准备深入学习transformer,并参考一些资料和论文实现一个大语言模型,顺便做一个教程,今天是第三部分。
本系列禁止转载,主要是为了有不同见解的同学可以方便联系我,我的邮箱 fanzexuan135@163.com
在transformer块中连接注意力和线性层
在本节中,我们正在实现transformer块,它是GPT-2和其他LLM架构的基本构建块。这个块在1.1亿参数的GPT-2架构中重复了十几次,结合了我们之前介绍过的几个概念:多头注意力、层归一化、dropout、前馈层和GELU激活,
当transformer块处理输入序列时,序列中的每个元素(例如,一个单词或子词token)都由固定大小的向量表示。transformer块内的操作,包括多头注意力和前馈层,被设计为以保持其维度的方式转换这些向量。
这个想法是,多头注意力块中的自注意力机制识别和分析输入序列中元素之间的关系。相比之下,前馈网络在每个位置单独修改数据。这种组合不仅能够对输入进行更细致入微的理解和处理,而且还提高了模型处理复杂数据模式的整体能力。
在代码中,我们可以按如下方式创建TransformerBlock:
代码清单6:GPT-2的transformer块组件
from previous_chapters import MultiHeadAttention
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg['emb_dim'],
d_out=cfg['emb_dim'],
block_size=cfg['context_length'],
num_heads=cfg['n_heads'],
dropout=cfg['dropout_rate'],
qkv_bias=cfg['qkv_bias'])
self.ffn = FeedForward(cfg)
self.norm1 = LayerNorm(cfg['emb_dim'])
self.norm2 = LayerNorm(cfg['emb_dim'])
self.drop_resid = nn.Dropout(cfg['dropout_rate'])
def forward(self, x):
# A
shortcut = x
x = self.norm1(x)
x = self.att(x)
x = self.drop_resid(x)
x = x + shortcut # 添加原始输入
shortcut = x # B
x = self.norm2(x)
x = self.ffn(x)
x = self.drop_resid(x)
x = x + shortcut # C
return x
给定的代码定义了一个TransformerBlock类,使用PyTorch,包括一个多头注意力机制(MultiHeadAttention)和一个前馈网络(FeedForward),两者都根据提供的配置字典(cfg)进行配置,例如GPT_CONFIG_SM。
在这两个组件之前应用层归一化(LayerNorm),之后应用dropout,以正则化模型并防止过拟合。这也被称为Pre-LayerNorm。较旧的架构,如原始的transformer模型,在自注意力和前馈网络之后应用层归一化,称为Post-LayerNorm,这通常会导致更差的训练动态。
该类还实现了前向传递,其中每个组件之后是一个快捷连接,将块的输入添加到其输出。这个关键特性有助于梯度在训练期间流过网络,并改善深度模型的学习,如3.3节所述。
使用我们之前定义的GPT_CONFIG_SM字典,让我们实例化一个transformer块并输入一些样本数据:
torch.manual_seed(1)
x = torch.rand(2, 3, 768) # 示例输入
block = TransformerBlock(GPT_CONFIG_SM)
output = block(x)
print("Input shape:", x.shape)
print("Output shape:", output.shape)
输出如下:
Input shape: torch.Size([2, 3, 768])
Output shape: torch.Size([2, 3, 768])
如代码输出所示,transformer块在其输出中维护输入维度,表明transformer架构在整个网络中处理数据序列而不改变其形状。
贯穿transformer块架构的形状保持并非偶然,而是其设计的一个关键方面。这种设计使其能够有效地应用于广泛的序列到序列任务,其中每个输出向量直接对应于一个输入向量,保持一对一的关系。然而,输出是一个上下文向量,封装了整个输入序列的信息,正如我们在第3章中了解到的。这意味着,虽然序列在通过transformer块时其物理维度(序列长度和特征大小)保持不变,但每个输出向量的内容都被重新编码,以整合整个输入序列的上下文信息。
通过本节中实现的transformer块,我们现在拥有了如图12所示的所有构建块,需要在下一节中实现GPT-2架构。
编写GPT-2模型
我们在本章开始时对GPT架构进行了高层次的概述,我们称之为DummyGPTModel。在这个DummyGPTModel代码实现中,我们展示了GPT-2模型的输入和输出,但它的构建块仍然是一个黑盒,使用DummyTransformerBlock和DummyLayerNorm类作为占位符。
