一、论文简介
CamFreeDiff(Camera-free Diffusion)的模型,用于从单个无相机参数的图像和文本描述生成360度全景图像。这种方法与现有的策略(如MVDiffusion)不同,它消除了对预定义相机姿态的需求。相反,该模型在多视图扩散框架内直接预测单应性变换。
与传统电影不同,360度电影提供沉浸式体验,使观众感觉自己是环境的一部分,而不仅仅是从固定视角观察。创建360度电影通常需要专门的设备,如360度相机,这是一项高度专业化的任务。基于图像的全景外推是向360度视频制作迈出的必要步骤。文本到图像的扩散模型的进步使得将图像外推到360度视图成为可能。
二、研究框架
输入:无相机参数的图像:输入是一张普通的2D图像,其相机参数(如焦距、视角、旋转角度等)未知。文本描述:与输入图像相关的文本描述,用于指导全景图像的生成。
输出:生成的360度全景图像,该图像与输入文本描述相匹配,并且在视觉上与输入图像一致。
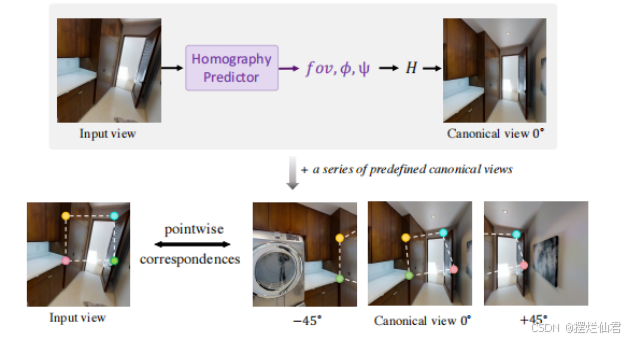
1.单应性矩阵估计:
目标:预测从输入图像到预定义规范视图的单应性变换。
过程:使用一个基于多层感知机(MLP)的分类器,该分类器建立在通用图像编码器之上。这个编码器使用预训练的稳定扩散模型的U-Net编码器,但权重被冻结以提高效率。只有MLP分类器被优化以学习单应性估计器。
参数化:单应性矩阵被参数化为三个自由度(3DoF):相机视场(f)、相机绕x轴旋转(ϕ)和相机绕z轴旋转(ψ)。
2.相机自由360度图像外推:
策略:基于估计的单应性矩阵,设计了三种变体来生成360度全景图像。
变体1(Unwarp Image):将输入图像通过估计的对应关系转换到规范视图,然后使用潜在扩散上色模型生成八个全景视图。
变体2(Unwarp Latent):与变体1不同,首先将图像编码到潜在空间,然后将潜在空间中的图像通过估计的对应关系转换到规范视图。
变体3(New View):引入了一种新方法,该方法通过一个条件分支和八个生成分支来生成全景图像。条件分支依赖于输入图像,而生成分支依赖于规范视图。
3.多视图一致性:
对应关系感知注意力(CAA):在多视图生成模型中,使用CAA来强制执行对应点之间的几何一致性。
信息聚合:通过CAA,从输入视图到所有目标规范视图聚合点级信息。
4.训练和评估:
数据集:在Matterport3D数据集上微调模型,该数据集包含高分辨率的全景图像。
训练细节:优化MLP块用于单应性预测,优化CAA块用于多视图一致性。
评估指标:使用FID、IS、CS和PSNR等标准图像生成指标来评估视觉质量和重建质量。
三、实验结果
提出了CamFreeDiff,这是一个能够处理无相机输入图像的全景生成模型。这是第一个设计用于处理未知输入视图和相机参数的模型。通过预测从输入图像到预定义规范视图的单应性变换来制定相机参数估计。在Structured3D数据集上测试了模型的泛化能力,即使没有进行微调或领域转移技术,模型也显示出强大的泛化能力。
定性结果:与MVDiffusion相比,CamFreeDiff在处理相机自由输入时显示出更强的鲁棒性。
定量结果:CamFreeDiff在视觉质量和重建质量方面取得了最佳结果。

虽然模型在处理未知相机参数的输入图像方面表现出色,但单应性矩阵的估计仍然是一个挑战。尽管模型在新领域数据上表现出良好的泛化能力,但在更广泛的应用场景中可能需要进一步的调整和优化。
四、示例代码
由于CamFreeDiff模型是一个复杂的深度学习模型,涉及到图像处理、单应性矩阵估计、多视图一致性等高级技术,因此实现它需要大量的代码和资源。此处提供一个简化的Python代码示例,以展示如何使用一些基本的库和概念来模拟CamFreeDiff模型的核心步骤。
import numpy as np
import cv2
from PIL import Image
import torch
import torch.nn as nn
# 假设的单应性矩阵估计器
class HomographyEstimator(nn.Module):
def __init__(self):
super(HomographyEstimator, self).__init__()
# 这里只是一个示例,实际模型会更复杂
self.fc = nn.Linear(2048, 6) # 假设输入特征维度为2048
def forward(self, x):
# 预测相机参数(f, phi, psi)
params = self.fc(x)
f, phi, psi = params.chunk(3, dim=1)
return f, phi, psi
# 假设的图像编码器
class ImageEncoder(nn.Module):
def __init__(self):
super(ImageEncoder, self).__init__()
# 这里只是一个示例,实际模型会更复杂
self.conv = nn.Conv2d(3, 3, kernel_size=3, padding=1)
def forward(self, x):
return self.conv(x)
# 假设的图像解码器
class ImageDecoder(nn.Module):
def __init__(self):
super(ImageDecoder, self).__init__()
# 这里只是一个示例,实际模型会更复杂
self.conv = nn.Conv2d(3, 3, kernel_size=3, padding=1)
def forward(self, x):
return self.conv(x)
# 生成360度全景图像
def generate_360_panorama(input_image, text_description):
# 假设的图像编码器
encoder = ImageEncoder()
# 假设的单应性矩阵估计器
homography_estimator = HomographyEstimator()
# 假设的图像解码器
decoder = ImageDecoder()
