一、window 概述
Streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 Flink window 是一种将无限数据切割为有限块进行处理的手段。window 是无限数据流处理的核心, window 将一个无限的 stream 拆分成有限大小的 ”buckets” 桶,然后可以在这些桶上做计算操作
二、window 类型
1. Time Window
时间窗口,按照时间生成 Window
1.1 Tumbling Time Window
滚动时间窗口
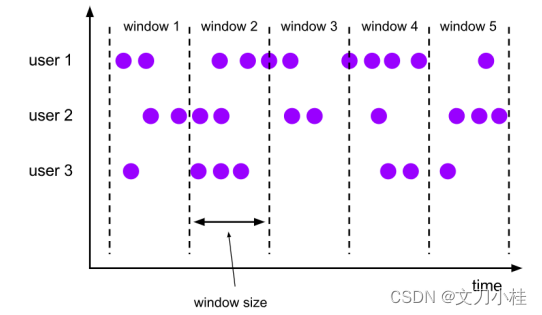
- 将数据依据固定的窗口长度(时间)对数据进行切片
- 特点:时间对齐,窗口长度固定,没有重叠
- 重要参数:窗口长度(时间值)
- 适用场景:适合做 BI 统计等(做每个时间段的聚合计算)
1.2 Sliding Time Window
滑动时间窗口
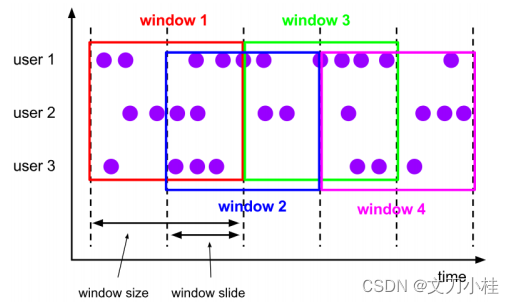
- 滑动时间窗口由固定的窗口长度和滑动间隔组成
- 特点:时间对齐,窗口长度固定,可以有重叠,数据最大的重叠数 = 窗口长度/滑动间隔
- 重要参数:窗口长度和滑动间隔(时间值)
- 适用场景:对最近一个时间段内的统计(求某接口最近 5min 的失败率来决定是否要报警)
1.3 Session Window
会话时间窗口
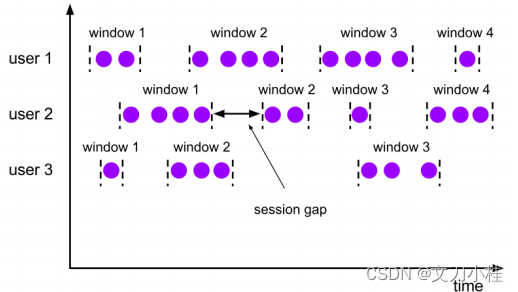
- 由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的 session,也就是一段时间没有接收到新数据就会生成新的窗口
- 特点:时间无对齐
- 重要参数:会话最小时间间隔
2. Count Window
计数窗口,按照指定的数据条数生成一个 Window,与时间无关
2.1 Tumbling Count Window
滚动计数窗口
- 将数据依据固定的窗口长度(计数)对数据进行切片
- 特点:计数对齐,窗口长度固定,没有重叠
- 重要参数:窗口长度(计数值)
2.2 Sliding Count Window
滑动计数窗口
- 滑动计数窗口由固定的窗口长度和滑动间隔组成
- 特点:计数对齐,窗口长度固定,可以有重叠,数据最大的重叠数 = 窗口长度/滑动间隔
- 重要参数:窗口长度和滑动间隔(计数值)
三、window API 操作

1. Window 创建
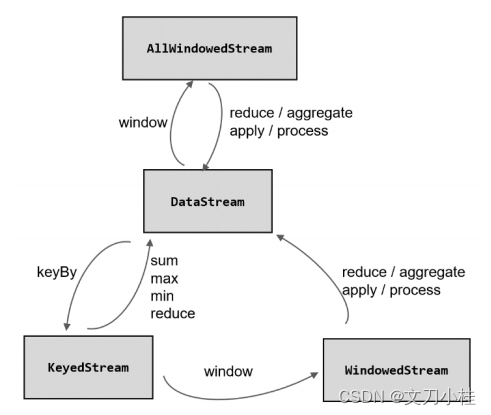
1.1 非按键分区流
原始的 DataStream 调用 windowAll() 方法创建的窗口只能在一个任务(task)上执行,相当于并行度变成了 1,生产上不建议使用
AllWindowedStream stream = dataStream.windowAll()
1.2 按键分区流
Window 的创建推荐是 DataStream 经过 KeyBy 之后调用 window() 方法
/**
通用开窗方法:WindowedStream<T> window()
参数:WindowAssigner
Flink 提供的通用 WindowAssigner:
1.滚动窗口(tumbling window)
2.滑动窗口(sliding window)
3.会话窗口(session window)
4.全局窗口(global window)
*/
public class TestWindowCreate {
public static void main(String[] args) throw Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文本数据
/*sensorReading.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
*/
DataStream<String> inputStream = env.readTextFile("sensorReading.txt");
DataStream<SensorReading> dataStream = inputStream.map(new MapFunction<String, SensorReading>(){
@Override
public SensorReading map(String value) throws Exception {
String[] fields = value.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
}
});
//创建窗口
//1.滚动时间窗口
//1.1 使用通用 window() 方法
dataStream.keyBy("id").window(TumblingProcessTimeWindows.of(Time.seconds(5)));
//1.2 使用 timeWindow() 方法
dataStream.keyBy("id").timeWindow(Time.seconds(5));
//2.滑动时间窗口
//2.1 使用通用 window() 方法
dataStream.keyBy("id").window(SlidingProcessTimeWindows.of(Time.seconds(6), Time.seconds(2)));
//2.2 使用 timeWindow() 方法
dataStream.keyBy("id").timeWindow(Time.seconds(6), Time.seconds(2));
//3.会话窗口
dataStream.keyBy("id").window(EventTimeSessionWindows.withGap(Time.minutes(1)));
//4.计数窗口
//4.1 滚动计数窗口
dataStream.keyBy("id").countWindow(10L);
//4.2 滑动计数窗口
dataStream.keyBy("id").countWindow(10L, 2L);
env.execute();
}
}
2. Window 函数
window function 定义了要对窗口中收集的数据做的计算操作
2.1 增量聚合函数
incremental aggregation functions,每条数据到来就进行计算,保持一个简单的状态,窗口结束时输出最终的状态。简单的 sum/max/maxBy/min/minBy 聚合函数都是增量聚合
2.1.1 ReduceFunction
/**
方法签名:reduce(ReduceFunction<T> reduce)
注意:ReduceFunction 的类型 T 不能改变
*/
public class TestWindowFunction {
public static void main(String[] args) throw Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文本数据