在本节中,我们现在将DummyTransformerBlock和DummyLayerNorm占位符替换为本章后面编写的真实的TransformerBlock和LayerNorm类,以组装一个完全可操作的原始1.1亿参数版本的GPT-2。在第6章,我们将预训练一个GPT-2模型,在第7章,我们将加载来自OpenAI的预训练权重。
在我们用代码组装GPT-2模型之前,让我们看一下图13中它的整体结构,它结合了我们到目前为止在本章中介绍的所有概念。
代码清单7:GPT-2模型架构实现
class GPT2Model(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg['vocab_size'], cfg['emb_dim'])
self.pos_emb = nn.Embedding(cfg['context_length'], cfg['emb_dim'])
self.drop_emb = nn.Dropout(cfg['dropout_rate'])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg['n_layers'])])
self.final_norm = LayerNorm(cfg['emb_dim'])
self.out_head = nn.Linear(
cfg['emb_dim'], cfg['vocab_size'], bias=False)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx) # A
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
多亏了我们在3.4节中实现的TransformerBlock类,GPT2Model类相对较小和紧凑。
这个GPT2Model类的__init__构造函数使用通过Python字典cfg传递的配置初始化token和位置嵌入层。这些嵌入层负责将输入token索引转换为密集向量并添加位置信息,如第3章所述。
接下来,__init__方法创建一个等于cfg中指定的层数的TransformerBlock模块的序列堆栈。在transformer块之后,应用一个LayerNorm层,标准化来自transformer块的输出,以稳定学习过程。最后,定义了一个没有偏置的线性输出头,它将transformer的输出投影到分词器的词汇空间,以生成每个词汇表中token的logits。
forward方法接受一批输入token索引,计算它们的嵌入,应用位置嵌入,将序列传递给transformer块,对最终输出进行归一化,然后计算表示下一个token的unnormalized概率的logits。我们将在下一节中将这些logits转换为tokens和文本输出。
让我们现在使用我们作为cfg参数传入的GPT_CONFIG_SM字典初始化1.1亿参数的GPT-2模型,并用我们在本章开头创建的批处理文本输入对其进行训练:
torch.manual_seed(1)
model = GPT2Model(GPT_CONFIG_SM)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
前面的代码打印输入批次的内容,然后是输出张量:
Input batch:
tensor([[50256, 25461, 20496, 379], # 文本1的token ID
[50256, 11298, 6410, 10851]]) # 文本2的token ID
Output shape: torch.Size([2, 4, 50257])
tensor([[[ 0.0042, 0.0046, 0.0010, ..., -0.0040, 0.0027, 0.0050],
[-0.0007, 0.0073, 0.0027, ..., -0.0052, 0.0013, 0.0052],
[ 0.0090, -0.0012, -0.0084, ..., -0.0043, 0.0021, 0.0063],
[-0.0002, 0.0021, 0.0028, ..., -0.0048, 0.0034, 0.0035]],
[[ 0.0016, 0.0066, 0.0018, ..., -0.0034, 0.0023, 0.0039],
[-0.0011, 0.0082, 0.0029, ..., -0.0048, 0.0019, 0.0047],
[-0.0007, 0.0083, 0.0023, ..., -0.0047, 0.0020, 0.0043],
[-0.0018, 0.0085, 0.0023, ..., -0.0043, 0.0021, 0.0040]]],grad_fn=<UnsafeViewBackward0>)
如我们所见,输出张量的形状为[2, 4, 50257],因为我们传入了2个输入文本,每个文本有4个token。最后一个维度50257对应于分词器的词汇表大小。在下一节中,我们将看到如何将这些50257维输出向量中的每一个转换回token。
在我们进入下一节并编写将模型输出转换为文本的函数之前,让我们再花一些时间研究模型架构本身,并分析它的大小。
使用numel()方法(元素数量的缩写),我们可以收集模型参数张量中的总参数数量:
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params}")
结果如下:
Total number of parameters: 124439808
现在,一个好奇的读者可能会注意到一个差异。早些时候,我们谈到初始化一个1.1亿参数的GPT-2模型,那么为什么实际参数数量是1.24亿,如前面的代码输出所示?
