爬取当当网图书数据并保存到本地,使用request、lxml的etree模块、pandas保存数据为excel到本地。
爬取网页的url为:
http://search.dangdang.com/?key={}&act=input&page_index={}
其中key为搜索关键字,page_index为页码。
爬取的数据包括:爬取的数据包括:书名、作者、图书简介、出版社、出版日期、价格、评论数量。
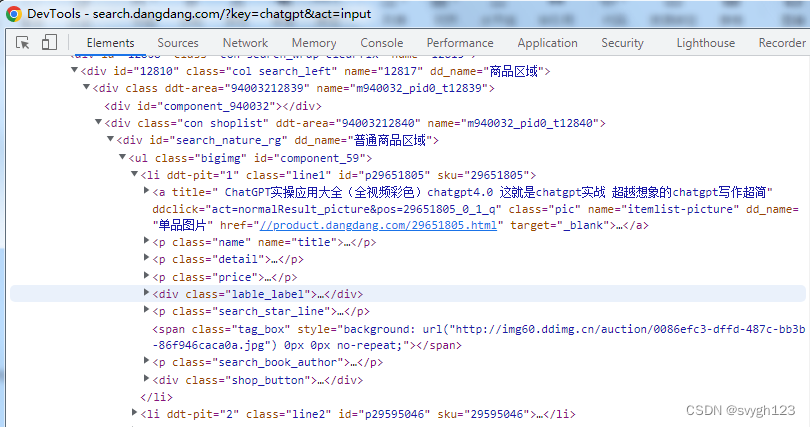
代码如下:
import random
import requests
from lxml import etree
import pandas as pd
import time
data = []
data.append(['书名', '作者', '图书简介', '出版社', '出版日期', '价格', '评论数量'])
def get_book_info(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
if response.status_code == 200:
selector = etree.HTML(response.text)
book_list = selector.xpath('//*[@id="component_59"]/li')
for book in book_list:
# 书名
book_name = ''.join(book.xpath('.//p[1]/a/@title'))
# 作者
book_author = ''.join(book.xpath('.//p[5]/span[1]/a/@title'))
# 图书简介
book_intro = ''.join(book.xpath('.//p[2]/text()'))
# 出版社
book_publisher = ''.join(book.xpath('.//p[5]/span[3]/a/@title'))
# 出版日期
book_date = ''.join(book.xpath('.//p[5]/span[2]/text()'))
# 价格
book_price = ''.join(book.xpath('.//p[3]/span[1]/text()'))
# 评论数量
book_comments = ''.join(book.xpath('.//p[4]/a/text()'))
# 随机等待时间,防止被封IP
rdn = random.randint(1, 5)
print(f'等待时间:{rdn}')
time.sleep(rdn)
data.append([book_name, book_author, book_intro, book_publisher, book_date, book_price, book_comments])
if __name__ == '__main__':
keyword = input('请输入搜索关键字:')
page_index = 1
while True:
url = f'http://search.dangdang.com/?key={keyword}&act=input&page_index={page_index}'
print(f'正在爬取第{page_index}页数据...')
get_book_info(url)
page_index += 1
if page_index > 1:
break
df = pd.DataFrame(data[1:], columns=data[0])
# 将DataFrame保存为Excel文件
df.to_excel(f'{keyword}.xlsx', index=False)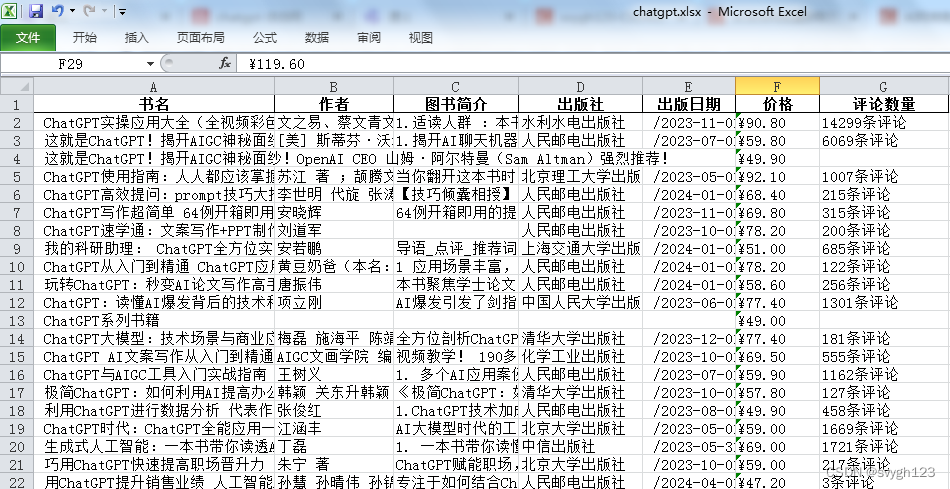
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 从当当网批量获取图书信息

发表评论 取消回复