目录
1,ArrayList的缺陷
当在ArrayList任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后搬移,时间复杂度为O(n),效率比较低,因此ArrayList不适合做任意位置插入和删除比较多的场景。因此:java 集合中又引入了LinkedList,即链表结构。
2,链表
2.1 链表的概念及结构
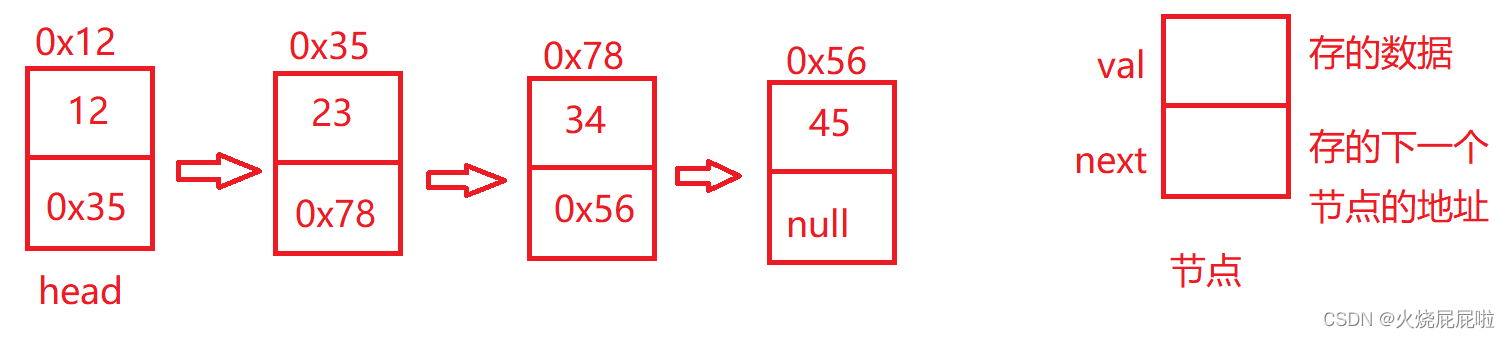
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。
链表是由一个一个节点组织起来的,整体就叫做链表
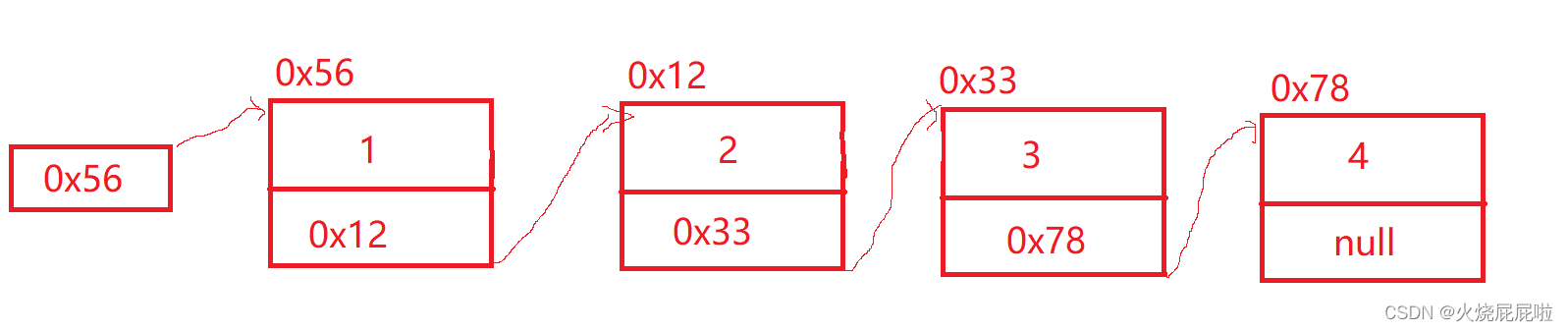
注意:
1,从上图可以看出,链式结构在逻辑上是连续的,但是在物理上(地址)不一定是连续的
2,现实中的节点一般都是从堆上申请出来的
3,从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,可能不连续
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向
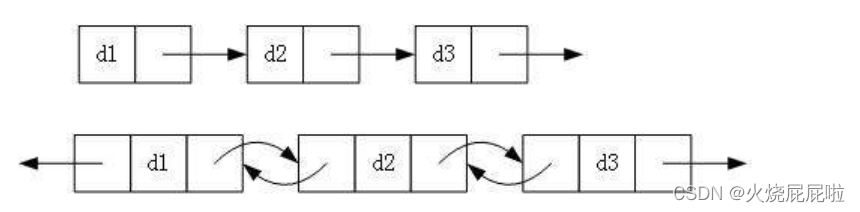
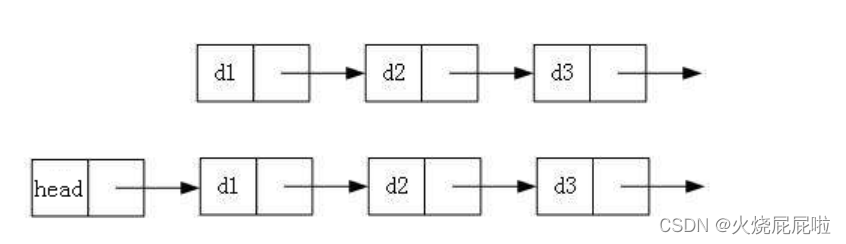
2. 带头或者不带头
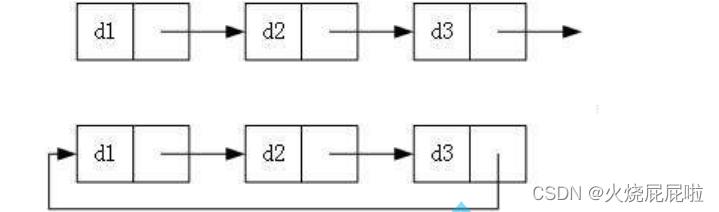
3. 循环或者非循环
我们主讲单向不带头非循环和双向不带头非循环:因为截止到目前为止,所有链表的题考的都是单项不带头非循环
1,单向不带头非循环:
带头:
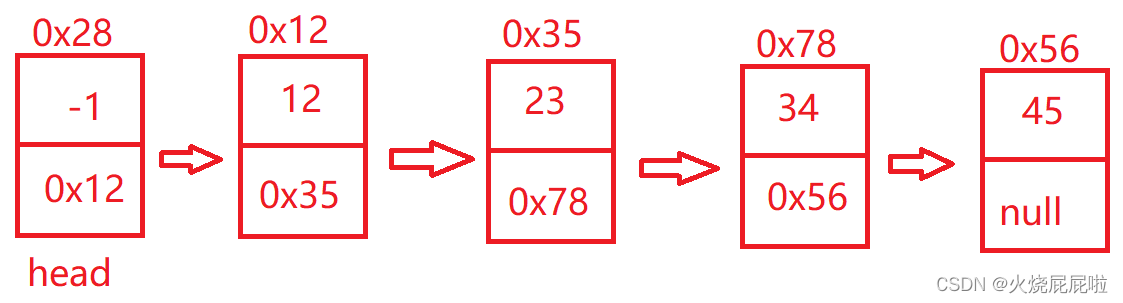
如果是带头的,头节点里面也可以存储值,但是不具备意义,可以认为头节点是一个标志,永远是头,不会动了,就是说对于不带头的链表,如果把12删了,head就会指向23节点的地址,对于带头的链表来说,把12删了,head还是在原来位置。
循环:
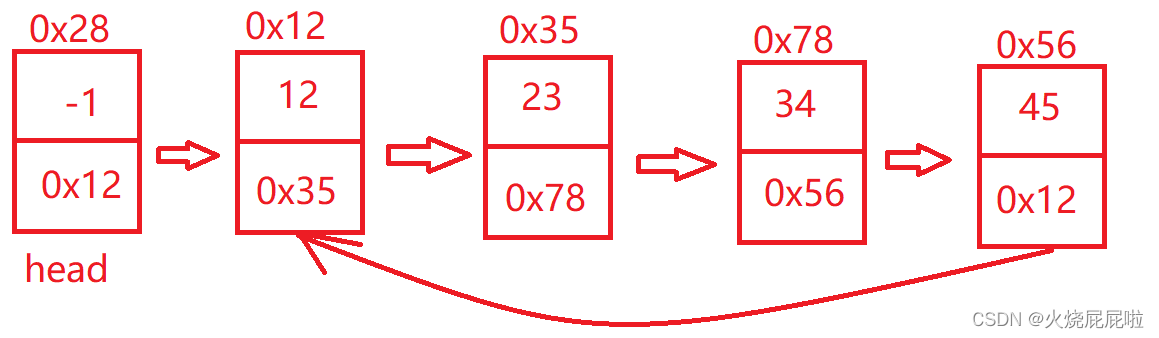
无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向非循环链表。
2.2 链表的实现
2.2.1 无头单向非循环链表实现
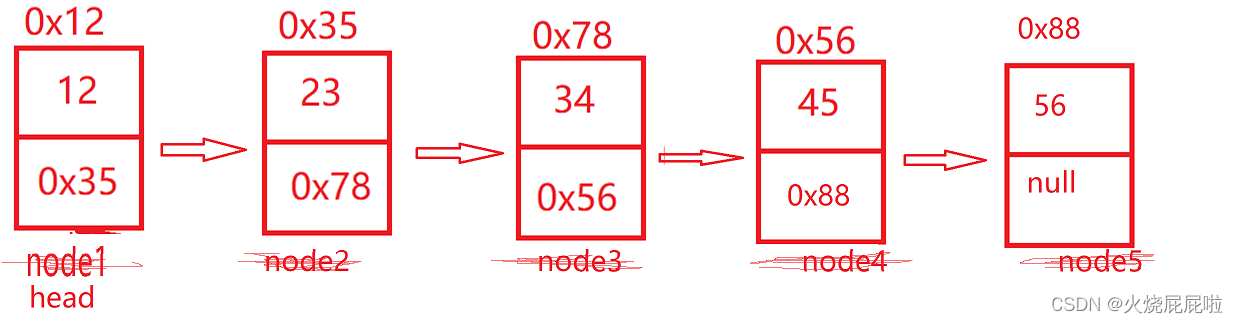
