一.为什么要使用消息队列?
使用消息队列,其实是需要根据实际业务场景来的,一般都是实际开发中,遇到了某种技术挑战,如果不使用MQ的话,业务实现起来比较麻烦,但是通过MQ就可以更快捷高效的实现业务功能。
消息队列使用有很多好处,比较核心的三个好处:解耦、异步、削峰。
1.异步
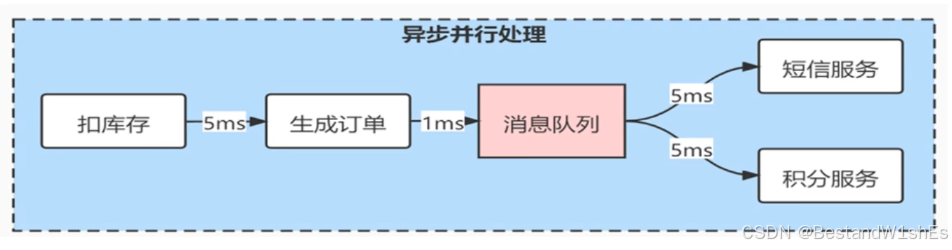
例如,用户下一个订单,它涉及到扣库存,同时会生成订单,然后向用户发送短信服务和积分服务,如果这个流程实现成一个同步的过程,那么业务线就很长,耗时就特别长,需要15ms,但如果中间加入一个消息队列,这种情况,用户下单,然后扣库存,生成订单,只要把消息写入消息队列,这时它的业务就结束了,对于用户来说,只需要耗时6ms,比起前面的15ms,这种方式可以异步提高用户的相应时间,后面这个消息再通过异步的方式发给了短信服务和积分服务;
如果我们在进行短信发送的时候,比如短信的第三方(移动、联通、电信)宕机了,如果采用的是同步的方式,那么用户的下单就不能成功,但是如果加入了消息队列,其实是没有任何影响的,就算宕机,用户也可以正常下单,等短信服务恢复后,这个消息依然可以通过异步的方式发给用户,这就可以避免第三方服务宕机带来的不好影响。
2.解耦
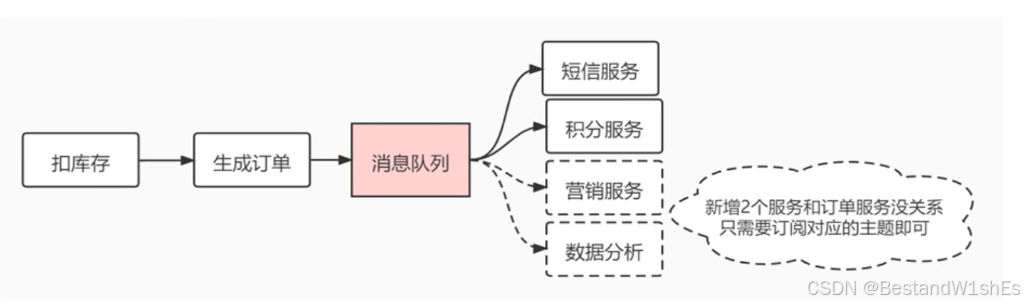
最开始生成订单后的消息只需要发送给短信服务和积分服务,但是后续业务扩大,我们还有要把消息发送给营销服务和进行数据分析的业务场景,如果此时没有消息队列的情况下,是需要去修改生成订单后的业务处理逻辑,这样的代码就具有耦合性,但是如果加入了消息队列,这个时候其实是解耦的,后续新增功能对这个条消息的处理,对前面的业务系统是没有任何影响的,本质上新增两个服务,我只需要新增两个消费者去定订阅相关的主题就可以了,这样这条消息依然可以发到对于的服务中,解耦后可以提高系统可用性和扩展性,哪怕后续再新增10个、100个业务场景,对原来的业务代码的侵入性也是相当小的。
3.削峰

