作者:来自 Elastic Ashish Tiwari
介绍
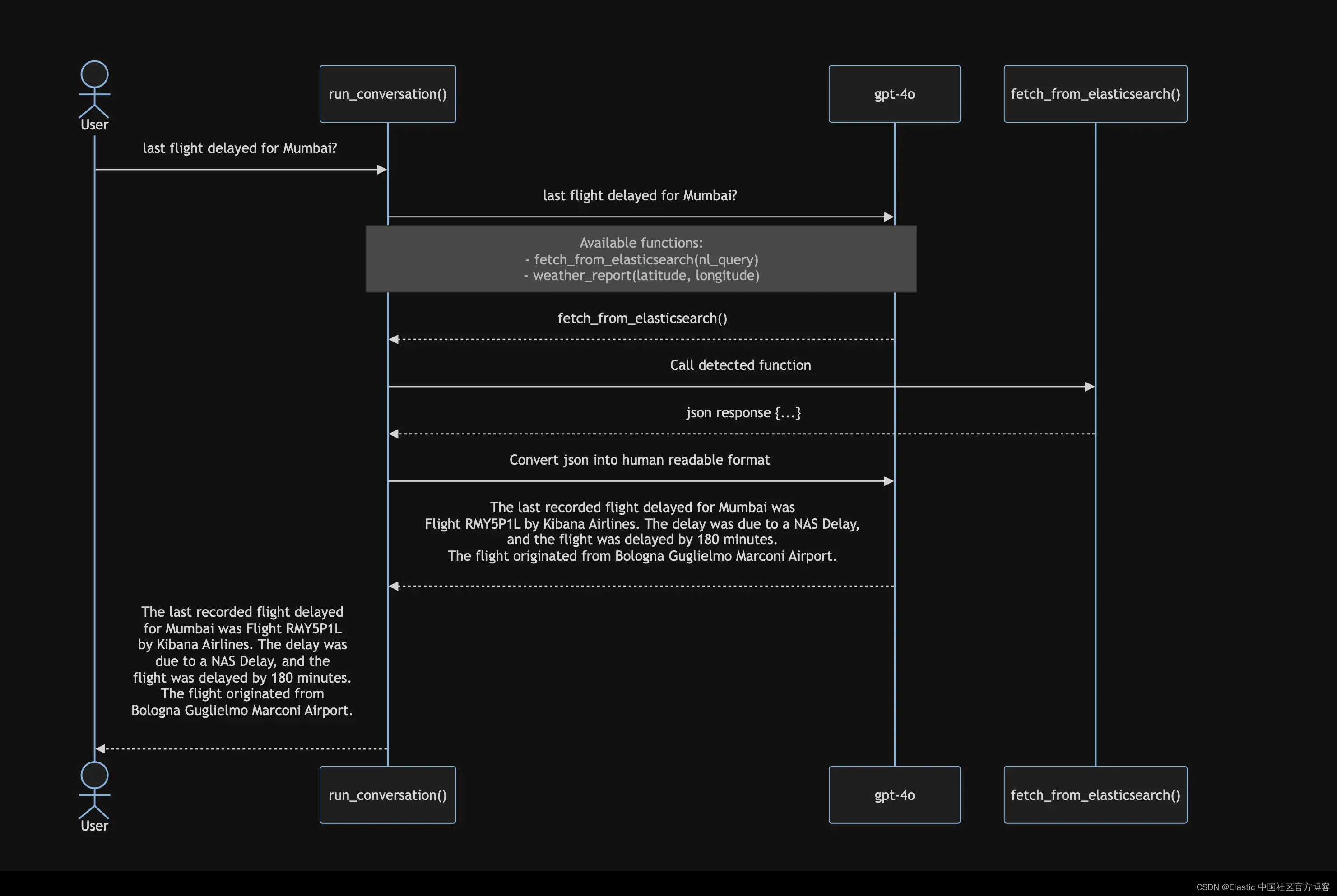
OpenAI 中的函数调用是指 AI 模型与外部函数或 API 交互的能力,使它们能够执行文本生成之外的任务。此功能使模型能够通过调用预定义函数来执行代码、从数据库检索信息、与外部服务交互等。
该模型根据用户提示智能识别需要调用哪个函数,并使用适当的参数调用该函数。参数也可以由模型动态生成。
可能的用例包括:
- 数据检索:从数据库或 API 访问实时数据。 (例如天气信息、股票价格)
- 增强交互:执行需要逻辑和计算的复杂操作(例如,预订航班、安排会议)。
- 与外部系统集成:与外部系统和工具交互(例如,执行脚本、发送电子邮件)。
在本博客中,我们将创建两个函数:
- fetch_from_elasticsearch() - 使用自然语言查询从 Elasticsearch 获取数据。
- weather_report() - 获取特定位置的天气预报。
我们将集成函数调用,以根据用户的查询动态确定要调用哪个函数,并相应地生成必要的参数。
先决条件
Elastic
创建 Elastic Cloud 部署以获取所有 Elastic 凭证。
- ES_API_KEY:创建 API 密钥。
- ES_ENDPOINT:复制 Elasticsearch 的端点。
OpenAI
- OPENAI_API_KEY:设置 Open AI 帐户并创建密钥。
- GPT 模型:我们将使用 gpt-4o 模型,但你可以在此处检查函数调用支持哪个模型。
Open-Meteo API
我们将使用 Open-Meteo API。 Open-Meteo 是一个开源天气 API,为非商业用途提供免费访问。无需 API 密钥。
OPEN_METEO_ENDPOINT:https://api.open-meteo.com/v1/forecast
样本数据
创建 Elastic 云部署后,我们在 Kibana 上添加示例飞行数据。样本数据将存储到 kibana_sample_data_flights 索引中。
Python notebook
我们将为整个流程创建一个快速的 Python notebook。安装以下依赖项并创建 Python 脚本/笔记本。
pip install openai
导入包
from openai import OpenAI
from getpass import getpass
import json
import requests
接受凭证
OPENAI_API_KEY = getpass("OpenAI API Key:")
client = OpenAI(
api_key=OPENAI_API_KEY,
)
GPT_MODEL = "gpt-4o"
ES_API_KEY = getpass("Elastic API Key:")
ES_ENDPOINT = input("Elasticsearch Endpoint:")
ES_INDEX = "kibana_sample_data_flights"
OPEN_METEO_ENDPOINT = "https://api.open-meteo.com/v1/forecast"
Function1: fetch_from_elasticsearch()
def fetch_from_elasticsearch(nl_query):
此函数将接受 nl_query 参数作为自然语言(英语)的字符串,并以字符串形式返回 json elasticsearch 响应。它将对 kibana_sample_data_flights 索引执行所有查询,该索引保存所有航班相关数据。
它将由 3 个步骤/子功能组成。
- get_index_mapping() - 它将返回索引的映射。
- get_ref_document() - 它将返回一个示例文档以供参考。
- build_query() - 这里我们将利用 GPT 模型 (gpt-4o) 和一些镜头提示将用户问题(文本)转换为 Elasticsearch Query DSL
通过将所有功能添加在一起来继续笔记本。
Get Index Mapping
def get_index_mapping():
url = f"""{ES_ENDPOINT}/{ES_INDEX}/_mappings"""
headers = {
"Content-type": "application/json",
"Authorization": f"""ApiKey {ES_API_KEY}""",
}
resp = requests.request("GET", url, headers=headers)
resp = json.loads(resp.text)
mapping = json.dumps(resp, indent=4)
return mappingGet reference document
def get_ref_document():
url = f"""{ES_ENDPOINT}/{ES_INDEX}/_search?size=1"""
headers = {
"Content-type": "application/json",
"Authorization": f"""ApiKey {ES_API_KEY}""",
}
resp = requests.request("GET", url, headers=headers)
resp = json.loads(resp.text)
json_resp = json.dumps(resp["hits"]["hits"][0], indent=4)
return json_resp注意:你还可以缓存索引映射和参考文档,以避免频繁查询 Elasticsearch。
