过去一年,多模态大语言模型(MLLM)在视觉问答、视觉理解和推理等任务中表现出色。然而,模型的庞大尺寸和训练推理的高成本限制了其在学术界和工业界的广泛应用。因此,研究高效和轻量级的MLLM具有重要意义,尤其是在边缘计算场景中。来自来自于腾讯、上海交通大学、北京人工智能研究院、华东师范大学等机构的研究人员联合撰写了《Efficient Multimodal Large Language Models: A Survey》,论文对高效多模态大语言模型的相关研究进行了系统性回顾,并对该领域的未来发展方向进行了展望。


1、引言
随着人工智能技术的飞速发展,大型预训练语言模型在自然语言处理领域取得了令人瞩目的成就。这些模型能够理解和生成复杂的文本,展现出强大的语言能力。然而,随着模型规模的不断扩大,其计算成本也急剧增加,给实际应用带来了挑战。因此,研究如何提高大型语言模型的效率,使其能够在更短的时间内处理更多的任务,成为了当前研究的热点。

本文旨在对高效多模态大型语言模型的研究进展进行全面的综述,以期为相关领域的研究者提供有益的参考。
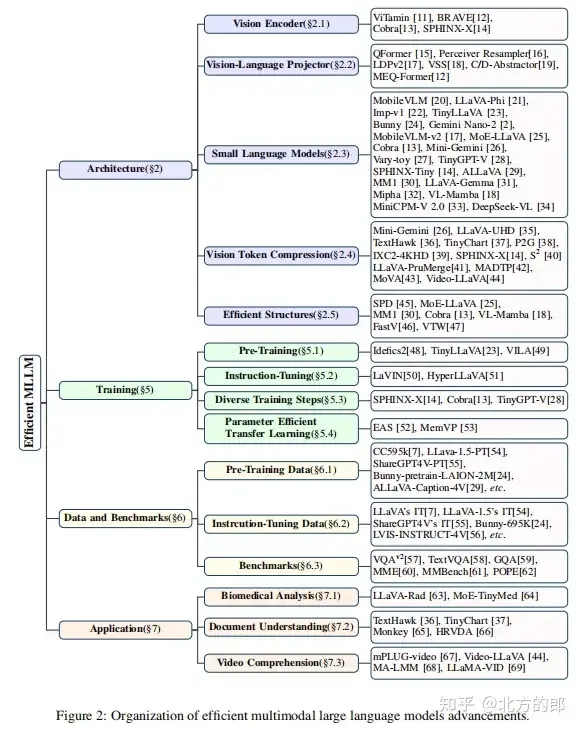
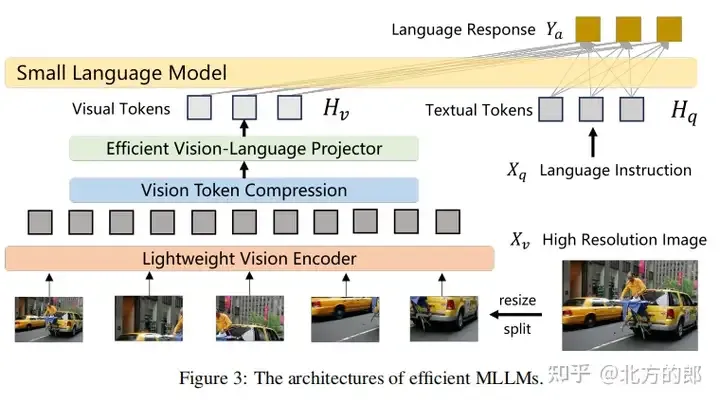
2、架构
2.1 视觉编码器(Vision Encoder)
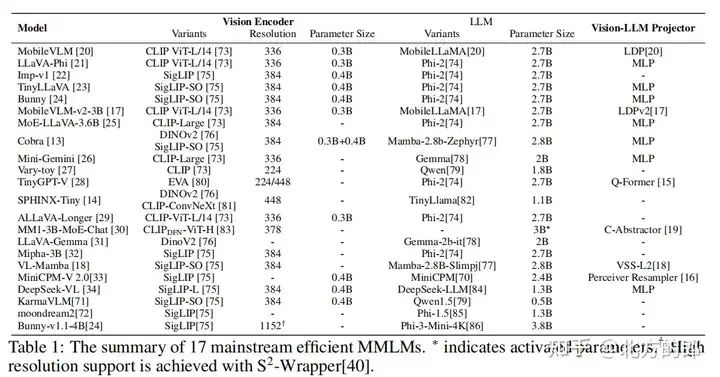
主流模型继续使用CLIP预训练的视觉编码器,如ViT等,以实现语义对齐。
一些研究采用了多个视觉编码器,以捕获更丰富的视觉表示。
一些研究采用了更轻量级的视觉编码器,例如ViTamin和Cobra等,以减少计算复杂度。
2.2 视觉-语言项目器(Vision-Language Projector)
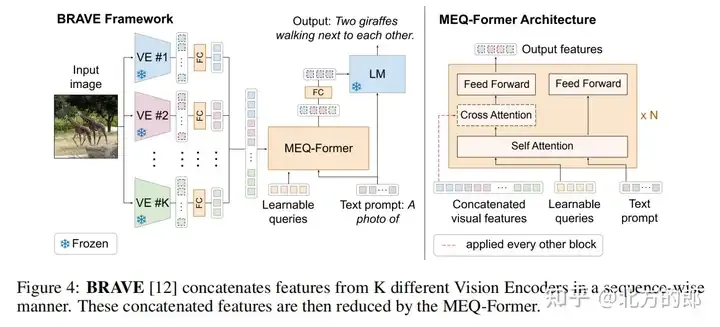
主流方法包括MLP和Attention-based,其中Attention-based方法如Q-Former和MEQ-Former。
