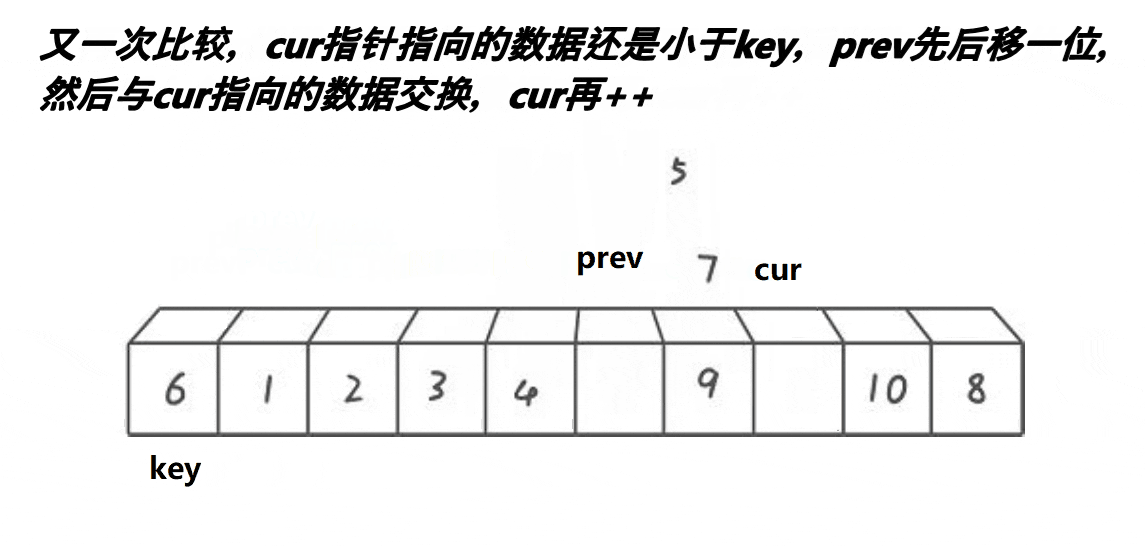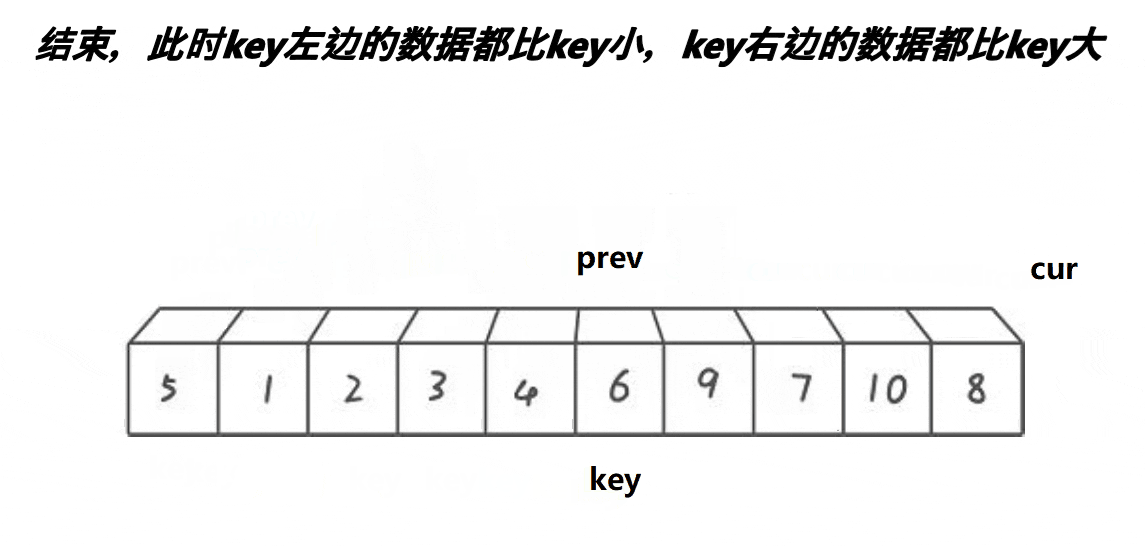
void QuickSort1(int* a, int left, int right)//快速排序快慢指针
{
if (left >= right)
{
return;
}
if ((right - left + 1) < 10)//小区间优化
{
InsertSort(a + left, right - left + 1);
}
int mid = GetMid(a, left, right);//三数取中
Swap(&a[left], &a[mid]);
int key = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[key] && prev++ != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[key], &a[prev]);
key = prev;
//[left, key - 1] key [key+1,right]
QuickSort1(a, left, key - 1);
QuickSort1(a, key + 1, right);
}3.非递归方法
创建一个栈,将右左区间范围放入栈中(出栈的时候就是先出左,再出右)。
void QuickSortNonR(int* a, int left, int right)//快速排序非递归
{
stack st;
STInit(&st);
STPush(&st, right);
STPush(&st, left);
while (!STEmpty(&st))
{
int begin = STTop(&st);
STPop(&st);
int end = STTop(&st);
