在人工智能快速发展的今天,对于高效且性能卓越的语言模型的追求,促使谷歌DeepMind团队开发出了RecurrentGemma这一突破性模型。这款新型模型在论文《RecurrentGemma:超越Transformers的高效开放语言模型》中得到了详细介绍,它通过结合线性递归和局部注意力机制,承诺重新定义语言处理的标准。
模型架构
RecurrentGemma模型的架构是其高效性能的核心,它基于Google DeepMind提出的Griffin架构,这一架构通过结合线性递归和局部注意力机制,为处理语言任务提供了新的可能性。在深入探究RecurrentGemma的模型架构时,我们首先需要理解Griffin架构的基础,以及RecurrentGemma是如何在其基础上进行创新和优化的。
RecurrentGemma对Griffin架构进行了一项关键的修改,这一修改涉及输入嵌入的处理。模型的输入嵌入乘以了一个常数,这个常数等于模型宽度的平方根。这种处理方式对模型的输入端进行了调整,但并没有改变输出端,因为输出嵌入没有应用这个乘法因子。这种调整允许模型更有效地处理信息,同时保持了模型宽度的一致性。这种修改在模型的数学表达和信息流中起到了重要作用。它不仅优化了模型对输入数据的初始处理,而且通过调整嵌入的尺度,有助于模型更好地捕捉和表示语言的特征。
RecurrentGemma模型的性能和效率在很大程度上由其超参数决定。这些超参数是模型定义的关键部分,它们包括但不限于以下几个方面:
- 总参数量:2.7亿个参数,这表明了模型的复杂性和容量。
- 非嵌入参数量:2.0亿个参数,这是模型中不包括嵌入层的参数数量。
- 嵌入参数量:0.7亿个参数,这部分参数与模型的词汇嵌入直接相关。
- 词汇量:25.6万个词汇,这是模型能够理解和生成的词汇总数。
- 模型宽度:2560,这代表了模型内部表示的维度。
- RNN宽度:2560,这是循环神经网络部分的宽度。
- MLP扩展因子:3,这影响了模型中多层感知机的扩展程度。
- 深度:26层,这是模型的层数,反映了模型处理数据的深度。
- 注意力头数:10,这表示模型在处理序列时使用的注意力机制的头数。
- 局部注意力窗口大小:2048,这定义了局部注意力机制在序列上的作用范围。
