以大语言模型为代表的AI 技术迅速发展,将会影响原有信息网络的方式。其中一个明显的趋势是通过chatGPT 对话代替搜索引擎和浏览器来获取信息。
互联网时代,主要是通过网站(website)提供信息。网站主要为人类阅读的方式构建的。主要技术基于HTML5/javascript 技术支撑。进入AI 时代,网站信息从人类浏览,转型AI 机器人搜索和获取。这种变化将引发重大的影响。诸如网络广告,文章的版权,网页的爬取等等。
本博文探讨一下AI 时代的网站发展趋势。
传统网站对大语言模型并不友好
不利于机器获取信息
浏览网站的主要方式是导航方式,人们根据导航指引获取信息。这种方式适合人类的阅读习惯,但是并不适合机器获取信息。目前使用一些”网络爬虫“技术来获取网站信息。
网站普遍采取前后端架构,前端网页通过web API 读取后端网页和数据库中的数据。webAPI 采用了RestFul方式。无论是调用方式,还是数据结构都是自定义的,没有统一的标准。
另一方面,网站信息是以HTML5 的形式表达,甚至是前端程序生成的。它是以人类阅读体验为中心设计的,对机器阅读并不友好,比如各种”网络爬虫“ 技术都不能完整地读取网站上的信息。网络搜索引擎页难以精准地搜索需要的信息。人们在浏览器面前浪费了大量的时间。特别是中文网站普遍信息质量低下,广告漫天飞。检索信息犹如大海捞针。小公司的网站几乎无人问津。