STPop(&st);
int key = Quick(a, begin, end);
if (key + 1 < end)
{
STPush(&st, end);
STPush(&st, key + 1);
}
if (begin < key - 1)
{
STPush(&st, key - 1);
STPush(&st, begin);
}
}
}4.三路划分
决定快排性能的关键点是每次单趟排序后,key对数组的分割,如果每次选key基本二分居中,那么快排的递归树就是颗均匀的二叉树,性能最佳。但是实践中虽然不可能每次都是二分居中,但性能也还是可控的。但是如果出现每次选到最小值/最大值,划分为0个和N-1个子问题时,时间复杂度为O(N^2),数组有序时就会出现这个问题,我们前面已经用三数取中或者随机选key解决了这个问题,但是还有一些场景没有解决(数组中大量重复数据时)。
三路划分算法解析:
当面对有大量跟key相同的值时,核心思想是把数据分为三段【比key小的值】【根key想等的值】【比key大的值】。
- key默认取left位置的值。
- left指向区间的最左边,right指向区间的最右边,cur指向left+1的位置。
- cur遇到比key小的值后跟left交换,换到左边,left++,cur++。
- cur遇到比key大的值后跟right交换,换到右边,right--。
- cur遇到跟key相等的值后,cur++。
- 直到cur>right时结束。
void QuickSortBy3Way(int* a, int left, int right)//三路划分
{
if (left >= right)
{
return;
}
int mid = GetMid(a, left, right);
Swap(&a[mid], &a[left]);
int begin = left;
