MoE概念
模型参数增加很多;计算量没有增加(gating+小FNN,比以前的大FNN计算量要小);收敛速度变快;
效果:PR-MoE > 普通MoE > DenseTransformer
MoE模型,可视为Sparse Model,因为每次参与计算的是一部分参数;
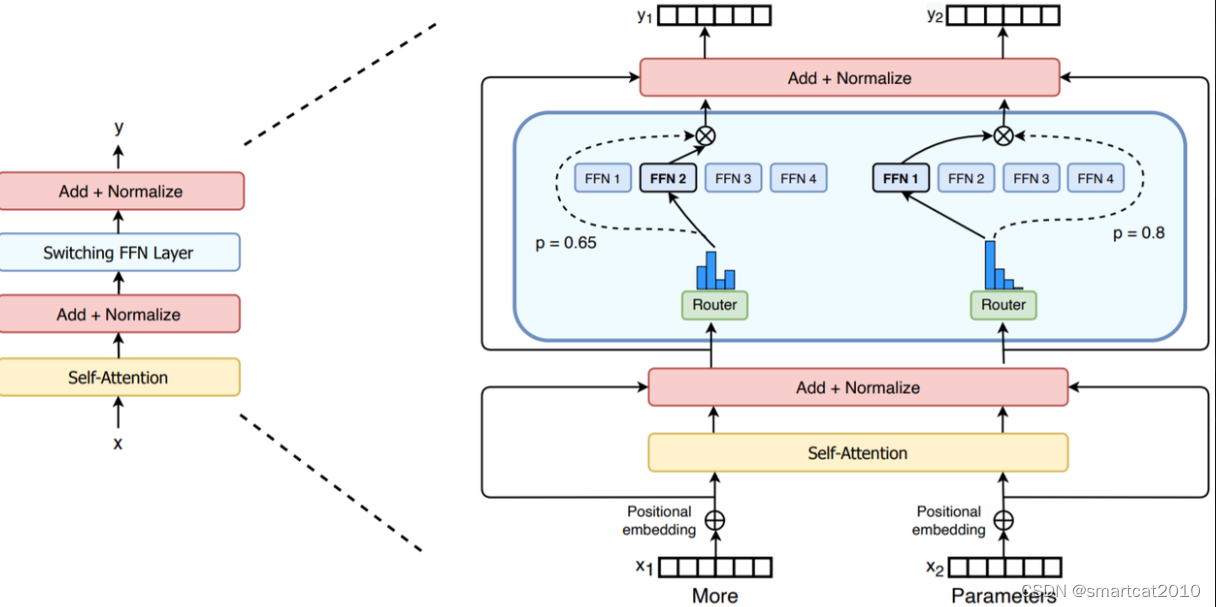
Expert并行,可以和其他并行方式,同时使用:
ep_size指定了MoE进程组大小,一个模型replica的所有MoE都分布在mp_size这些GPU卡上。
下例,启动2个DP replica,每个DP replica包含2个MoE rank,每个MoE rank包含4个MoE FFN,每个GPU放置一个MoE rank;
import torch import deepspeed import deepspeed.utils.groups as groups from deepspeed.moe.layer import MoE WORLD_SIZE = 4 EP_WORLD_SIZE = 2 EXPERTS = 8 fc3 = torch.nn.Linear(84, 84) fc3 = MoE(hidden_size=84, expert=self.fc3, num_experts=EXPERTS, ep_size=EP_WORLD_SIZE, k=1) fc4 = torch.nn.Linear(84, 10)
节约显存的方式:
1. 配置好ZeRo
2. 配置好fp16
"fp16": { "enabled": true, "fp16_master_weights_and_grads": true, }
支持PR-MoE
Pyramid: 金字塔 ;前面的层,Experts数量少些,后面的层Experts数量多些;
Residual:每层都过一个固定的MLP,并和选中的Expert输出结果,相加;
支持Random Token Selection
推理
import deepspeed import torch.distributed as dist # Set expert-parallel size world_size = dist.get_world_size() expert_parallel_size = min(world_size, args.num_experts) # create the MoE model moe_model = get_model(model, ep_size=expert_parallel_size) ... # Initialize the DeepSpeed-Inference engine ds_engine = deepspeed.init_inference(moe_model, mp_size=tensor_slicing_size, dtype=torch.half, moe_experts=args.num_experts, checkpoint=args.checkpoint_path, replace_with_kernel_inject=True,) model = ds_engine.module output = model('Input String')如果Experts数目大于GPU数目, 均分在各个GPU上;如果小于,则Expert将被切片,均分到各个GPU上;
注意:ep_size, mp_size(模型并行),dtype为half, 优化版kernel的使用replace_with_kernel_inject=True;
generate_samples_gpt.py \ --tensor-model-parallel-size 1 \ --num-experts ${experts} \ --num-layers 24 \ --hidden-size 2048 \ --num-attention-heads 32 \ --max-position-embeddings 1024 \ --tokenizer-type GPT2BPETokenizer \ --load $checkpoint_path \ --fp16 \ --ds-inference \PR-MoE, 前面那些层的experts个数少,后面的多:
experts="64 64 64 64 64 64 64 64 64 64 128 128" generate_samples_gpt.py \ --tensor-model-parallel-size 1 \ --num-experts ${experts} \ --mlp_type 'residual' \ --num-layers 24 \ --hidden-size 2048 \ --num-attention-heads 16 \ --max-position-embeddings 1024 \ --tokenizer-type GPT2BPETokenizer \ --load $checkpoint_path \ --fp16 \ --ds-inference \--mlp_type指定使用PR-MoE,推理latency更块;
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » DeepSpeed MoE

发表评论 取消回复