不利于LLM访问
未来的发展趋势是使用大语言模型的对话获取网站信息,目前的方式是通过搜索引擎寻找相关的网页内容,通过所谓的RAG技术读取关注的信息,RAG需要embedding,矢量数据库技术的支持。这就要求网站的信息有利于RAG。比如在数据库中,除了关键字以外,要添加必要的描述(description)。有助于生成更加有效的矢量数据。
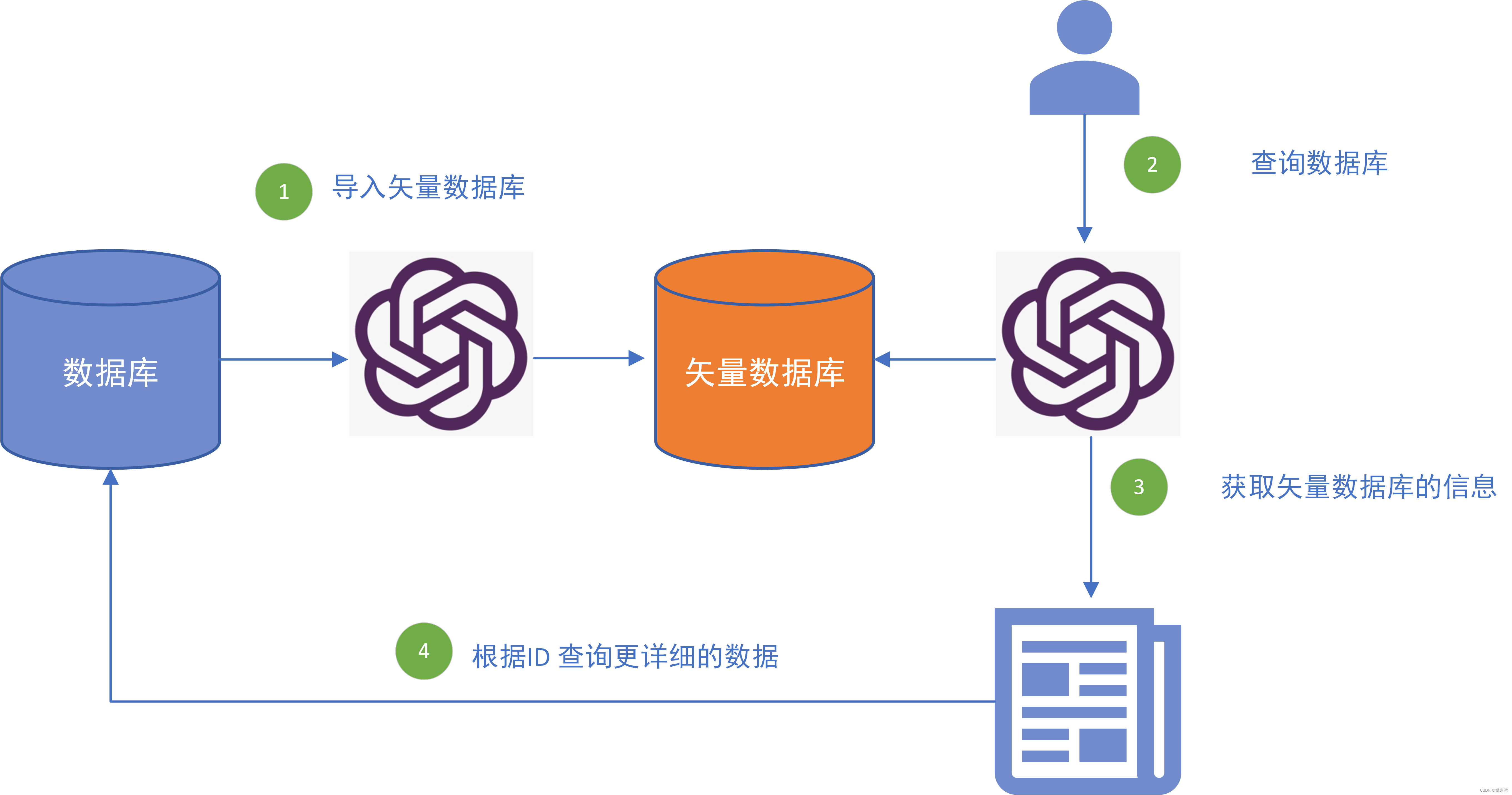
在网站上添加chatGPT 接口也具有不同的方式:
- 浏览器网页与chatGPT 是完全独立的接口
- 借助于chatGPT 实现网页导航的方式
网站的信息开放与内容保护
网络上的网站可以分成两类,一种是尽量能够提供所有信息的网站,比如企业网站,购物网站。另一种是内容保护的网站,他们不希望其他人爬取所有的信息,比如科研论文发布,新闻网,银行,信息有偿服务网站等等。
对于第一种网站而言,未来应该提供机器读取信息的接口和大语言模型的接口,为”网络爬虫“提供服务,让网站的内容尽量地发布出去。
由此看来,未来网站将会有三种基本的访问方式
- 浏览器阅读
- 大语言模型对话
- 网络爬虫和搜索
这三种访问方式如下图所示:
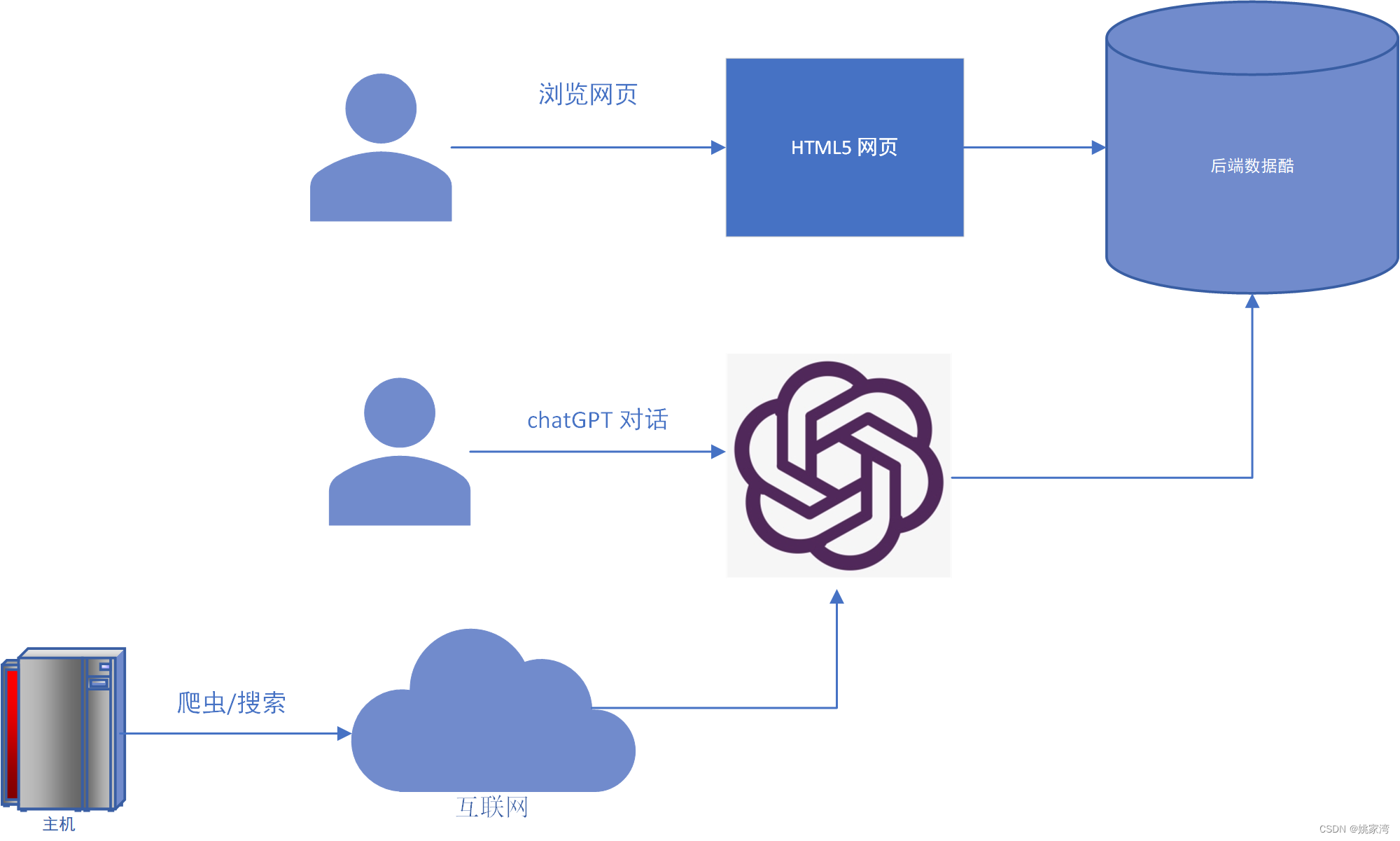