一些研究采用了CNN-based方法,如MobileVLMv2的LDPv2。
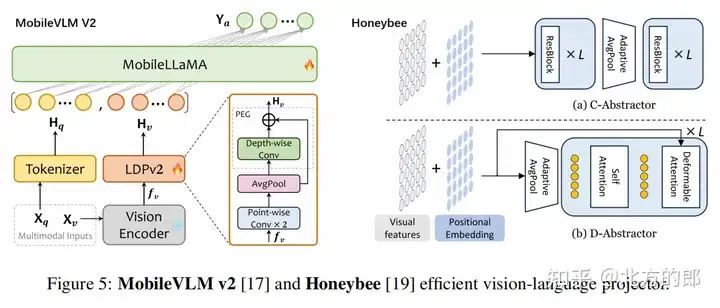
一些研究采用了混合结构,例如Honeybee的C-Abstractor和D-Abstractor。
2.3 小语言模型(Small Language Model)
主流方法使用参数规模小于3B的小语言模型,如phi2-2.7B和Gemma-2B。
一些研究采用自训练的小语言模型,如MobileVLM的LLaMA。
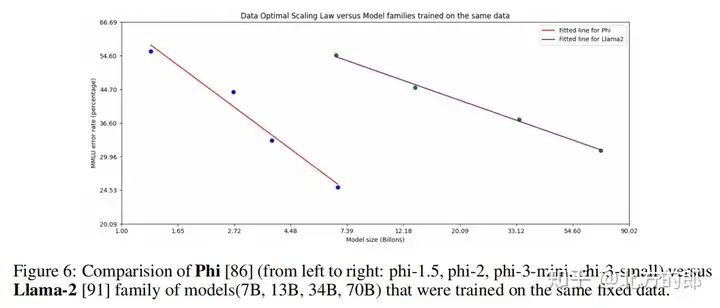
一些研究通过模型缩放降低参数规模,例如phi2和phi3-mini。
2.4 视觉标记压缩(Vision Token Compression)
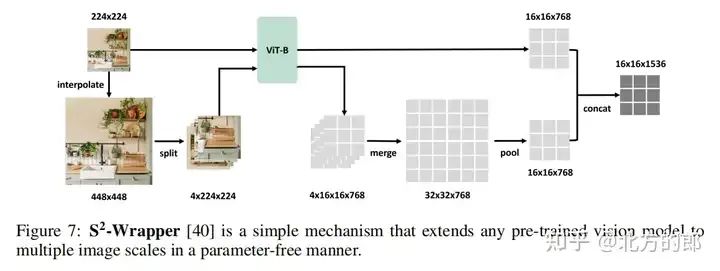
一些研究采用了多视图输入,如LLaVA-UHD。
一些研究采用了视觉标记处理方法,如LLaVA-PruMerge和MADTP。
一些研究采用了多尺度信息融合,如Mini-Gemini。
一些研究采用了视觉专家代理,如P2G。
一些研究采用了视频特定方法,如Video-LLaVA。
2.5 高效结构(Efficient Structures)
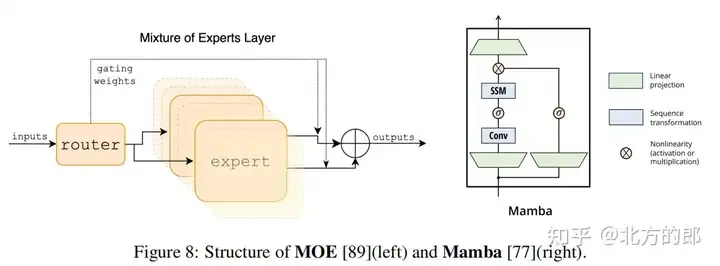
主要方向包括Mixture-of-Experts、Mamba和Inference Acceleration。
主流的MoE方法包括MoE-LLaVA和MM1。
主流的Mamba方法包括Cobra和VL-Mamba。
主流的Inference Acceleration方法包括SPD、FastV和VTW。
3 Efficient Vision
Efficient Vision部分主要介绍了用于高效多模态大语言模型的视觉编码方法,具体内容如下:
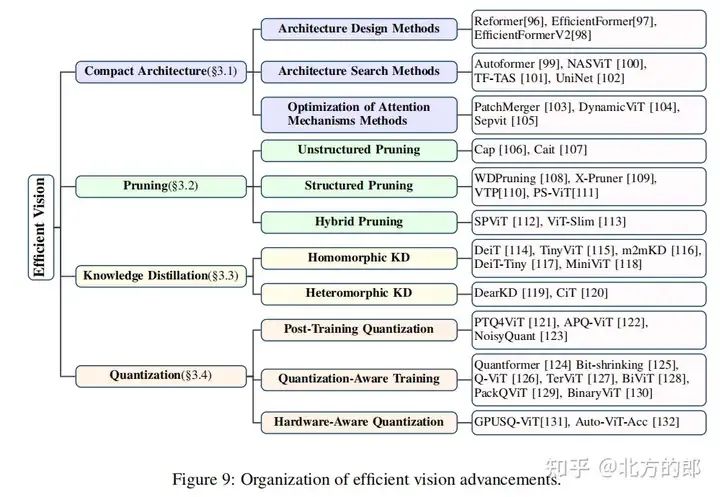
Compact Architecture
介绍了三种构建高效视觉模型的方法,包括架构设计、架构搜索和注意力机制优化。其中:
- • 架构设计方法可以通过调整现有架构或创建新架构来实现高效性,例如使用可逆残差层和局部敏感哈希等技术。
- • 架构搜索方法则利用神经架构搜索算法来发现适合特定任务或约束的紧凑架构。
- • 注意力机制优化方法则通过引入自适应注意力、学习稀疏注意力模式和动态调整注意力机制等方式来降低计算复杂度。
Pruning
介绍了三种剪枝方法,包括非结构化剪枝、结构化剪枝和混合剪枝。
- • 非结构化剪枝是指对单个权重进行剪枝,而不考虑其在模型中的结构安排。
- • 结构化剪枝是指根据预定义的标准来剪枝结构组件,例如注意力头或层。
- • 混合剪枝则是结合了非结构化和结构化剪枝的方法。
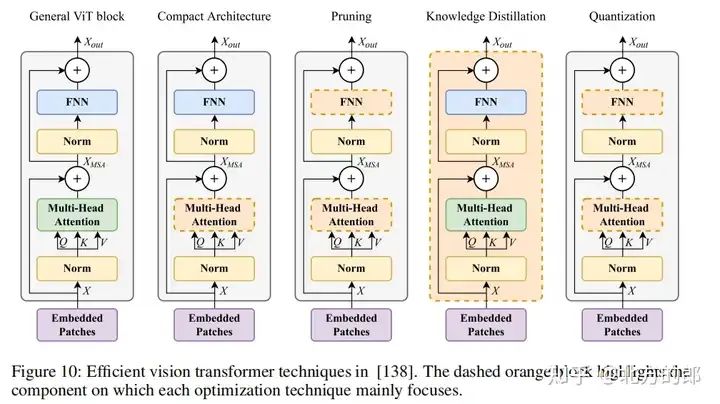
Knowledge Distillation
介绍了两种知识蒸馏方法,包括同构和异构知识蒸馏。
- • 同构知识蒸馏是指将大型模型的知识传递到小型模型中,而保持模型架构相同。
- • 异构知识蒸馏是指将知识从不同架构的模型中传递到另一个模型中。
Quantization
介绍了四种量化方法,包括后训练量化、量化感知训练、硬件感知量化和二值化。
- • 后训练量化是指在训练完成后对模型进行量化,以减少参数数量和计算量。
- • 量化感知训练是指在训练过程中引入量化操作,以提高模型对量化的鲁棒性。
- • 硬件感知量化是指根据特定硬件平台的特性来优化量化过程,以提高性能和效率。
- • 二值化是指将模型的参数二值化为0或1,以进一步减少参数数量和计算量。
4 Efficient LLMs
Efficient LLMs部分主要介绍了提高大语言模型效率的方法,具体内容如下:
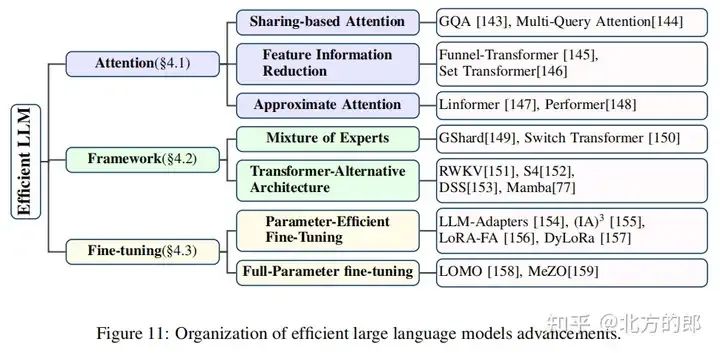
Attention
