Python因其简洁易用、丰富的库支持以及强大的社区,被广泛应用于机器学习与人工智能(AI)领域。本教程通过实用的代码示例和讲解,带你从零开始掌握Python在机器学习与人工智能中的基本用法。
1. 机器学习与AI的Python生态系统
Python拥有多种支持机器学习和AI的库,以下是几个核心库:
- NumPy:处理高效数组和矩阵运算。
- Pandas:提供数据操作与分析工具。
- Matplotlib/Seaborn:用于数据可视化。
- Scikit-learn:机器学习的核心库,包含分类、回归、聚类等算法。
- TensorFlow/PyTorch:深度学习框架,用于构建和训练神经网络。
安装:
pip install numpy pandas matplotlib scikit-learn tensorflow2. 数据预处理
加载数据
import pandas as pd
# 示例数据
data = pd.DataFrame({
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Target': [1, 0, 1, 0, 1]
})
print(data)
输出:
Feature1 Feature2 Target
0 1 5 1
1 2 4 0
2 3 3 1
3 4 2 0
4 5 1 1特征缩放
归一化或标准化数据有助于提升模型性能。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = pd.DataFrame({
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Target': [1, 0, 1, 0, 1]
})
scaler = MinMaxScaler()
scaled_features = scaler.fit_transform(data[['Feature1', 'Feature2']])
print(scaled_features)
输出:
[[0. 1. ]
[0.25 0.75]
[0.5 0.5 ]
[0.75 0.25]
[1. 0. ]]3. 数据可视化
利用Matplotlib和Seaborn绘制数据分布图。
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.DataFrame({
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Target': [1, 0, 1, 0, 1]
})
scaler = MinMaxScaler()
scaled_features = scaler.fit_transform(data[['Feature1', 'Feature2']])
print(scaled_features)
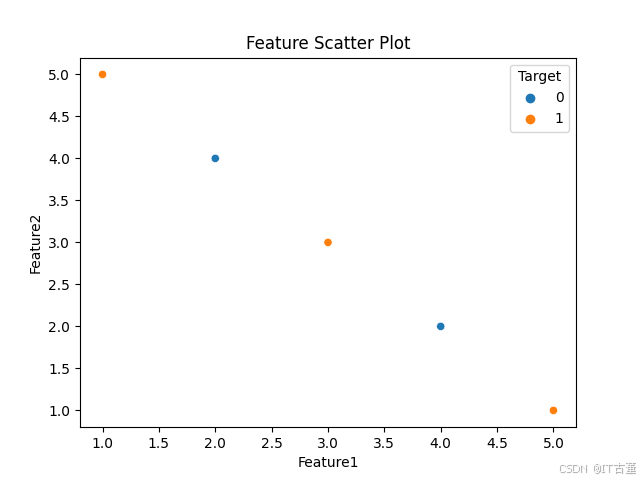
# 散点图
sns.scatterplot(x='Feature1', y='Feature2', hue='Target', data=data)
plt.title('Feature Scatter Plot')
plt.show()
4. 构建第一个机器学习模型
使用Scikit-learn实现分类模型。
拆分数据
import pandas as pd
from sklearn.model_selection import train_test_split
data = pd.DataFrame({
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Target': [1, 0, 1, 0, 1]
})
X = data[['Feature1', 'Feature2']]
y = data['Target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print('X_train:')
print(X_train)
print('X_test:')
print(X_test)
print('y_train:')
print(y_train)
print('y_test:')
print(y_test)
X_train:
Feature1 Feature2
4 5 1
2 3 3
0 1 5
3 4 2
X_test:
Feature1 Feature2
1 2 4
y_train:
4 1
2 1
0 1
3 0
Name: Target, dtype: int64
y_test:
1 0
Name: Target, dtype: int64训练模型
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
data = pd.DataFrame({
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Target': [1, 0, 1, 0, 1]
})
X = data[['Feature1', 'Feature2']]
y = data['Target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 随机森林分类器
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
Accuracy: 0.05. 深度学习与神经网络
构建一个简单的神经网络进行分类任务。
安装TensorFlow
conda install tensorflow如果安装遇到Could not solve for environment spec错误,请先执行以下命令
conda create -n tf_env python=3.8
conda activate tf_env 构建模型
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 构建神经网络
model = Sequential([
Dense(8, input_dim=2, activation='relu'),
Dense(4, activation='relu'),
Dense(1, activation='sigmoid')
])
编译与训练
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, batch_size=1, verbose=1)
评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)
完整代码
import pandas as pd
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
data = pd.DataFrame({
'Feature1': [1, 2, 3, 4, 5],
'Feature2': [5, 4, 3, 2, 1],
'Target': [1, 0, 1, 0, 1]
})
X = data[['Feature1', 'Feature2']]
y = data['Target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建神经网络
model = Sequential([
Dense(8, input_dim=2, activation='relu'),
Dense(4, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, batch_size=1, verbose=1)