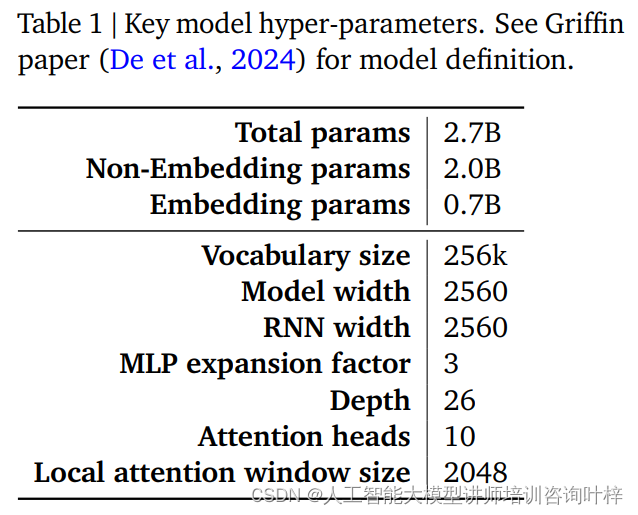
表1提供了这些关键超参数的总结,更详细的模型定义可以在De等人的Griffin论文中找到。这些超参数共同构成了RecurrentGemma模型的基础,使其能够在保持较小内存占用的同时,实现对长序列的高效处理。
通过对Griffin架构的精心修改和超参数的细致调整,RecurrentGemma模型不仅在理论上展现了其先进性,更在实际应用中证明了其高效性和强大的语言处理能力。
训练细节
RecurrentGemma-2B的预训练使用了2万亿个token,这一数据量虽然小于Gemma-2B使用的3万亿个token,但依然构成了一个庞大的数据集,为模型提供了丰富的语言信息。
预训练的数据来源主要是英文的网络文档、数学和代码。这些数据不仅涵盖了广泛的主题和领域,而且经过了精心的筛选和清洗,以减少不想要或不安全的内容,并排除了个人或敏感数据。此外,为了确保评估的公正性,所有评估集都被排除在预训练数据集之外。
RecurrentGemma-2B在预训练中首先使用了一个大型的通用数据混合,然后转向更小但更高质量的数据集进行进一步训练。这种分阶段的训练方法有助于模型在广泛的数据上学习通用的语言表示,然后通过更专业的数据进行细化和优化。
在预训练之后,RecurrentGemma-2B通过指令调整和RLHF算法进行了微调。这一过程旨在优化模型,使其能够更好地遵循指令并生成具有高奖励的响应。
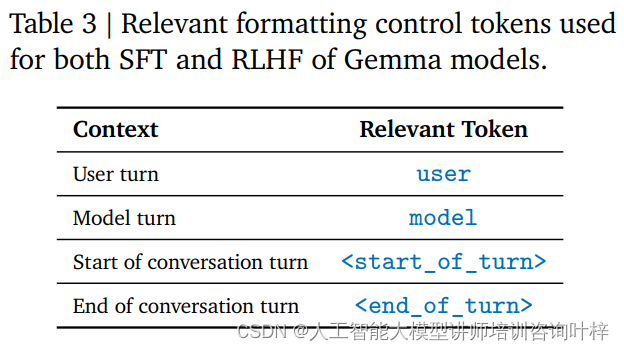
指令调整(Instruction Tuning)是一种训练方法,它使模型能够理解和响应特定的指令格式。RecurrentGemma-2B被训练以遵守特定的对话格式,这种格式通过特定的控制标记来定义,例如用户的输入和模型的输出分别用不同的标记来标识。
RLHF算法是一种先进的微调技术,它通过强化学习框架来优化模型的输出。在RLHF中,模型的输出会根据人类反馈进行评估,并根据评估结果进行调整,以提高输出的质量和奖励。这种算法使得模型能够学习如何在不同的上下文中生成更合适的响应。