1,首先定义一个类,表链是由多个节点组成的,节点是一个完整的结构,提供给链表使用,我们就可以把节点定义到内部类当中,节点当中至少有两个域,value的类型是int,next是用来存下一个节点的地址的,所以next的类型应该是节点的类类型。
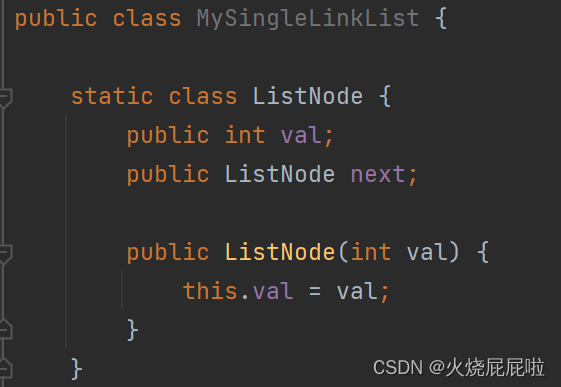
2,整个链表有一个东西叫做head,代表指向当前的链表,属于链表的属性,代表的是链表的头节点部分。head存的也是地址,即类型为节点类型
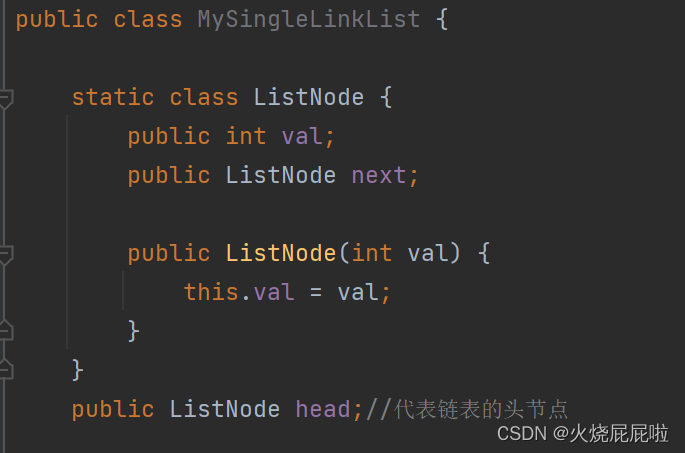
3,创建链表,外部类里面定义一个方法,用于链表的实现。首先有很多节点,一个一个节点属于节点对象
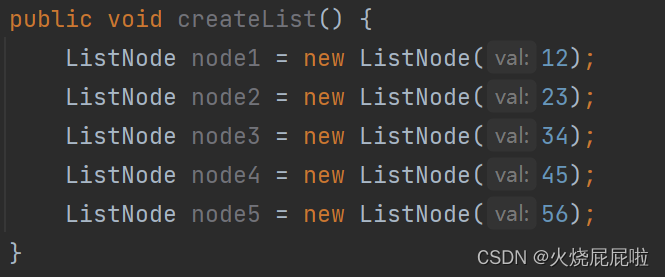
此时的链表是这样的
问题一:如何让第一个节点和第二个节点关联,以此内推......