介绍了多种提高注意力机制效率的方法,包括共享注意力、特征信息减少、近似注意力等。其中:
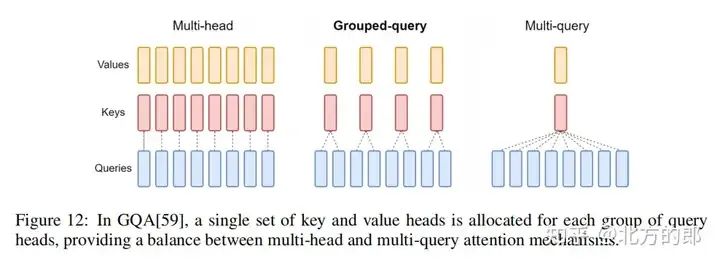
- • 共享注意力通过共享计算资源来加速注意力计算,例如LLaMA-2模型使用的GQA技术。
- • 特征信息减少通过减少输入特征的数量来降低计算复杂度,例如Funnel-Transformer和Set Transformer模型。
- • 近似注意力通过使用低维空间中的核函数或低秩矩阵来近似注意力计算,例如Linformer和Performer模型。
Framework
介绍了多种提高大语言模型效率的框架,包括混合专家模型、Transformer替代结构、状态空间模型等。其中:
- • 混合专家模型将大模型分解为多个小模型,每个小模型专注于学习输入数据的一部分,从而提高效率。
- • Transformer替代结构通过使用其他结构来替代Transformer,例如RWKV和Mamba模型,从而提高效率。
- • 状态空间模型通过将输入数据映射到低维状态空间中,从而提高效率。
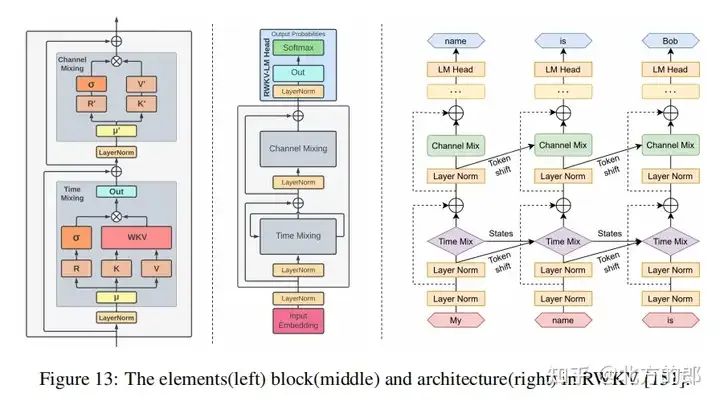
Fine-Tuning
介绍了多种提高大语言模型微调效率的方法,包括参数高效微调、全参数微调等。其中:
- • 参数高效微调通过引入轻量级适配器模块来减少微调参数的数量,从而提高效率。
- • 全参数微调通过更新预训练模型的所有参数来实现最优性能,但需要更多的计算资源。
5 Training
Training部分主要介绍了高效多模态大语言模型的训练方法,具体内容如下:
Pre-Training
介绍了预训练的重要性和目标,以及常见的预训练数据集。
- • 预训练的主要目标是促进不同模态的融合,并传达全面的知识。
- • 常见的预训练数据集包括CC3M、CC12M、SBU、LAION-5B、LAION-COCO、COYO、COCO Caption、CC595k、RefCOCO、DocVQA、LLava-1.5-PT、ShareGPT4V-PT和Bunny-pretrain-LAION-2M。
