高可用只针对于api-server,需要用到nginx + keepalived,nginx提供4层负载,keepalived提供vip(虚拟IP)
系统采用openEuler 22.03 LTS
1. 前期准备
因为机器内存只有16G,所有我采用3master + 1node
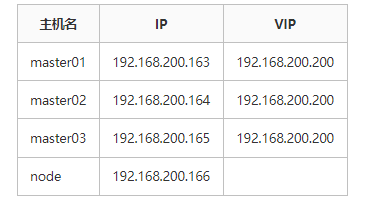
1.1 修改主机配置(所有节点操作)
-
修改主机名
-
关闭防火墙,selinux
-
关闭swap
-
配置时间同步
主机过多,我只写master01的操作
# 修改主机名
[root@localhost ~]# hostnamectl set-hostname master01
[root@localhost ~]# bash
# 关闭防火墙,selinux
[root@master01 ~]# systemctl disable --now firewalld
[root@master01 ~]# setenforce 0
[root@master01 ~]# sed -i s"/^SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
# 关闭swap
[root@master01 ~]# swapoff -a
# 配置时间同步
[root@master01 ~]# yum install chrony -y
[root@master01 ~]# chronyc sources1.2 开启ipvs(所有节点)
[root@master01 ~]# cat > /etc/sysconfig/modules/ipvs.modules << END
> #!/bin/bash
> ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
> for kernel_module in ${ipvs_modules};do
> /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
> if [ 0 -eq 0]; then
> /sbin/modprobe ${kernel_module}
> fi
> done
> END
[root@master01 ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules
[root@master01 ~]# bash /etc/sysconfig/modules/ipvs.modules1.3 配置k8s yum源(所有节点)
# 直接到华为镜像站搜索kubernetes
[root@master01 ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.huaweicloud.com/kubernetes/yum/repos/kubernetes-el7-$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.huaweicloud.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.huaweicloud.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF使用欧拉的话需要将$basearch 改为自己的架构 x86_64
2. 安装docker(所有节点)
由于欧拉目前最高支持k8s的版本是1.23 ,所以需要安装docker
2.1 安装
[root@master01 ~]# yum install docker -y2.2 修改docker配置
[root@master01 ~]# vim /etc/docker/daemon.json
{
"exec-opts":["native.cgroupdriver=systemd"]
}2.3 重启docker
[root@master01 ~]# systemctl daemon-reload
[root@master01 ~]# systemctl restart docker3. 配置高可用(所有master节点)
3.1 安装软件包
[root@master01 ~]# yum install nginx nginx-all-modules keepalived -y3.2 配置nginx负载
在nginx的配置文件内加入一下内容
[root@master01 ~]# vim /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 添加这一段,要写在http段之外,因为我们用的是四层负载,并不是七层负载
stream {
upstream k8s-apiserver {
server 192.168.200.163:6443;
server 192.168.200.164:6443;
server 192.168.200.165:6443;
}
server {
listen 16443;
proxy_pass k8s-apiserver;
}
}
# 到这里结束
# 检测语法
[root@master01 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
# 重启
[root@master01 ~]# systemctl restart nginx3.3 配置keepalived
# 备份原有配置
[root@master01 ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
# 修改配置
[root@master01 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id master1
}
vrrp_instance Nginx {
state MASTER # 只有master01写MASTER,其他master写BACKUP
interface ens33 # 写上网卡
virtual_router_id 51
priority 200 # 其他节点的值要低于这个,另外2个节点的值也不要一样
advert_int 1
authentication {
auth_type PASS
auth_pass 123
}
virtual_ipaddress {
192.168.200.200 # 写VIP
}
}
# 重启
[root@master01 ~]# systemctl restart keepalived.service将原本的配置项都删除,写入这些内容
注意:只有master01的 state 是MASTER,其他2个节点应该写为BACKUP。且priority要低于master01
3.4 验证keepalived
# 查看master01的ens33
[root@master01 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:8d:ce:8a brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.200.163/24 brd 192.168.200.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.200.200/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::ce91:fe4e:625d:6e32/64 scope link noprefixroute
valid_lft forever preferred_lft forever现在他有自己的iP和VIP
# 停掉keepalived
[root@master01 ~]# systemctl stop keepalived.service
[root@master01 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:8d:ce:8a brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.200.163/24 brd 192.168.200.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::ce91:fe4e:625d:6e32/64 scope link noprefixroute
valid_lft forever preferred_lft forever停掉之后vip不存在了,切换到master02 来看看
[root@master02 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:2d:b0:8a brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.200.164/24 brd 192.168.200.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.200.200/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::f409:2f97:f02e:a8d4/64 scope link noprefixroute
valid_lft forever preferred_lft forever现在vip跑到master02了,将master01的keepalived启动,vip会回来,因为master01的
优先级高于他
[root@master01 ~]# systemctl restart keepalived.service
[root@master01 ~]# systemctl enable --now nginx keepalived.service
Created symlink /etc/systemd/system/multi-user.target.wants/nginx.service → /usr/lib/systemd/system/nginx.service.
