主要学习两个流行的建模工具包,statsmodels 和 scikit-learn。
一、pandas 与模型代码之间的接口
模型开发的常见工作流程是使用 pandas 进行数据加载和清理,然后再切换到建模库来构建模型本身。模型开发过程的一个重要部分在机器学习中称为特征工程,这可以描述从原始数据集中提取可能在建模上下文中有用信息的任何数据转换或分析。之前学习的数据聚合和 GroupBy 工具经常用于特征工程上下文中。
pandas 和其他分析库之间的连接点通常是 NumPy 数组。要将 DataFrame 转换为 NumPy 数组,请使用 to_numpy 方法(代码解释在注释中):
import pandas as pd
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
print(data)
print(data.columns)
print(data.to_numpy())
# 要转换回 DataFrame,可以传递一个带有可选列名的二维 ndarray
df2 = pd.DataFrame(data.to_numpy(), columns=['one', 'two', 'three'])
print(df2)
# to_numpy 方法适用于数据为同类数据时使用。
# 如果有异构数据,则结果ndarray结果中的数据类型为python object
df3 = data.copy()
df3['strings'] = ['a', 'b', 'c', 'd', 'e']
print(df3)
print(df3.to_numpy())
# 对于某些模型,可能仅使用列的子集。
# 建议将 loc 索引与 to_numpy 一起使用:
model_cols = ['x0', 'x1']
print(data.loc[:, model_cols].to_numpy())
# 一些库对 pandas 有原生支持,并自动完成一些工作:从 DataFrame 转换为 NumPy 并将模型参数名称附加到输出表或 Series 的列。
# 其他情况下,则需要手动执行此 “元数据管理”。
# 在之前学习的 “分类数据”中,我们了解了 pandas 的分类类型和 pandas.get_dummies 函数。
# 假设我们的示例数据集中有一个非数字列:
data['category'] = pd.Categorical(['a', 'b', 'a', 'a', 'b'], categories=['a', 'b'])
print(data)
# 我们使用虚拟变量替换 'category' 列,我们创建虚拟变量,删除 'category' 列,然后连接结果:
dummies = pd.get_dummies(data.category, prefix='category')
data_with_dummies = data.drop('category', axis=1).join(dummies)
print(data_with_dummies)print(data)
print(data.columns)
print(data.to_numpy()) 这三行代码输出:
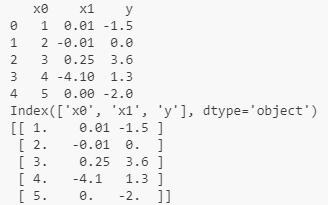
print(df2) 输出:
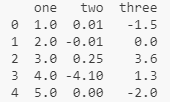
print(df3) 和 print(df3.to_numpy()) 这两行代码输出:

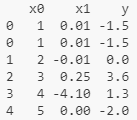
print(data.loc[:, model_cols].to_numpy()) 输出:

使用Categorical之后print(data) 输出:

print(data_with_dummies) 输出:
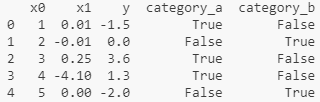
使用虚拟变量拟合某些统计模型存在一些细微差别。当拥有的不仅仅是简单的数字列时,使用 Patsy可能更简单且不易出错。
二、使用 Patsy 创建模型描述
Patsy 是一个 Python 库,使用基于字符串的“公式语法”来描述统计模型(尤其是线性模型),当安装 statsmodels 时(pip install statsmodels),它会自动安装。
Patsy 的公式是一种特殊的字符串语法,如下所示:
y ~ x0 + x1
语法 a + b 并不是将 a 添加到 b,而是表示为模型创建而设计的矩阵中的项。patsy.dmatrices 函数采用公式字符串和数据集(可以是 DataFrame 或数组字典),并为线性模型生成设计矩阵:
import pandas as pd
import patsy
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
print(data)
y, X = patsy.dmatrices('y ~ x0 + x1', data)
print(y, '\n', X)print(data) 输出:
y的详细信息是:

X的详细信息是:

这些 Patsy DesignMatrix 实例是具有附加元数据的 NumPy ndarray。
在上面的输出中,有一个 Intercept 。这是普通最小二乘法 (OLS) 回归等线性模型的约定。我们可以通过向模型添加 + 0 来隐藏:
import numpy as np
import pandas as pd
import patsy
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
print(data)
# y, X这些 Patsy DesignMatrix 实例是具有附加元数据的 NumPy ndarray
y, X = patsy.dmatrices('y ~ x0 + x1', data)
print(y, '\n', X)
print(np.asarray(y))
print(np.asarray(X))
# 添加 +0 隐藏Intercept
a = patsy.dmatrices('y ~ x0 + x1 + 0', data)[1]
print(a)a输出的详细信息是:

这里隐藏了Intercept。
Patsy 对象可以直接传递到 numpy.linalg.lstsq 等算法中, numpy.linalg.lstsq 算法执行普通的最小二乘回归:
import numpy as np
import pandas as pd
import patsy
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
print(data)
# y, X这些 Patsy DesignMatrix 实例是具有附加元数据的 NumPy ndarray
y, X = patsy.dmatrices('y ~ x0 + x1', data)
coef, resid, _, _ = np.linalg.lstsq(X, y)
print(coef)
# 模型元数据保留在 design_info 属性中,因此可以将模型列名称重新附加到拟合系数以获得 Series
coef = pd.Series(coef.squeeze(), index=X.design_info.column_names)
print(coef)data输出:

未附加列名前coef输出:

附加列名生成Series后coef输出:
Patsy 公式中的数据转换
可以将 Python 代码混合到 Patsy 公式中;在计算公式时,该库将尝试查找我们在封闭作用域中使用的函数:
import numpy as np
import pandas as pd
import patsy
data = pd.DataFrame({
'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
y, X = patsy.dmatrices('y ~ x0 + np.log(np.abs(x1) + 1)', data)
print(X)
# 常用的变量转换包括标准化(平均值为 0 和方差 1)和居中(减去平均值)。Patsy 为此提供了内置函数:
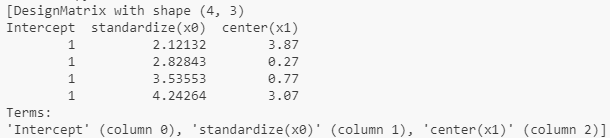
y, X = patsy.dmatrices('y ~ standardize(x0) + center(x1)', data)
print(X)y, X = patsy.dmatrices('y ~ x0 + np.log(np.abs(x1) + 1)', data) 中X的详细信息:

y, X = patsy.dmatrices('y ~ standardize(x0) + center(x1)', data) 中X的详细信息:

作为建模过程的一部分,可以在一个数据集上拟合模型,然后基于另一个数据集(可能是之前数据集的一部分作为测试集,也可能是后面操作后得到的数据集)评估模型。在应用像 center 和 standardized 等转换得到新数据后,使用模型根据新数据形成谓词时应小心。这些转换称为有状态转换,因为在转换新数据集时,必须使用原始数据集的平均值或标准差等统计数据。
patsy.build_design_matrices 函数可以使用原始 in-sample 数据集中保存的信息将转换为新的 out-of-sample 数据:
import pandas as pd
import patsy
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
y, X = patsy.dmatrices('y ~ standardize(x0) + center(x1)', data)
new_data = pd.DataFrame({'x0': [6, 7, 8, 9],
'x1': [3.1, -0.5, 0, 2.3],
'y': [1, 2, 3, 4]})
new_X = patsy.build_design_matrices([X.design_info], new_data)
print(new_X)print(new_x) 输出:
因为 Patsy 公式上下文中的加号 (+) 并不意味着加法,所以当想按名称从数据集添加列时,必须将它们包装在特殊的 I 函数中:
import pandas as pd
import patsy
data = pd.DataFrame({'x0': [1, 2, 3, 4, 5],
'x1': [0.01, -0.01, 0.25, -4.1, 0.],
'y': [-1.5, 0., 3.6, 1.3, -2.]})
y, X = patsy.dmatrices('y ~ I(x0 + x1)', data)
print(X)X详细信息如下:

Patsy 在 patsy.builtins 模块中还有其他几个内置转换。可以查看在线官方文档学习。
分类数据和 Patsy
非数值数据可以通过多种不同的方式转换为模型设计矩阵。但这些知识最好与统计学课程一起学习。当在 Patsy 公式中使用非数字数据时,默认情况下,它们将转换为虚拟变量。如果有截距 intercept,则省略其中一个level以避免共线性:
import pandas as pd
import patsy
data = pd.DataFrame({
'key1': ['a', 'a', 'b', 'b', 'a', 'b', 'a', 'b'],
'key2': [0, 1, 0, 1, 0, 1, 0, 0],
'v1': [1, 2, 3, 4, 5, 6, 7, 8],
'v2': [-1, 0, 2.5, -0.5, 4.0, -1.2, 0.2, -1.7]
})
y, X = patsy.dmatrices('v2 ~ key1', data)
print(X)X的详细信息如下:

如果省略模型中的截距intercept,则每个类别值的列都将包含在模型设计矩阵中:
import pandas as pd
import patsy
data = pd.DataFrame({
'key1': ['a', 'a', 'b', 'b', 'a', 'b', 'a', 'b'],
'key2': [0, 1, 0, 1, 0, 1, 0, 0],
'v1': [1, 2, 3, 4, 5, 6, 7, 8],
'v2': [-1, 0, 2.5, -0.5, 4.0, -1.2, 0.2, -1.7]
})
y, X = patsy.dmatrices('v2 ~ key1 + 0', data)
print(X)此时X的详细信息:

数字列可以使用 C 函数解释为分类列:
import pandas as pd
import patsy
data = pd.DataFrame({
'key1': ['a', 'a', 'b', 'b', 'a', 'b', 'a', 'b'],
'key2': [0, 1, 0, 1, 0, 1, 0, 0],
'v1': [1, 2, 3, 4, 5, 6, 7, 8],
'v2': [-1, 0, 2.5, -0.5, 4.0, -1.2, 0.2, -1.7]
})
y, X = patsy.dmatrices('v2 ~ C(key2)', data)
print(X)X的详细信息:

当在模型中使用多个分类项时,情况可能会更加复杂,因为我们可以包含 key1:key2 形式的交互项,例如,这些项可用于方差分析 (ANOVA) 模型:
import pandas as pd
import patsy
data = pd.DataFrame({
'key1': ['a', 'a', 'b', 'b', 'a', 'b', 'a', 'b'],
'key2': [0, 1, 0, 1, 0, 1, 0, 0],
'v1': [1, 2, 3, 4, 5, 6, 7, 8],
'v2': [-1, 0, 2.5, -0.5, 4.0, -1.2, 0.2, -1.7]
})
data['key2'] = data['key2'].map({0: 'zero', 1: 'one'})
y, X = patsy.dmatrices('v2 ~ key1 + key2', data)
print(X)
y, X = patsy.dmatrices('v2 ~ key1 + key2 + key1:key2', data)
print(X)y, X = patsy.dmatrices('v2 ~ key1 + key2', data) 执行后X的详细信息:

y, X = patsy.dmatrices('v2 ~ key1 + key2 + key1:key2', data) 执行后X的详细信息:

Patsy 提供了其他方法来转换分类数据,包括具有特定排序的术语的转换。有关更多信息,请参阅官方在线文档。
三、statsmodels 简介
statsmodels 是一个 Python 库,用于拟合多种统计模型、执行统计测试以及数据探索和可视化。statsmodels 包含许多“经典”频率统计方法,但是贝叶斯方法和机器学习模型要使用其他库。
statsmodels 中的模型包括:
- 线性模型、广义线性模型和稳健线性模型
- 线性混合效应模型
- 方差分析 (ANOVA) 方法
- 时间序列过程和状态空间模型
- 广义矩量法
接下来,我们将学习使用 statsmodels 中的一些基本工具,探索如何将建模接口与 Patsy 公式和 pandas DataFrame 对象一起使用。如果没有安装 statsmodels,可以使用以下命令安装它:
pip(或conda) install statsmodels
估计线性模型
statsmodels 中有几种线性回归模型,从最基本的(普通最小二乘法)到复杂的(迭代重新加权的最小二乘法)。statsmodels 中的线性模型有两个不同的主要接口:基于数组和基于公式。可以通过以下 API 模块导入进行访问:
- import statsmodels.api as sm
- import statsmodels.formula.api as smf
为了学习如何使用这些,我们从一些随机数据中生成一个线性模型。可以在 Jupyter 中运行以下代码,但我还是用vs code 编辑器:
import numpy as np
import pandas as pd
import patsy
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
N = 100
X = np.c_[dnorm(0, 0.4, size=N),
dnorm(0, 0.6, size=N),
dnorm(0, 0.2, size=N)]
eps = dnorm(0, 0.1, size=N)
beta = [0.1, 0.3, 0.5]
y = np.dot(X, beta) + eps在上面的代码中,我写下了具有已知参数 beta 的 “true” 模型。dnorm 是一个辅助函数,用于生成具有特定均值和方差的正态分布数据。所以现在我们输出X,y有:
X[:5] 输出:
[[-0.90050602 -0.18942958 -1.0278702 ]
[ 0.79925205 -1.54598388 -0.32739708]
[-0.55065483 -0.12025429 0.32935899]
[-0.16391555 0.82403985 0.20827485]
[-0.04765129 -0.21314698 -0.04824364]]
y[:5] 输出:
[-0.59952668 -0.58845445 0.18563386 -0.00747657 -0.01537445]
线性模型通常拟合一个截距项 intercept,正如之前在 Patsy 中看到的那样。sm.add_constant 函数可以向现有矩阵添加截距列:
import numpy as np
import pandas as pd
import patsy
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
N = 100
X = np.c_[dnorm(0, 0.4, size=N),
dnorm(0, 0.6, size=N),
dnorm(0, 0.2, size=N)]
eps = dnorm(0, 0.1, size=N)
beta = [0.1, 0.3, 0.5]
y = np.dot(X, beta) + eps