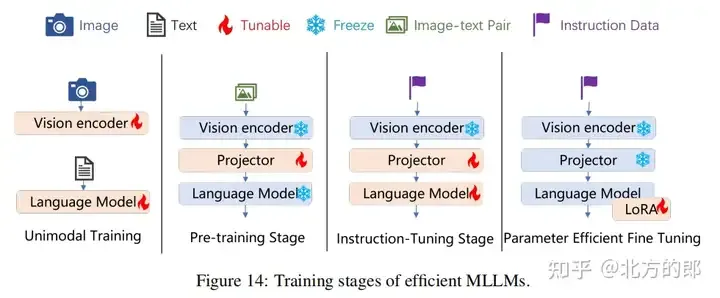
Instruction-Tuning
介绍了指令调优的重要性和方法,以及常见的指令调优数据集。
- • 指令调优的主要目标是使模型能够理解和遵循自然语言指令,从而提高其在特定任务上的性能。
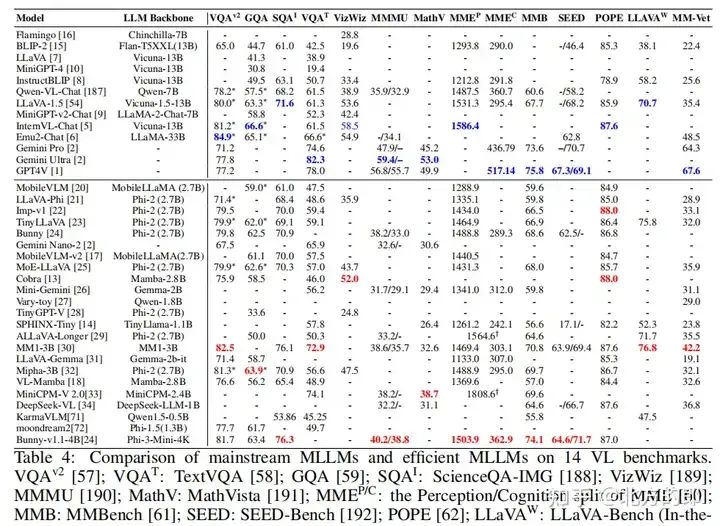
- • 常见的指令调优数据集包括LLaVA’s IT、MobileVLM、ShareGPT4V’s IT、LLaVA-1.5’s IT、LRV-Instruct、LVIS-INSTRUCT-4V、LAION GPT4V、MiniGPT-4’s IT、SVIT、Bunny-695K、GQA、VQAv2、VQAT、GQA、SQAI、VizWiz、MMMU、MathV、MMEP、MMEC、MMB、SEED、POPE、LLAVAW和MM-Vet。
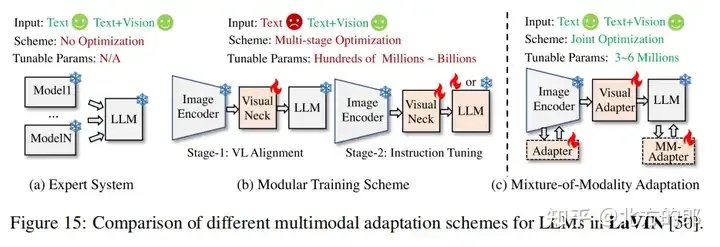
Diverse Training Steps
介绍了多种训练步骤的优化方法,包括单阶段训练、预对齐阶段的必要性、不同数据集的融合以及多任务学习。
- • 单阶段训练可以减少训练时间和计算成本,
- • 预对齐阶段可以提高模型的性能和泛化能力
- • 不同数据集的融合可以提高模型的多样性和适应性
- • 多任务学习可以提高模型的性能和泛化能力。
Parameter Efficient Transfer Learning
介绍了参数高效转移学习的重要性和方法,以及常见的参数高效转移学习技术。
- • 参数高效转移学习的主要目标是在不损失性能的情况下,减少模型的参数数量和计算量。
- • 常见的参数高效转移学习技术包括LoRA、(IA)3、LoRA-FA、DyLoRa、LLM-Adapters、Full-Parameter fine-tuning、Unsupervised learning和Reinforcement learning。
