使用IDEA+Maven实现MapReduce
准备工作
- 在桌面创建文件
wordfile1.txt
I love Spark
I love Hadoop
- 在桌面创建文件
wordfile2.txt
Hadoop is good
Spark is fast
上传文件到Hadoop
# 启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
# 删除HDFS的hadoop对应的input和output目录,确保后面程序运行不会出现问题(如果有)
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output
# 新建input目录
./bin/hdfs dfs -mkdir input
# 上传本地文件系统中的文件
./bin/hdfs dfs -put ~/Desktop/wordfile1.txt input
./bin/hdfs dfs -put ~/Desktop/wordfile2.txt input
IDEA创建项目
创建Maven项目
我的项目名是MapReduce,可以自己修改。
IDEA自带Maven,如果需要自己安装Maven可以参考安装Maven
创建项目,选择Maven,模板可以选择第一个maven-archetype-archetype
创建java 文件(WordCount)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
public class WordCount2 {
public WordCount2() {
}
public static void main(String[] args) throws Exception {
// 创建一个Configuration对象,用于配置MapReduce作业
Configuration conf = new Configuration();
// 使用GenericOptionsParser解析命令行参数并判断
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: buycount <in> [<in>...] <out>");
System.exit(2);
}
// 创建一个MapReduce作业实例,并设置作业名称。
Job job = Job.getInstance(conf, "buy count");
// 指定包含作业类的jar文件
job.setJarByClass(WordCount2.class);
// 设置Mapper类。
job.setMapperClass(WordCount2.TokenizerMapper.class);
// 设置Combiner类,Combiner是Map端的一个可选优化步骤,可以减少传输到Reduce端的数据量。
job.setCombinerClass(WordCount2.IntSumReducer.class);
// 设置Reducer类
job.setReducerClass(WordCount2.IntSumReducer.class);
// 设置作业输出键和值的类型。
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 为作业添加输入路径。
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// 设置作业的输出路径。
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 等待作业完成,并根据作业是否成功来设置退出状态。
System.exit(job.waitForCompletion(true)?0:1);
}
/*
*定义了一个名为TokenizerMapper的Mapper类,
* 它继承自Hadoop的Mapper类,
* 并指定了输入键、输入值、输出键和输出值的类型。
* 计算每个单词的个数
* */
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
// one用于在map方法中输出计数为1
private static final IntWritable one = new IntWritable(1);
// word用于存储当前处理的单词。
private Text word = new Text();
