一、MapReduce概述
1.定义
是分布式运算框架
MapReduce:用户处理业务相关代码+自身的默认代码
2.优势劣势
优点:
1).易于编程。用户只关心业务逻辑,实现框架的接口。
2).良好的扩展性。可以动态增加服务器,解决计算资源不够的问题。
3).高容错性:任何一台挂掉,可以将任务转移到其它节点。
4).适合海量数据计算(TB/PB)几千台服务器共同计算。
劣势:
1).不擅长实时计算。mysql
2).不擅长流式计算。SparkStream flink适合。
3).不擅长DAG有向无环图计算。spark
3.Mapreduce核心思想-WordCount案例
例如:统计其中每一个单词出现的总次数(查询结果:a-p 一个文件,q-z一个文件)
Map阶段:分阶段
Reduce阶段:统计阶段
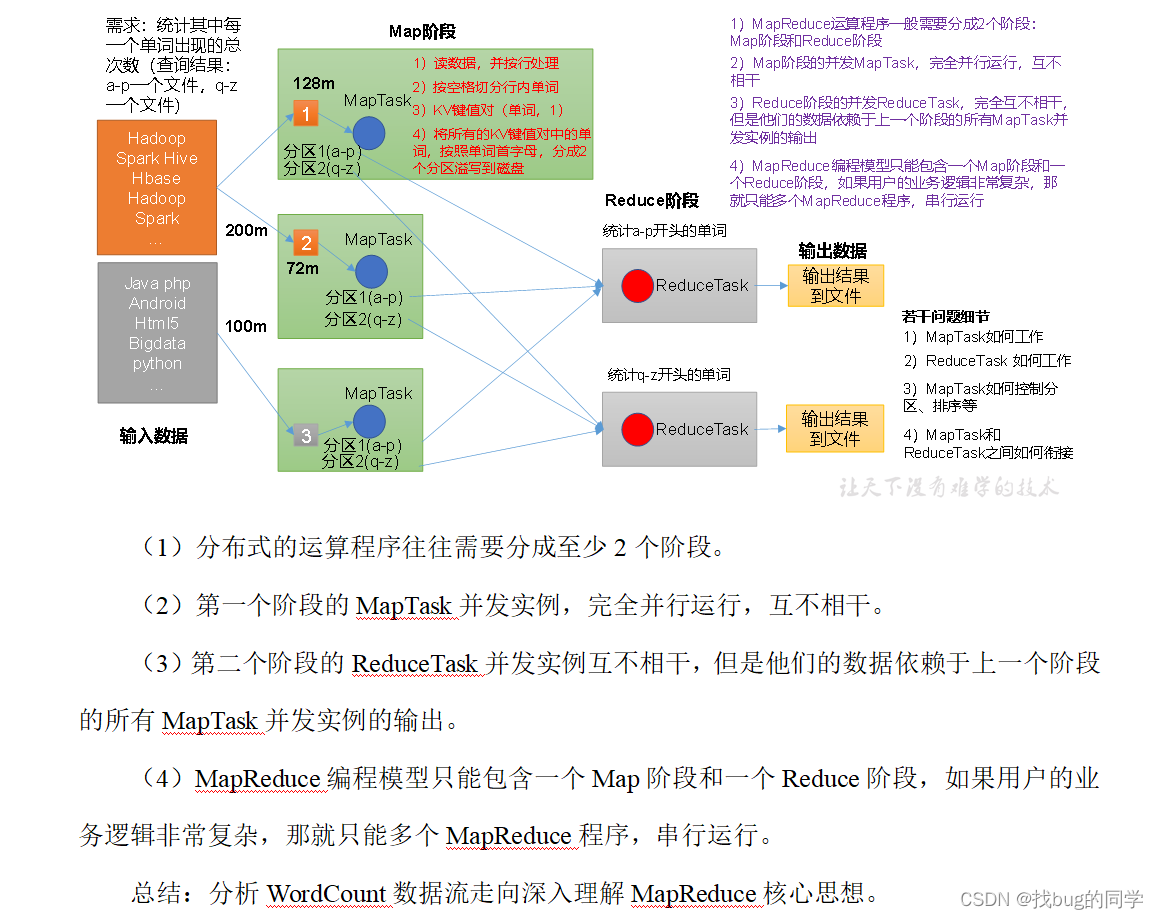
MapReduce程序运行时有三类进程:
1)、MrAppMaster:负责整个程序的过程调度及状态协调。
2)、MapTask:负责Map阶段整个数据处理流程处理。
3)、ReduceTask:负责Reduce阶段的整个处理流程。
说这是一个任务,一个job,一个mr都是一个事情
二、序列化
1.常用序列化进程:
除了String类型变成Text,其他类型都在Java类型基础上加Writable.
| Java类型 | Hadoop Writable类型 |
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
三、核心框架原理
1.输入数据InputFormat
2.shuffle
3.输出数据OutputFormat
4.join
5.ETL
hadoop作为etl工具之一。
清理的过程只需要在Mapper程序进行,不需要运行Reduce程序。
6.总结
四、压缩
1、有哪些压缩算法
2.特点
3.在生产上怎么用
五、常见的问题及解决方案
82-125跳过去
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » MapReduce复习

发表评论 取消回复