/*sensorReading.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
*/
DataStream<String> inputStream = env.readTextFile("sensorReading.txt");
DataStream<SensorReading> dataStream = inputStream.map(new MapFunction<String, SensorReading>(){
@Override
public SensorReading map(String value) throws Exception {
String[] fields = value.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
}
});
//创建窗口并使用窗口函数
dataStream.keyBy("id").timeWindow(Time.seconds(5)).reduce(new ReduceFunction<SenesorReading>() {
@Override
public SenesorReading reduce(SenesorReading value1, SenesorReading value2) throws Exception {
return value2;
}
}).print();
env.execute();
}
}
2.1.2 AggregateFunction
/**
方法签名:aggregate(AggregateFunction<IN, ACC, OUT> aggregate)
AggregateFunction 的 3 个泛型:
1.IN:输入数据类型
2.ACC:中间累加器的数据类型
3.OUT:输出数据类型
AggregateFunction 接口中需要实现的 4 个方法:
1.createAccumulator():创建一个累加器,即为聚合创建了一个初始状态,每个聚合任务只会调用一次
2.add():将输入的元素添加到累加器中。基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value 和当前的累加器accumulator;返回一个新的累加器值,是对聚合状态进行更新。每条数据到来之后都会调用这个方法
3.getResult():从累加器中提取聚合的输出结果。可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如计算平均值,可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用
4.merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)
*/
public class TestWindowFunction {
public static void main(String[] args) throw Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文本数据
/*sensorReading.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
*/
DataStream<String> inputStream = env.readTextFile("sensorReading.txt");
DataStream<SensorReading> dataStream = inputStream.map(new MapFunction<String, SensorReading>(){
@Override
public SensorReading map(String value) throws Exception {
String[] fields = value.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
}
});
//创建窗口并使用窗口函数
dataStream.keyBy("id").timeWindow(Time.seconds(15)).aggregate(new AggregateFunction<SenesorReading, Integer, Integer>() {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(SenesorReading value, Integer accumulator) {
return accumulator + 1;
}
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
}).print();
env.execute();
}
}
2.2 全窗口函数
full window functions,先收集窗口中的每一条数据,并在内部缓存起来,等到窗口要输出结果的时候再将所有数据进行计算并输出
2.2.1 WindowFunction
/**
方法签名:apply(WindowFunction<IN, OUT, KEY, W extends Window> window)
泛型:
1.IN:输入数据类型
2.OUT:输出数据类型
3.KEY:分组 key 的类型
4.W:窗口的类型
需要实现的方法:void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out)
1.key:分区的 key
2.window:当前窗口信息
3.input:窗口所有数据的可迭代集合
4.out:数据收集器
*/
public class TestFullWindowFunction {
public static void main(String[] args) throw Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文本数据
/*sensorReading.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
*/
DataStream<String> inputStream = env.readTextFile("sensorReading.txt");
DataStream<SensorReading> dataStream = inputStream.map(new MapFunction<String, SensorReading>(){
@Override
public SensorReading map(String value) throws Exception {
String[] fields = value.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
}
});
//创建窗口并使用窗口函数