根据用户查询生成 Elasticsearch Query DSL
def build_query(nl_query):
index_mapping = get_index_mapping()
ref_document = get_ref_document()
few_shots_prompt = """
1. User Query - Average delay time of flights going to India
Elasticsearch Query DSL:
{
"size": 0,
"query": {
"bool": {
"filter": {
"term": {
"DestCountry": "IN"
}
}
}
},
"aggs": {
"average_delay": {
"avg": {
"field": "FlightDelayMin"
}
}
}
}
2. User Query - airlines with the highest delays
Elasticsearch Query DSL:
{
"size": 0,
"aggs": {
"airlines_with_highest_delays": {
"terms": {
"field": "Carrier",
"order": {
"average_delay": "desc"
}
},
"aggs": {
"average_delay": {
"avg": {
"field": "FlightDelayMin"
}
}
}
}
}
}
3. User Query - Which was the last flight that got delayed for Bangalore
Elasticsearch Query DSL:
{
"query": {
"bool": {
"must": [
{ "match": { "DestCityName": "Bangalore" } },
{ "term": { "FlightDelay": true } }
]
}
},
"sort": [
{ "timestamp": { "order": "desc" } }
],
"size": 1
}
"""
prompt = f"""
Use below index mapping and reference document to build Elasticsearch query:
Index mapping:
{index_mapping}
Reference elasticsearch document:
{ref_document}
Return single line Elasticsearch Query DSL according to index mapping for the below search query related to flights.:
{nl_query}
If any field has a `keyword` type, Just use field name instead of field.keyword.
Just return Query DSL without REST specification (e.g. GET, POST etc.) and json markdown format (e.g. ```json)
few example of Query DSL
{few_shots_prompt}
"""
resp = client.chat.completions.create(
model=GPT_MODEL,
messages=[
{
"role": "user",
"content": prompt,
}
],
temperature=0,
)
return resp.choices[0].message.content
注意:有时,可能需要修改提示以获得更准确的响应(查询 DSL)或一致的报告。虽然我们依靠模型自身的知识来生成查询,但可以通过对更复杂查询的少量提示来提高可靠性。少量提示涉及提供你希望其返回的查询类型的示例,这有助于提高一致性。
Execute Query on Elasticsearch
def fetch_from_elasticsearch(nl_query):
query_dsl = build_query(nl_query)
print(f"""Query DSL: ==== \n\n {query_dsl}""")
url = f"""{ES_ENDPOINT}/{ES_INDEX}/_search"""
payload = query_dsl
headers = {
"Content-type": "application/json",
"Authorization": f"""ApiKey {ES_API_KEY}""",
}
resp = requests.request("GET", url, headers=headers, data=payload)
resp = json.loads(resp.text)
json_resp = json.dumps(resp, indent=4)
print(f"""\n\nElasticsearch response: ==== \n\n {json_resp}""")
return json_resp
文本到 Elasticsearch 查询
让我们带着一些问题/查询调用 fetch_from_elasticsearch()。
Query1
fetch_from_elasticsearch("Average delay time of flights going to India")
响应:
Query DSL: ====
{
"size": 0,
"query": {
