1.为什么要做参数化?
在用jmeter脚本进行压测的时候,为了更真实的模拟起到更好的效果,我们需要让参数动态变化起来,也就是参数化。通过参数化我们也可以更好、更灵活的维护我们的测试脚本。
2.参数化的方式
能够实现参数化的方式有很多种,比如定义全局变量、通过函数助手、从文件中读取等方式,这里先只描述几种我比较熟悉的参数化方式,其它的之后再进行补充完善。
2.1.定义全局变量
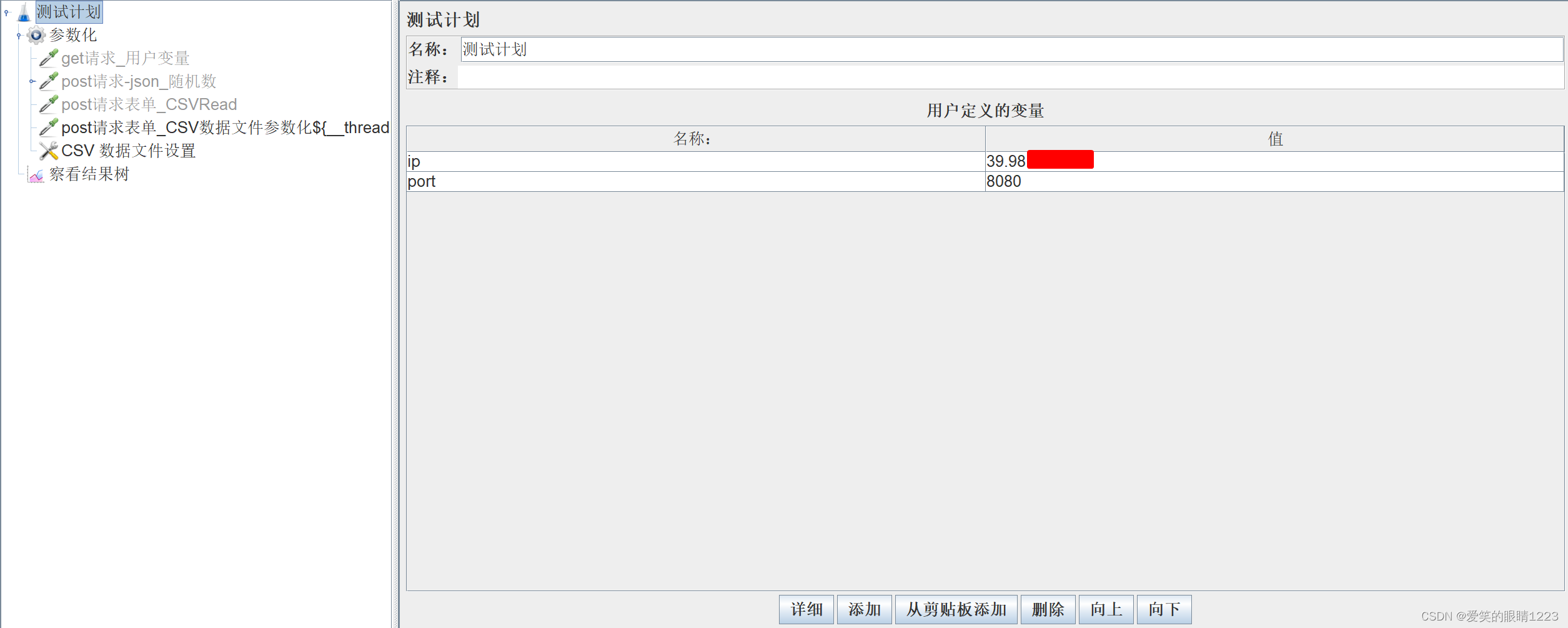
定义全局变量非常简单,只需要在测试计划页面“用户定义的变量”下维护变量名和对应的变量值,然后在需要调用变量的地方使用${变量名}即可调用变量实现参数化,如下图所示。
2.2.函数助手
函数助手也是我们经常用于参数化的方式之一,可以选择随机数(_Random)或者随机字符串(_RandomString)通过生成随机数据来进行参数化。
2.2.1.随机数
想用随机数可以在函数助手中选择_Random函数,然后设置最小值和最大值,点击生成按钮可以生成随机数的表达式,将其拷贝到所需要引用的地方即可,如生成1000~9999范围内的随机数,如下图所示。
2.2.2.随机字符串
想用随机字符串可以在函数助手中选择_RandomString函数,然后设置字符串长度和取值范围,点击生成按钮可以生成随机字符串的表达式,将其拷贝到所需要引用的地方即可,如生成1000~9999范围内的随机数,如下图所示。
2.3.从文件中读取
在函数助手中选择_CSVRead函数,在“用于获取值的CSV文件|*别名”处维护待参数化文件的路径,在“CSV文件列号”所在行维护取值列,然后点击生成按钮,即可生成变量表达式,如下图所示。
参数化文件中列与列之间用英文逗号分隔,在参数化取列的值时0代表第一列,1代表第二列,依此类推。
在实际执行过程中还发现,当有多个线程循环读取的时候,每个线程只读取1行值,如5个线程循环2次,共执行10次,只会读取到前5行所在值,1个线程循环10次都在读取第一行所在值。
小结:
csv_read函数特点:每个并发用户只读取1行,且永远使用同一行数据,无论并发用户循环多少次,执行多少个http请求。
使用场景:某些业务场景是流程式,需要分成多个http请求,且多个http请求需要用到一个共同的参数,如:用户id、用户名。
2.4.csv文件参数化
在线程组中添加“CSV数据文件设置”配置元件,在文件设置中“文件名”处维护参数化文件的路径,文件编码根据需求选择,我这里选择“UTF-8”,在“变量名称”处维护要从文件中取值的变量名,如果要取多列值,不同变量之间用英文逗号分隔,“分隔符”所在处输入英文逗号,在需要引用变量的地方用${变量名}进行引用即可。
需要注意的是:遇到文件结束符再次循环和遇到文件结束符停止线程两个值是相反的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Jmeter的几种参数化方式

发表评论 取消回复