机器学习周志华学习笔记-第6章<支持向量机>
6支持向量机
支持向量机是一种经典的二分类模型,是一种监督学习算法。基本模型定义为特征空间中最大间隔的线性分类器,其学习的优化目标便是间隔最大化,因此支持向量机本身可以转化为一个凸二次规划求解的问题。
6.1 函数间隔与几何间隔
对于二分类学习,假设现在的数据是线性可分的,这时分类学习最基本的想法就是找到一个合适的超平面,该超平面能够将不同类别的样本分开,类似二维平面使用
a
x
+
b
y
+
c
=
0
ax+by+c=0
ax+by+c=0来表示,超平面实际上表示的就是高维的平面,如下图所示:
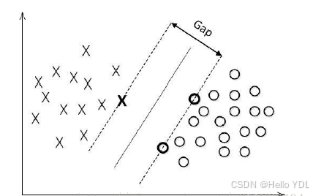
6.1.1 函数间隔
在超平面
ω
’
x
+
b
=
0
\omega’x+b=0
ω’x+b=0确定的情况下,
∣
ω
’
x
∗
+
b
∣
|\omega’x^*+b|
∣ω’x∗+b∣能够代表点
x
∗
x^*
x∗距离超平面的远近,易知:当
ω
’
x
∗
+
b
>
0
\omega’x^*+b>0
ω’x∗+b>0时,表示
x
∗
x^*
x∗在超平面的一侧(正类,类标为1),而当
ω
’
x
∗
+
b
<
0
\omega’x^*+b<0
ω’x∗+b<0时,则表示
x
∗
x^*
x∗在超平面的另外一侧(负类,类别为-1)。因此
(
ω
’
x
∗
+
b
)
y
∗
(\omega’x^*+b)y^*
(ω’x∗+b)y∗的正负性恰能表示数据点
x
∗
x^*
x∗是否被分类正确。于是便引出了函数间隔的定义(functional margin):
γ
^
=
y
(
ω
T
x
+
b
)
=
y
f
(
x
)
\hat{\gamma}=y\left(\omega^{T} x+b\right)=y f(x)
γ^=y(ωTx+b)=yf(x)
而超平面
(
ω
,
b
)
(\omega,b)
(ω,b)关于所有样本点
(
X
i
,
Y
i
)
(X_i,Y_i)
(Xi,Yi)的函数间隔最小值则为超平面在训练数据集T上的函数间隔:
γ
^
=
min
γ
^
i
,
(
i
=
1
,
…
,
n
)
\hat{\gamma}=\min \hat{\gamma}_{i},(i=1, \ldots, n)
γ^=minγ^i,(i=1,…,n)
可以看出:这样定义的函数间隔在处理SVM上会有问题,当超平面的两个参数
ω
\omega
ω和
b
b
b同比例改变时,函数间隔也会跟着改变,但是实际上超平面还是原来的超平面,并没有变化。例如:
ω
1
x
1
+
ω
2
x
2
+
ω
3
x
3
+
b
=
0
\omega_1x_1+\omega_2x_2+\omega_3x_3+b=0
ω1x1+ω2x2+ω3x3+b=0其实等价于
2
ω
1
x
1
+
2
ω
2
x
2
+
2
ω
3
x
3
+
2
b
=
0
2\omega_1x_1+2\omega_2x_2+2\omega_3x_3+2b=0
2ω1x1+2ω2x2+2ω3x3+2b=0,但计算的函数间隔却翻了一倍。从而引出了能真正度量点到超平面距离的概念–几何间隔(geometrical margin)。
6.1.2 几何间隔
几何间隔代表的则是数据点到超平面的真实距离,对于超平面 ω ’ x + b = 0 \omega’x+b=0 ω’x+b=0, ω \omega ω代表的是该超平面的法向量,设 x ∗ x^* x∗为超平面外一点 x x x在法向量 ω \omega ω方向上的投影点, x x x与超平面的距离为 γ \gamma γ,则有 x ∗ = x − γ ( ω / ∣ ∣ ω ∣ ∣ ) x^*=x-\gamma(\omega/||\omega||) x∗=x−γ(ω/∣∣ω∣∣),又 x ∗ x^* x∗在超平面上,即 ω ’ x ∗ + b = 0 \omega’x^*+b=0 ω’x∗+b=0,代入即可得:
γ
=
ω
T
x
+
b
∥
ω
∥
=
f
(
x
)
∥
ω
∥
\gamma=\frac{\omega^{T} x+b}{\|\omega\|}=\frac{f(x)}{\|\omega\|}
γ=∥ω∥ωTx+b=∥ω∥f(x)
为了得到
γ
\gamma
γ的绝对值,令
γ
\gamma
γ乘上其对应的类别
y
y
y,即可得到几何间隔的定义:
γ
~
=
y
γ
=
γ
^
∥
ω
∥
\tilde{\gamma}=y \gamma=\frac{\hat{\gamma}}{\|\omega\|}
γ~=yγ=∥ω∥γ^
从上述函数间隔与几何间隔的定义可以看出:实质上函数间隔就是
∣
ω
’
x
+
b
∣
|\omega’x+b|
∣ω’x+b∣,而几何间隔就是点到超平面的距离。
6.2 最大间隔与支持向量
通过前面的分析可知:函数间隔不适合用来最大化间隔,因此这里我们要找的最大间隔指的是几何间隔,于是最大间隔分类器的目标函数定义为:
max
γ
~
y
i
(
ω
T
x
i
+
b
)
=
γ
^
i
≥
γ
^
,
i
=
1
,
…
,
n
\begin{array}{l} \max \tilde{\gamma} \\ y_{i}\left(\omega^{T} x_{i}+b\right)=\hat{\gamma}_{i} \geq \hat{\gamma}, \quad i=1, \ldots, n \end{array}
maxγ~yi(ωTxi+b)=γ^i≥γ^,i=1,…,n
一般地,我们令
γ
^
\hat{\gamma}
γ^为1(这样做的目的是为了方便推导和目标函数的优化),从而上述目标函数转化为:
max
1
∥
ω
∥
,
s.t.
y
i
(
ω
T
x
i
+
b
)
≥
1
,
i
=
1
,
…
,
n
\max \frac{1}{\|\omega\|}, \quad \text { s.t. } \quad y_{i}\left(\omega^{T} x_{i}+b\right) \geq 1, i=1, \ldots, n
max∥ω∥1, s.t. yi(ωTxi+b)≥1,i=1,…,n
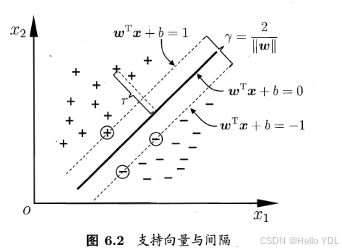
对于
y
(
ω
’
x
+
b
)
=
1
y(\omega’x+b)=1
y(ω’x+b)=1的数据点,即右图中位于
ω
’
x
+
b
=
1
\omega’x+b=1
ω’x+b=1或
ω
’
x
+
b
=
−
1
\omega’x+b=-1
ω’x+b=−1上的数据点,我们称之为支持向量(support vector),易知:对于所有的支持向量,它们恰好满足
y
∗
(
ω
’
x
∗
+
b
)
=
1
y^*(\omega’x^*+b)=1
y∗(ω’x∗+b)=1,而所有不是支持向量的点,有
y
∗
(
ω
’
x
∗
+
b
)
>
1
y^*(\omega’x^*+b)>1
y∗(ω’x∗+b)>1
6.3 对偶问题
对于上述得到的目标函数,求
1
/
∣
∣
ω
∣
∣
1/||\omega||
1/∣∣ω∣∣的最大值相当于求
∣
∣
ω
∣
∣
2
||\omega||^2
∣∣ω∣∣2的最小值,因此很容易将原来的目标函数转化为:
min
1
2
∥
ω
∥
2
,
s.t.
y
i
(
ω
T
x
i
+
b
)
≥
1
,
i
=
1
,
…
.