通过指令调整和RLHF微调,RecurrentGemma-2B不仅能够生成高质量的语言输出,还能够在对话和遵循指令方面表现出色。这种训练方法为模型提供了灵活性和适应性,使其能够在各种应用场景中发挥作用。

通过这种方式,RecurrentGemma-2B成为了一个强大的语言模型,能够在多种任务和环境中提供高效和准确的语言处理能力。
评估
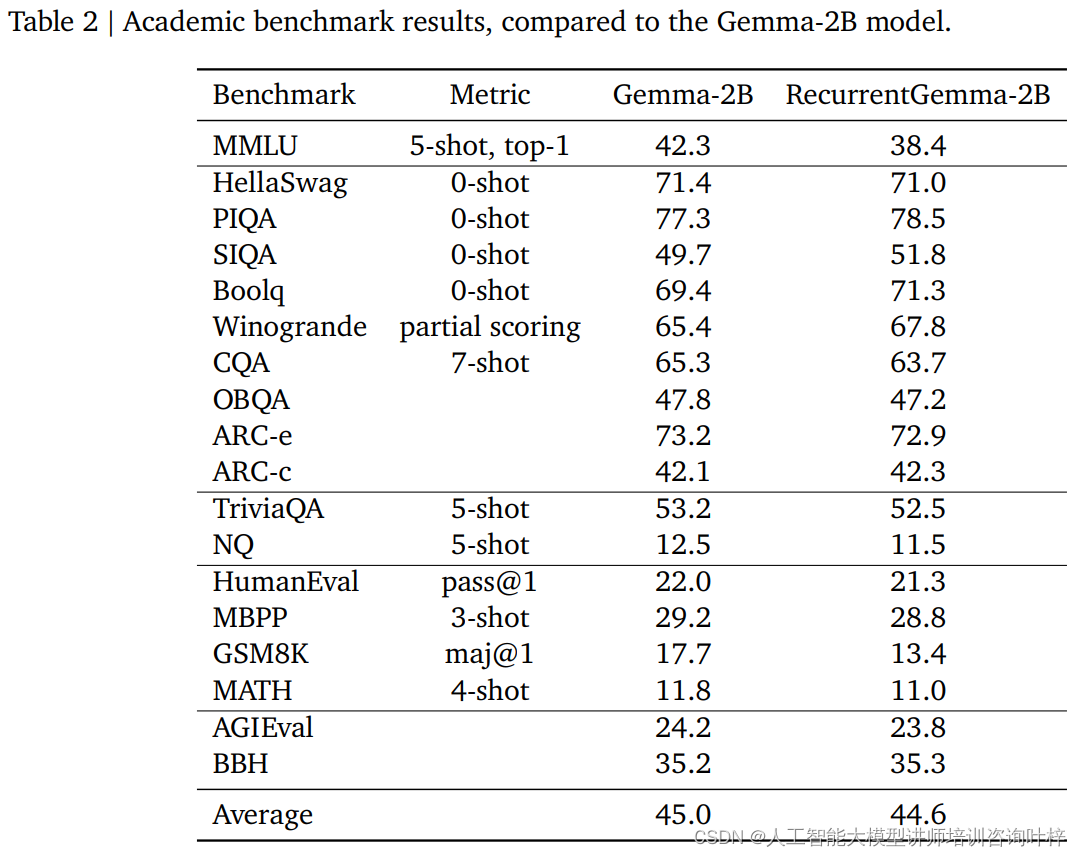
自动化基准测试是评估RecurrentGemma-2B性能的第一步。这些测试涵盖了多种流行的下游任务,包括但不限于问答、文本摘要、语言推理等。RecurrentGemma-2B在这些任务上的表现与Gemma-2B进行了比较,结果显示,尽管RecurrentGemma-2B训练的token数量较少,但其性能与Gemma-2B相当。
RecurrentGemma-2B在如MMLU 5-shot、HellaSwag 0-shot、PIQA 0-shot等多个学术基准测试中的表现与Gemma-2B相近,这证明了其在不同任务上的通用性和有效性。这些测试结果不仅展示了模型对语言的深入理解能力,也反映了其在实际应用中的潜力。
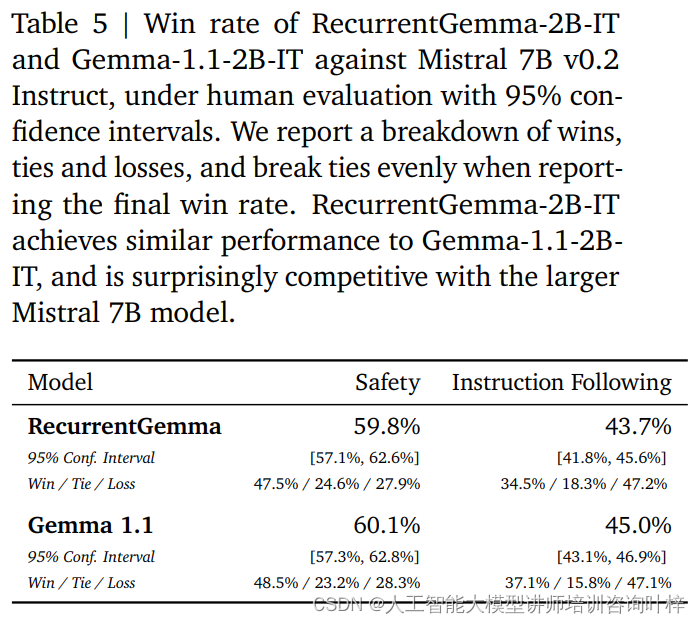
除了自动化基准测试,RecurrentGemma-2B还经过了人类评估的检验。人类评估是评估语言模型能否生成符合人类期望的响应的关键步骤。在这个过程中,RecurrentGemma-2B的指令调整变体(RecurrentGemma-2B-IT)与Mistral 7B v0.2 Instruct模型进行了对比。
人类评估使用了大约1000个针对创意写作和编码任务的指令遵循的提示集合。RecurrentGemma-2B-IT在这个集合上的表现令人印象深刻,其胜率达到了43.7%,仅略低于Gemma-1.1-2B-IT的45.0%。这一结果表明RecurrentGemma-2B在理解和执行复杂指令方面的能力与现有的先进模型相当。
RecurrentGemma-2B-IT还在大约400个测试基本安全协议的提示集合上进行了评估,其胜率达到了59.8%,显示出模型在遵循安全准则方面的优势。