"bool": {
"filter": {
"term": {
"DestCountry": "IN"
}
}
}
},
"aggs": {
"average_delay": {
"avg": {
"field": "FlightDelayMin"
}
}
}
}
Elasticsearch response: ====
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 372,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"average_delay": {
"value": 48.346774193548384
}
}
}
Query2
fetch_from_elasticsearch("airlines with the highest delays")
响应:
Query DSL: ====
{
"size": 0,
"aggs": {
"airlines_with_highest_delays": {
"terms": {
"field": "Carrier",
"order": {
"average_delay": "desc"
}
},
"aggs": {
"average_delay": {
"avg": {
"field": "FlightDelayMin"
}
}
}
}
}
}
Elasticsearch response: ====
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10000,
"relation": "gte"
},
"max_score": null,
"hits": []
},
"aggregations": {
"airlines_with_highest_delays": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Logstash Airways",
"doc_count": 3323,
"average_delay": {
"value": 49.59524526030695
}
},
{
"key": "ES-Air",
"doc_count": 3211,
"average_delay": {
"value": 47.45250700716288
}
},
{
"key": "Kibana Airlines",
"doc_count": 3219,
"average_delay": {
"value": 46.38397017707363
}
},
{
"key": "JetBeats",
"doc_count": 3261,
"average_delay": {
"value": 45.910763569457224
}
}
]
}
}
}
尝试其中一些查询,看看会得到什么结果 -
fetch_from_elasticsearch("top 10 reasons for flight cancellation")
fetch_from_elasticsearch("top 5 flights with expensive ticket")
fetch_from_elasticsearch("flights got delay for Bangalore")
完成测试后,你可以从上面的代码中注释掉我们出于调试目的而添加的 print 语句。
Function2: weather_report()
def weather_report(latitude, longitude):
该函数将接受参数纬度和经度作为字符串。它将调用 Open-Meteo API 来获取指定坐标的报告。
在 notebook 中添加函数
def weather_report(latitude, longitude):
url = f"""{OPEN_METEO_ENDPOINT}?latitude={latitude}&longitude={longitude}¤t=temperature_2m,precipitation,cloud_cover,visibility,wind_speed_10m"""
resp = requests.request("GET", url)
resp = json.loads(resp.text)
json_resp = json.dumps(resp, indent=4)
print(f"""\n\nOpen-Meteo response: ==== \n\n {json_resp}""")
return json_resp
Test function
让我们调用 weather_report() 函数:
检 Whitefield,Bangalore
weather_report("12.96","77.75")
响应:
{
"latitude": 19.125,
"longitude": 72.875,
"generationtime_ms": 0.06604194641113281,
"utc_offset_seconds": 0,
"timezone": "GMT",
"timezone_abbreviation": "GMT",
"elevation": 6.0,
"current_units": {
"time": "iso8601",
"interval": "seconds",
"temperature_2m": "\u00b0C",
"precipitation": "mm",
"cloud_cover": "%",
"visibility": "m",
"wind_speed_10m": "km/h"
},
"current": {
"time": "2024-05-30T21:00",