原因是一个称为权重绑定(weight tying)的概念,用于原始GPT-2架构,这意味着原始GPT-2架构在其输出层中重用token嵌入层的权重。为了理解这意味着什么,让我们看一下我们之前通过GPT2Model初始化模型时初始化的token嵌入层和线性输出层的形状:
print("Token embedding layer shape:", model.tok_emb.weight.shape)
print("Output layer shape:", model.out_head.weight.shape)
正如我们从打印输出中看到的,这两层的权重张量具有相同的形状:
Token embedding layer shape: torch.Size([50257, 768])
Output layer shape: torch.Size([50257, 768])
token嵌入和输出层非常大,这是由于分词器词汇表中的行数。让我们根据权重绑定从总的GPT-2模型计数中删除输出层参数计数:
total_params_gpt = total_params - sum(p.numel() for p in model.out_head.parameters())
print(f"Number of trainable parameters considering weight tying: {total_params_gpt}")
输出如下:
Number of trainable parameters considering weight tying: 117432320
正如我们所见,考虑权重绑定,模型现在只有1.17亿参数,与原始GPT-2模型的大小相匹配。
权重绑定减少了模型的整体内存占用和计算复杂性。然而,根据我的经验,使用单独的token嵌入和输出层会导致更好的训练和模型性能,因此我们在GPT2Model实现中使用单独的层。现代LLMs也是如此。然而,我们将在第7章重新审视并实现权重绑定概念,届时我们将加载来自OpenAI的预训练权重。
练习:前馈和注意力模块中的参数数量
计算并比较前馈模块和多头注意力模块中包含的参数数量。
最后,让我们计算GPT2Model对象中1.24亿个参数的内存需求:
total_size_bytes = total_params * 4 # A
total_size_mb = total_size_bytes / (1024 * 1024) # B
print(f"Total size of the model: {total_size_mb:.2f} MB")
结果如下:
Total size of the model: 473.33 MB
总之,通过计算我们的GPT2Model对象中1.24亿个参数的内存需求,并假设每个参数是一个32位浮点数,占用4个字节,我们发现模型的总大小为473.33 MB,说明即使是相对较小的LLMs也需要相对较大的存储容量。
在本节中,我们实现了GPT2Model架构,并看到它输出形状为[batch_size, num_tokens, vocab_size]的数值张量。在下一节中,我们将编写代码将这些输出张量转换为文本。
练习:初始化更大的GPT-2模型
在本章中,我们初始化了一个1.1亿参数的GPT-2模型,称为GPT-2 small。在不进行任何代码修改的情况下(除了更新配置文件),使用GPT2Model类实现GPT-2 medium(使用1024维嵌入、24个transformer块、16个多头注意力头)、GPT-2 large(1280维嵌入、36个transformer块、20个多头注意力头)和GPT-2 XL(1600维嵌入、48个transformer块、25个多头注意力头)。作为奖励,计算每个GPT-2模型中的总参数数量。
生成文本
在本章的最后一节,我们将实现将GPT-2模型的张量输出转换回文本的代码。在我们开始之前,让我们简要回顾一下像LLM这样的生成模型如何一次生成一个单词(或token)的文本,如图14所示。
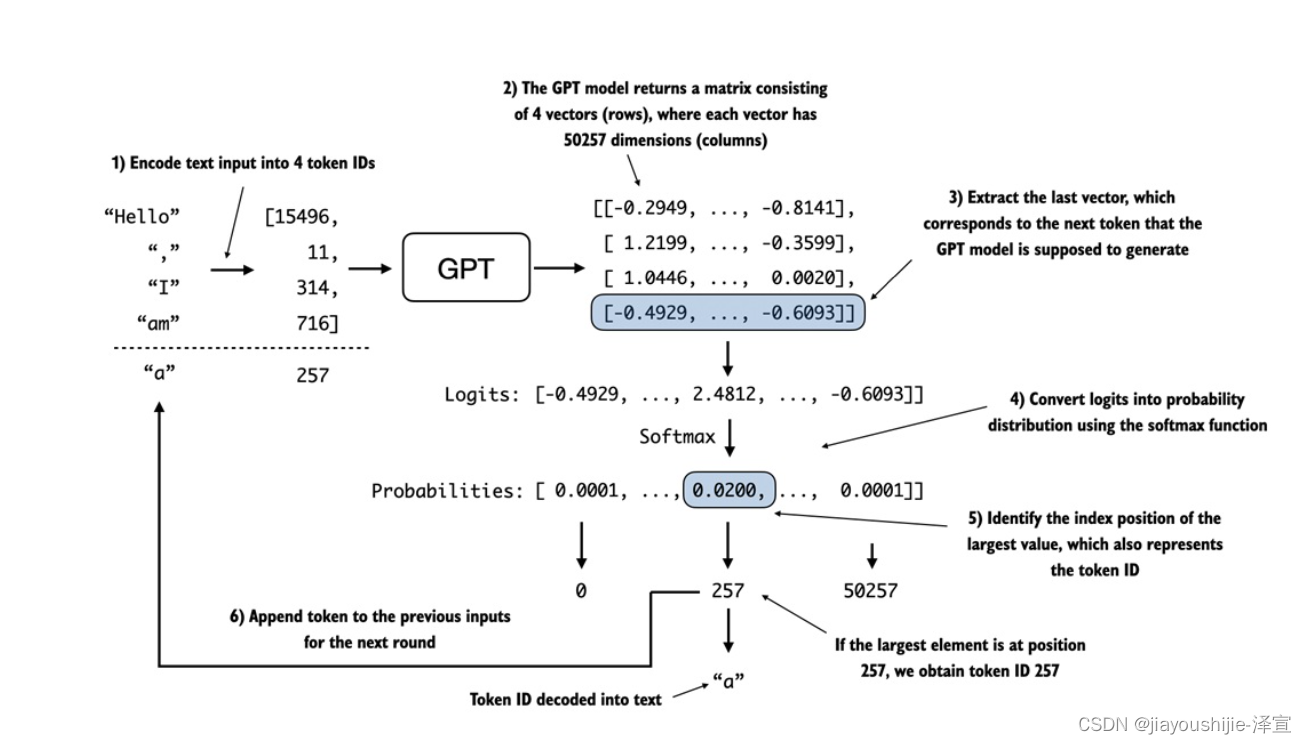
图14:此图说明了LLM一次生成一个token的文本的逐步过程。从初始输入上下文开始(“Hello I am”),模型在每次迭代中预测后续token,将其附加到输入上下文中,用于下一轮预测。如图所示,第一次迭代添加了"a",第二次添加了"model",第三次添加了"ready",逐步构建句子。