,
n
\min \frac{1}{2}\|\omega\|^{2}, \quad \text { s.t. } \quad y_{i}\left(\omega^{T} x_{i}+b\right) \geq 1, i=1, \ldots ., n
min21∥ω∥2, s.t. yi(ωTxi+b)≥1,i=1,….,n
即变为了一个带约束的凸二次规划问题,按书上所说可以使用现成的优化计算包(QP优化包)求解,但由于SVM的特殊性,一般我们将原问题变换为它的对偶问题,接着再对其对偶问题进行求解。为什么通过对偶问题进行求解,有下面两个原因:
- 一是因为使用对偶问题更容易求解;
- 二是因为通过对偶问题求解出现了向量内积的形式,从而能更加自然地引出
核函数。
对偶问题,顾名思义,可以理解成优化等价的问题,更一般地,是将一个原始目标函数的最小化转化为它的对偶函数最大化的问题。对于当前的优化问题,首先我们写出它的朗格朗日函数:
上式很容易验证:当其中有一个约束条件不满足时,L的最大值为 ∞(只需令其对应的
α
\alpha
α为 ∞即可);当所有约束条件都满足时,L的最大值为
1
/
2
∣
∣
ω
∣
∣
2
1/2||\omega||^2
1/2∣∣ω∣∣2(此时令所有的
α
\alpha
α为0),因此实际上原问题等价于:
min
ω
,
b
θ
(
ω
)
=
min
ω
,
b
max
α
i
≥
0
L
(
ω
,
b
,
α
)
=
p
∗
\min _{\omega, b} \theta(\omega)=\min _{\omega, b} \max _{\alpha_{i} \geq 0} L(\omega, b, \alpha)=p^{*}
ω,bminθ(ω)=ω,bminαi≥0maxL(ω,b,α)=p∗
由于这个的求解问题不好做, 因此一般我们将最小和最大的位置交换一下(需满足 KKT 条件),变成原问题的对偶问题:
max
α
i
≥
0
min
ω
,
b
L
(
ω
,
b
,
α
)
=
d
∗
\max _{\alpha_{i} \geq 0} \min _{\omega, b} L(\omega, b, \alpha)=d^{*}
αi≥0maxω,bminL(ω,b,α)=d∗
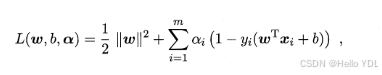
这样就将原问题的求最小变成了对偶问题求最大 (用对偶这个词还是很形象), 接下来便可先求 L 对 ω \omega ω 和 b b b 的极小, 再求 L 对 α \alpha α 的极大。
- 首先求 L 对 ω \omega ω 和 b b b 的极小, 分别求 L 关于 ω \omega ω 和 b b b 的偏导, 可以得出:
∂
L
∂
ω
=
0
⇒
ω
=
∑
i
=
1
n
α
i
y
i
x
i
∂
L
∂
b
=
0
⇒
∑
i
=
1
n
α
i
y
i
=
0
\begin{array}{l} \frac{\partial L}{\partial \omega}=0 \Rightarrow \omega=\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i} \\ \\ \frac{\partial L}{\partial b}=0 \Rightarrow \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \end{array}
∂ω∂L=0⇒ω=∑i=1nαiyixi∂b∂L=0⇒∑i=1nαiyi=0
将上述结果代入 L 得到:
L
(
ω
,
b
,
α
)
=
1
2
∑
i
,
j
=
1
n
α
i
α
j
y
i
y
j
x
i
T
x
j
−
∑
i
,
j
=
1
n
α
i
α
j
y
i
y
j
x
i
T
x
j
−
b
∑
i
=
1
n
α
i
y
i
+
∑
i
=
1
n
α
i
=
∑
i
=
1
n
α
i
−
1
2
∑
i
,
j
=
1
n
α
i
α
j
y
i
y
j
x
i
T
x
j
→
现在只包含
α
\begin{aligned} L(\omega, b, \alpha) & =\frac{1}{2} \sum_{i, j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i}^{T} x_{j}-\sum_{i, j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i}^{T} x_{j}-b \sum_{i=1}^{n} \alpha_{i} y_{i}+\sum_{i=1}^{n} \alpha_{i} \\ & =\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i}^{T} x_{j} \rightarrow \text { 现在只包含 } \alpha \end{aligned}
L(ω,b,α)=21i,j=1∑nαiαjyiyjxiTxj−i,j=1∑nαiαjyiyjxiTxj−bi=1∑nαiyi+i=1∑nαi=i=1∑nαi−21i,j=1∑nαiαjyiyjxiTxj→ 现在只包含 α
-