dataStream.keyBy("id").timeWindow(Time.seconds(15)).apply(new WindowFunction<SenesorReading, Tuple3<String, Long, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple key, TimeWindow window, Iterable<SensorReading> input, Collector<Tuple3<String, Long, Integer>> out) throws Exception {
String id = key.getField(0);
Long windowEnd = window.getEnd();
Integer count = IteratorUtils.toList(input.iterator()).size();
out.collect(new Tuple3<>(id, windowEnd, count));
}
}).print();
env.execute();
}
}
2.2.2 ProcessWindowFunction
/**
方法签名:process(ProcessWindowFunction<IN, OUT, KEY, W extends Window> window)
泛型:
1.IN:输入数据类型
2.OUT:输出数据类型
3.KEY:分组 key 的类型
4.W:窗口的类型
需要实现的方法:void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out)
1.key:分区的 key
2.context:上下文环境对象
3.input:窗口所有数据的可迭代集合
4.out:数据收集器
*/
public class TestFullWindowFunction {
public static void main(String[] args) throw Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//读取文本数据
/*sensorReading.txt
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
*/
DataStream<String> inputStream = env.readTextFile("sensorReading.txt");
DataStream<SensorReading> dataStream = inputStream.map(new MapFunction<String, SensorReading>(){
@Override
public SensorReading map(String value) throws Exception {
String[] fields = value.split(",");
return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));
}
});
//创建窗口并使用窗口函数
dataStream.keyBy("id").timeWindow(Time.seconds(15)).process(new ProcessWindowFunction<SenesorReading, Tuple3<String, Long, Integer>, Tuple, TimeWindow>() {
@Override
public void process(Tuple key, Context context, Iterable<SensorReading> input, Collector<Tuple3<String, Long, Integer>> out) throws Exception {
String id = key.getField(0);
Long windowEnd = context.window().getEnd();
Integer count = IteratorUtils.toList(input.iterator()).size();
out.collect(new Tuple3<>(id, windowEnd, count));
}
}).print();
env.execute();
}
}
3. 其他可选 API
3.1 trigger
触发器主要是用来控制窗口什么时候触发计算,即执行窗口函数
/**
参数:Trigger 抽象类
内置实现类:EventTimeTrigger、ProcessingTimeTrigger 和 CountTrigger 等
自定义实现类:继承 Trigger 抽象类并重写方法
1.onElement():窗口中每到来一个元素,都会调用这个方法
2.onEventTime():当注册的事件时间定时器触发时,将调用这个方法
3.onProcessingTime():当注册的处理时间定时器触发时,将调用这个方法
4.clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态
*/
trigger(Trigger<> trigger)
3.2 evictor
移除器主要用来定义移除某些数据的逻辑
/**
参数:Evictor 接口
实现方法:
1.evictBefore():定义执行窗口函数之前的移除数据操作
2.evictAfter():定义执行窗口函数之后的以处数据操作
注意:默认情况下,预实现的移除器都是在执行窗口函数(window fucntions)之前移除数据的
*/
evictor(Evictor evictor)
3.3 allowedLateness
允许延迟的数据,设定允许延迟一段时间,在这段时间内,窗口不会销毁,继续到来的数据依然可以进入窗口中并触发计算更新结果。直到水位线推进到了 窗口结束时间 + 延迟时间,才真正将窗口的内容清空,正式关闭窗口
/**
方法签名
*/
allowedLateness(Time time)
3.4 sideOutputLateData
将迟到的数据放入侧输出流,可以将未收入窗口的迟到数据,放入“侧输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”,这个流中单独放置那些错过了该上的车、本该被丢弃的数据
/**
参数:OutputTag 输出标签,用来标记分支的迟到数据流
*/
sideOutputLateData(OutputTag<T> outputTag)
//实例化方式:
OutputTag<String> outputTag = new OutputTag<String>("late") {};
//提取侧输出流方法:由执行完所有窗口函数后得到的 DataStream 调用
getSideOutput(OutputTag<T> outputTag)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 详解 Flink 的 window API

发表评论 取消回复