图14说明了GPT-2模型在高层次上根据输入上下文(如"Hello I am")生成文本的逐步过程。随着每次迭代,输入上下文增长,允许模型生成连贯且上下文适当的文本。到第三次迭代,模型已经构建了一个完整的句子:“Hello I am a model ready to help”。
在上一节中,我们看到我们当前的GPT2Model实现输出形状为[batch_size, num_tokens, vocab_size]的张量。现在的问题是,GPT-2模型如何从这些输出张量转到图14中所示的生成文本?
GPT-2模型从输出张量到生成文本的过程涉及几个步骤,如图15所示。这些步骤包括解码输出张量,根据概率分布选择token,以及将这些token转换为人类可读的文本。
图15详细说明了GPT-2模型中文本生成的机制,显示了token生成过程中的单个迭代。该过程从将输入文本编码为token ID开始,然后将其输入GPT-2模型。然后将模型的输出转换回文本并附加到原始输入文本中。
图15中详细说明的下一个token生成过程说明了GPT-2模型在给定其输入的情况下生成下一个token的单个步骤。
在每个步骤中,模型输出一个矩阵,其中向量表示潜在的下一个token。提取对应于下一个token的向量,并通过softmax函数将其转换为概率分布。在包含结果概率分数的向量中,定位最高值的索引,该索引转换为token ID。然后将此token ID解码回文本,生成序列中的下一个token。最后,将此token附加到先前的输入中,形成下一次迭代的新输入序列。这个逐步过程使模型能够按顺序生成文本,从初始输入上下文构建连贯的短语和句子。
在实践中,我们在许多迭代中重复这个过程,如图14所示,直到达到用户指定的生成token数量。
在代码中,我们可以按如下方式实现token生成过程:
代码清单8:GPT-2模型生成文本的函数
def generate_text_simple(model, idx, max_new_tokens, context_size): # A
for _ in range(max_new_tokens):
idx_cond = idx[-context_size:] # B
with torch.no_grad():
logits = model(idx_cond)
logits = logits[-1] # C
probas = torch.softmax(logits, dim=0) # D
idx_next = torch.argmax(probas, dim=0, keepdim=True) # E
idx = torch.cat((idx, idx_next), dim=0) # F
return idx
提供的代码片段演示了使用PyTorch为语言模型实现一个简单的生成循环。它迭代指定数量的新token,将当前上下文裁剪到模型的最大上下文大小,计算预测,然后根据最高概率预测选择下一个token。
在前面的代码中,generate_text_simple函数使用softmax函数将logits转换为概率分布,从中我们通过torch.argmax识别具有最高值的位置。softmax函数是单调的,这意味着它在将输入转换为输出时保留其顺序。所以在实践中,softmax步骤是多余的,因为softmax输出张量中分数最高的位置与logit张量中的位置相同。换句话说,我们可以直接将torch.argmax函数应用于logits张量,并获得相同的结果。然而,我们编码了转换以说明将logits转换为概率的完整过程,这可以增加额外的直觉,例如模型生成最可能的下一个token,这被称为贪婪解码。
在下一章中,当我们将实现GPT-2训练代码时,我们还将介绍额外的采样技术,在这些技术中,我们修改softmax输出,使模型并不总是选择最可能的token,这引入了生成文本的可变性和创造性。
现在让我们在实践中尝试generate_text_simple函数,使用图16中所示的"Hello I am"上下文作为模型输入。
首先,我们将输入上下文编码为token ID:
start_context = "Hello I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # A
print("encoded_tensor shape:", encoded_tensor.shape)
编码后的ID如下:
encoded: [50256, 11298, 318]
encoded_tensor shape: torch.Size([1, 3])