接着 L 关于 α \alpha α 极大求解 α \alpha α (通过 SMO 算法求解,此处不做深入)。
max α ∑ i = 1 n α i − 1 2 ∑ i , j = 1 n α i α j y i y j x i T x j s.t. α i ≥ 0 , i = 1 , … , n ∑ i = 1 n α i y i = 0 \begin{aligned} \max _{\alpha} & \sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i}^{T} x_{j} \\ \text { s.t. } & \alpha_{i} \geq 0, i=1, \ldots, n \\ & \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \end{aligned} αmax s.t. i=1∑nαi−21i,j=1∑nαiαjyiyjxiTxjαi≥0,i=1,…,ni=1∑nαiyi=0 -
最后便可以根据求解出的 , 计算出 ω \omega ω 和 b b b , 从而得到分类超平面函数。
ω ∗ = ∑ i = 1 n α i y i x i b ∗ = − max i : y i = − 1 ω ∗ T x i + min i : y i = 1 ω ∗ T x i 2 \begin{aligned} \omega^{*} & =\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i} \\ b^{*} & =-\frac{\max _{i: y_{i}=-1} \omega^{* T} x_{i}+\min _{i: y_{i}=1} \omega^{* T} x_{i}}{2} \end{aligned} ω∗b∗=i=1∑nαiyixi=−2maxi:yi=−1ω∗Txi+mini:yi=1ω∗Txi
在对新的点进行预测时, 实际上就是将数据点 x ∗ x^* x∗ 代入分类函数 f ( x ) = ω ′ x + b f(x)=\omega^{\prime} x+b f(x)=ω′x+b 中, 若 f ( x ) > 0 f(x)>0 f(x)>0 ,则为正类, f ( x ) < 0 f(x)<0 f(x)<0 , 则为负类, 根据前面推导得出的 ω \omega ω 与 b b b , 分类函数如下所示, 此时便出现了上面所提到的内积形式。
f ( x ) = ( ∑ i = 1 n α i y i x i ) T x + b = ∑ i = 1 n α i y i ⟨ x i , x ⟩ + b \begin{aligned} f(x) & =\left(\sum_{i=1}^{n} \alpha_{i} y_{i} x_{i}\right)^{T} x+b \\ & =\sum_{i=1}^{n} \alpha_{i} y_{i}\left\langle x_{i}, x\right\rangle+b \end{aligned} f(x)=(i=1∑nαiyixi)Tx+b=i=1∑nαiyi⟨xi,x⟩+b
这里实际上只需计算新样本与支持向量的内积, 因为对于非支持向量的数据点, 其对应的拉格朗日乘子一定为 0 , 根据最优化理论( K-T 条件),对于不等式约束 y ( ω ′ x + b ) − 1 ⩾ 0 \mathrm{y}\left(\mathrm{\omega}^{\prime} \mathrm{x}+\mathrm{b}\right)-1 \geqslant 0 y(ω′x+b)−1⩾0 ,满足:
∂ i ( y i ( ω T x i + b ) − 1 ) = 0 ⇒ 即总有一个为 0 \partial_{i}\left(\mathrm{y}_{i}\left(\omega^{T} \mathrm{x}_{i}+\mathrm{b}\right)-1\right)=0 \Rightarrow \text { 即总有一个为 } 0 ∂i(yi(ωTxi+b)−1)=0⇒ 即总有一个为 0
6.4 核函数
由于上述的超平面只能解决线性可分的问题, 对于线性不可分的问题, 例如: 异或问题, 我们需要使用核函数将其进行推广。一般地, 解决线性不可分问题时, 常常采用咉射的方式, 将低维原始空间映射到高维特征空间, 使得数据集在高维空间中变得线性可分, 从而再使用线性学习器分类。如果原始空间为有限维, 即属性数有限, 那么总是存在一个高维特征空间使得样本线性可分。若 ∅ \varnothing ∅ 代表一个映射, 则在特征空间中的划分函数变为:
f ( x ) = ω T ϕ ( x ) + b f(\boldsymbol{x})=\boldsymbol{\omega}^{\mathrm{T}} \phi(\boldsymbol{x})+b f(x)=ωTϕ(x)+b
按照同样的方法, 先写出新目标函数的拉格朗日函数, 接着写出其对偶问题, 求 L 关于
ω
\omega
ω 和 b的极大, 最后运用 SOM 求解
α
\alpha
α 。可以得出:
(1) 原对偶问题变为:
max
α
∑
i
=
1
n
α
i
−
1
2
∑
i
,
j
=
1
n
α
i
α
j
y
i
y
j
⟨
ϕ
(
x
i
)
,
ϕ
(
x
j
)
⟩
s.t.