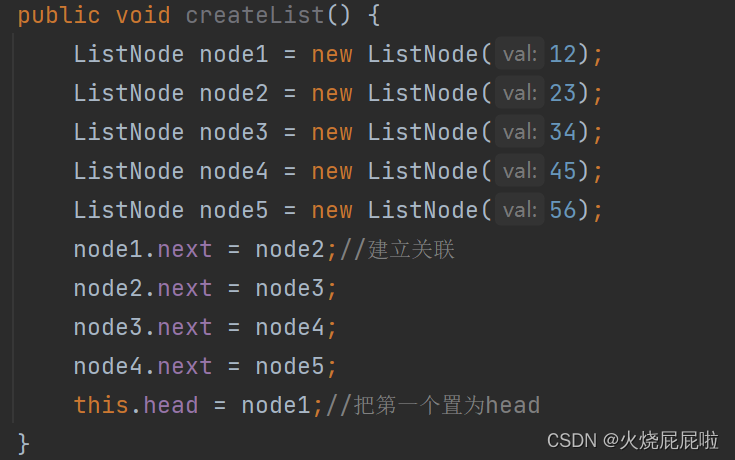
当这个方法结束之后,node1,2,3,4,5就不会存地址了,他们属于局部变量,局部变量会被回收,所以这个方法走完之后,就没有这几个局部变量了
此时,就形成了一个链表
测试类:
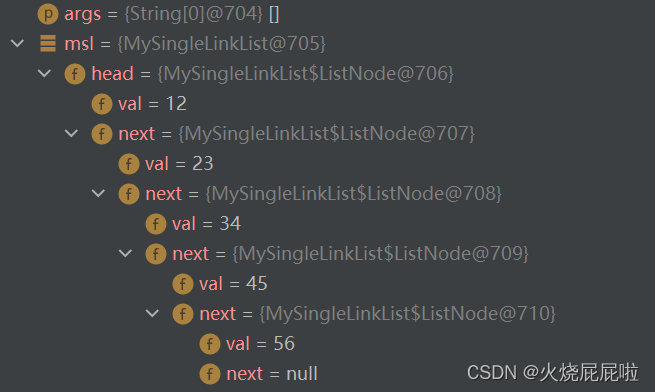
4,打印链表
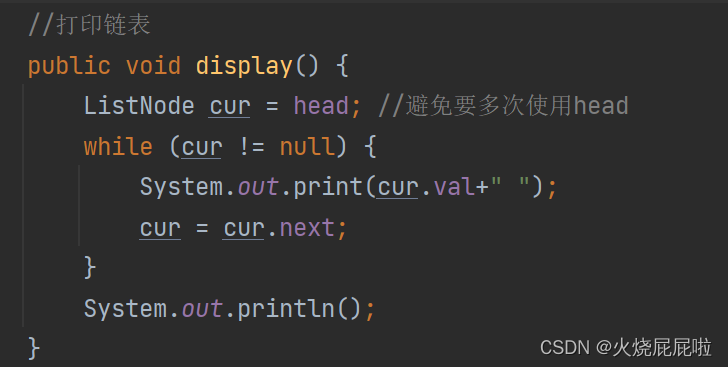
问题一:怎么从第一个节点走到第二个节点......
head = head.next
问题二:链表什么时候遍历完?
head = null ,整个链表会遍历完。若head.next = null ,56不会打印
还是在外部类中定义一个方法,用于遍历链表
测试类:
5,求链表的长度 ,还是在外部类当中定义一个方法,定义一个count用来计数。

测试类:
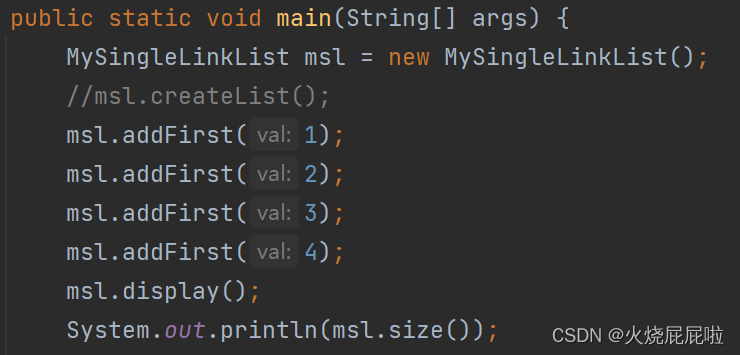
6,头插法
我们插入的是一个节点,实例化出来一个节点对象,再把这个节点插入到头节点的前面,head指向的位置应该指向插入节点的位置
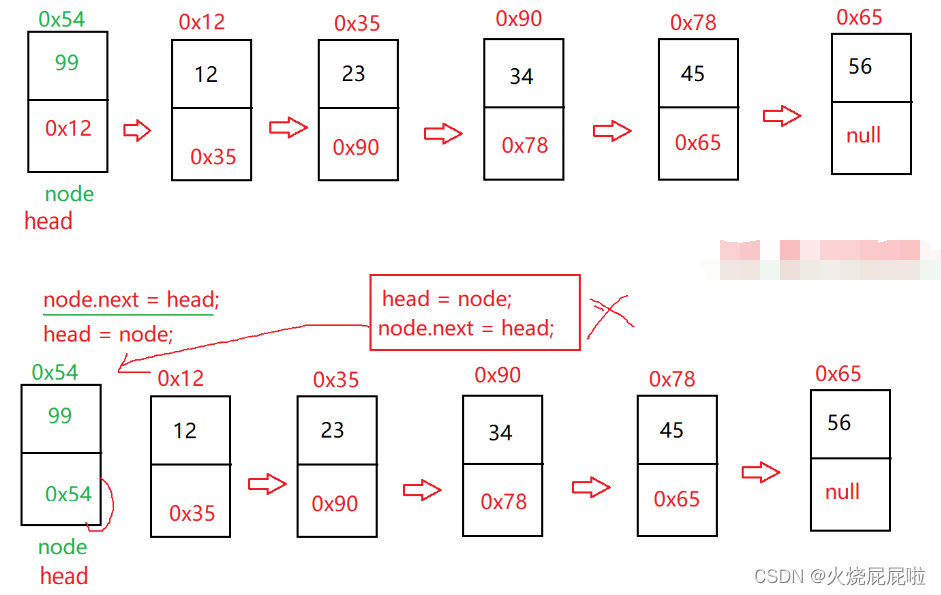
node.next = head
head = node
两个顺序不可交换,插入节点的时候,一般首先绑后面
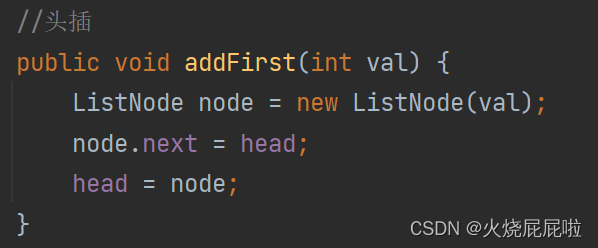
哪怕你所插入的链表是一个空链表,这个代码也是可以完成的
即我们在创建链表的时候,就可以不用上面createList()方法(枚举)来创建了,直接只要头插即可
测试类:
7,尾插法
