SVM模型实现城镇居民月平均消费数据分类
一、SVM支持向量机简介
支持向量机是由感知机发展而来的机器学习算法,属于监督学习算法。支持向量机具有完备的理论基础,算法通过对样本进行求解,得到最大边距的超平面,并将其作为分类决策边界。
支持向量机(Support Vector Machines, SVM)在解决小样本、线性、非线性及高维模式识别领域表现出特有的优势。
SVM是一种研究小样本机器学习模型的统计学习方法,其目标是在有限的数据信息情况下,渐进求解得到最优结果。其核心思想是假设一个函数集合,其中每个函数都能取得小的误差,然后从中选择误差小的函数作为最优函数。
SVM的原理是寻找一个保证分类要求的最优分类超平面,策略是使超平面两侧的间隔最大化。模型建立过程可转换为一个凸二次规划问题的求解。SVM很容易处理线性可分的问题。对于非线性问题,SVM的处理方法是选择一个核函数,然后通过核函数将数据映射到高维特征空间,最终在高维空间中构造出最优分类超平面,从而把原始平面上不好分的非线性数据分开。
二、数据集介绍
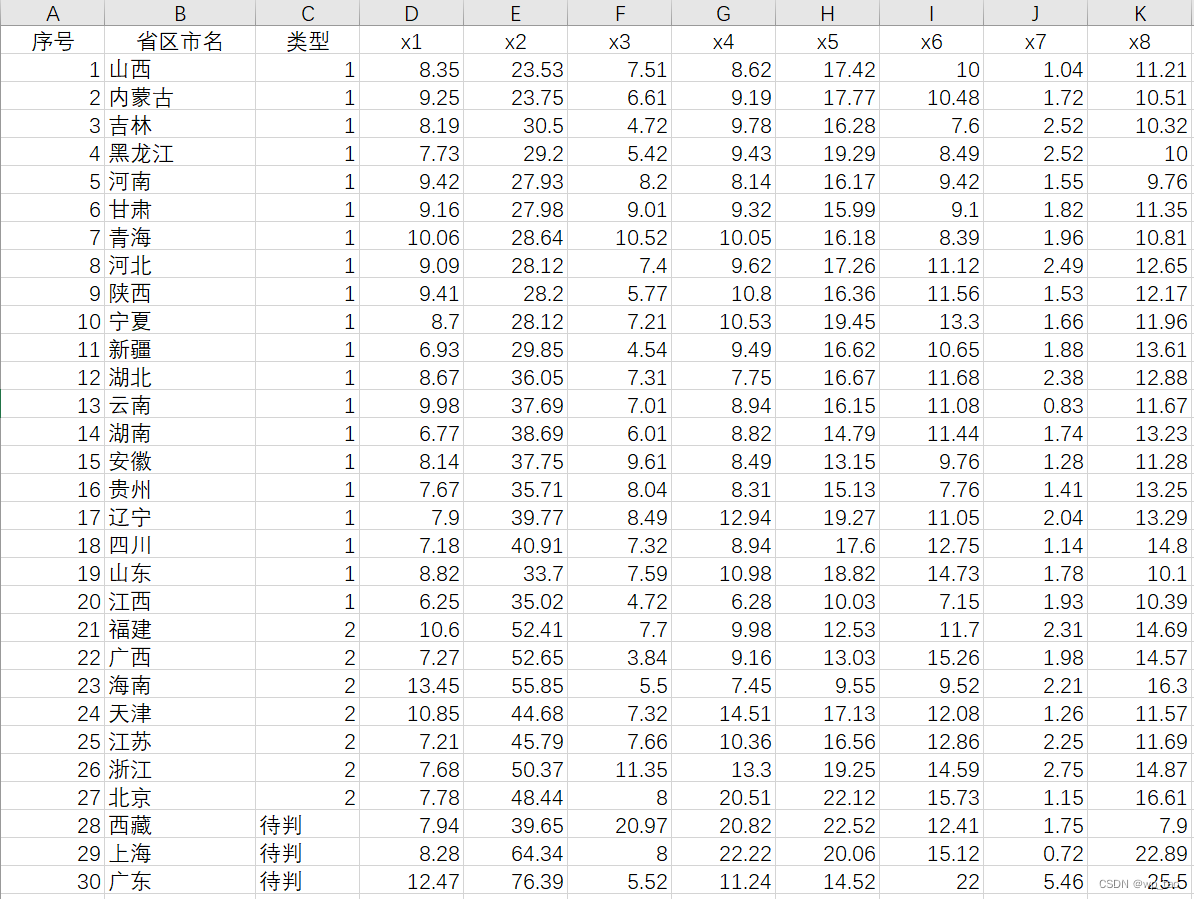
先来整体看一下数据情况:
某年全国各省、区、市城镇居民月平均消费情况数据。 确定分类为:1-20号省份为第一类,记为G1 ,21-27号省份为第二类,记为G2。其中表中的指标为:x1人均粮食支出(元/人);x2人均副食支出(元/人);x3 人均烟酒茶支出(元/人)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » SVM模型实现城镇居民月平均消费数据分类

发表评论 取消回复