一、故障场景
用户访问服务偶发报错【502 Bad Gateway】,但是服务后端正常运行。架构如下:
二、问题线索
服务正常,但是nginx报错【502 Bad Gateway】,这代表nginx认为后端服务都不存活
首先会想到网络问题,是不是网络抖动导致的,检查没有问题,那么只能看看nginx的日志了
在nginx的日志中看到三个报错:
- 502 Bad Gateway (各个接口都有,不固定)
- 504 upstream teime out (单个接口报错,都是接口A)
- no live upstream while connect (各个接口都有,不固定)
三、问题原因
看到nginx的日志之后,就可以明确定位到原因了,是nginx的健康检查机制导致。
3.1、nginx的健康检查介绍
nginx的upstream有默认的健康检查机制(max_fails和fail_timeout)
这个健康检查机制的逻辑是:
在fail_timeout时间段之内,如果该节点累计异常次数大于或等于max_fails,那么这个节点就会被摘除fail_timeout时间,fail_timeout时间之后该实例会被重新加入,并且该节点的异常次数重置为0,重新开始进行新一轮的检查
fail_timeout默认值为10S,max_fails默认值为1。
【举个例子】
后端两个实例,1.1.1.1 实例卡死(进程在,无响应,访问到会报504),2.2.2.2正常
Nginx配置如下
upstream test {
server 1.1.1.1:8081 weight=1;
server 2.2.2.2:8081 weight=1;
}
那么用户第一次访问,如果访问到1.1.1.1实例,实例无响应,超过超时时间,报错504,1.1.1.1的fail次数达到1次(max_fails默认值为1)
1.1.1.1实例被剔除10秒(fail_timeout默认值为10秒)
这10秒内存访问都会落在正常的2.2.2.2实例上,访问正常
直到10秒之后,异常实例1.1.1.1被重新加入转发,用户访问到之后再次报错504,1.1.1.1再次被剔除10秒,周而复始
这就会出现一个很规律的异常现象,每10秒就会出现一次504访问超时(访问到1.1.1.1异常实例无响应,超时报错)
3.2、本次异常原因梳理
本次异常是几个因素配到一起导致出现的异常现象
- 一个高频接口响应时间长,超过60秒
- fail_timeout是默认值10S,max_fails是默认值1
- proxy_read_timeout后端响应超时时间设置的是60S
有一个接口响应时间大部分都大于proxy_read_timeout设置的后端响应超时时间60秒,每次请求到这个接口,这个接口转发到后端实例,这个后端实例在proxy_read_timeout时间内没有返回,nginx直接返回504,并且记录失败次数为1,因为达到最大失败次数1(max_fails默认值为1),所以将该后端直接剔除10秒(fail_timeout默认值为10秒)
而这个接口被调用频繁,有几率出现短暂时间,所有实例都被nginx剔除的情况,如下图所示:
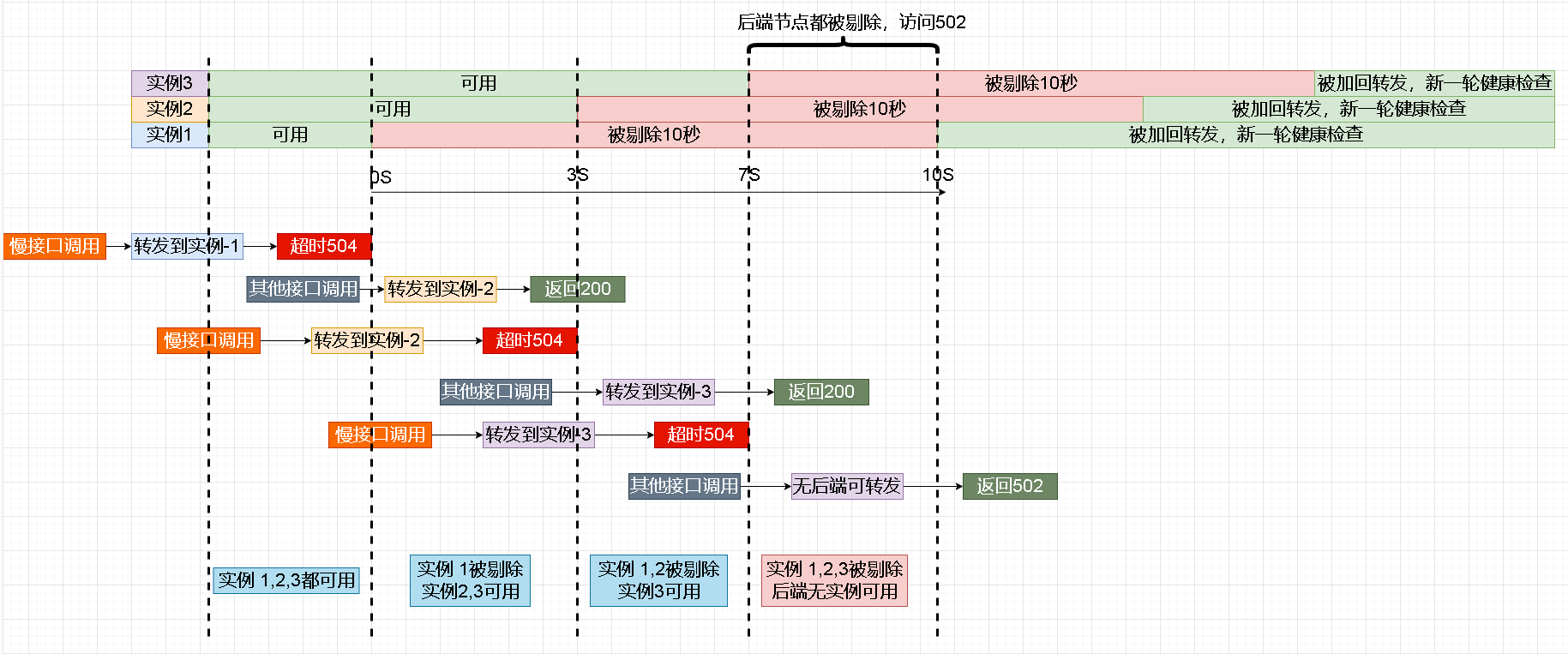
所以会出现一个接口报错504(响应慢的接口),全部接口偶发502的情况(所有节点被剔除的时间段),并且nginx error日志偶发出现【no live upstream while connect 】
四、处理方法
1、根本解决还是优化那个慢接口
2、或者为耗时较长的慢接口单独设置upstream和server,这样不会影响其他接口。
3、调大proxy_read_timeout,不让慢接口出现504。
4、提高检测是否可用的频率,即调大max_fails,调小fail_timeout,使 fail_timeout/max_fails变小。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Nginx实战:故障处理_后端服务正常,nginx偶发502(Bad Gateway)

发表评论 取消回复