6 Data and Benchmarks
这部分介绍了用于训练和评估高效多模态大语言模型的数据和基准,具体内容如下:
Pre-Training Data
介绍了预训练数据的两个主要目标,即促进模态融合和传达全面知识。大规模的图像-文本对数据集通常满足这些要求,它们主要来自互联网,提供了广泛的知识覆盖。预训练数据的处理方法包括使用自动化工具进行清洗和过滤,以及利用更强大的多模态模型进行高质量的预训练。
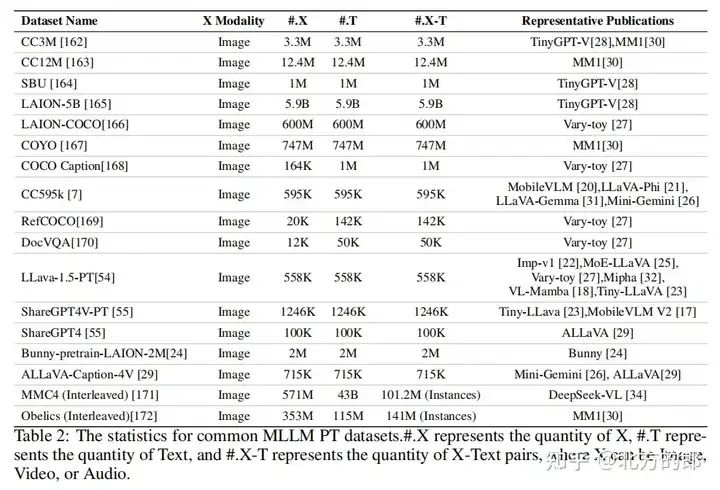
Instruction-Tuning Data
介绍了指令调优数据的重要性和来源。高质量的指令调优数据可以来自任务特定的数据集,也可以通过半自动化生成或利用大型语言模型进行自监督学习得到。多任务数据集可以提供丰富的数据,但在实际应用中可能不够灵活。此外,还提到了利用文本指令数据和图像-文本数据的组合来提高模型的性能。
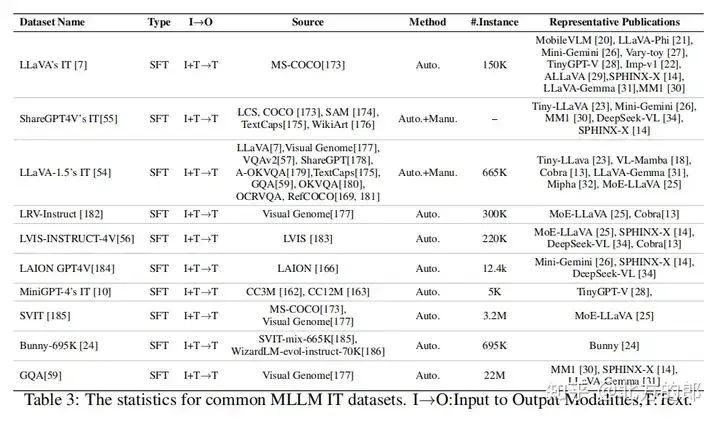
Benchmarks
展示了用于评估22个多模态大语言模型在14个已建立的视觉语言基准上的性能的表格,并与13个更显著和更大的多模态大语言模型进行了比较。
7 Applications
这部分介绍了高效多模态大语言模型在一些下游任务中的应用,具体内容如下:
Biomedical Analysis
介绍了多模态生成AI在生物医学领域的应用,特别是在医学问答和医学图像分类方面的应用。还提到了MoE-TinyMed和LLaVA-Rad等模型在资源有限的医疗环境中的优势。
Document Understanding
介绍了文档理解的重要性和挑战,以及现有的文档理解模型在处理高分辨率图像和视觉信息压缩方面的局限性。还提到了TinyChart、TextHawk、HRVDA和Monkey等模型在解决这些问题方面的优势。
Video Comprehension