通过结合自动化基准测试和人类评估,RecurrentGemma-2B的性能得到了全面的检验。自动化测试提供了对模型在各种语言任务上性能的定量评估,而人类评估则提供了对模型输出质量的定性理解。这种综合评估方法确保了RecurrentGemma-2B不仅在理论上表现出色,而且在实际应用中也能提供高质量的语言生成和理解能力。
推理速度基准测试
推理速度是衡量语言模型实用性的关键指标之一,尤其是在处理长序列数据时。RecurrentGemma-2B在推理速度上的优化是其区别于传统Transformer模型的一大亮点。在传统的Transformer模型中,为了进行有效的序列处理,模型需要检索和加载键值(KV)缓存到设备内存中。随着序列长度的增加,KV缓存的大小也会线性增长,这不仅增加了内存的使用,也限制了模型处理长序列的能力。尽管可以通过局部注意力机制减小缓存的大小,但这通常以牺牲一定的性能为代价。
RecurrentGemma-2B通过其创新的架构设计,解决了上述问题。它将输入序列压缩成固定大小的状态,而不是依赖于随序列长度增长的KV缓存。这种设计显著减少了内存的使用,并且使得模型在处理长序列时能够保持高效的推理速度。
在基准测试中,RecurrentGemma-2B展现出了显著的吞吐量优势。如图1a所示,在单个TPUv5e设备上,从2k个token的提示中采样不同长度序列时,RecurrentGemma-2B能够实现每秒高达6k个token的吞吐量,而Gemma模型则随着缓存的增长而吞吐量下降。
RecurrentGemma-2B的固定状态大小是其高效推理的关键。与Gemma模型相比,RecurrentGemma-2B的状态不会随着序列长度的增加而增长,这意味着它可以不受限制地生成任意长度的序列,而不受主机内存大小的限制。这一点在长序列处理中尤为重要,因为它允许模型在保持高性能的同时,处理更长的文本数据。
推理速度的提升不仅在理论上具有重要意义,更在实际应用中展现出其价值。在资源受限的环境中,如移动设备或边缘计算设备,RecurrentGemma-2B的高吞吐量和低内存占用特性使其成为一个理想的选择。此外,高效的推理速度也使得模型能够更快地响应用户请求,提供更加流畅的交互体验。
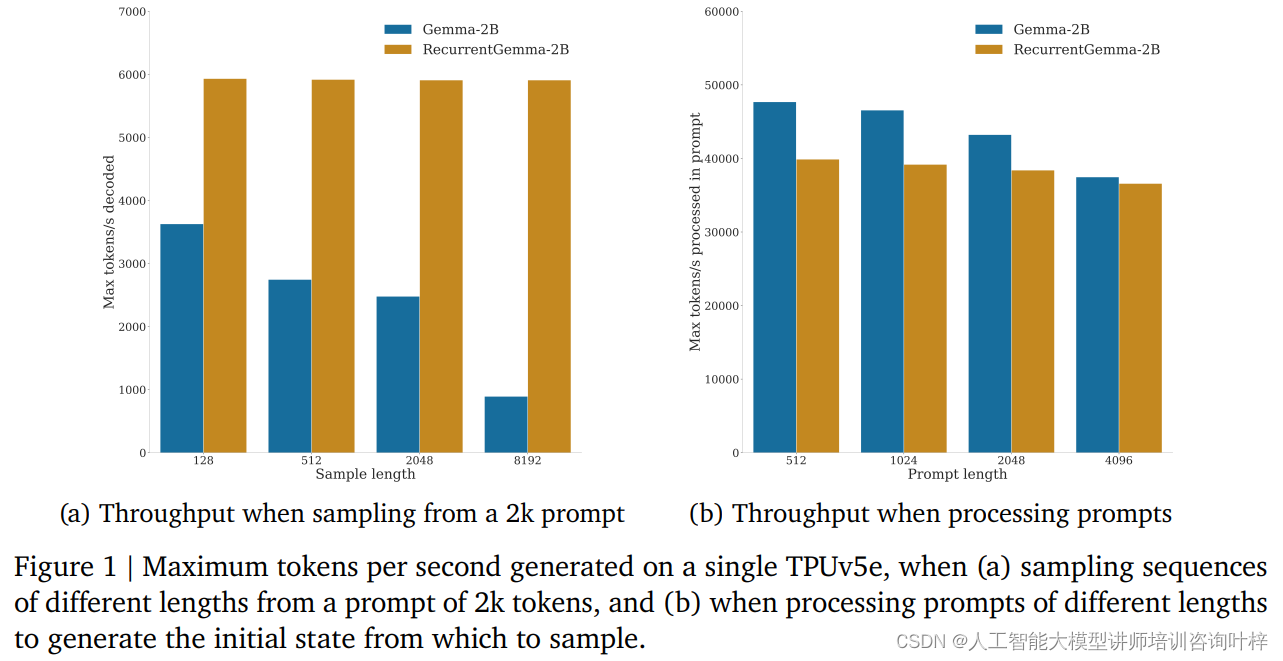