loss, accuracy = model.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)
输出:
Epoch 1/50
4/4 [==============================] - 1s 1ms/step - loss: 0.6867 - accuracy: 0.5000
Epoch 2/50
4/4 [==============================] - 0s 997us/step - loss: 0.6493 - accuracy: 0.5000
Epoch 3/50
4/4 [==============================] - 0s 997us/step - loss: 0.6183 - accuracy: 0.5000
Epoch 4/50
4/4 [==============================] - 0s 665us/step - loss: 0.5920 - accuracy: 0.5000
Epoch 5/50
4/4 [==============================] - 0s 1ms/step - loss: 0.5702 - accuracy: 0.5000
Epoch 6/50
4/4 [==============================] - 0s 997us/step - loss: 0.5612 - accuracy: 0.7500
Epoch 7/50
4/4 [==============================] - 0s 998us/step - loss: 0.5405 - accuracy: 0.7500
Epoch 8/50
4/4 [==============================] - 0s 665us/step - loss: 0.5223 - accuracy: 0.7500
Epoch 9/50
4/4 [==============================] - 0s 1ms/step - loss: 0.5047 - accuracy: 0.7500
Epoch 10/50
4/4 [==============================] - 0s 665us/step - loss: 0.4971 - accuracy: 0.7500
Epoch 11/50
4/4 [==============================] - 0s 997us/step - loss: 0.4846 - accuracy: 0.7500
Epoch 12/50
4/4 [==============================] - 0s 997us/step - loss: 0.4762 - accuracy: 0.7500
Epoch 13/50
4/4 [==============================] - 0s 665us/step - loss: 0.4753 - accuracy: 0.7500
Epoch 14/50
4/4 [==============================] - 0s 997us/step - loss: 0.4623 - accuracy: 1.0000
Epoch 15/50
4/4 [==============================] - 0s 998us/step - loss: 0.4563 - accuracy: 1.0000
Epoch 16/50
4/4 [==============================] - 0s 998us/step - loss: 0.4530 - accuracy: 1.0000
Epoch 17/50
4/4 [==============================] - 0s 997us/step - loss: 0.4469 - accuracy: 1.0000
Epoch 18/50
4/4 [==============================] - 0s 997us/step - loss: 0.4446 - accuracy: 0.7500
Epoch 19/50
4/4 [==============================] - 0s 665us/step - loss: 0.4385 - accuracy: 0.7500
Epoch 20/50
4/4 [==============================] - 0s 998us/step - loss: 0.4355 - accuracy: 0.7500
Epoch 21/50
4/4 [==============================] - 0s 997us/step - loss: 0.4349 - accuracy: 0.7500
Epoch 22/50
4/4 [==============================] - 0s 665us/step - loss: 0.4290 - accuracy: 0.7500
Epoch 23/50
4/4 [==============================] - 0s 997us/step - loss: 0.4270 - accuracy: 0.7500
Epoch 24/50
4/4 [==============================] - 0s 997us/step - loss: 0.4250 - accuracy: 0.7500
Epoch 25/50
4/4 [==============================] - 0s 665us/step - loss: 0.4218 - accuracy: 0.7500
Epoch 26/50
4/4 [==============================] - 0s 997us/step - loss: 0.4192 - accuracy: 0.7500
Epoch 27/50
4/4 [==============================] - 0s 997us/step - loss: 0.4184 - accuracy: 0.7500
Epoch 28/50
4/4 [==============================] - 0s 665us/step - loss: 0.4152 - accuracy: 0.7500
Epoch 29/50
4/4 [==============================] - 0s 997us/step - loss: 0.4129 - accuracy: 0.7500
Epoch 30/50
4/4 [==============================] - 0s 997us/step - loss: 0.4111 - accuracy: 0.7500
Epoch 31/50
4/4 [==============================] - 0s 997us/step - loss: 0.4095 - accuracy: 0.7500
Epoch 32/50
4/4 [==============================] - 0s 997us/step - loss: 0.4070 - accuracy: 0.7500
Epoch 33/50
4/4 [==============================] - 0s 997us/step - loss: 0.4053 - accuracy: 0.7500