首先还是需要实例化一个节点,在需要找到当前链表的尾巴,然后在把尾巴的next置为你所插入节点的地址即可
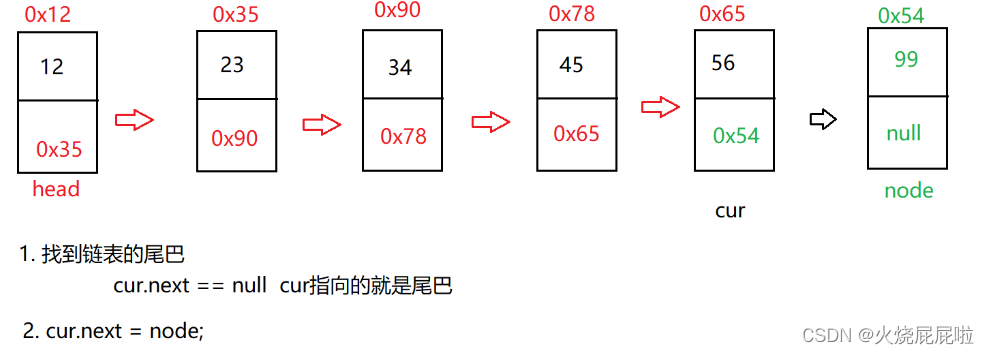
但是还需要考虑你的head为空的时候
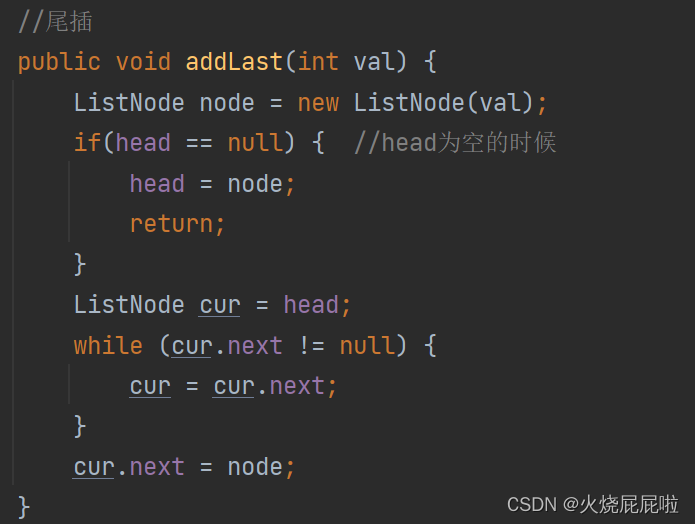
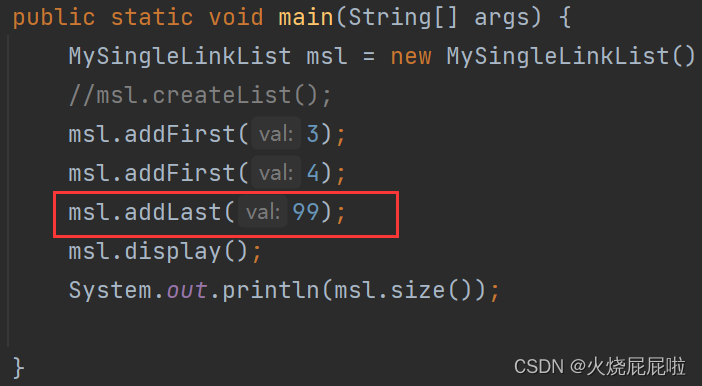
测试类:

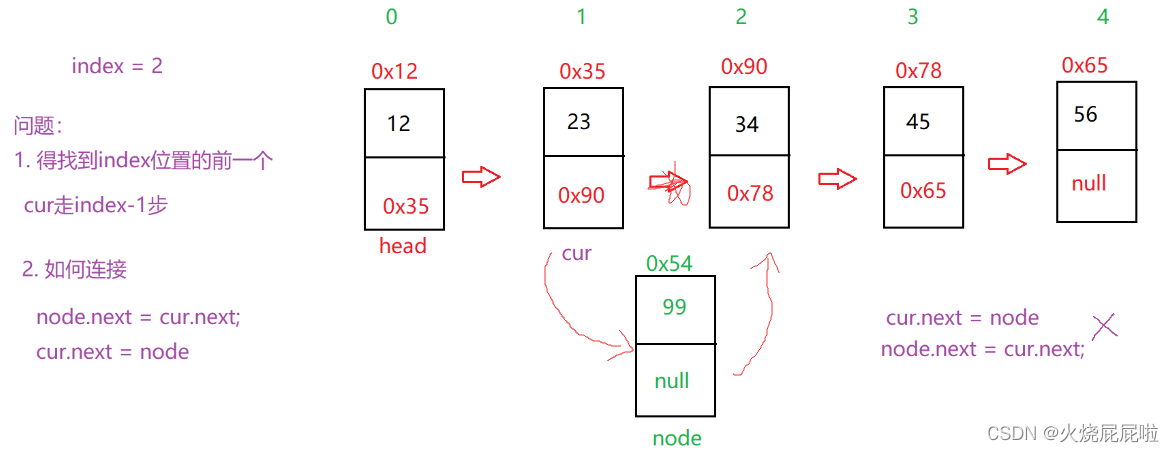
8,任意位置插入
可以把原链表做一个位置标记,然后在某位置前面插入。例如在2位置前面插入一个节点。
首先要找到2位置的前一个节点,cur只需要走2-1步。将插入节点的next改为1位置的next,在把1位置的next改为所插入节点的地址。定义一个count来记录cur的位置
