paper:PVT v2: Improved Baselines with Pyramid Vision Transformer
official implementation:https://github.com/whai362/PVT
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/pvt_v2.py
存在的问题
在PVT v1中存在一些问题,具体如下
- 计算复杂度高:与ViT类似,当处理高分辨率输入时(例如,较短边为800像素),PVT v1的计算复杂度相对较大
- 缺少局部连续性:PVT v1将图像视为一系列不重叠的patch,这在一定程度上丧失了图像的局部连续性
- 位置编码不灵活:PVT v1将图像视为一系列不重叠的patch,这在一定程度上丧失了图像的局部连续性
本文的创新点
针对PVT v1存在的问题,PVT v2引入了以下改进
- 线性空间降维注意力:通过使用线性空间降维注意力(linear spatial reduction attention)来降低计算成本
- 重叠的patch embedding:通过重叠的patch embedding来保留图像的局部连续性
- 卷积FFN:通过引入卷积feed-forward network来增强特征表示能力,并去掉了固定大小的位置编码,采用zero padding位置编码,从而提高了处理任意大小输入的灵活性
方法介绍
Linear Spatial Reduction Attention
为了减少attention操作的高计算开销,作者提出了linear spatial reduction attention层,如图1所示。
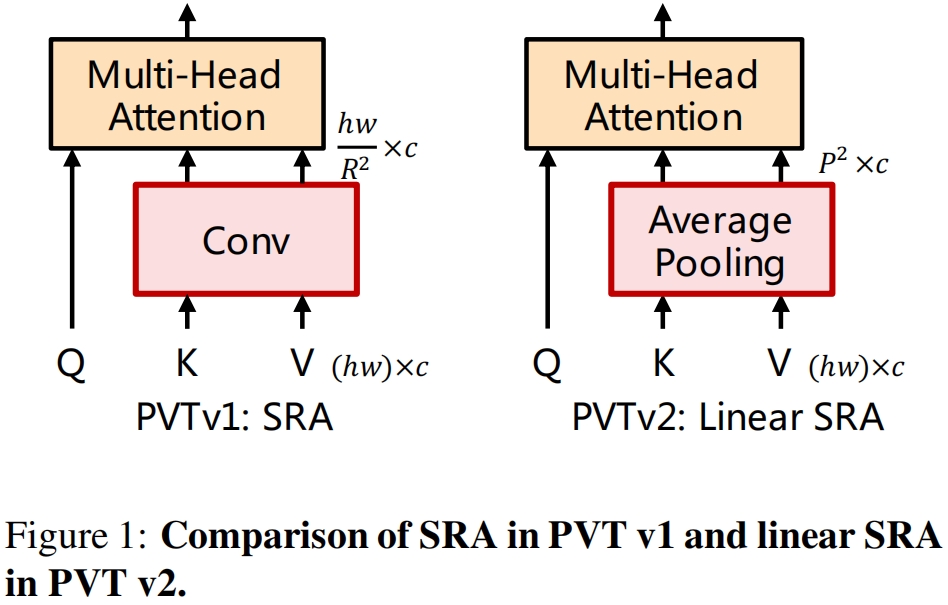
和PVT v1中的SRA采用卷积进行空间降维不同,linear SRA采用平均池化在attention operation之前将空间维度由 \(h\times w\) 减小到固定大小 \(P\times P\)。所以linear SRA就具有了线性计算和内存开销。具体来说,对于大小为 \(h\times w\times c\) 的输入,SRA和linea SRA的复杂度如下
其中 \(R\) 是SRA的spatial reduction ratio,\(P\) 是linear SRA的池化大小,设置为7。
Overlapping Patch Embedding
为了对局部连续性信息进行建模,作者采用重叠的patch embedding对图片进行tokenize。
如图2(a)所示,我们扩大patch window,使得相邻的窗口重叠一半的面积,并用zero padding来保持特征图的分辨率。具体使用卷积和zero padding来实现重叠的patch embedding,给定大小 \(h\times w\times c\) 的输入,我们对它进行卷积操作,其中stride为 \(S\),kernel size为 \(2S-1\),padding size为 \(S-1\),kernel的数量为 \(C'\),则输出大小为 \(\frac{h}{S}\times \frac{W}{S}\times C'\)。
Convolutional Feed-Forward
受CPVT(CPVT(ICLR 2023)论文解读-CSDN博客)和LocalViT(LocalViT 论文解读-CSDN博客)的启发,作者将零填充位置编码(zero padding position encoding)引入PVT。如图2(b)所示,在FFN中,作者在第一个全连接层和GELU之间引入了一个padding size为1的3x3深度卷积。
实验结果
在ImageNet上的结果如表2所示,可以看到PVT v2全面超越了PVT v1。
在下游任务目标检测和语义分割中,PVT v2也全面超越了PVT v1,如表3和表5所示
代码解析
这里讲解的是timm中的实现。首先是重叠的patch embedding,代码如下,其中stride=S=4,patch_size=kernel_size=2S-1=7,padding_size=kernel_size//2=S-1=3。
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
assert max(patch_size) > stride, "Set larger patch_size than stride"
self.patch_size = patch_size
self.proj = nn.Conv2d(
in_chans, embed_dim, patch_size,
stride=stride, padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x): # (1,3,224,224)
x = self.proj(x) # (1,64,56,56)
x = x.permute(0, 2, 3, 1) # (1,56,56,64)
x = self.norm(x)
return x接下来进入多个stage,每个stage一开始也调用OverlapPatchEmbed进行降采样,从而得到金字塔结构。这里降采样2倍,所以stride=2,patch_size=2S-1=3。
if downsample:
self.downsample = OverlapPatchEmbed(
patch_size=3,
stride=2,
in_chans=dim,
embed_dim=dim_out,
)
else:
assert dim == dim_out
self.downsample = None然后是Attention部分,代码如下。当采用v1中的SRA时,通过self.sr即卷积进行spatial降维,当采用linear SRA时,通过self.pool进行spatial降维,此时的self.sr是一个1x1-s1的卷积。
class Attention(nn.Module):
fused_attn: torch.jit.Final[bool]
def __init__(
self,
dim,
num_heads=8,
sr_ratio=1,
linear_attn=False,
qkv_bias=True,
attn_drop=0.,
proj_drop=0.