public TokenizerMapper() {
}
// 接收输入键值对和上下文对象,
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 使用StringTokenizer分割输入文本行,并为每个单词输出一个键值对(单词,1)。
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
/*
* 定义了一个名为IntSumReducer的Reducer类,
* 它继承自Hadoop的Reducer类,
* 并指定了输入键、输入值、输出键和输出值的类型。
* */
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 存储单词的总计数
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
// reduce方法,它接收输入键、值的集合和上下文对象
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 遍历值的集合,计算单词的总计数。
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
// 设置结果并输出。
this.result.set(sum);
context.write(key, this.result);
}
}
}
添加依赖(pom.xml)
记得修改自己的hadoop的版本和Java_Home的路径
打包时记得修改main方法的位置
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.6.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- main()所在的类,注意修改 -->
<mainClass>WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>7</source>
<target>7</target>
</configuration>
</plugin>
</plugins>
</build>
<!-- 环境配置 -->
<properties>
<hadoop.version>3.3.5</hadoop.version>
<JAVA_HOME>C:\lang\Java\jdk1.8.0_151</JAVA_HOME>
</properties>
<dependencies>
<!-- 打包工具 -->
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<!-- Hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
设置完成后重新加载Maven
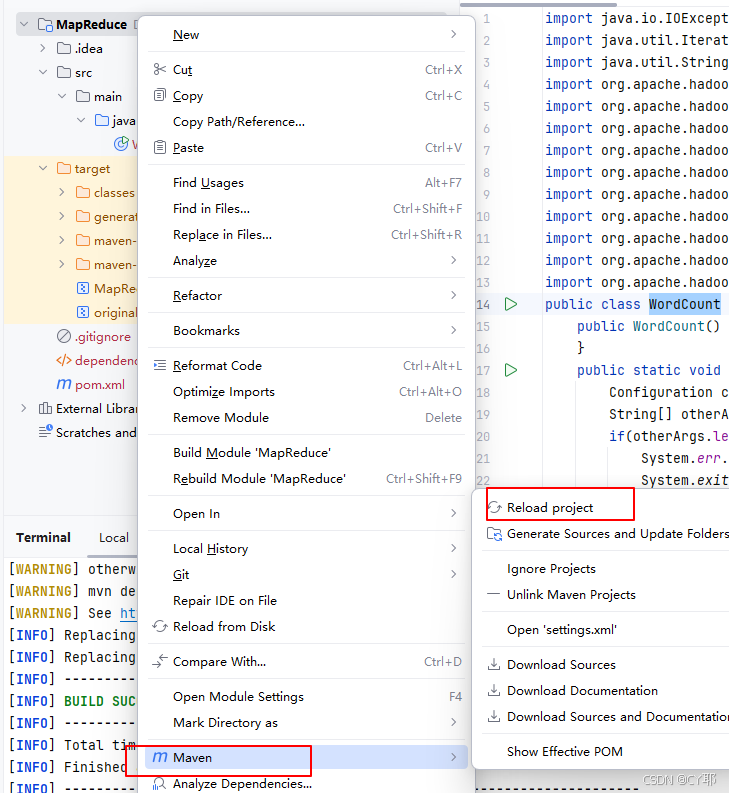
Maven 打包
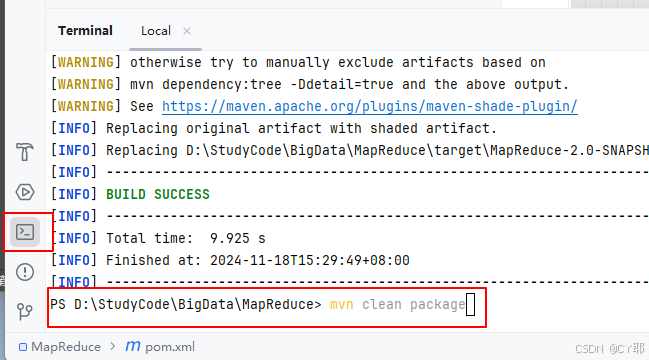
在IDEA的终端运行以下代码
mvn clean package
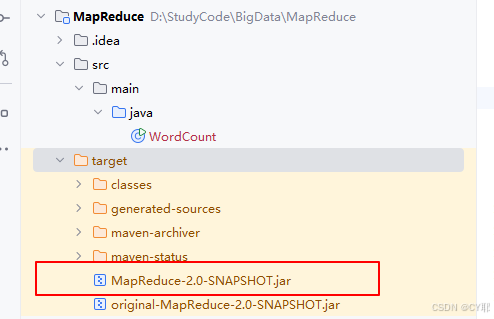
打包完成后可以查看target文件夹中是否有MapReduce-2.0-SNAPSHOT.jar
打包过程可能存在的报错
No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK?
没有配置Java_Home,在系统环境变量中配置Java_Home
在虚拟机运行jar包
- 复制jar包(
MapReduce-2.0-SNAPSHOT.jar)到虚拟机的桌面或其他位置 - 在终端运行以下代码
cd /usr/local/hadoop
# jar包位置需要根据自己的位置修改
./bin/hadoop jar ~/Desktop/MapReduce-2.0-SNAPSHOT.jar input output
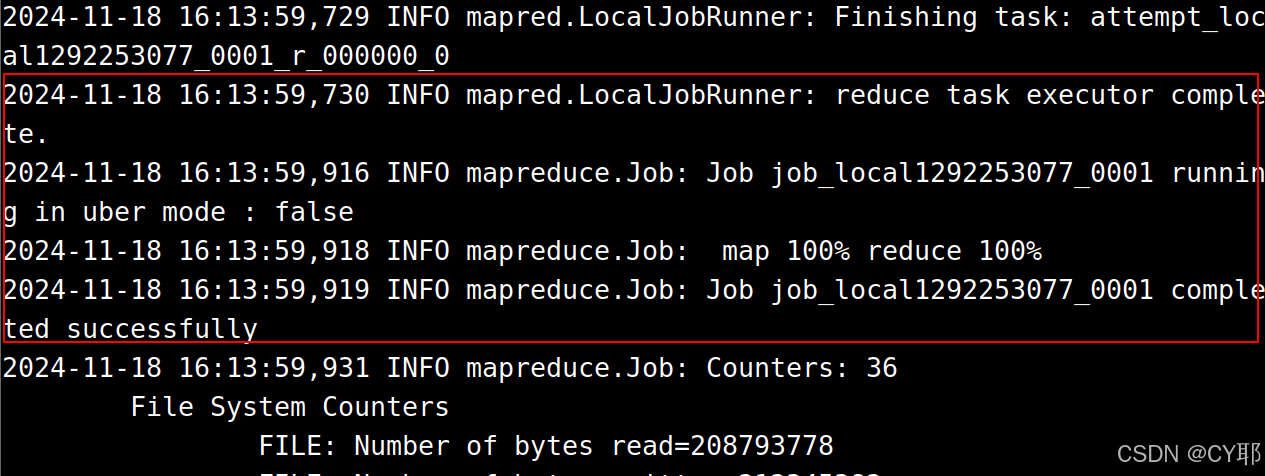
上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息:
... //这里省略若干屏幕信息
2023-06-17 02:50:31,862 INFO mapred.LocalJobRunner: reduce task executor complete.