int key = a[left];
int end = right;
int cur = left + 1;
while (cur <= end)
{
if (a[cur] < key)
{
Swap(&a[cur], &a[left]);
cur++;
left++;
}
else if (a[cur] > key)
{
Swap(&a[cur], &a[right]);
right--;
}
else
{
cur++;
}
}
//[begin ,left - 1] [left right] [right + 1, end];
QuickSortBy3Way(a, begin, left - 1);
QuickSortBy3Way(a, right + 1, end);
}1.时间复杂度:O(N*logN)
2.空间复杂度:O(logN)
3.稳定性:不稳定
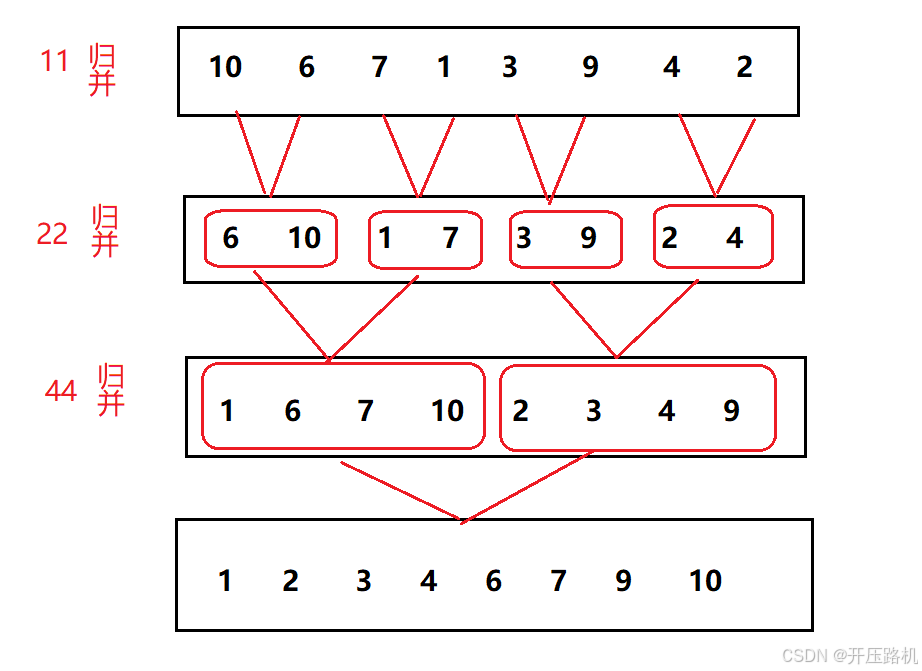
6.归并排序
基本思想:归并排序是建立在归并操作上的一种有效排序算法,该算法是采用分治法的一个典型应用,将已有序的子序列合并,得到完全有序的序列,即使每个子序列有序,再使子序列段间有序,若将两个有序表合并成一个有序表,称为二路归并。
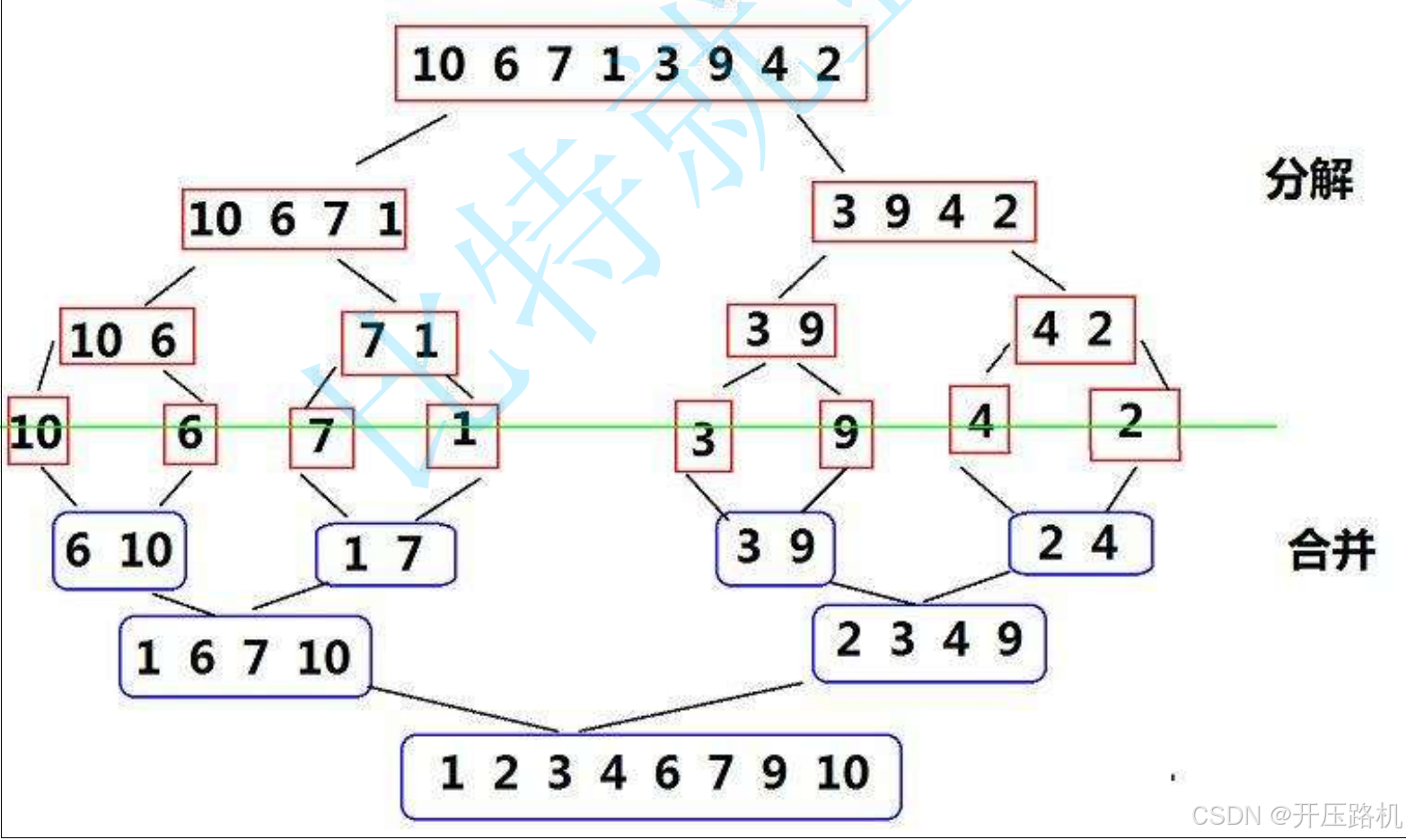
void _MergeSort(int* a, int* tmp, int left, int right)
{
if (left >= right)
{
return;
}
int mid = (left + right) / 2;
_MergeSort(a, tmp, left, mid);
_MergeSort(a, tmp, mid + 1, right);//分割
//归并