Epoch 34/50
4/4 [==============================] - 0s 997us/step - loss: 0.4033 - accuracy: 0.7500
Epoch 35/50
4/4 [==============================] - 0s 998us/step - loss: 0.4028 - accuracy: 0.7500
Epoch 36/50
4/4 [==============================] - 0s 997us/step - loss: 0.3998 - accuracy: 0.7500
Epoch 37/50
4/4 [==============================] - 0s 1ms/step - loss: 0.3978 - accuracy: 0.7500
Epoch 38/50
4/4 [==============================] - 0s 997us/step - loss: 0.3966 - accuracy: 0.7500
Epoch 39/50
4/4 [==============================] - 0s 665us/step - loss: 0.3946 - accuracy: 0.7500
Epoch 40/50
4/4 [==============================] - 0s 997us/step - loss: 0.3926 - accuracy: 0.7500
Epoch 41/50
4/4 [==============================] - 0s 997us/step - loss: 0.3918 - accuracy: 0.7500
Epoch 42/50
4/4 [==============================] - 0s 997us/step - loss: 0.3898 - accuracy: 0.7500
Epoch 43/50
4/4 [==============================] - 0s 997us/step - loss: 0.3877 - accuracy: 0.7500
Epoch 44/50
4/4 [==============================] - 0s 997us/step - loss: 0.3861 - accuracy: 0.7500
Epoch 45/50
4/4 [==============================] - 0s 665us/step - loss: 0.3842 - accuracy: 0.7500
Epoch 46/50
4/4 [==============================] - 0s 665us/step - loss: 0.3830 - accuracy: 0.7500
Epoch 47/50
4/4 [==============================] - 0s 997us/step - loss: 0.3815 - accuracy: 0.7500
Epoch 48/50
4/4 [==============================] - 0s 665us/step - loss: 0.3790 - accuracy: 0.7500
Epoch 49/50
4/4 [==============================] - 0s 665us/step - loss: 0.3778 - accuracy: 0.7500
Epoch 50/50
4/4 [==============================] - 0s 997us/step - loss: 0.3768 - accuracy: 0.7500
1/1 [==============================] - 0s 277ms/step - loss: 2.8638 - accuracy: 0.0000e+00
Loss: 2.863826274871826
Accuracy: 0.06. 数据聚类
实现一个K-Means聚类模型:
from sklearn.cluster import KMeans
# 数据
data_points = [[1, 2], [2, 3], [3, 4], [8, 7], [9, 8], [10, 9]]
# K-Means
kmeans = KMeans(n_clusters=2)
kmeans.fit(data_points)
# 输出聚类中心
print("Cluster Centers:", kmeans.cluster_centers_)
输出:
Cluster Centers: [[9. 8.]
[2. 3.]]7. 自然语言处理 (NLP)
使用NLTK处理文本数据:
pip install nltk文本分词
import nltk
nltk.download('punkt_tab')
nltk.download('punkt')
from nltk.tokenize import word_tokenize
text = "Machine learning is amazing!"
tokens = word_tokenize(text)
print(tokens)
输出:
['Machine', 'learning', 'is', 'amazing', '!']词袋模型
from sklearn.feature_extraction.text import CountVectorizer
texts = ["I love Python", "Python is great for AI"]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
print(X.toarray())
输出:
[[0 0 0 0 1 1]
[1 1 1 1 0 1]]8. 实用案例:房价预测
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载数据集
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# 数据拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
print("Model Coefficients:", model.coef_)
# 评估
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
输出:
Model Coefficients: [ 4.48674910e-01 9.72425752e-03 -1.23323343e-01 7.83144907e-01
-2.02962058e-06 -3.52631849e-03 -4.19792487e-01 -4.33708065e-01]
Mean Squared Error: 0.5558915986952442总结
本教程涵盖了Python在机器学习和人工智能领域的基础应用,从数据预处理、可视化到模型构建和评估,再到深度学习的基本实现。通过这些示例,你可以逐步掌握如何使用Python进行机器学习和AI项目开发。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【人工智能】Python在机器学习与人工智能中的应用

发表评论 取消回复