"interval": 900,
"temperature_2m": 29.7,
"precipitation": 0.0,
"cloud_cover": 36,
"visibility": 24140.0,
"wind_speed_10m": 2.9
}
}
Function 调用
在本部分中,我们将看到 OpenAI 模型如何根据用户查询检测需要调用哪个函数并生成所需的参数。
定义函数
让我们在一个对象数组中定义这两个函数。我们将创建一个新函数 run_conversation()。
def run_conversation(query):
all_functions = [
{
"type": "function",
"function": {
"name": "fetch_from_elasticsearch",
"description": "All flights/airline related data is stored into Elasticsearch. Call this function if receiving any query around airlines/flights.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Exact query string which is asked by user.",
}
},
"required": ["query"],
},
},
},
{
"type": "function",
"function": {
"name": "weather_report",
"description": "It will return weather report in json format for given location co-ordinates.",
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "string",
"description": "The latitude of a location with 0.01 degree",
},
"longitude": {
"type": "string",
"description": "The longitude of a location with 0.01 degree",
},
},
"required": ["latitude", "longitude"],
},
},
},
]
在每个对象中,我们需要设置属性。
- type:function
- name:要调用的函数的名称
- description:函数功能的描述,模型使用它来选择何时以及如何调用该函数。
- parameters:函数接受的参数,以 JSON Schema 对象的形式描述。
查看工具参考以了解有关属性的更多信息。
调用 OpenAI Chat Completion API
让我们在 Chat Completion API 中设置上述 all_functions。在 run_conversation() 中添加以下代码片段:
messages = []
messages.append(
{
"role": "system",
"content": "If no data received from any function. Just say there is issue fetching details from function(function_name).",
}
)
messages.append(
{
"role": "user",
"content": query,
}
)
response = client.chat.completions.create(
model=GPT_MODEL,
messages=messages,
tools=all_functions,
tool_choice="auto",
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print(tool_calls)
tools:所有函数的集合。tool_choice = "auto":这让模型决定是否调用函数,如果调用,则调用哪些函数。但我们可以通过为 tool_choice 设置适当的值来强制模型使用一个或多个函数。
- 设置 tool_choice:“required” 以确保模型始终调用一个或多个函数。
- 使用 tool_choice:{“type”:“function”, “function”:“name”:“my_function”}} 强制模型调用特定函数。
- 设置 tool_choice:“none” 以禁用函数调用并使模型仅生成面向用户的消息。
让我们运行聊天完成 API,看看它是否选择了正确的函数。
run_conversation(“how many flights got delay”)
响应:
[ChatCompletionMessageToolCall(id='call_0WcSIBFj3Ekg2tijS5yJJOYu', function=Function(arguments='{"query":"flights delayed"}', name='fetch_from_elasticsearch'), type='function')]
如果你注意到,它检测到了 name='fetch_from_elasticsearch',因为我们已经询问了航班相关查询,并且 Elasticsearch 具有航班相关数据。让我们尝试其他查询。
run_conversation("hows weather in delhi")
响应:
[ChatCompletionMessageToolCall(id='call_MKROQ3VnmxK7XOgiEJ6fFXaW', function=Function(arguments='{"latitude":"28.7041","longitude":"77.1025"}', name='weather_report'), type='function')]
函数检测到 name='weather_report()' 和由模型arguments='{"latitude":"28.7041","longitude":"77.1025"}' 生成的参数。我们刚刚传递了城市名称(德里),模型生成了适当的参数,即纬度和经度。
执行选定的函数
让我们使用生成的参数执行检测到的函数。在此部分中,我们将简单地运行由模型确定的函数并传递生成的参数。
在 run_conversation() 中添加以下代码片段。
if tool_calls:
available_functions = {
"fetch_from_elasticsearch": fetch_from_elasticsearch,
"weather_report": weather_report,
}
messages.append(response_message)
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
if function_name == "fetch_from_elasticsearch":
function_response = function_to_call(
nl_query=function_args.get("query"),
)
if function_name == "weather_report":
function_response = function_to_call(
latitude=function_args.get("latitude"),
longitude=function_args.get("longitude"),
)
print(function_response)
让我们测试一下这部分:
run_conversation("hows weather in whitefield, bangalore")
响应:
[ChatCompletionMessageToolCall(id='call_BCfdhkRtwmkjqmf2A1jP5k6U', function=Function(arguments='{"latitude":"12.97","longitude":"77.75"}', name='weather_report'), type='function')]
{
"latitude": 13.0,
"longitude": 77.75,
"generationtime_ms": 0.06604194641113281,
"utc_offset_seconds": 0,
"timezone": "GMT",
"timezone_abbreviation": "GMT",
"elevation": 873.0,
"current_units": {
"time": "iso8601",
"interval": "seconds",
"temperature_2m": "\u00b0C",
"precipitation": "mm",
"cloud_cover": "%",
"visibility": "m",
"wind_speed_10m": "km/h"
},
"current": {
"time": "2024-05-30T21:00",
"interval": 900,
"temperature_2m": 24.0,
"precipitation": 0.0,
"cloud_cover": 42,
"visibility": 24140.0,
"wind_speed_10m": 11.7
}
}
它检测到函数 weather_report() 并使用适当的参数执行它。
让我们尝试一些与航班相关的查询,我们希望从 Elasticsearch 获取数据。
run_conversation("Average delay for Bangalore flights")
响应:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 78,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"average_delay": {
"value": 48.65384615384615
}
}
}
延长对话
我们以 JSON 格式获取所有响应。这实际上不是人类可读的。让我们使用 GPT 模型将此响应转换为自然语言。我们将函数响应传递给 Chat Completion API 以延长对话。
在 run_conversation() 中添加以下代码片段。
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
)
second_response = client.chat.completions.create(
model=GPT_MODEL,
messages=messages,
)
return second_response.choices[0].message.content
让我们测试端到端流程。我建议注释掉所有打印语句,除非你想保留它们用于调试目的。
i = input("Ask:")
answer = run_conversation(i)
print(answer)
Q1: Average delay for Bangalore flights
The average delay for Bangalore flights is approximately 48.65 minutes.
