提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
最近面对一个需求,就是需要传递声音文件到模型里推理完成语音转文字,问题是我们使用的是麦克风啊,由于这个特殊属性就需要有一个合理的方法来判断声音的开始,声音的结束和声音的长度。像科大讯飞这样的库已经有这个功能了,如果遇到没有这个功能的怎么办,还得靠自己。
方法其实有很多,我们这里使用根据分贝来判断,首先就需要获取到分贝。
一、分贝是什么?
分贝(decibel)是量度两个相同单位之数量比例的单位,常用dB表示。“分”(deci-)指十分之一,个位是“贝”或“贝尔”(bel,纪念发明家亚历山大·格拉汉姆·贝尔),但一般只用分贝。
计算分贝的方法有功率量和场量两种方式,功率量这种方式我还没有完全研究透,我先阐述下概念,等我研究透了再补充具体代码。我们这里先介绍场量这种方式,再给出具体的代码。
1.功率量
功率量(power quantity)是功率值或者直接与功率值成比例的其它量,如能量密度、音强、发光强度等。
考虑功率或者强度(intensity)时,其比值可以表示为分贝,这是通过把测量值与参考量值之比计算基于10的对数,再乘以10。因此功率值P1与另一个功率值P0之比用分贝表示为LdB:
两个功率值的比值基于10的对数,就是贝尔(bel)值。两个功率值之比的分贝值是贝尔值的1/10倍(或者说,1个分贝是十分之一贝尔)。P1与P0必须度量同一个数值类型,具有相同的单位。如果在上式中P1 = P0,那么LdB = 0。如果P1大于P0,那么LdB是正的;如果P1小于P0,那么LdB是负的。
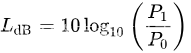
重新安排上式可得到计算P1的公式,依据P0与LdB:
因为贝尔是10倍的分贝,对应的使用贝尔(LB)的公式为:
2.场量
场量(field quantity)是诸如电压、电流、声压、电场强度、速度、电荷密度等量值,其平方值在一个线性系统中与功率成比例。
考虑到场(field)的幅值(amplitude)时,通常使用A1(度量到的幅值)的平方与A0(参考幅值)的平方之比。这是因为对于大多数应用,功率与幅值的平方成比例,并期望对同一应用采取功率计算的分贝与用场的幅值计算的分贝相等。因此使用下述场量的分贝定义:
上述公式可写成:
总结:拿到声音的幅值和参考幅值以10为底求对数,然后再乘以20就是最终的分贝数了。为了方便阐述这里以单声道、16000HZ采样率、16bits小端为示例。
注意:以下所有的都是基于上面的参数来阐述的,不懂得请先补习下知识,要不然后面得就完全看不懂了。
二、实际操作
由于读取麦克风和分析文件完全不一样,这里就分开讲。
1.分析wav文件
先说下RIFF,这个是分析文件必备的知识。
RIFF,全称Resource Interchange File Format(资源交换文件格式),是一种元文件格式(meta-format),设计用于高效地存储和交换多媒体数据,如音频、视频、图像以及相关元数据。该格式由Microsoft和IBM于1991年联合推出,主要用于当时的Windows 3.1操作系统,并成为其默认的多媒体文件格式。
就是说我们以.wav文件为示例,这种文件都是符合RIFF规范的。下面的图片是.wav文件典型的存储格式:
wav文件主要包含三个chunk:riff chunk、format chunk、data chunk,这三个是缺一不可的。我简单写了个解析wav的算法我觉得还不完善,所以暂时不放出来了,因为ffmpeg已经自带解析算法了,也不需要再单独写一个,感兴趣的可以私下研究下。这里我用ffmpeg的代码来演示:
main.cpp
#include <iostream>
#include <cstdio>
extern "C" {
#include <libavformat/avformat.h>
#include <libavdevice/avdevice.h>
}
void read_file_ffmpeg(const char *filename) {
av_register_all();
avformat_network_init();
AVFormatContext *formatContext = nullptr;
if (avformat_open_input(&formatContext, filename, nullptr, nullptr) != 0) {
fprintf(stderr, "Could not open file.\n");
return;
}
if (avformat_find_stream_info(formatContext, nullptr) < 0) {
fprintf(stderr, "Failed to retrieve stream info.\n");
return;
}
int audioStreamIndex = av_find_best_stream(formatContext, AVMEDIA_TYPE_AUDIO, -1, -1, nullptr, 0);
if (audioStreamIndex < 0) {
fprintf(stderr, "No audio stream found.\n");
return;
}
AVCodecContext *codecContext = formatContext->streams[audioStreamIndex]->codec;
AVCodec *codec = avcodec_find_decoder(codecContext->codec_id);
if (!codec) {
fprintf(stderr, "Codec not found.\n");
return;
}
if (avcodec_open2(codecContext, codec, nullptr) < 0) {
fprintf(stderr, "Could not open codec.\n");
return;
}
AVPacket packet;
AVFrame *frame = av_frame_alloc();
//check max db
double max_db = 0;
while (av_read_frame(formatContext, &packet) >= 0) {
if (packet.stream_index == audioStreamIndex) {
int ret;
// 发送数据包到解码器
ret = avcodec_send_packet(codecContext, &packet);
if (ret < 0) {
fprintf(stderr, "Error sending a packet for decoding.\n");
break;
}
// 获取解码后的帧
while (true) {
ret = avcodec_receive_frame(codecContext, frame);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF) {
break;
} else if (ret < 0) {
fprintf(stderr, "Error during decoding.\n");
break;
}
// 解码成功,处理frame->data和frame->linesize中的音频数据
// std::cout << frame->linesize[0] << std::endl;
uint8_t *sampleValues = frame->data[0];
for (int k = 0; k < frame->linesize[0]; k = k + 2) {
uint16_t u_sample = sampleValues[k] | (sampleValues[k + 1] << 8);
auto sample = (int16_t) u_sample;
// std::cout << sample << ',';
double dB = 20 * log10(abs(sample));
std::cout << dB << ',';
if (dB > max_db) {
max_db = dB;
}
// if (dB > DB_SAMPLE) {
// std::cout << "people talk" << std::endl;
// }
}
std::cout << "---------------" << std::endl;
}
}
av_packet_unref(&packet);
}
std::cout << "max_db: " << max_db << std::endl;
av_frame_free(&frame);
avcodec_close(codecContext);
