概述
- 本文所涉及的所有资源的获取方式:https://www.aspiringcode.com/content?id=100000000027&uid=2f1061526e3a4548ab2e111ad079ea8c
论文标题:
本文提出了 VoiceLDM,这是一种旨在生成准确遵循两种不同自然语言文本提示的音频的模型:描述提示和内容提示。前者提供有关音频整体环境背景的信息,而后者则传达语言内容。为了实现这一目标,我们采用基于潜在扩散模型的文本到音频(TTA)模型,并扩展其功能以纳入额外的内容提示作为条件输入。通过利用预训练对比语言音频预训练 (CLAP) 和 Whisper,VoiceLDM 可以在大量真实世界音频上进行训练,而无需手动注释或转录。此外,我们采用双分类器免费引导来进一步增强 VoiceLDM 的可控性。实验结果表明,VoiceLDM 能够生成与两种输入条件均吻合的可信音频,甚至超过了 AudioCaps 测试集上真实音频的语音清晰度。此外,我们还探索了 VoiceLDM 的文本转语音 (TTS) 和零样本文本转音频功能,并表明它取得了有竞争力的结果。
演示效果
可以看到演示效果(暂时只支持英文,不过试了一下拼音,效果尚可)

1、描述一个环境,比如:She is talking in a park! 2、写下一段内容,比如:Good morning! How are you feeling today? 3、程序就可以输出一段环境语音,让你一下子就能感受到:早晨鸟语花香的公园里,她在跟人家亲切的打招呼的场景语音
核心逻辑
详见描述
环境声(文本转音频) + 说话声(文字转语音) = 场景合成声(环境控制的文本转语音)
使用方式
生成带有描述提示和内容提示的音频
python generate.py --desc_prompt "She is talking in a park." --cont_prompt "Good morning! How are you feeling today?"
上述程序初次调用会下载对应模型,有些资源可能需要魔法:

涉及的模型(运行程序时会自动下载):
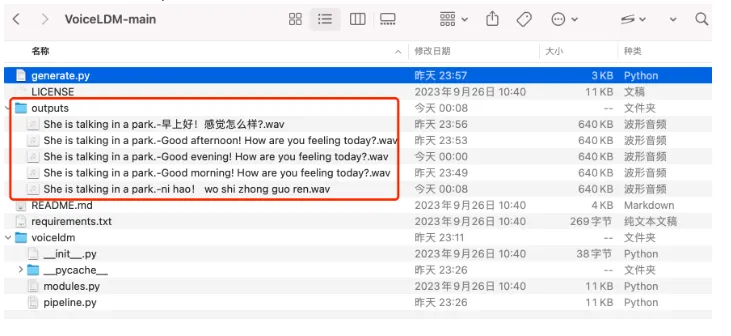
成功后会生成语音在outputs文件夹下:
- 本文所涉及的所有资源的获取方式:https://www.aspiringcode.com/content?id=100000000027&uid=2f1061526e3a4548ab2e111ad079ea8c
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 环境背景文本到语音转换

发表评论 取消回复