# 将输入图像转换为张量
input_tensor = transforms.ToTensor()(input_image).unsqueeze(0)
# 编码输入图像
encoded_image = encoder(input_tensor)
# 估计单应性矩阵
f, phi, psi = homography_estimator(encoded_image)
# 假设的单应性矩阵
H = cv2.getPerspectiveTransform(np.float32([[0, 0], [0, 1], [1, 0], [1, 1]]),
np.float32([[f.item(), phi.item()], [f.item(), psi.item()],
[f.item(), psi.item()], [psi.item(), psi.item()]]))
# 应用单应性变换
warped_image = cv2.warpPerspective(input_image, H, (input_image.width, input_image.height))
# 解码生成的全景图像
output_tensor = decoder(warped_image)
# 将输出张量转换为图像
output_image = transforms.ToPILImage()(output_tensor.squeeze(0))
return output_image
# 主函数
def main():
# 加载输入图像
input_image = Image.open("input_image.jpg")
text_description = "A bathroom with a large mirror and a sink."
# 生成360度全景图像
panorama_image = generate_360_panorama(input_image, text_description)
# 保存生成的全景图像
panorama_image.save('generated_360_panorama.jpg')
if __name__ == "__main__":
main()这个示例代码展示了如何使用一些基本的库和概念来模拟CamFreeDiff模型的核心步骤。实际实现可能需要更多的细节和调整。为了提供一个更详细的示例代码,我们将模拟CamFreeDiff模型的关键步骤,包括单应性矩阵估计和图像的变换。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from PIL import Image
import numpy as np
import cv2
# 定义一个简单的图像编码器
class ImageEncoder(nn.Module):
def __init__(self):
super(ImageEncoder, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
def forward(self, x):
return self.conv(x)
# 定义单应性矩阵估计器
class HomographyEstimator(nn.Module):
def __init__(self, input_dim):
super(HomographyEstimator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 6) # 预测 f, phi, psi, theta, cx, cy
)
def forward(self, x):
x = x.view(x.size(0), -1)
return self.fc(x)
# 生成360度全景图像
def generate_360_panorama(encoder, homography_estimator, input_image_path):
# 加载和预处理输入图像
input_image = Image.open(input_image_path).convert('RGB')
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
input_tensor = transform(input_image).unsqueeze(0)
# 使用编码器编码图像
encoded_image = encoder(input_tensor)
# 预测单应性矩阵参数
with torch.no_grad():
homography_params = homography_estimator(encoded_image)
f, phi, psi, theta, cx, cy = homography_params.chunk(6, dim=1)
# 将预测的参数转换为单应性矩阵
f = f.item()
phi = phi.item()
psi = psi.item()
theta = theta.item()
cx = cx.item()
cy = cy.item()
# 创建单应性矩阵
H = np.array([[f, 0, cx],
[0, f, cy],
[0, 0, 1]])
# 应用单应性变换
input_image_np = np.array(input_image)
warped_image = cv2.warpPerspective(input_image_np, H, (input这个示例代码提供了一个框架,展示了如何使用PyTorch和OpenCV来实现从输入图像到360度全景图像的转换。实际应用中,可以根据更复杂的模型和训练过程来提高生成全景图像的质量和准确性。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 《Camera-free Image to PanoramaGeneration with Diffusion Model》论文解析——CamFreeDiff

发表评论 取消回复