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + left, tmp + left, (right - left + 1) * sizeof(int));//将tmp一段一段拷贝回a中
}
void MergeSort(int* a, int n)//归并排序
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}
先不断分割,分割成长度为1数组进行比较,一段一段比较进行归并,开辟一个tmp空间,用来存放归并完的结果再将tmp一段一段的拷贝回a中。
非递归
通过循环来进行非递归,每组数据设为gap个,将gap个数据归并。
void MergeSortNonR(int* a, int n)//归并排序非递归
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
//每组数据有gap个
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)//每次归并两组,i代表每组归并的起始位置
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int j = i;
if (begin2 >= n)//当第二组都越界不存在时,这一组就不需要归并
{
break;
}
if (end2 >= n)//当第二组begin2没有越界,end2越界时,修正end2
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));//一组一组往回拷贝
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}7.非比较排序
思想:计数排序有称为鸽巢原理,是对哈希直接定址的变形应用
- 统计相同元素出现的次数
- 根据统计的结果将序列回收到原来的序列中
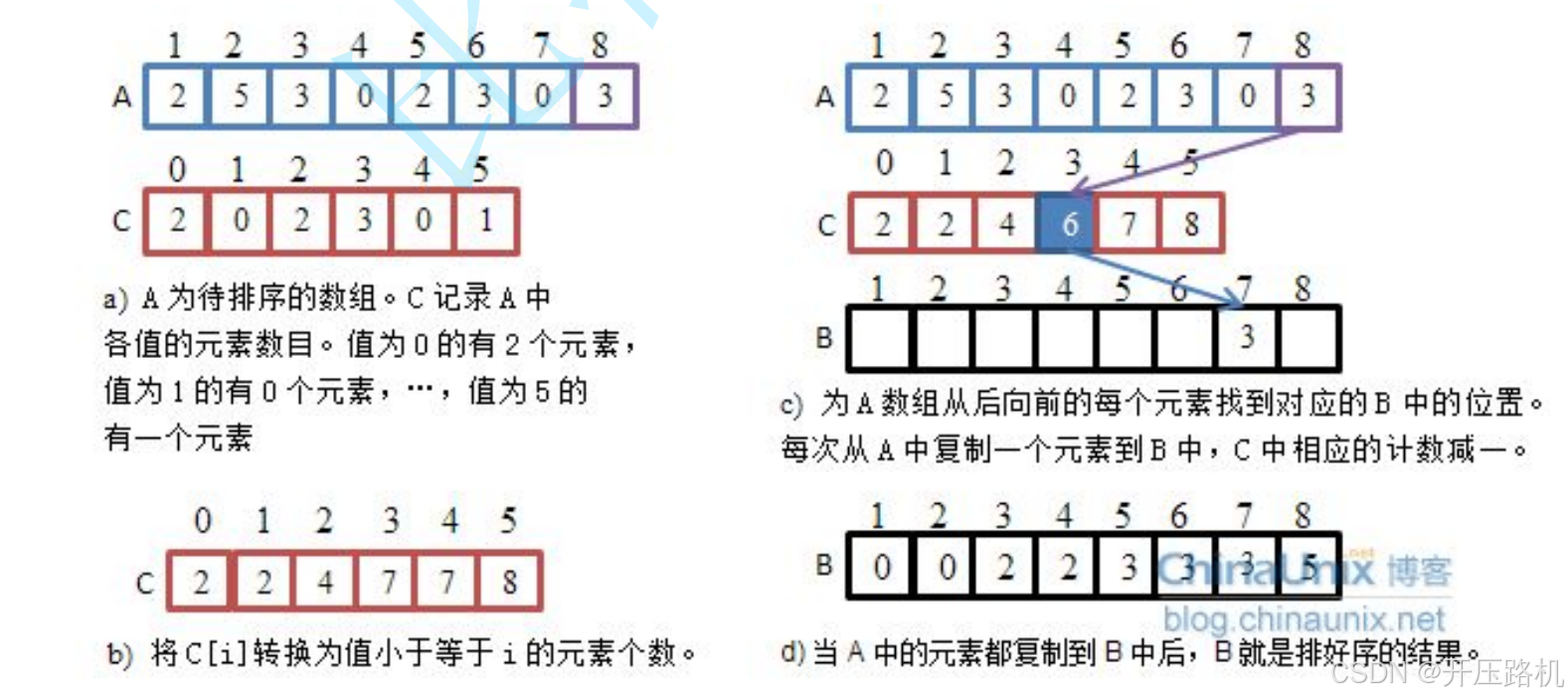
void CountSort(int* a, int n)//计数排序
{
int min = a[0], max = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min + 1;
int* count = (int*)calloc(range,sizeof(int));
if (count == NULL)
{
perror("calloc fail");
return;
}
//统计次数
for (int i = 0; i < n; i++)
{
count[a[i] - min]++;
}
int j = 0;
//排序
for (int i = 0; i < range; i++)
{
while (count[i]--)
{
a[j++] = i + min;
}
}
free(count);
}计数排序的特性总结
- 计数排序在数据范围集中时,效率很高,但适用的范围及场景有限。
- 时间复杂度:O(N+range)
- 空间复杂度:O(range)
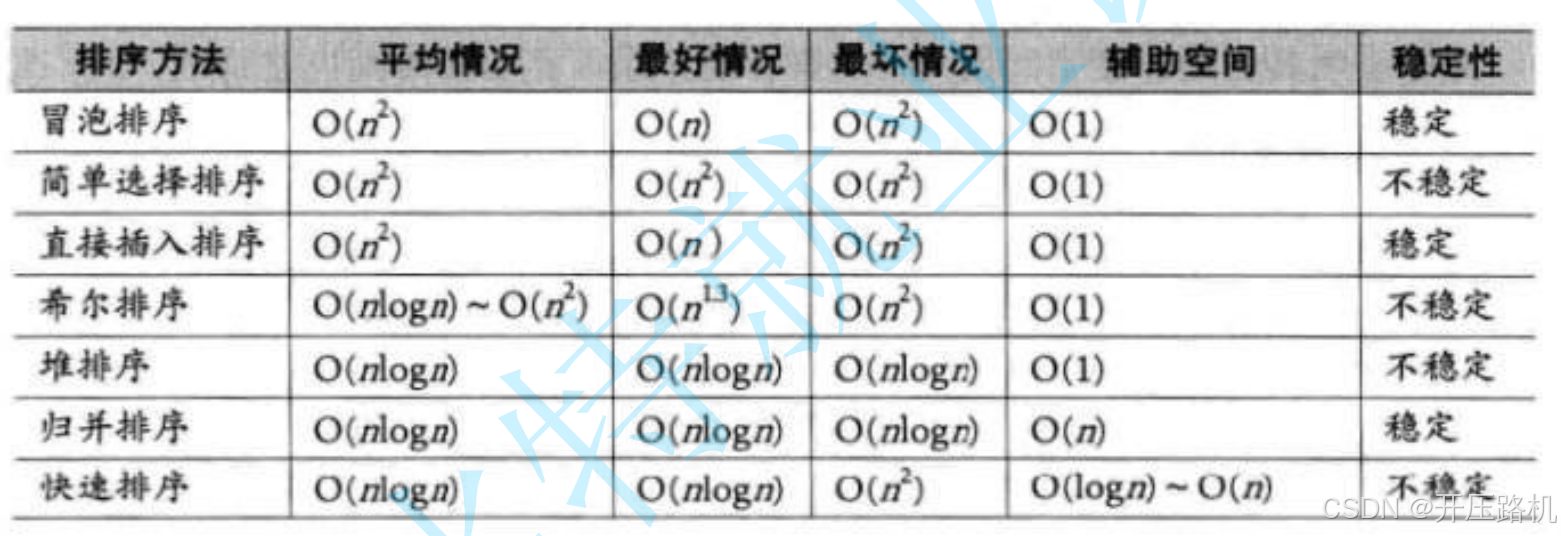
8.排序算法及稳定性分析
稳定性:假定待排序的记录序列中,存在多个具有相同关键词的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中r[i] = r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则成称这种算法是稳定的否则为不稳定。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 排序算法:直接插入排序,希尔排序,选择排序,快速排序,堆排序,归并排序

发表评论 取消回复