):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim # 64
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.fused_attn = use_fused_attn()
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
if not linear_attn:
self.pool = None
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio) # 64,64,8,8
self.norm = nn.LayerNorm(dim)
else:
self.sr = None
self.norm = None
self.act = None
else:
self.pool = nn.AdaptiveAvgPool2d(7)
self.sr = nn.Conv2d(dim, dim, kernel_size=1, stride=1)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU()
def forward(self, x, feat_size: List[int]):
B, N, C = x.shape # (1,3136,64)
H, W = feat_size # (56,56)
q = self.q(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3) # (1,3136,64)->(1,3136,1,64)->(1,1,3136,64)
if self.pool is not None:
x = x.permute(0, 2, 1).reshape(B, C, H, W) # (1,64,3136)->(1,64,56,56)
x = self.sr(self.pool(x)).reshape(B, C, -1).permute(0, 2, 1) # (1,64,7,7)->(1,64,49)->(1,49,64)
x = self.norm(x)
x = self.act(x)
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
else:
if self.sr is not None:
x = x.permute(0, 2, 1).reshape(B, C, H, W) # (1,3136,64)->(1,64,3136)->(1,64,56,56)
x = self.sr(x).reshape(B, C, -1).permute(0, 2, 1) # (1,64,7,7)->(1,64,49)->(1,49,64)
x = self.norm(x)
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4) # (1,49,128)->(1,49,2,1,64)->(2,1,1,49,64)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
k, v = kv.unbind(0) # (1,1,49,64),(1,1,49,64)
if self.fused_attn:
x = F.scaled_dot_product_attention(q, k, v, dropout_p=self.attn_drop.p if self.training else 0.)
else:
q = q * self.scale
attn = q @ k.transpose(-2, -1) # (1,1,3136,64) @ (1,1,64,49) -> (1,1,3136,49)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = attn @ v # (1,1,3136,49) @ (1,1,49,64) -> (1,1,3136,64)
x = x.transpose(1, 2).reshape(B, N, C) # (1,3136,1,64)->(1,3136,64)
x = self.proj(x) # (1,3136,64)
x = self.proj_drop(x)
return xAttention后就是FFN,代码如下。其中在两个fc之间加了一个深度卷积self.dwconv。
class MlpWithDepthwiseConv(nn.Module):
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.,
extra_relu=False,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.relu = nn.ReLU() if extra_relu else nn.Identity()
self.dwconv = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, bias=True, groups=hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, feat_size: List[int]): # (1,3136,64)
x = self.fc1(x) # (1,3136,512)
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, feat_size[0], feat_size[1]) # (1,512,3136)->(1,512,56,56)
x = self.relu(x)
x = self.dwconv(x) # (1,512,56,56)
x = x.flatten(2).transpose(1, 2) # (1,512,3136)->(1,3136,512)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x) # (1,3136,64)
x = self.drop(x)
return x本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PVT v2 原理与代码解析

发表评论 取消回复