在我们日程的业务中,业务的处理量其实是不平均的,比如每天0点到16 点,系统风平浪静,每秒并发请求数量就100个,结果每次一到16 点至23点,每秒并发请求数量突然会暴增到1万条,但是系统的后端服务的最大的业务处理能力就只能是每秒钟处理1000个请求,多余的9000个请求,是处理不了的,那么这个时候就可以使用消息队列进行流量的削峰,让系统可以平缓的处理突增的请求,因为消息队列里面有一个很重要的功能,是可以把过来的请求进行短暂的存储的,也就是说每秒钟多于的9000条请求,是可以存在消息队列中,让系统慢慢去处理这些短暂存储的请求,相当于用时间换空间,让系统平缓的处理突增的请求。
二.如何选择合适的消息队列?
这里针对比较常用的RabbitMQ、Kafka、RocketMQ三者做区分
1.RabbitMQ
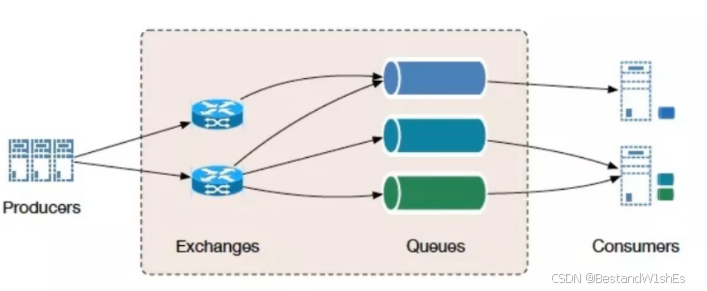
RabbitMQ 有一个生产者(Producers)和一个消费者(Consumers),首先作为生产者,发送消息给一个叫做交换器的东西(Exchanges),然后交换器会把消息路由到一个它对应的队列(Queues),然后消费者直接拿到这个队列里面的消息,进行对应的消费。
(1)基本介绍
1)RabbitMQ 于 2007 年发布,是使用 Erlang 编程语言编写的,最早是为电信行业系统之间的可靠通信设计的,也是少数几个支持 AMQP 协议的消息队列之一;
2)RabbitMQ 的轻量级、迅捷是它的宣传口号,也很明确地表明了 RabbitMQ 的特点:Messaging that just works,开箱即用的消息队列,也就是说,RabbitMQ 是一个相当轻量级的消息队列,非常容器部署和使用;
3)RabbitMQ 的客户端支持的编程语言大概是所有消息队列中最多的。
(2)存在的问题
1)RabbitMQ 对消息堆积的支持并不好,当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降;
2)RabbitMQ 的性能是这几个消息队列(相对于Kafka、RocketMQ)中最差的,大概每秒钟可以处理几万到十几万条消息,如果应用对消息队列的性能要求非常高,那不要选择 RabbitMQ,比较适用于中小型公司,如果是大项目不太适应,因为他的并发量并不高;
3)RabbitMQ 使用的编程语言 Erlang,扩展和二次开发成本高。
2.Kafka
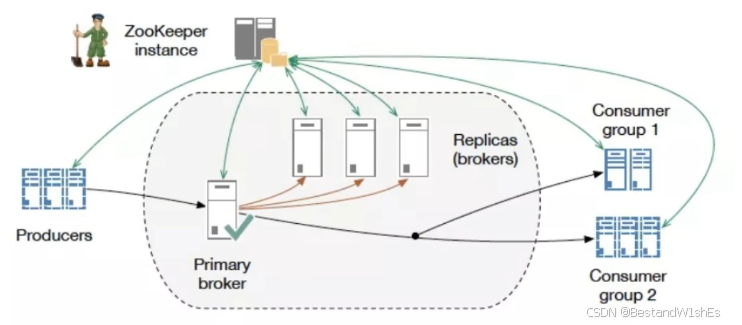
Kafka其实是依赖于Zookeeper的,安装Kafka是需要安装Zookeeper来做服务的注册和发现的,它有一个生产者(Producers)和一个消费者(Consumers),只是说它在处理的时候,可以可以进行分布式的部署,可以部署多台Broker,这是Kafka的一个特点。
(1)基本介绍
1)Apache Kafka 是一个分布式消息发布订阅系统,它最初由 Linkedln 公司基于独特的设计实现为一个分布式的日志提交系统,之后成为 Apache 项目的一部分;
2)在早期的版本中,为了获得极致的性能,在设计方面做了很多的牺牲,比如不保证消息的可靠性,可能会丢失消息,也不支持集群,功能上也比较简陋,这些牺牲对于处理海量日志这个特定的场景都是可以接受的,但是,随后几年 Kafka 逐步补齐了这些短板,当下的 Kafka 已经发展为一个非常成熟的消息队列产品,无论在数据可靠性、稳定性和功能特性等方面都可以满足绝大多数场景的需求。
3)Kafka与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所有的相关开源软件系统都会优先支持 Kafka;
4)Kafka 性能高效、可扩展良好并且可以磁盘持久化,它的分区特性,可复制和可容错都是不错的特性,Kafka 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,使得 Kafka 能做到超高的性能,Kafka 的性能,尤其是异步收发的性能,是三者中最好的,但与 RocketMQ 并没有量级上的差异,大约每秒钟可以处理几十万甚至上百万条消息;
5)在有足够的客户端并发进行异步批量发送,并且开启压缩的情况下,Kafka 的极限处理能力可以超过每秒 2000 万条消息。
(2)存在的问题
Kafka 异步批量的设计带来的问题是,它的同步收发消息的响应时延比较高,因为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批消息再发送,在它的 Broker中,很多地方都会使用这种先攒一波再一起处理的设计,当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高,所以,Kafka 不太适合在线业务场景,topic达到上百个时,吞吐量会大幅下降(比如,像电商场景,topic是相当的多,kafka就并不适用,所以它比较适用于日志场景,里面的topic相对来说比较少)。
3.RocketMQ
RocketMQ 也是一个分布式的,它可以部署Master节点,也可以部署Slave节点,也可以多Matster、多Slave的,它里面还有一个NameServer,这个是可以用来取代Zookeeper来完成服务的注册和发现。

(1)基本介绍
1)RocketMQ 是阿里巴巴在 2012 年开源的消息队列产品,用Java 语言实现,在设计时参考了Kafka,并做出了自己的一些改进,后来捐赠给 Apache 软件基金会,2017 正式毕业,成为Apache 的顶级项目,RocketMQ 在阿里内部被广泛应用在订单、交易、充值、流计算、消息推送、日志流式处理、Binglog 分发等场景,经历过多次双十一考验,它的性能、稳定性和可靠性都是值得信赖的;
2)RocketMQ 有着不错的性能,稳定性和可靠性,具备一个现代的消息队列应该有的几乎全部功能和特性,并且它还在持续的成长中,阿里还有很多人在进行维护;
3)RocketMQ 有非常活跃的中文社区,大多数问题可以找到中文的答案,RocketMQ 使用 Java 语言开发,源代码相对比较容易读懂,容易对 RocketMQ 进行扩展或者二次开发;
4)RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ;
5)RocketMQ 的性能比 RabbitMQ 要高一个数量级,每秒钟大概能处理几十万接近上百万条消息。
(2)存在的问题
RocketMQ 的劣势是与周边生态系统的集成和兼容程度不够(因为它发展的比较晚,而且是Java开发,比如对C、C++、GO等语言的兼容性程度不够)。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 彻底理解消息队列的作用及如何选择

发表评论 取消回复