介绍了智能视频理解的重要性和应用,以及现有的基于LLM的大模态模型在处理长视频时的计算挑战。还提到了mPLUG-video、Video-LLaVA、LLaMA-VID和MA-LMM等模型在处理长视频方面的优势。
8 Discussion and Conclusion
这部分对高效多模态大语言模型的发展现状进行了总结,指出了当前研究面临的挑战,并对未来的研究方向进行了展望,具体内容如下:
Limitations and Future Work:
- • 处理多模态信息的能力有限:目前的高效多模态大语言模型在处理多模态信息时仍存在挑战,通常只能接受单一图像,这限制了它们在处理长视频和复杂文档等方面的应用。
- • 输入和输出模态的多样性不足:大多数高效多模态大语言模型主要支持图像和文本作为输入模态,以及文本作为输出模态。然而,现实世界中的模态更加丰富,例如音频、触觉等。
- • 模型的可扩展性和定制性有待提高:为了使高效多模态大语言模型更具适用性,需要进一步提高其可扩展性和定制性,以满足不同应用场景的需求。
- • 边缘计算和具身智能的应用潜力尚未充分挖掘:高效多模态大语言模型在边缘计算和具身智能领域具有巨大的应用潜力,但目前这方面的研究还相对较少。
Conclusion
高效多模态大型语言模型是一个充满挑战和机遇的研究领域,未来的发展还需要学术界和产业界的共同努力和合作。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

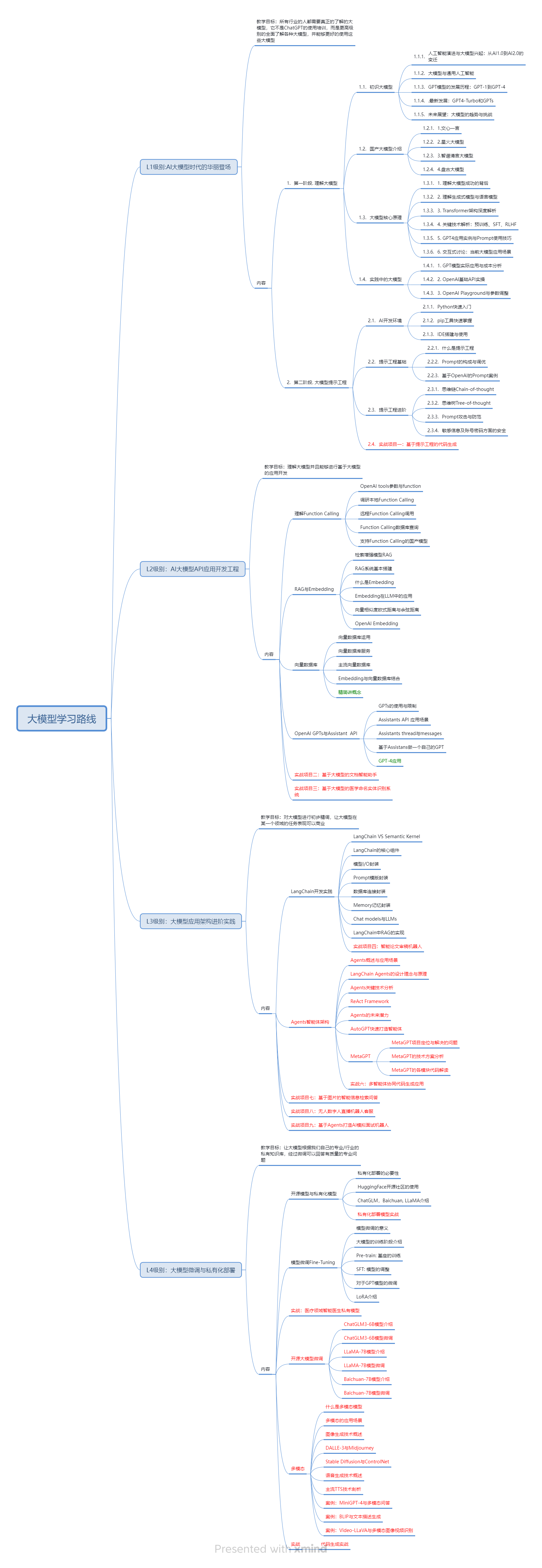
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。
二、AI大模型视频教程
三、AI大模型各大学习书籍
四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 探索高效和轻量级多模态大语言模型的奥秘

发表评论 取消回复