Q2: last 10 flight delay to Bangalore, show in table
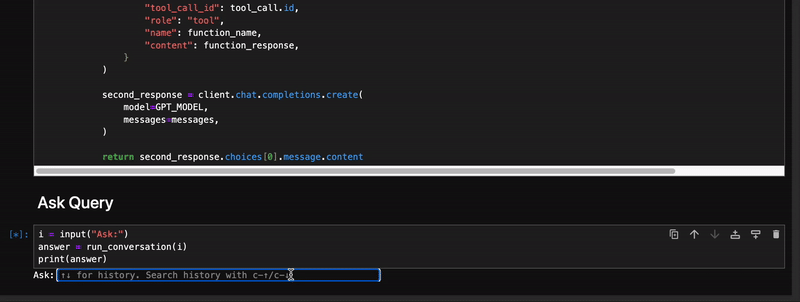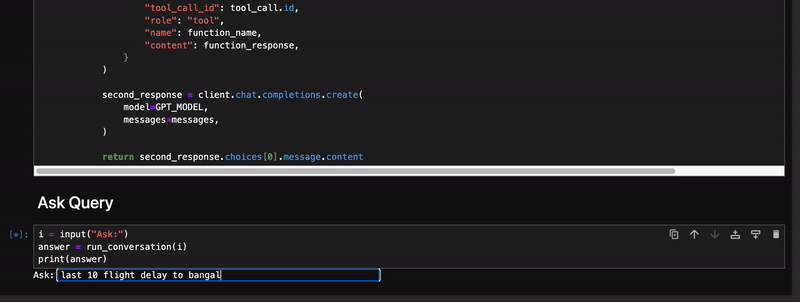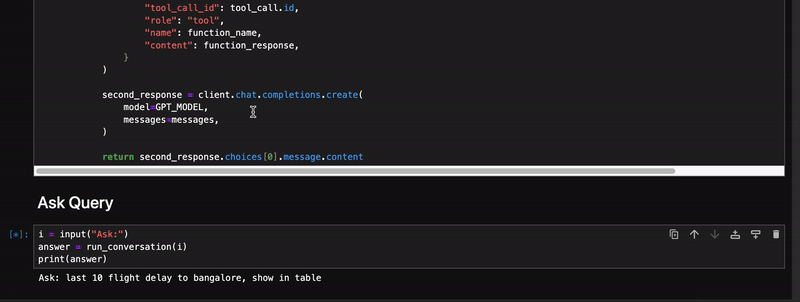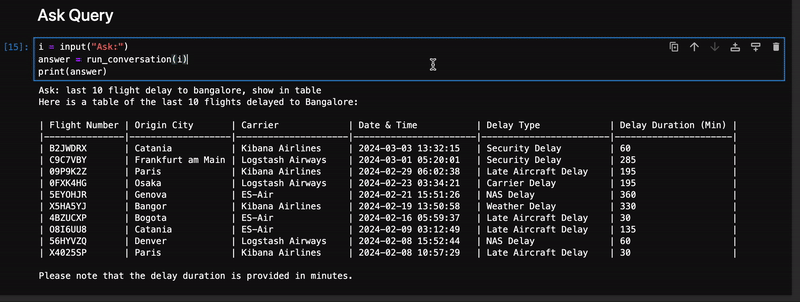
以上数据来自 Elasticsearch 和模型将 json 响应转换为表。
Q3: How is the climate in Whitefield, Bangalore, and what precautions should I take?