(b) 展示了处理不同长度提示时的吞吐量,与自回归采样不同,提示是并行处理的。Gemma和RecurrentGemma在处理提示时的速度相似。
负责任的部署
在人工智能领域,模型的部署不仅仅是技术的实现,更是对安全和伦理责任的承担。RecurrentGemma-2B的部署策略充分体现了对这些关键因素的重视。
在模型部署之前,RecurrentGemma-2B经过了一系列标准学术安全基准测试,这些测试旨在评估模型可能产生的不当行为或偏见。通过这些测试,开发团队能够识别并减轻潜在的风险,确保模型在公开使用时的安全性。
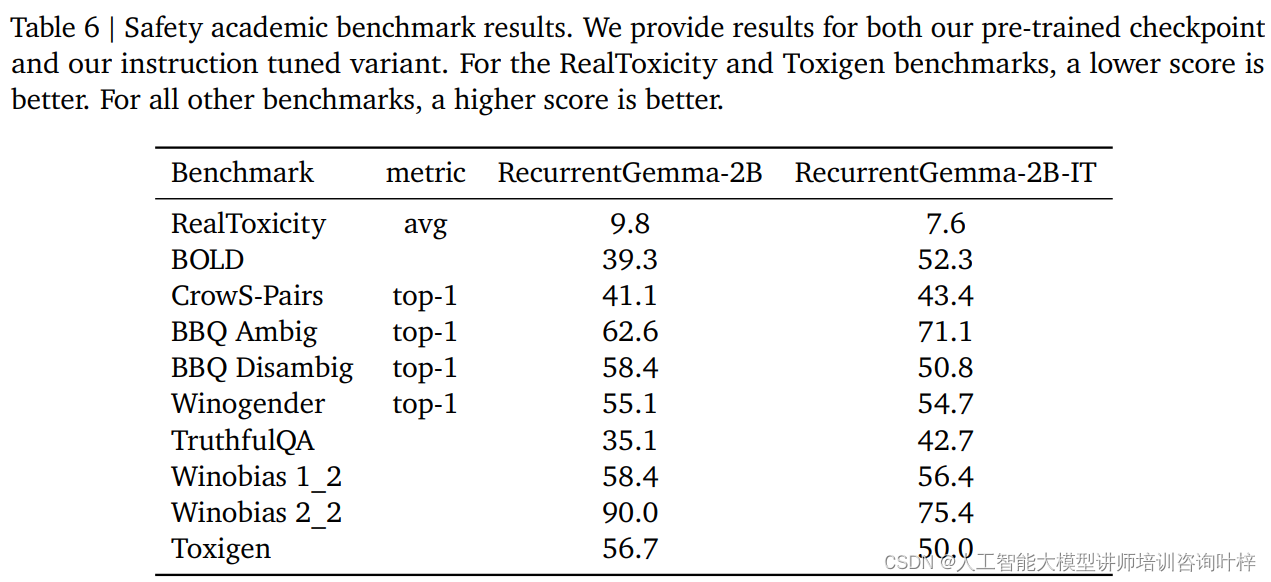
除了自动化的安全基准测试,RecurrentGemma-2B还接受了独立团队的伦理和安全评估。这一过程涉及对模型进行全面的审查,包括但不限于其对特定群体的公平性、避免产生有害输出的能力,以及对用户隐私的保护。
尽管进行了严格的测试和评估,但考虑到RecurrentGemma-2B可能被应用于多种不同的场景,开发团队强调无法覆盖所有可能的使用案例。因此,他们建议所有使用者在部署模型之前,根据自己的特定用例进行额外的安全测试。这一建议体现了对用户责任的强调,确保每个部署都是经过深思熟虑和定制化的。
负责任的部署还包括对模型性能和限制的透明度。开发团队提供了详细的模型架构和训练细节,使用户和研究人员能够理解模型的工作原理和潜在局限。此外,团队承诺对模型进行持续的监控和改进,以应对新出现的风险和挑战。
负责任的部署还涉及到与更广泛的AI社区和多方利益相关者的合作。通过分享研究成果、参与公开讨论和接受外部反馈,RecurrentGemma的开发团队展示了其对开放科学和协作的承诺。
随着人工智能领域的不断扩展,RecurrentGemma作为结合了创新架构设计理念、严格的训练和评估过程的典范,证明了在语言理解和生成方面突破可能性的界限的潜力。
论文链接:https://arxiv.org/abs/2404.07839
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 超越 Transformer开启高效开放语言模型的新篇章

发表评论 取消回复