α
i
≥
0
,
i
=
1
,
…
,
n
∑
i
=
1
n
α
i
y
i
=
0
\begin{aligned} \max _{\alpha} & \sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} \left\langle\phi\left(x_{i}\right), \phi\left(x_{j}\right)\right\rangle \\ \text { s.t. } & \alpha_{i} \geq 0, i=1, \ldots, n \\ & \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \end{aligned}
αmax s.t. i=1∑nαi−21i,j=1∑nαiαjyiyj⟨ϕ(xi),ϕ(xj)⟩αi≥0,i=1,…,ni=1∑nαiyi=0
等价于:
(2) 原分类函数变为:
f
(
x
)
=
∑
i
n
α
i
y
i
⟨
ϕ
(
x
i
)
,
ϕ
(
x
)
⟩
+
b
\begin{aligned} f(x)=\sum_{i}^{n} \alpha_{i}y_{i} \left\langle\phi\left(x_{i}\right), \phi\left(x\right)\right\rangle + b \end{aligned}
f(x)=i∑nαiyi⟨ϕ(xi),ϕ(x)⟩+b
等价于:
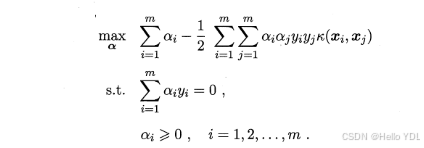

求解的过程中,只涉及到了高维特征空间中的内积运算,由于特征空间的维数可能会非常大,例如:若原始空间为二维,映射后的特征空间为5维,若原始空间为三维,映射后的特征空间将是19维,之后甚至可能出现无穷维,根本无法进行内积运算了,此时便引出了核函数(Kernel)的概念。
因此,核函数可以直接计算隐式映射到高维特征空间后的向量内积,而不需要显式地写出映射后的结果,它虽然完成了将特征从低维到高维的转换,但最终却是在低维空间中完成向量内积计算,与高维特征空间中的计算等效(低维计算,高维表现),从而避免了直接在高维空间无法计算的问题。引入核函数后,原来的对偶问题与分类函数则变为:
(1) 对偶问题:
max
α
∑
i
=
1
n
α
i
−
1
2
∑
i
,
j
=
1
n
α
i
α
j
y
i
y
j
K
(
x
i
,
x
j
)
s.t.
