1.Data Source 原理
a)核心组件
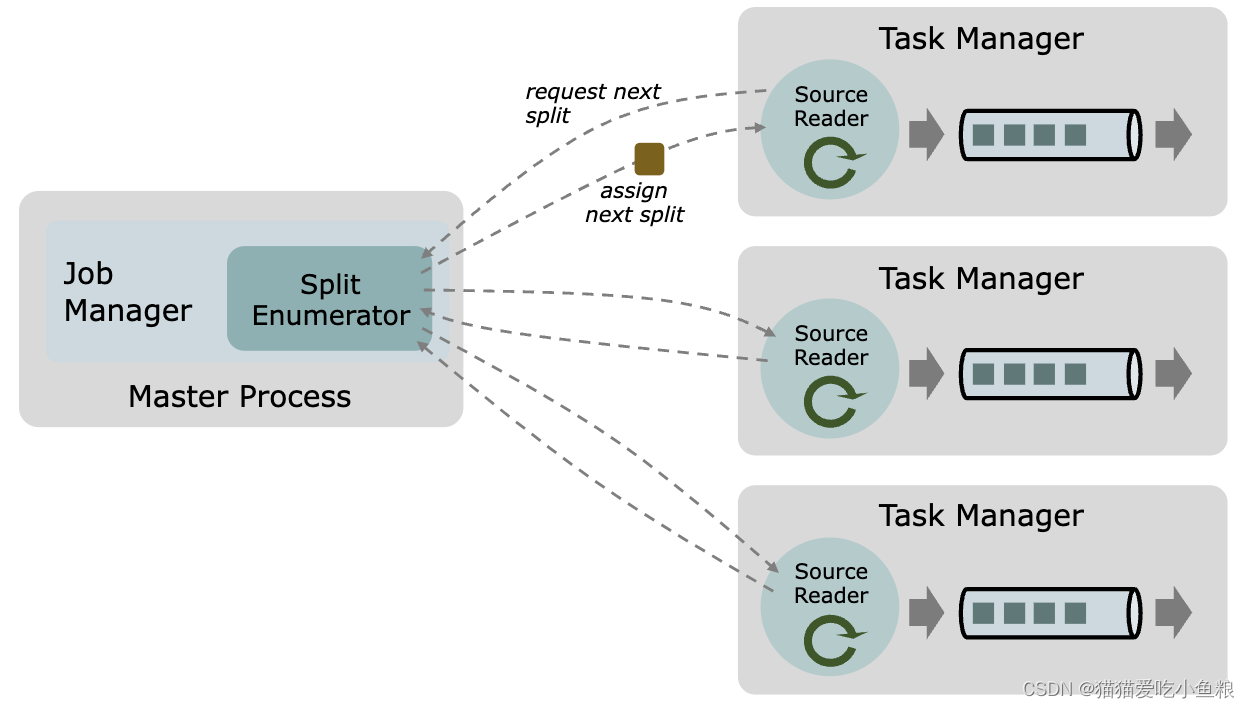
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
- 分片(Split) 是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
- 源阅读器(SourceReader) 会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的
SourceOperators并行运行,并产生并行的事件流/记录流。 - 分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
Source 类作为API入口,将上述三个组件结合在了一起。
b)流处理和批处理的统一
Data Source API 以统一的方式对无界流数据和有界批数据进行处理。
流处理和批处理区别很小:在有界/批处理情况中,枚举器生成固定数量的分片,而且每个分片都必须是有限的;但在无界流的情况下,分片大小可以不是有限的,或者枚举器将不断生成新的分片。
c)示例
展示在流和批处理情况下 data source 组件如何交互;以下内容并没有准确地描述出 Kafka 和 File source 的工作方式。
有界 File Source
Source 包含待读取目录的 URI/路径(Path),以及一个定义了如何对文件进行解析的格式(Format)。
- 分片是一个文件,或者是文件的一个区域(如果该文件格式支持对文件进行拆分)。
- SplitEnumerator 将会列举给定目录路径下的所有文件,并在收到来自 reader 的请求时对分片进行分配。一旦所有的分片都被分配完毕,则会使用 NoMoreSplits 来响应请求。
- SourceReader 则会请求分片,读取所分配的分片(文件或者文件区域),并使用给定的格式进行解析。如果当前请求没有获得下一个分片,而是 NoMoreSplits,则会终止任务。
无界 Streaming File Source
与**有界 File Source **类似,除了 SplitEnumerator 从不会使用 NoMoreSplits 来响应 SourceReader 的请求,并且还会定期列出给定 URI/路径下的文件来检查是否有新文件;一旦发现新文件,则生成对应的新分片,并将它们分配给空闲的 SourceReader。
无界 Streaming Kafka Source
Source 将具有 Kafka Topic(亦或者一系列 Topics 或者通过正则表达式匹配的 Topic)以及一个 解析器(Deserializer) 来解析记录(record)。
- 分片是一个 Kafka Topic Partition。
- SplitEnumerator 会连接到 broker 从而列举出已订阅的 Topics 中的所有 Topic Partitions。枚举器可以重复此操作以检查是否有新的 Topics/Partitions。
- SourceReader 使用 KafkaConsumer 读取所分配的分片(Topic Partition),并使用提供的 解析器 反序列化记录。由于流处理中分片(Topic Partition)大小是无限的,因此 reader 永远无法读取到数据的尾部。
有界 Kafka Source
每个分片(Topic Partition)都会有一个预定义的结束偏移量,其他与上述相同;一旦 SourceReader 读取到分片的结束偏移量,整个分片的读取就会结束。而一旦所有所分配的分片读取结束,SourceReader 也就终止任务了。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 47、Flink 的 Data Source 原理

发表评论 取消回复