X_model = sm.add_constant(X)x_model[:5] 输出:
[[ 1. -0.90050602 -0.18942958 -1.0278702 ]
[ 1. 0.79925205 -1.54598388 -0.32739708]
[ 1. -0.55065483 -0.12025429 0.32935899]
[ 1. -0.16391555 0.82403985 0.20827485]
[ 1. -0.04765129 -0.21314698 -0.04824364]]
sm.OLS 类可以拟合普通的最小二乘线性回归,模型的 fit 方法返回一个 regression results 对象,其中包含估计的模型参数和其他诊断:
import numpy as np
import statsmodels.api as sm
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
N = 100
X = np.c_[dnorm(0, 0.4, size=N),
dnorm(0, 0.6, size=N),
dnorm(0, 0.2, size=N)]
eps = dnorm(0, 0.1, size=N)
beta = [0.1, 0.3, 0.5]
y = np.dot(X, beta) + eps
# 普通的最小二乘线性回归
model = sm.OLS(y, X)
# 模型的 fit 方法返回一个 regression results 对象,
# 其中包含估计的模型参数和其他诊断信息
results = model.fit()
print(results.params)
# 结果的 summary 方法可以打印模型诊断输出的模型 的详细信息:
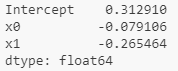
print(results.summary())results.params 输出:[0.06681503 0.26803235 0.45052319]
results.summary() 输出:
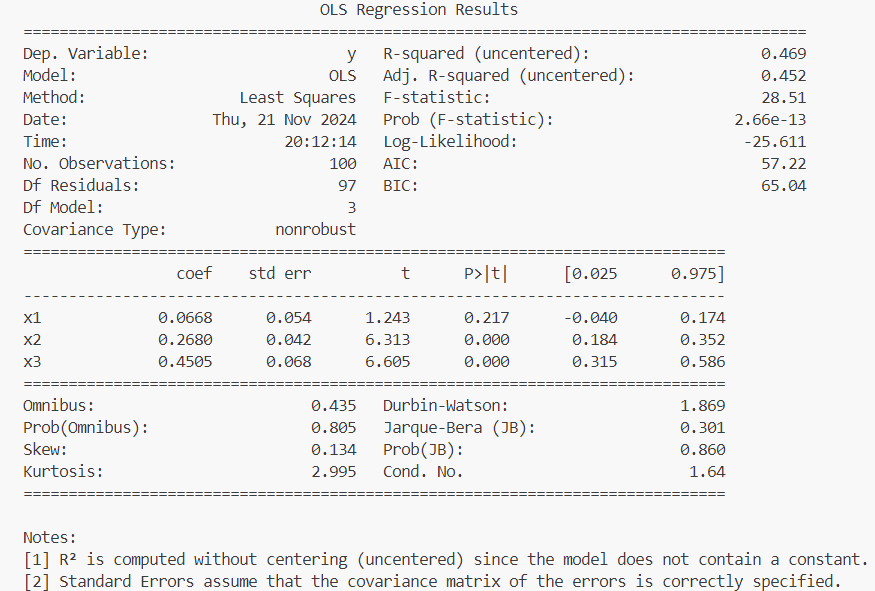
上面输出的参数名称已指定通用名称 x1、x2、x3 等。假设所有模型参数都在 DataFrame 中:
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
N = 100
X = np.c_[dnorm(0, 0.4, size=N),
dnorm(0, 0.6, size=N),
dnorm(0, 0.2, size=N)]
eps = dnorm(0, 0.1, size=N)
beta = [0.1, 0.3, 0.5]
y = np.dot(X, beta) + eps
# 所有模型参数都在 DataFrame 中
data = pd.DataFrame(X, columns=['col0', 'col1', 'col2'])
data['y'] = y
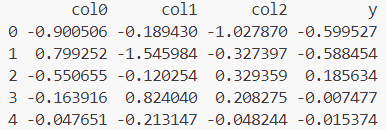
print(data[:5])
# 现在我们使用 statsmodels 公式 API 和 Patsy 公式字符串:
# 普通的最小二乘线性回归
results = smf.ols('y ~ col0 + col1 + col2', data=data).fit()
print(results.params)
print(results.tvalues)print(data[:5]) 输出:
print(results.params) 输出:
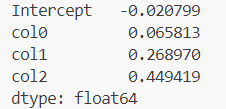
print(results.tvalues) 输出:

我们从输出可以看出 statsmodels 如何将结果作为附加了 DataFrame 列名称的 Series 返回。在使用公式和 pandas 对象时,不需要使用 add_constant。
给定新的样本外数据(out-of-sample data),可以在给定估计模型参数的情况下计算预测值:
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
N = 100
X = np.c_[dnorm(0, 0.4, size=N),
dnorm(0, 0.6, size=N),
dnorm(0, 0.2, size=N)]
eps = dnorm(0, 0.1, size=N)
beta = [0.1, 0.3, 0.5]
y = np.dot(X, beta) + eps
# 所有模型参数都在 DataFrame 中
data = pd.DataFrame(X, columns=['col0', 'col1', 'col2'])
data['y'] = y
# 现在我们使用 statsmodels 公式 API 和 Patsy 公式字符串:
# 普通的最小二乘线性回归
results = smf.ols('y ~ col0 + col1 + col2', data=data).fit()
# 给定新的样本外数据(out-of-sample data),
# 在给定估计模型参数的情况下计算预测值:
print(results.predict(data[:5]))results.predict(data[:5]) 输出:

我们可以探索 statsmodels 中用于分析、诊断和可视化线性模型结果的许多其他工具。除了普通的最小二乘法之外,还有其他种类的线性模型。
估计时间序列过程
statsmodels 中的另一类模型用于时间序列分析。其中包括自回归过程、卡尔曼滤波和其他状态空间模型以及多变量自回归模型。
我们模拟一些具有自回归结构和噪声的时间序列数据:
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.tsa.ar_model import AutoReg
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
init_x = 4
values = [init_x, init_x]
N = 1000
b0 = 0.8
b1 = -0.4
noise = dnorm(0, 0.1, N)
for i in range(N):
new_x = values[-1] * b0 + values[-2] * b1 + noise[i]
values.append(new_x)以上代码生成的数据具有参数为 0.8 和 –0.4 的 AR(2) 结构(两个滞后)。拟合 AR 模型时,我们可能不知道要包含的滞后项的数量,因此可以使用更多的滞后来拟合模型:
import numpy as np
from statsmodels.tsa.ar_model import AutoReg
# 使得随机数可重现
rng = np.random.default_rng(seed=12345)
def dnorm(mean, variance, size=1):
if isinstance(size, int):
size = size,
return mean + np.sqrt(variance) * rng.standard_normal(*size)
init_x = 4
values = [init_x, init_x]
N = 1000
b0 = 0.8
b1 = -0.4
noise = dnorm(0, 0.1, N)
for i in range(N):
new_x = values[-1] * b0 + values[-2] * b1 + noise[i]
values.append(new_x)
MAXLAGS = 5
model = AutoReg(values, MAXLAGS)
results = model.fit()
# 结果中的估计参数首先是截距,然后是前两个滞后的估计值:
print(results.params)results.params 输出:
[ 0.00312421 0.82271464 -0.43568671 -0.00569183 0.02271538 -0.02522406]
要深入学习这些模型,请在 statsmodels 官方文档中还探索。
四、scikit-learn 简介
scikit-learn 是使用最广泛和最受信任的通用 Python 机器学习工具包之一。它包含广泛的标准监督式和无监督式机器学习方法,以及用于模型选择和评估、数据转换、数据加载和模型持久性的工具。这些模型可用于分类、聚类、预测和其他常见任务。可以这样安装 scikit-learn:
pip(或conda) install scikit-learn
下面使用了一个现在很经典的数据集,该数据集来自 1912 年泰坦尼克号上乘客的 Kaggle 竞赛。我们使用 pandas 加载训练和测试数据集。
训练数据集:titanic/train.csv:

测试数据集:titanic/test.csv

下面我们根据数据中的特征预测乘客是否会幸存下来。模型拟合到训练数据集上,然后在样本外测试数据集上进行评估。
我们使用 Age 作为预测因子,但Age列存在缺失数据,我们会在代码中填补缺失数据。有很多方法可以进行缺失数据插补,但我们执行一个简单的方法,使用训练数据集的中位数来填充两个数据表中的 null 值。
import pandas as pd
from sklearn.linear_model import LogisticRegression
train = pd.read_csv('datasets/titanic/train.csv')
test = pd.read_csv('datasets/titanic/test.csv')
# statsmodels 和 scikit-learn 这样的库通常不能包含缺失数据,
# 查看这些列,看看是否有任何包含缺失数据的列:
print(train.isna().sum())
print(test.isna().sum())
# 使用训练数据集的中位数来填充两个表中Age列的缺失值
impute_value = train['Age'].median()
train['Age'] = train['Age'].fillna(impute_value)
test['Age'] = test['Age'].fillna(impute_value)
# 现在指定模型。添加了一个 IsFemale 列为 'Sex' 列的编码
train['IsFemale'] = (train['Sex'] == 'female').astype(int)
test['IsFemale'] = (test['Sex'] == 'female').astype(int)
# 然后指定一些模型变量并创建 NumPy 数组
predictors = ['Pclass', 'IsFemale', 'Age']
X_train = train[predictors].to_numpy()
X_test = test[predictors].to_numpy()
y_train = train['Survived'].to_numpy()
print(X_train[:5])
print(y_train[:5])
# 使用 scikitlearn 中的 LogisticRegression 模型并创建一个模型实例:
model = LogisticRegression()
# 使用模型的 fit 方法将此模型拟合到训练数据:
model.fit(X_train, y_train)
# 现在,可以使用 model.predict 为测试数据集形成预测:
y_predict = model.predict(X_test)
print(y_predict[:10])
# 如果我们有测试数据集的 true 值,则可以计算预测的准确率百分比或其他一些误差指标:
# (y_true == y_predict).mean()
# 在实践中,模型训练中通常还有许多其他复杂性。许多模型都有可以调整的参数,
# 并且有一些技术(例如交叉验证)可用于参数调整,以避免过度拟合训练数据。
# 这通常可以产生更好的预测性能或对新数据的稳健性。
# 交叉验证的工作原理是拆分训练数据以模拟样本外预测。
# 根据模型准确度分数(如均方误差),可以对模型参数执行网格搜索。
# 某些模型(如 Logistic 回归)具有具有内置交叉验证的 estimator 类。
# 例如,LogisticRegressionCV 类可以与一个参数一起使用,
# 该参数指示对模型正则化参数 C 执行网格搜索的精细程度
from sklearn.linear_model import LogisticRegressionCV
model_cv = LogisticRegressionCV(Cs=10)
model_cv.fit(X_train, y_train)
# 要手动执行交叉验证,可以使用 cross_val_score helper函数,该函数处理数据拆分过程。
# 例如,要使用训练数据的 4 个不重叠的 split来交叉验证我们的模型,可以这样做:
from sklearn.model_selection import cross_val_score
model = LogisticRegression(C=10)
scores = cross_val_score(model, X_train, y_train, cv=4)
print(scores)以上代码输出如下(代码解释在注释中):
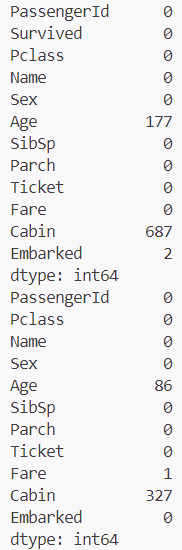
print(train.isna().sum()) 和 print(test.isna().sum()) 判断数据集是否存在缺失值:
print(X_train[:5]) 输出:
[[ 3. 0. 22.]
[ 1. 1. 38.]
[ 3. 1. 26.]
[ 1. 1. 35.]
[ 3. 0. 35.]]
print(y_train[:5]) 输出:[0 1 1 1 0]
print(y_predict[:10]) 输出:[0 0 0 0 1 0 1 0 1 0]
print(scores) 输出:[0.77578475 0.79820628 0.77578475 0.78828829]
默认评分指标取决于模型,但可以选择显式评分函数。交叉验证的模型需要更长的训练时间,但通常可以产生更好的模型性能。
总结:虽然上面只了解了一些 Python 建模库的皮毛,但越来越多的框架用于各种统计和机器学习,我们学习建模最好的方法是熟悉各种统计或机器学习框架的官方文档,以便及时了解最新的功能和 API。
我写的这个Python数据分析专栏 主要是对《Python for Data Analysis THIRD EDITION Data Wrangling with pandas, NumPy, and Jupyter Wes McKinney》这本书的学习记录。
后面我将用具体的数据分析示例来学习和巩固之前的学习内容。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python数据分析NumPy和pandas(四十、Python 中的建模库statsmodels 和 scikit-learn)

发表评论 取消回复