2023-06-17 02:50:32,532 INFO mapreduce.Job: map 100% reduce 100%
2023-06-17 02:50:32,533 INFO mapreduce.Job: Job job_local51129470_0001 completed successfully
2023-06-17 02:50:32,578 INFO mapreduce.Job: Counters: 36
... //这里省略若干屏幕信息
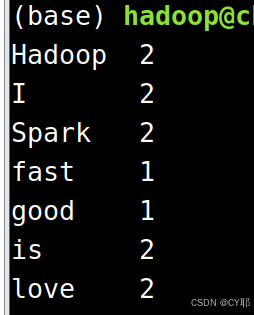
词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:
cd /usr/local/hadoop
./bin/hdfs dfs -cat output/*
如果要再次运行,需要首先删除HDFS中的output目录,否则会报错。
题目二
题目:
假设你有一个包含用户购买记录的文本文件,每行记录包含用户ID、商品ID和购买数量,格式如“user1,item1,2”。请编写一个MapReduce程序来处理这个文件,统计每个用户购买商品的总数量,并输出每个用户及其购买的总商品数。下面是一个示例
用户购买记录的文本文件
user1,item1,2
user1,item2,3
user2,item1,1
user3,item3,4
user1,item3,1
user2,item2,2
输出
user1 6 user2 3 user3 4
要求:
- 使用Java或Python等支持MapReduce的编程语言编写。
- 详细描述Map函数和Reduce函数的实现逻辑。
给出运行程序所需的输入文件示例和预期输出结果。
实现
- 在虚拟机桌面创建文件(
buy_count.txt)添加内容并上传文件到Hadoop
# 启动Hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
# 删除HDFS的hadoop对应的input和output目录,确保后面程序运行不会出现问题
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output
# 新建input目录
./bin/hdfs dfs -mkdir input
# 上传本地文件系统中的文件
./bin/hdfs dfs -put ~/Desktop/buy_count.txt input
- 创建
Java文件(BuyCount)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Iterator;
public class BuyCount {
public BuyCount() {
}
public static void main(String[] args) throws Exception {
// 创建一个Configuration对象,用于配置MapReduce作业
Configuration conf = new Configuration();
// 使用GenericOptionsParser解析命令行参数并判断
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: buycount <in> [<in>...] <out>");
System.exit(2);
}
// 创建一个MapReduce作业实例,并设置作业名称。
Job job = Job.getInstance(conf, "buy count");
// 指定包含作业类的jar文件
job.setJarByClass(BuyCount.class);
// 设置Mapper类。
job.setMapperClass(BuyCount.TokenizerMapper.class);
// 设置Combiner类,Combiner是Map端的一个可选优化步骤,可以减少传输到Reduce端的数据量。
job.setCombinerClass(BuyCount.IntSumReducer.class);
// 设置Reducer类
job.setReducerClass(BuyCount.IntSumReducer.class);
// 设置作业输出键和值的类型。
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 为作业添加输入路径。
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// 设置作业的输出路径。
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
// 等待作业完成,并根据作业是否成功来设置退出状态。
System.exit(job.waitForCompletion(true)?0:1);
}
/*
*定义了一个名为TokenizerMapper的Mapper类,
* 它继承自Hadoop的Mapper类,
* 并指定了输入键、输入值、输出键和输出值的类型。
* 计算每个单词的个数
* */
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
// one用于在map方法中输出计数为1
private static final IntWritable one = new IntWritable(1);
// word用于存储当前处理的单词。
private Text word = new Text();
public TokenizerMapper() {
}
// 接收输入键值对和上下文对象,
// 会得到每一行
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
this.word.set(strs[0]);
int num = Integer.parseInt(strs[2]);
context.write(this.word, new IntWritable(num));
}
}
/*
* 定义了一个名为IntSumReducer的Reducer类,
* 它继承自Hadoop的Reducer类,
* 并指定了输入键、输入值、输出键和输出值的类型。
* */
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 存储单词的总计数
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
// reduce方法,它接收输入键、值的集合和上下文对象
// 将相同的结果进行相加
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 遍历值的集合,计算单词的总计数。
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
// 设置结果并输出。
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 修改
pom.xml中的mainClass - 在虚拟机运行jar包

cd /usr/local/hadoop
# 删除output目录
./bin/hdfs dfs -rm -r output
# jar包位置需要根据自己的位置修改
./bin/hadoop jar ~/Desktop/MapReduce-2.0-SNAPSHOT.jar input output
# 查看统计结果
./bin/hdfs dfs -cat output/*
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=156a5nk5kjl84

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 使用IDEA+Maven实现MapReduced的WordCount

发表评论 取消回复