网络爬虫、搜索引擎友好的网站
有意思的是上面提到的第三种方式。借助大语言模型,能够实现网站对网络爬虫和搜索引擎友好。使用自然语言的成为网站的统一的接口,避免了访问内部的web API 。同时能够实现更加精准的网络搜索。
网站将成为“超级推销员”
chatGPT 支持的网站将成为你公司的“超级推销员”和“导购”员。它能够回答客户关心的问题。甚至可以播放视频,PPT。回答专业的技术问题。

网页设计的变化
相信未来的网页设计也将发生变化,一方面网页中应该添加chatGPT 对话的栏目,另一方面,如果使用chatGPT 完成网页内容的导航,那么网页的前端设计将大幅度简化,网页将是单页的方式显示内容,去掉了大量的导航内容。网页的内容与chatGPT 对话同步显示,网页的UX 设计风格也将发生变化。
思考比行动更重要
chatGPT 带来的AI革命正在到来,人们为之兴奋不已。像谷歌,百度等依靠搜索引擎赚钱的公司受到的巨大的压力。靠弹广告为生的浏览器公司感到商业模型即将失灵了。AI 时代一切皆有可能。目前几乎大家都在急切地寻找落地的场景。笔者看来,急于应用之前,深入地思考比仓促上阵更重要。
相信好事情即将发生。。。。。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 构建大语言模型友好型网站

发表评论 取消回复