训练过程中,显存的主要占用来自:
- 激活值(Activations):前向传播过程中存储的中间计算结果。
- 梯度存储:用于反向传播。
- 权重和偏置参数。
一、梯度检查点(Gradient Checkpointing)
在深度学习中,反向传播需要保留前向传播过程中生成的中间激活值(activations)来计算梯度。
Gradient Checkpointing 提供了一种折衷方案,允许用时间换空间。
-
普通训练
- 在前向传播中,每一层的激活值会保存在内存中,供反向传播使用。
- 这样可以减少重复计算,但占用了大量显存。
-
Gradient Checkpointing
- 在前向传播时,只保存某些关键层(称为“检查点”)的激活值,而不是所有层的激活值。
- 在反向传播时,未保存的激活值会被重新计算。
- 这种方法减少了显存需求,但增加了计算量。
在 Hugging Face 的 Trainer 中,可以通过 TrainingArguments 启用:
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=16,
gradient_checkpointing=True, # 启用梯度检查点
num_train_epochs=3,
learning_rate=5e-5
)
这会自动启用 Trainer 使用的模型的 Gradient Checkpointing。
二、梯度累积
在深度学习中,大的批量大小(batch size)可以提高模型性能和稳定性,但直接增大批量大小需要更多的显存。如果你的 GPU 显存有限,无法直接处理大批量数据,可以使用梯度累积:
梯度累积过程
- 模型前向传播,计算每个小批量的损失。
- 反向传播,计算梯度,但不更新模型参数(梯度被累积)。
- 累积了
N个小批量的梯度后,执行一次优化器的step(),更新模型参数。 - 清空累积的梯度,进入下一个循环。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=16, # 每个设备的批量大小
gradient_accumulation_steps=4, # 每 4 个小批量累积一次
num_train_epochs=3,
)
三、混合精度训练(FP16 Precision)
混合精度训练通过在深度学习模型的训练过程中,将部分数据和计算从 32 位浮点数(FP32)转换为 16 位浮点数(FP16),从而显著减少显存使用并提高训练速度。
1. 混合精度训练的原理
在深度学习中,大部分计算可以在更低的精度(FP16)下完成,而不会影响训练的准确性和稳定性。混合精度训练结合了 FP16 和 FP32 的优势:
-
FP16(16位浮点数):
- 数据占用显存更小(相比 FP32,内存占用减半)。
- 计算速度更快(支持 FP16 的硬件如 NVIDIA Tensor Cores 能显著加速 FP16 运算)。
- 适合大多数张量的存储和计算。
-
FP32(32位浮点数):
- 用于关键操作(如梯度累积)和需要高精度的部分运算。
- 避免因精度不足导致数值不稳定。
在混合精度训练中,使用 FP16(16位浮点数) 替代传统的 FP32(32位浮点数),可以显著节省显存和提高运算速度,但也引入了一些数值稳定性问题。
2. FP16 的数值范围较小
- FP32:可以表示的数值范围非常大,适合精确运算(≈±10^38)。
- FP16:数值范围较小(≈±10^5),且精度较低,容易出现:
- 梯度下溢(Underflow):梯度值非常小,接近 0,被 FP16 表示为 0,导致权重无法正确更新。
- 梯度溢出(Overflow):梯度值非常大,超出 FP16 的范围,变为无穷大(
inf),使模型训练失败。
损失值影响梯度范围
-
损失函数的值大小会直接影响其梯度的范围:
- 如果损失值过小,梯度也可能过小,导致 下溢。
- 如果损失值过大,梯度可能过大,导致 溢出。
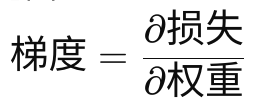
3. 动态损失缩放(Dynamic Loss Scaling)
- 为了解决 FP16 的数值稳定性问题,PyTorch 和其他框架提供了 动态损失缩放 技术。
- 核心思想:
- 损失放大:在反向传播前,将损失值乘以一个较大的缩放因子(如
1024)。 - 梯度缩小:在计算梯度后,将梯度除以相同的缩放因子,确保权重更新时的数值范围合理。
- 损失放大:在反向传播前,将损失值乘以一个较大的缩放因子(如
假设缩放因子为 scale,则:
-
放大损失:
- L:原始损失值。
- L’:放大的损失值。
- 这样可以避免梯度下溢。
-
反向传播后缩小梯度:
- ∇W’:放大损失后的梯度。
- ∇W:实际用于更新权重的梯度。
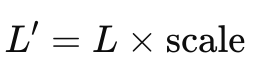
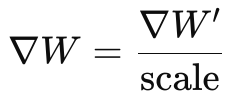
- 初始值:缩放因子一般从较大的值(如
1024)开始。 - 动态调整:
- 如果训练过程中发现梯度溢出(
NaN或inf),会减少缩放因子。 - 如果梯度稳定,会逐渐增大缩放因子以更充分利用 FP16 的范围。
- 如果训练过程中发现梯度溢出(
动态损失缩放的优点
-
避免数值不稳定
- 防止梯度因 FP16 下溢或溢出,确保权重能够正常更新。
- 动态调整能适应不同模型和任务的需求。
-
无额外显存开销
- 缩放因子只是一组标量,不会增加显存需求。
-
效率高
- 自动化的损失缩放由框架内部完成,对开发者透明,不需要手动调整。
4. 框架中的实现
在 PyTorch 中
PyTorch 的 torch.cuda.amp 提供了动态损失缩放支持:
from torch.cuda.amp import GradScaler, autocast
# 初始化损失缩放器
scaler = GradScaler()
for inputs, labels in dataloader:
optimizer.zero_grad()
# 使用混合精度
with autocast():
outputs = model(inputs)
loss = loss_fn(outputs, labels)
# 使用损失缩放
scaler.scale(loss).backward() # 缩放损失,反向传播
scaler.step(optimizer) # 更新权重
scaler.update() # 动态调整缩放因子
5. 启用混合精度训练
在 Hugging Face 中,可以通过设置 TrainingArguments 的 fp16=True 启用混合精度训练:
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./results",
learning_rate=5e-5,
per_device_train_batch_size=16,
num_train_epochs=3,
evaluation_strategy="epoch",
fp16=True, # 启用混合精度训练
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset
)
trainer.train()
6. 使用混合精度训练的硬件支持
- 混合精度训练依赖于硬件对 FP16 运算的支持。
需要支持混合精度的 GPU(如 NVIDIA Volta 架构及以上,V100/T4/A100 等)。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【深度学习】模型训练时减少GPU显存占用

发表评论 取消回复