接下来,我们将模型置于eval()模式,这将禁用训练期间使用的随机组件(如dropout),并在编码的输入张量上使用generate_text_simple函数:
model.eval() # A
out = generate_text_simple(
model, # 模型
idx=encoded_tensor, # 编码输入
max_new_tokens=20, # 要生成的token数
context_size=GPT_CONFIG_SM['context_length']) # 上下文长度
print("Output:", out)
print("Output length:", len(out[0]))
结果输出token ID如下:
Output: tensor([[ 50256, 11298, 318, 3298, 1891, 9991, 1160, 7075, 1891,
3445, 15852, 280725, 464, 16556, 636, 11514, 2671, 9,
41968, 5423, 581, 14163, 290]])
Output length: 23
使用分词器的decode方法,我们可以将ID转换回文本:
decoded_text = tokenizer.decode(out.squeeze().tolist())
print(decoded_text)
文本格式的模型输出如下:
Hello I am Feature iman Byeswick attribute argue logger Normandy Compton anal
如我们所见,根据前面的输出,模型生成了乱码,完全不像图16中所示的连贯文本。发生了什么?模型无法生成连贯文本的原因是我们还没有训练它。到目前为止,我们只是实现了GPT-2架构并初始化了一个具有初始随机权重的GPT-2模型实例。
模型训练本身就是一个大话题,我们将在下一章中讨论它。
练习:使用单独的dropout参数
在本章开始时,我们在GPT_CONFIG__SM字典中定义了一个全局dropout_rate设置,以在整个GPT2Model架构中的各个位置设置dropout率。修改代码以为模型架构中的各个dropout层指定单独的dropout值。(提示:我们在三个不同的地方使用了dropout层:嵌入层、快捷连接层和多头注意力模块。)
总结
- 层归一化通过确保每一层的输出具有一致的均值和方差来稳定训练。
- 快捷连接是跳过一个或多个层的连接,通过将一个层的输出直接馈送到更深层来帮助缓解深度神经网络(如LLMs)训练中的梯度消失问题。
- Transformer块是GPT-2模型的核心结构组件,结合了带掩码的多头注意力模块和使用GELU激活函数的全连接前馈网络。
- GPT-2模型是具有许多重复transformer块的LLMs,参数数量从数亿到数十亿不等。
- GPT-2模型有不同的尺寸,例如1.1亿、3.45亿、7.62亿和15.5亿个参数,我们可以用相同的
GPT2ModelPython类实现。 - 类GPT LLM的文本生成能力涉及将输出张量解码为人类可读的文本,通过基于给定输入上下文依次预测一个token。
- 如果不进行训练,GPT-2模型会生成不连贯的文本,这突出了模型训练对连贯文本生成的重要性,这是后续章节的主题。
参考文献:
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
- Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization. arXiv preprint arXiv:1607.06450.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
- Hendrycks, D., & Gimpel, K. (2016). Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Press, O., Smith, N. A., & Lewis, M. (2022). Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409.
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 从零实现ChatGPT:第三章实现大型语言模型(2)

发表评论 取消回复