HikariCP的简单介绍
hikari-光,hikariCP取义:像光一样轻和快的Connetion Pool。这个几乎只用java写的中间件连接池,极其轻量并注重性能,HikariCP目前已是SpringBoot默认的连接池,伴随着SpringBoot和微服务的普及,HikariCP 的使用也越来越多。
在hikariCP github首页就放了一篇性能对比:
(https://github.com/brettwooldridge/HikariCP-benchmark)
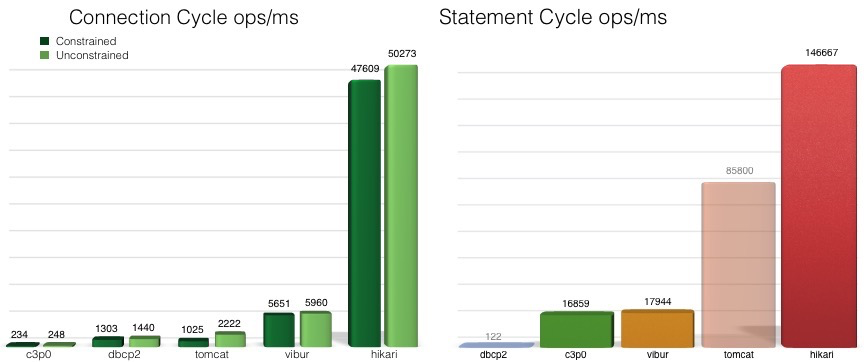
看上去好像是碾压一众数据库连接池中间件。然而这个性能对比的有点老了,而且没有阿里自研的国产巅峰连接池druid的性能对比。我稍微看了下druid的github首页,star比hikariCP还多一点,druid在功能性上明显比hikariCP强。至于两者的性能谁更好,还引发过一次大佬间的口水战,目前没有看到有严格的性能对比报告。不过这不是我们这篇文章的重点···这篇文章只是为了稍微了解下hikariCP。
几个连接池参数
参数其实不多,挑几个重要的:
| 参数 | 含义 |
|---|---|
| minimumIdle | 这个属性控制着HikariCP尝试在连接池中维持的空闲连接的最小数量。如果空闲连接的数量下降至此值以下,并且连接池中的总连接数少于maximumPoolSize,HikariCP将尽最大努力快速而高效地添加额外的连接。然而,为了达到最大性能和对高峰需求的响应性,我们推荐不设置这个值,而是让HikariCP充当一个固定大小的连接池。默认值:与maximumPoolSize相同。 |
| maximumPoolSize | 此属性控制池所能达到的最大大小,包括空闲和正在使用的连接。基本上,此值将决定到数据库后端的实际连接数的上限。合理的值最好由您的执行环境确定。当池达到此大小且没有可用的空闲连接时,调用 getConnection() 将会阻塞,直至 connectionTimeout 毫秒后超时。默认值:10 |
| maxLifetime | 此属性控制池中连接的最大生命周期。正在使用中的连接永远不会被弃用,只有当它被关闭时才会被移除。为了避免池中发生大规模的连接消失,该属性会对每个连接适用轻微的负衰减。我们强烈推荐设置此值,并且应该比任何数据库或基础设施强加的连接时间限制短几秒。值为0表示无最大生命周期(无限生命周期),当然,这受到idleTimeout设置的约束。允许的最小值是30000毫秒(30秒)。默认值:1800000(30分钟)。 |
| idleTimeout | 此属性控制连接在池中允许空闲的最大时间。此设置仅在minimumIdle被定义为小于maximumPoolSize时适用。一旦池达到minimumIdle连接数,空闲连接不会被回收。连接是否被视为空闲并回收,其最大变化范围为+30秒,平均变化范围为+15秒。一个连接在此超时前永远不会被视为空闲并回收。值0表示空闲连接永远不会从池中移除。允许的最小值是10000毫秒(10秒)。默认值:600000(10分钟)。 |
| keepaliveTime | 此属性控制 HikariCP 将多频繁地尝试保持连接active,以防止它因数据库或网络基础设施而超时。这个值必须小于 maxLifetime 的值。"keepalive"操作仅会发生在空闲连接上。允许的最小值是30000毫秒(30秒),但最理想的值是在几分钟的范围内。默认值:0(禁用)。 |
keepaliveTime参数的设置应低于数据库空闲连接超时时间、TCP空闲连接超时时间以及一切其他设施的空闲超时时间。对于PostgreSQL来说,hikariCP的keepaliveTime参数应设置为小于PG库idle_in_transaction_session_timeout的时间。
很明显,maximumPoolSize代表连接到数据库中的最大连接数。当然一般来说,真实场景中数据库中的连接数不会一直保持maximumPoolSize,因为应用不可能从始至终都是最高负荷运行。即使经过一个请求高峰期,根据idleTimeout或者maxLifetime的设置,那些空闲的连接经过一段时间后应该被释放。为了保证数据库的可用性,这个值应该设置为比数据库最大连接数小一些。比如PostgreSQL数据库,maximumPoolSize参应设置为小于PG库的max_connections。这个参数还有调优空间,我们下面会提及。