α
i
≥
0
,
i
=
1
,
…
,
n
∑
i
=
1
n
α
i
y
i
=
0
\begin{array}{ll} \max _{\alpha} & \sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} \red{K\left(x_{i}, x_{j}\right) }\\ \text { s.t. } & \alpha_{i} \geq 0, i=1, \ldots, n \\ & \sum_{i=1}^{n} \alpha_{i} y_{i}=0 \end{array}
maxα s.t. ∑i=1nαi−21∑i,j=1nαiαjyiyjK(xi,xj)αi≥0,i=1,…,n∑i=1nαiyi=0

(2) 分类函数:
f
(
x
)
=
∑
i
=
1
n
α
i
y
i
K
(
x
i
,
x
)
+
b
f(x)=\sum_{i=1}^{n} \alpha_{i} y_{i} \red{K\left(x_{i}, x\right)}+b
f(x)=i=1∑nαiyiK(xi,x)+b
因此,在线性不可分问题中,核函数的选择成了支持向量机的最大变数,若选择了不合适的核函数,则意味着将样本映射到了一个不合适的特征空间,则极可能导致性能不佳。同时,核函数需要满足以下这个必要条件:
由于核函数的构造十分困难,通常我们都是从一些常用的核函数中选择,下面列出了几种常用的核函数:


6.5 软间隔支持向量机
前面的讨论中,我们主要解决了两个问题:当数据线性可分时,直接使用最大间隔的超平面划分;当数据线性不可分时,则通过核函数将数据映射到高维特征空间,使之线性可分。然而在现实问题中,对于某些情形还是很难处理,例如数据中有噪声的情形,噪声数据(outlier)本身就偏离了正常位置,但是在前面的SVM模型中,我们要求所有的样本数据都必须满足约束,如果不要这些噪声数据还好,当加入这些outlier后导致划分超平面被挤歪了,如下图所示,对支持向量机的泛化性能造成很大的影响。
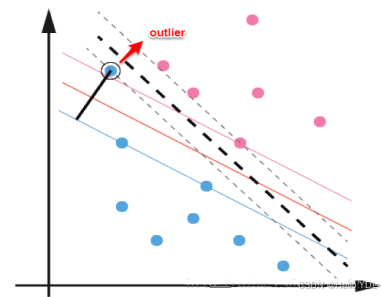
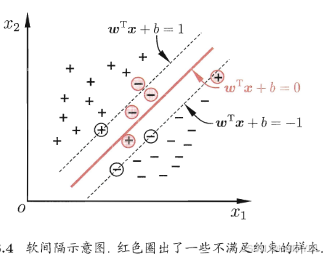
为了解决这一问题,我们需要允许某一些数据点不满足约束,即可以在一定程度上偏移超平面,同时使得不满足约束的数据点尽可能少,这便引出了“软间隔”支持向量机的概念
- 允许某些数据点不满足约束 y ( ω ′ x + b ) ≥ 1 y(\omega'x+b)≥1 y(ω′x+b)≥1;
- 同时又使得不满足约束的样本尽可能少。
这样优化目标变为:
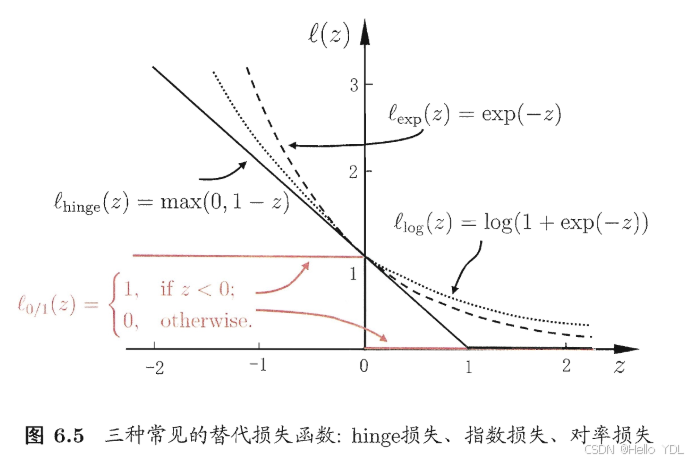
如同阶跃函数,0/1损失函数虽然表示效果最好,但是数学性质不佳。因此常用其它函数作为“替代损失函数”。
图像如下所示:
支持向量机中的损失函数为hinge损失,引入“松弛变量”,目标函数与约束条件可以写为:
书中描述如下:

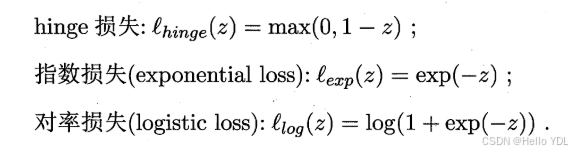