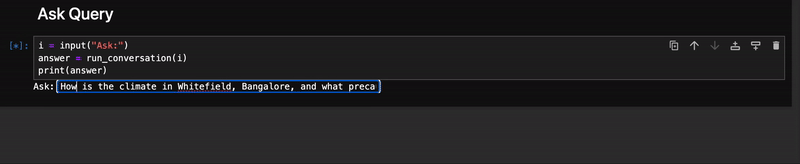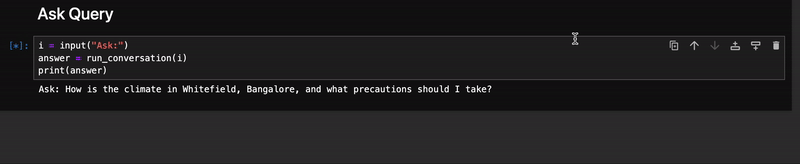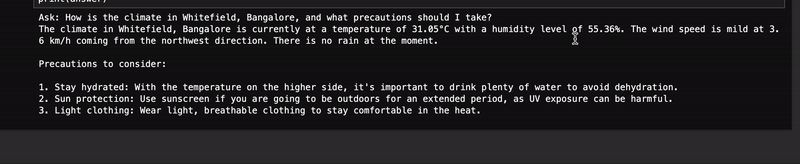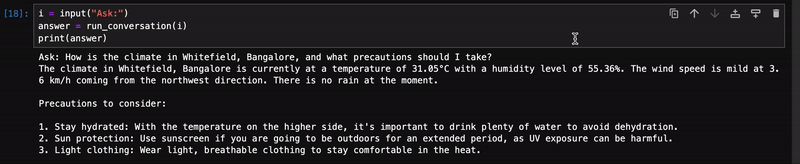
模型调用 weather_report() 函数来获取班加罗尔怀特菲尔德的信息,并添加了需要采取的预防措施。
执行的一些问答:
Q4: How's the weather in BKC Mumbai?
e current weather in BKC Mumbai is as follows:
- Temperature: 31.09°C
- Humidity: 74.5%
- Wind Speed: 0.61 m/s, coming from the west-northwest (256.5°)
- No rain intensity or accumulation reported at the moment.
Q5: Which day of the week do flights experience the most delays?
Here is a table showing the count of flight cancellations by country:
Country Count of Cancellations IT (Italy) 315 US (United States) 253 JP (Japan) 118 CN (China) 97 CA (Canada) 67 DE (Germany) 66 IN (India) 63 GB (United Kingdom) 72 AU (Australia) 56 KR (South Korea) 55
