参考自李宏毅课程-人类语言处理
四、GPT3
1. 介绍
GPT-3是一个language model,它的参数量相当巨大,是ELMO的2000倍。
2. GPT-3的野心
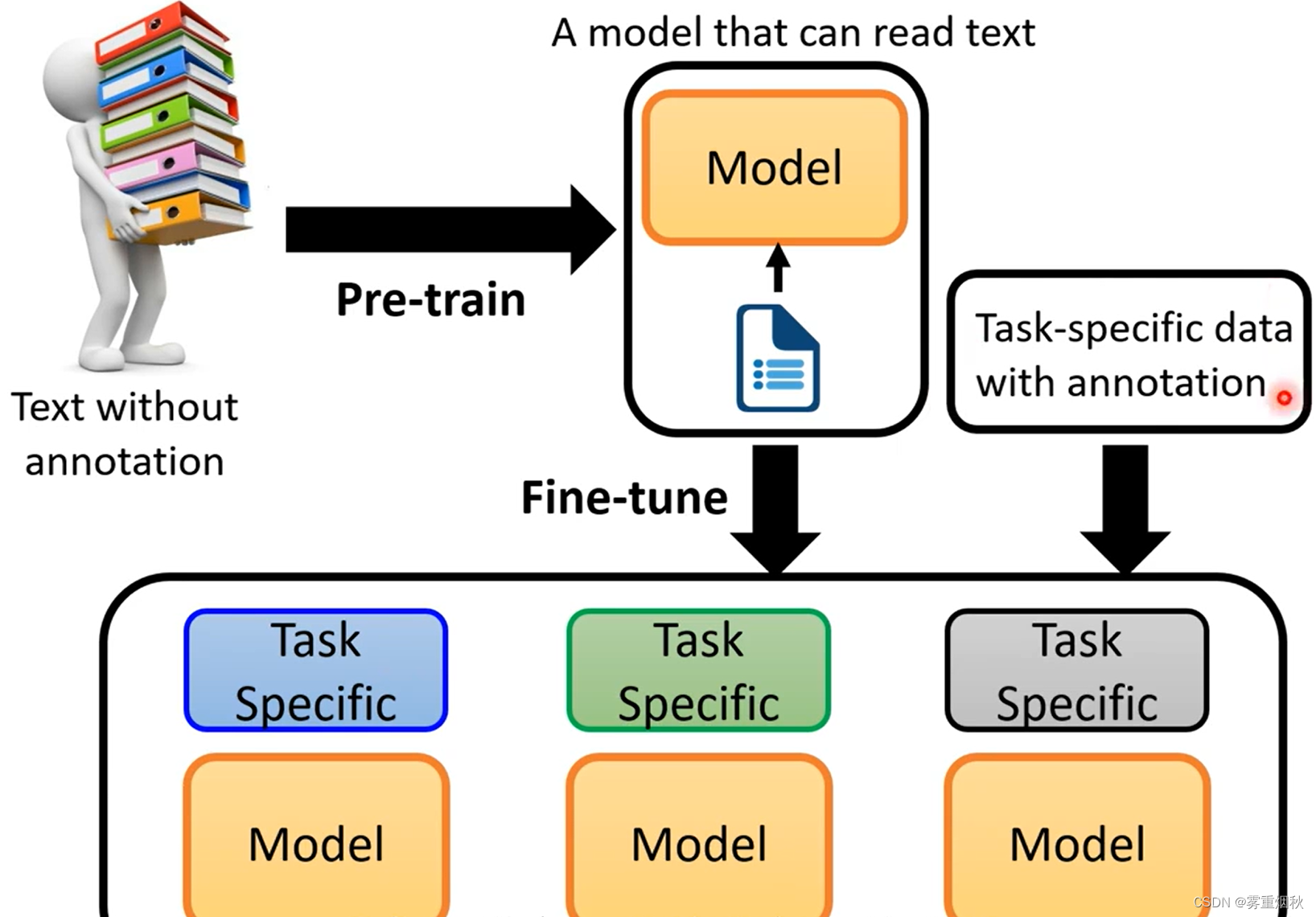
虽然GPT-3和BERT等模型一样,但是GPT-3是不需要针对特定的task做finetune的,也就是说GPT-3只需要预训练就够了。
具体来说,GPT-3定义了三种learning,第一个是“few-shot learning”,就是先告诉模型要干什么,然后给几个例子,最后给模型一个题目让它做出来,第二个是“one-shot learning”,就是告诉模型要干什么,然后给一个例子,最后给模型一个题目让它做出来;最后一个是“zero-shot learning”,就是告诉模型要干什么,然后给模型一个题目让它做出来。这就相当于人一样了,这种learning被GPT-3的作者们称作“in-context learning”。
3. GPT-3的效果
在42个NLP任务上的平均准确率随参数量的变化如下图所示,可见随着参数量的增大,准确率是在一直上升的。
GPT-3在closed book QA上的表现如下所示,之前的QA都是给一个knowledge source,让模型从中找出答案,而所谓的closed book就是没有knowledge source的QA,就只给问题,看模型能不能够打上来。在175B参数量的情况下,用few-shot是可以超过SOTA的。
GPT-3在SuperGLUE的表现如下图所示,总结一下就是参数量越大,给的例子越多,模型的表现就越好。
GPT-3也可以用在生成任务上,下图是不同参数量下GPT-3生成的文章让人去辨别是不是机器生成时的准确率,当参数量最大时,人几乎已经无法辨别出时机器还是人写的了。
GPT-3也会做算术,如下图所示,问它"What is 17 minus 14?"这样的两位数的加减法基本都会回答正确,但是三位数及以上就不灵了。
当然,GPT-3也有不擅长的任务,比如NLI任务,GPT-3的结果就和随便猜的一样。NLI就是给两句话,让模型判断是矛盾,还是相近,还是中立。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 人类语言处理nlp部分笔记——四、GPT3

发表评论 取消回复