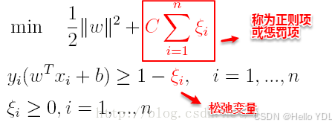

其中C为一个参数,控制着目标函数与新引入正则项之间的权重,这样显然每个样本数据都有一个对应的松弛变量,用以表示该样本不满足约束的程度,将新的目标函数转化为拉格朗日函数得到:
按照与之前相同的方法,先让L求关于
ω
,
b
\omega,b
ω,b以及松弛变量的极小,再使用SMO求出
α
\alpha
α,有:

将
ω
\omega
ω代入
L
L
L化简,便得到其对偶问题:
将“软间隔”下产生的对偶问题与原对偶问题对比可以发现:新的对偶问题只是约束条件中的
α
\alpha
α多出了一个上限C,其它的完全相同,因此在引入核函数处理线性不可分问题时,便能使用与“硬间隔”支持向量机完全相同的方法。
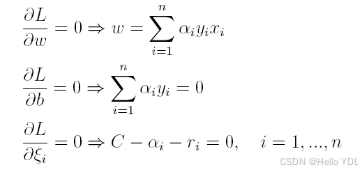

6.6 支持向量机
对样本
(
x
,
y
)
(\boldsymbol{x}, y)
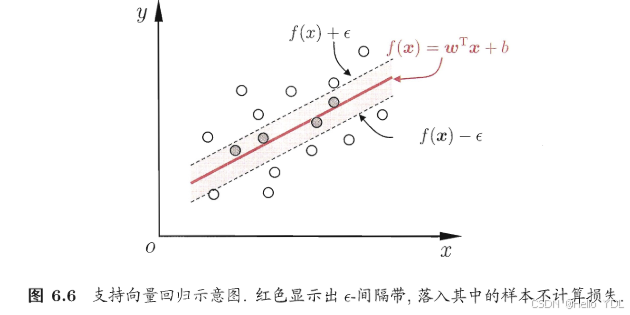
(x,y) , 传统回归模型通常直接基于模型输出 $f(\boldsymbol{x}) $ 与真实输出 $y $ 之间的差别来计算损失, 当且仅当
f
(
x
)
f(\boldsymbol{x})
f(x) 与
y
y
y 完全相同时, 损失才为零. 与此不同,支持向量回归(Support Vector Regression, 简称 SVR) 假设我们能容忍
f
(
x
)
f(\boldsymbol{x})
f(x) 与
y
y
y之间最多有
ϵ
\epsilon
ϵ的偏差, 即仅当
f
(
x
)
f(\boldsymbol{x})
f(x) 与
y
y
y 之间的差别绝对值大于
ϵ
\epsilon
ϵ 时才计算损失. 如下图所示, 这相当于以
f
(
x
)
f(x)
f(x) 为中心, 构建了一个宽度为 2
ϵ
\epsilon
ϵ 的间隔带, 若训练样本落入此间隔带, 则认为是被预测正确的。
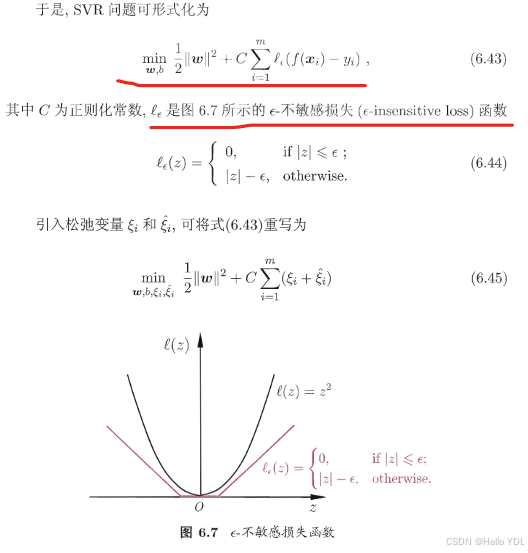
与之前类似,根据拉格朗日与对偶问题的最终转换可得:
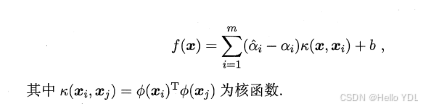
6.7核方法
表示定理对损失函数没有限制,对正则化项Ω仅要求单调递增,甚至不要求几是凸函数,意味着对于一般的损失函数和正则化项,优化问题(6.57)的最优解
h
∗
(
x
)
h*(x)
h∗(x)都可表示为核函数
κ
(
x
,
x
i
)
κ(x,x_i)
κ(x,xi)的线性组合;这显示出核函数的巨大威力。人们发展出一系列基于核函数的学习方法,统称为“核方法”(内核
方法)。最常见的,是通过“核化”(即引入核函数)来将线性学习器拓展为非线性学习器。

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习周志华学习笔记-第6章<支持向量机>

发表评论 取消回复