Created symlink /etc/systemd/system/multi-user.target.wants/keepalived.service → /usr/lib/systemd/system/keepalived.service.4. 部署k8s
欧拉目前只支持1.23版本,所以目前的容器运行时是docker,没有写执行节点那么就是master01
4.1 安装软件包(所有master节点)
[root@master01 ~]# yum install kubeadm kubelet kubectl -y
[root@master01 ~]# systemctl enable kubelet4.3 生成部署文件
[root@master01 ~]# kubeadm config print init-defaults > init.yaml4.3.1 修改部署文件
[root@master01 ~]# vim init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.200.163 # 这个地方需要修改为自己的IP地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: master01 # 这个地方改成你的主机名或者IP,作用是集群部署出来之后在集群内显示的名称,这里写什么到时候就是什么
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
certSANs: # 添加这一整段,目的是让这些地址所在的主机都能够使用证书
- master01
- master02
- master03
- 127.0.0.1
- localhost
- kubernetes
- kubernetes.default
- kubernetes.default.svc
- kubernetes.default.svc.cluster.local
- 192.168.200.163 # 这里3个是master的IP地址
- 192.168.200.164
- 192.168.200.165
- 192.168.200.200 # VIP也需要写上
controlPlaneEndpoint: 192.168.200.200:16443 # 添加这一行,IP为VIP
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: swr.cn-east-3.myhuaweicloud.com/hcie_openeuler # 镜像仓库要改为国内的
kind: ClusterConfiguration
kubernetesVersion: 1.23.1 # 改为kubeadm版本一样的
networking:
dnsDomain: cluster.local
podSunbet: 10.244.0.0/12 # 添加这一行
serviceSubnet: 10.96.0.0/12
scheduler: {}
--- # 添加这一整段
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs4.4 提前拉取镜像
# 这是在部署之前提前先把镜像拉取下来
[root@master01 ~]# kubeadm config images pull --config ./init.yaml4.5 开始部署
[root@master01 ~]# kubeadm init --upload-certs --config ./init.yaml
# 如果安装失败了可以执行kubeadm reset -f 重置环境再来init,如果直接init会报错执行成功之后会输出一些信息
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You can now join any number of the control-plane node running the following command on each as root:
# 加入新的master节点使用这个命令
kubeadm join 192.168.200.200:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:de0e41b3bc59d2879af43da29f3f25cc1b133efda1f202d4c4ce5f865cad71d3 \
--control-plane --certificate-key 8be5d0b8d4914a930d58c4171e748210cbdd118befa0635ffcc1031b7840386e
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
# 加入node节点就使用这个命令
kubeadm join 192.168.200.200:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:de0e41b3bc59d2879af43da29f3f25cc1b133efda1f202d4c4ce5f865cad71d3 4.6 其他master节点加入集群
生成的token只有24小时有效,如果token过期了还需要有节点加入集群的话可以执行
[root@master01 ~]# kubeadm token create --print-join-commandkubeadm join 192.168.200.200:16443 --token gb00dz.tevdizf7mxqx1egj --discovery-token-ca-cert-hash sha256:de0e41b3bc59d2879af43da29f3f25cc1b133efda1f202d4c4ce5f865cad71d3 这个命令可以直接让node节点加入
如果需要加入master节点,那么需要加上 --control-plane --certificate-key 8be5d0b8d4914a930d58c4171e748210cbdd118befa0635ffcc1031b7840386e
[root@master02 ~]# kubeadm join 192.168.200.200:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:de0e41b3bc59d2879af43da29f3f25cc1b133efda1f202d4c4ce5f865cad71d3 \
--control-plane --certificate-key 8be5d0b8d4914a930d58c4171e748210cbdd118befa0635ffcc1031b7840386e
[root@master02 ~]# mkdir -p $HOME/.kube
[root@master02 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master02 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@master03 ~]# kubeadm join 192.168.200.200:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:de0e41b3bc59d2879af43da29f3f25cc1b133efda1f202d4c4ce5f865cad71d3 \
--control-plane --certificate-key 8be5d0b8d4914a930d58c4171e748210cbdd118befa0635ffcc1031b7840386e
[root@master03 ~]# mkdir -p $HOME/.kube
[root@master03 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master03 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config 可以使用 --node-name 指定加入集群后的名字
4.7 node节点加入集群
[root@node ~]# kubeadm join 192.168.200.200:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:de0e41b3bc59d2879af43da29f3f25cc1b133efda1f202d4c4ce5f865cad71d34.8 查看集群节点
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 NotReady control-plane,master 45m v1.23.1
master02 NotReady control-plane,master 27m v1.23.1
master03 NotReady control-plane,master 27m v1.23.1
node NotReady <none> 10s v1.23.15. 安装网络插件 calico
没安装网络插件之前状态是NotReady,装完之后就是Ready
在官方文档里面可以找到最新的版本
[root@master01 ~]# wget https://docs.projectcalico.org/archive/v3.23/manifests/calico.yaml
[root@master01 ~]# kubectl apply -f calico.yaml稍等一会之后,查看集群节点状态
[root@master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 5h38m v1.23.1
master02 Ready control-plane,master 5h21m v1.23.1
master03 Ready control-plane,master 5h21m v1.23.1
node Ready <none> 4h53m v1.23.1如果登了很久还没有ready的话可以使用
[root@master01 ~]# kubectl get pods -A看看那些pod没有起来,找到原因并解决之后就可以了
6. 验证集群是否可用
[root@master01 ~]# kubectl run web01 --image nginx:1.24
pod/web01 created
[root@master01 ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web01 1/1 Running 0 27s能够正常启动pod
文章转载自:FuShudi
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 搭建高可用k8s

发表评论 取消回复