avformat_close_input(&formatContext);
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(read_microphone)
set(CMAKE_CXX_STANDARD 11)
#set(CMAKE_CXX_COMPILER /usr/bin/g++-11)
#set(CMAKE_C_COMPILER /usr/bin/gcc-11)
find_package(PkgConfig REQUIRED)
pkg_check_modules(ffmpeg_lib REQUIRED IMPORTED_TARGET libavformat libavutil libavdevice libavcodec)
add_executable(ffmpeg_bin main.cpp)
target_link_libraries(ffmpeg_bin PkgConfig::ffmpeg_lib)
执行成功了输出分贝值:
25.1055,20,20,18.0618,25.1055,6.0206,16.902,23.5218,33.442,31.8213,33.0643,34.4855,35.8478,33.9794,31.8213,33.6248,34.8073,36.2583,34.8073,35.563,32.2
这个结果的参考幅值是1而不是32767,我查了下幅值计算分贝是没有标准参考值的,因参考值的不同结果也会不同。不过这并不影响我们对结果的判断。
注意:一定要用我说的那种wav文件,因为市面上主流的语音识别都是基于16000hz,单声道,16bits小端处理的。双声道除了增加了性能消耗和复杂度几乎没有特别的意义,而且过高的采样率并不利于人声识别,反而增加背景噪声。
2.读取麦克风
同样使用ffmpeg,只不过读出来的数据不是wav,而是pcm格式,不用对数据进行特别的解码,直接拿来用即可。
main.cpp
#include <iostream>
#include <cstdio>
#include <fstream>
extern "C" {
#include <libavformat/avformat.h>
#include <libavdevice/avdevice.h>
}
/**
* @author arnold
* @brief use alsa and default device
* */
void read_microphone() {
// av_register_all();//ffmpeg 3.x version
avdevice_register_all();
AVFormatContext *fmt_ctx = nullptr;
AVInputFormat *input_fmt = av_find_input_format("alsa"); // 音频设备的输入格式,如alsa、pulse等
const char *dev_name = "default"; // microphone device name
AVDictionary *format_opts = nullptr;//set stream format options
av_dict_set(&format_opts, "sample_rate", "16000", 0);//set audio sample
av_dict_set(&format_opts, "channels", "1", 0);//set audio channel
av_dict_set(&format_opts, "fragment_size", "256", 0);//set audio fragment size
// open audio device
if (avformat_open_input(&fmt_ctx, dev_name, input_fmt, &format_opts) != 0) {
printf("can't open input device!\n");
if (format_opts)
av_dict_free(&format_opts);
return;
}
if (format_opts)
av_dict_free(&format_opts);
//Output Info---
printf("---------------- File Information ---------------\n");
av_dump_format(fmt_ctx, 0, dev_name, 0);
printf("-------------------------------------------------\n");
// find audio stream info
if (avformat_find_stream_info(fmt_ctx, nullptr) < 0) {
printf("can't get audio stream info!\n");
return;
}
int audio_stream_idx = -1;
// find audio stream index
for (int i = 0; i < fmt_ctx->nb_streams; i++) {
if (fmt_ctx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_AUDIO) {
audio_stream_idx = i;
break;
}
}
if (audio_stream_idx == -1) {
printf("can't find audio stream index!\n");
return;
}
//write pcm data
// std::ofstream ofs("../audio/test.pcm");
AVPacket packet;
while (av_read_frame(fmt_ctx, &packet) >= 0) {
if (packet.stream_index == audio_stream_idx) {
std::cout << "packet size: " << packet.size << std::endl;
std::cout << "packet duration: " << packet.duration << std::endl;
// ofs.write((char *) packet.data, packet.size);
// ofs.flush();
for (int i = 0; i < packet.size; i = i + 2) {
uint16_t u_sample = packet.data[i] | (packet.data[i + 1] << 8);
auto sample = (int16_t) u_sample;
// std::cout << sample << ',';
double dB = 20 * log10(abs(sample));
if (dB > 60){
std::cout << dB << ',';
}
}
std::cout << std::endl;
}
av_packet_unref(&packet);
}
avformat_close_input(&fmt_ctx);
// ofs.close();
}
int main() {
read_microphone();
return 0;
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(read_microphone)
set(CMAKE_CXX_STANDARD 11)
#set(CMAKE_CXX_COMPILER /usr/bin/g++-11)
#set(CMAKE_C_COMPILER /usr/bin/gcc-11)
find_package(PkgConfig REQUIRED)
pkg_check_modules(ffmpeg_lib REQUIRED IMPORTED_TARGET libavformat libavutil libavdevice libavcodec)
add_executable(ffmpeg_bin main.cpp)
target_link_libraries(ffmpeg_bin PkgConfig::ffmpeg_lib)
总结
1、代码完全基于单声道音频,没对多声道进行处理,理论上除了参考值不同对多声道音频也是能处理的
2、注意出来的分贝值不一定等于分贝计测出来的,分贝计很可能是基于功率强度或声压强度来来测试结果,我们依据的是幅值,原理还是不一样的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » C++结合ffmpeg获取声音的分贝值

发表评论 取消回复