minimumIdle是最小空闲连接数。例如,如果minimumIdle=100,数据库的active会话有10个,那么理论上数据库中的总连接数应该是100+10个。因为有可能有连接风暴的情况,真实的数据库连接应该比active+minimumIdle略多一点,但肯定小于maximumPoolSize。
为什么数据库连接数远大于minimumIdle?
理论上数据库总连接数只应该略大于minimumIdle,但是经过我实际观察连接池多节点的情况,哪怕数据库活跃连接只有10几个,数据库总连接数却远大于minimumIdle。观察pg_stat_activity的min(backend_start)、min(state_change),基本保持在maxLifetime左右,说明连接回收是有作用的。看上去新请求总喜欢启用新连接,而不是直接拿已有的idle连接用。个人猜多节点部署是原因之一,每个节点minimumIdle很低,也可能存在某些组件上的节点请求要多一点,瞬时请求数超过了minimumIdle从而创建了新的连接。第二,这跟maxLifetime参数也有关系,maxLifetime的目的是为了旋转连接,释放那些一直在用的连接,这样就存在那些使用过的链接需要一段时间来释放,并且最好不要再使用了,以免延长释放周期。
连接池大小设置
连接数过多的影响
在数据库的世界中,“数据库连接数的增多,数据库性能都会一定的下降”。
例如oracle的连接数对性能的影响,参考这个视频。当资源配置、jdbc并发都不变的情况下,连接数从2048下降到1024个,请求响应时间下降一半;如果连接数调整到96个,响应时间下降几十倍!!
连接数设置为多少才合适?
Unless you have a database server that has 1000 cores, it is very unlikely that you really want a maximumPoolSize of 2000.
除非你的数据库有1000C,不然你不应该有2000个连接。
最初始的情况下,数据库连接数应设置为cpu数,这样就能达到cpu的最大性能模式。但是这不是真实的。因为数据库的消耗不仅在cpu,也在磁盘和网络(也有内存、但相对影响不大)。例如,磁盘的读写也需要时间,cpu需要等待磁盘返回数据才可以进行下一步动作。在IO等待的这段时间(有可能时间很长),cpu最好是不要闲着,而是给其他进程使用。所以,基于磁盘等设备的等待时间,数据库连接数最好是高于cpu个数。
由于SSD等磁盘性能的提升,磁盘访问的速度是非常快的,也就是说IO等待时间下降,意味着连接数应该调整得更低。
调低了不能压榨CPU,调太高数据库性能损耗,那么到底调整到多少合适呢?hikariCP给出了这么一个公式
connections = ((core_count * 2) + effective_spindle_count)
其中core_count不应该计算超线程数;effective_spindle_count为主轴数,如果活动数据集完全被缓存,那么effective_spindle_count为零,随着缓存命中率的下降,它应该接近于实际的主轴数量。对应SSD还没有想过公式,不过可以肯定小于以上的最大值。当然这些都是理论值,实际情况要比这个更复杂,比如长连接问题,具体可参考连接池大小相关知识。
即使前端有10000个用户,连接池也不可能是10000个,即使是1000也太多了,需要一个更小的连接数,让其余的请求在连接池中等待,发挥数据库及其CPU的最佳性能才是最好的方式,参考连接数设置如上公式所示。
fixed pool
fixed pool是HikariCP的作者Brett Wooldridge的一个理念,是为了解决连接风暴问题。在minimumIdle参数解释中已经提及fixed pool:
为了达到最大性能和对高峰需求的响应性,我们推荐不设置minimumIdle,而是让HikariCP充当一个固定大小连接池(fixed size connection pool)。默认值:与maximumPoolSize相同。
把minimumIdle=maximumPoolSize就是fixed size connection pool。minimumIdle的默认值就等于maximumPoolSize。
其实早在2014年,Brett Wooldridge就提到了这个概念,参考PG社区邮件。这段话很重要,我将逐字翻译:
根据我的经验,即使是维护最小空闲连接数的池,在响应突发需求时也是有问题的。如果你有一个最大30个连接的池,并且有一个最小10个空闲连接的目标,突发的需求需要20个连接意味着连接池可以立即满足10个,但随后要尝试在应用程序申请连接时间到达connectionTimeout之前建立另外10个连接。这反过来在数据库上产生了突发需求,不仅减慢了建立连接本身,也减慢了实际上可能会将连接返回给连接池的事务。
现在,如果你的峰值是100个连接,你的中位数是50个,这并不重要。但我知道不少工作负载的峰值是1000,中位数是25,在这种情况下你会想要逐渐减少空闲连接。
最终我们采用了一个maxPoolSize + minIdle模型,默认情况它俩相等(fixed pool)。
虽然我不怀疑存在这样的工作负载(1000个活动连接),如果有人真的这么做了,我很想听听他们的理由。除非他们有超过128个CPU核和固态存储,否则基本上就是在白费功夫。
这也意味着,即使连接池的大小是固定的,你也想要旋转(rotate in and out)实际的会话,这样它们就不会无限期地挂着最大虚拟内存。
我们确实是这样做,有一个maxLifeTime设置来旋转这些连接。
在真实场景中,fixed pool对连接风暴影响的保护是可见的。fixed pool下,数据库的瞬时active连接突增,数据库的idle链接数下降,但数据库的总连接数不变,请求响应耗时影响不大。如果把maximumPoolSize设置为比minimumIdle大的一个值,连接风暴会造成瞬间产生很多新会话,而新会话的连接是非常消耗资源的,这明显增加了请求的响应时间。
连接泄露案例
由于本人不是连接池的专家,这里只是把最近找到的连接泄露资料小小汇总下。
连接泄露有如下现象:
-
“Connection is not available” exception。连接泄露,连接打满或者数据库因为active会话过度响应不过来了,新的请求会因为超过
connectionTimeout时间而报错 -
Growth of active connections。数据库监控可以明显看到活动会话上涨
-
Application logs。应用日志也可以看到很多连接请求,包括活跃会话信息
-
Database views and logs。
pg_stat_activity可以看到所有的会话状态和具体的sql,以及在log中可以看到新连接认证登录信息 -
HikariCP leak detection。需要打开
leakDetectionThreshold,HikariCP可以检测链接泄露,这个参数默认是关闭的
对于定位连接泄露,应该
- 检查应用日志,特别是问题刚发生的时间点
- 合理的监控系统
- 善于debug、trace等hikariCP设置
- 设置
leakDetectionThreshold参数
可能的原因:
- Misuse of streaming responses;
- Misuse of raw connections;
- Prolonged operations within
@Transactionalmethod (such as network invocation). - 配置错误,参考
- vitual thread,参考
References
https://github.com/brettwooldridge/HikariCP
https://github.com/brettwooldridge/HikariCP/issues/2148
https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
https://blogs.oracle.com/opal/post/always-use-connection-pools
https://mkyong.com/jdbc/hikaripool-1-connection-is-not-available-request-timed-out-after-30002ms/
https://medium.com/@eremeykin/how-to-deal-with-hikaricp-connection-leaks-part-1-1eddc135b464
https://medium.com/@eremeykin/how-to-deal-with-hikaricp-connection-leaks-part-2-847a9629627f
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » HikariCP连接池初识

发表评论 取消回复