并行函数调用
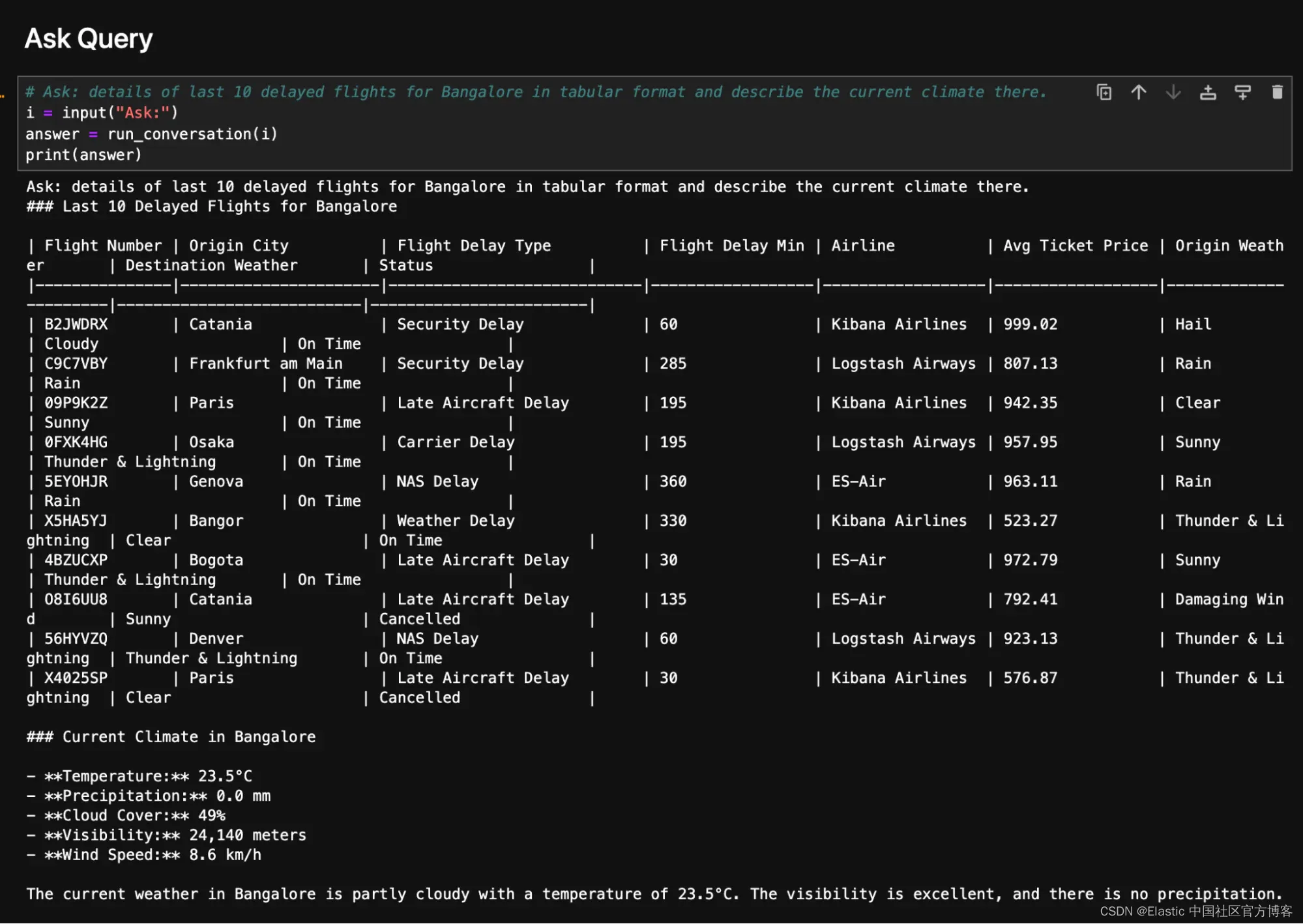
较新的模型(例如 gpt-4o 或 gpt-3.5-turbo)可以一次调用多个函数。例如,如果我们询问 “details of last 10 delayed flights for Bangalore in tabular format and describe the current climate there.”,则我们需要来自这两个函数的信息。
Python 笔记本
在 Elasticsearch Labs 中查找完整的 Python notebook。
结论
使用 GPT-4 或其他模型将函数调用合并到你的应用程序中可以显著增强其功能和灵活性。通过策略性地配置 tool_choice 参数,你可以决定模型何时以及如何与外部函数交互。
它还为你的响应添加了一层智能。在上面的例子中,我要求以表格格式显示数据,它会自动将 json 转换为表格格式。它还根据国家代码添加了国家名称。
因此,函数调用不仅简化了复杂的工作流程,还为集成各种数据源和 API 开辟了新的可能性,使你的应用程序更智能、更能响应用户需求。
准备好自己尝试一下了吗?开始免费试用。
想要将 RAG 构建到你的应用程序中吗?想尝试使用向量数据库的不同 LLM 吗?
在 Github 上查看我们针对 LangChain、Cohere 等的示例笔记本,并立即加入 Elasticsearch Relevance Engine 培训。
原文:OpenAI function calling with Elasticsearch — Elastic Search Labs
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 使用 Elasticsearch 调用 OpenAI 函数

发表评论 取消回复