还要考虑其他问题:
index == 0—>头插法 index == size—>尾插法
index < 0 || index > size 位置不合法,抛异常即可

测试类:

9,判断某个关键字是否在链表当中

测试类:
10,删除第一次出现的关键字节点
首先要遍历链表,是否你要删除的val。然后找到val节点的前一个节点cur,不能走到val节点,他是单向链表,不能再回去了。在将你要删除的节点val定义为del,将 cur.next = del.next 或者写成cur.next = cur.next。next 即可。
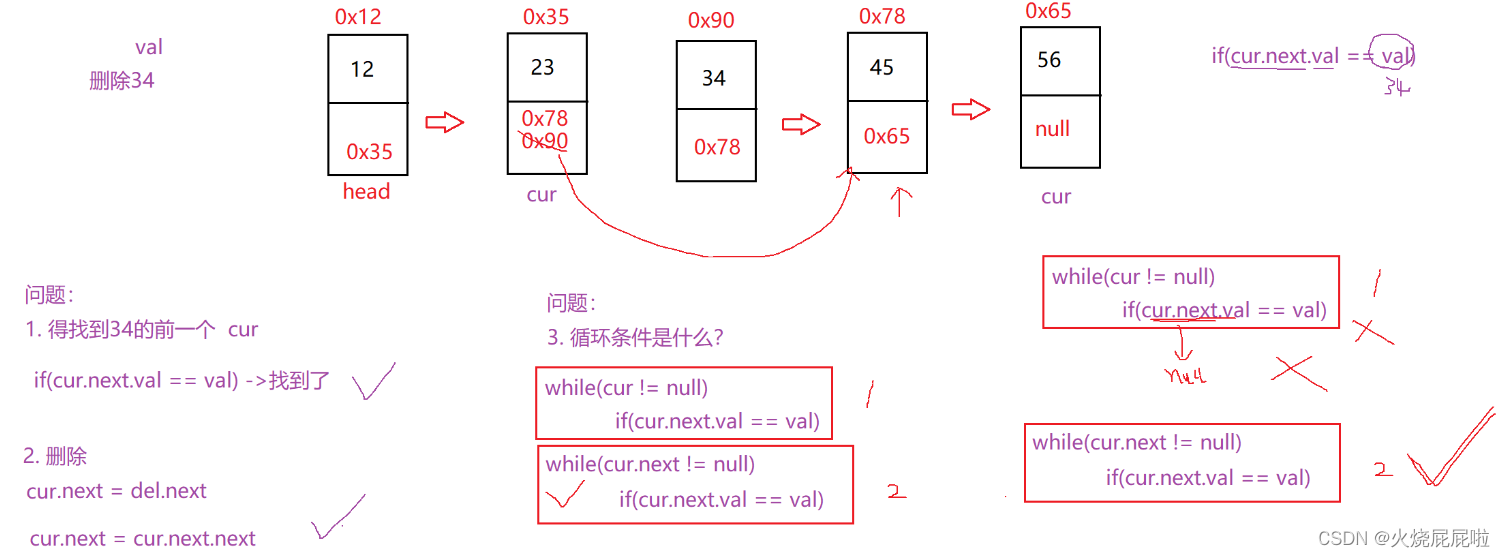
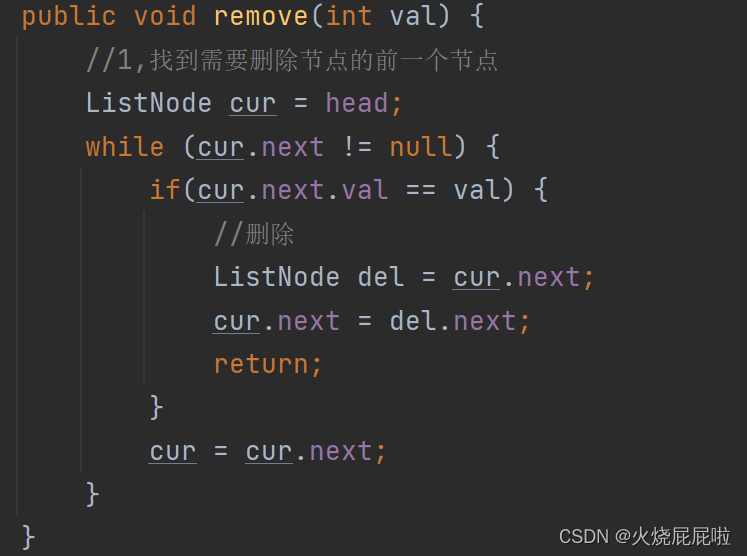
注意:此代码不能删除头节点,需要另外判断
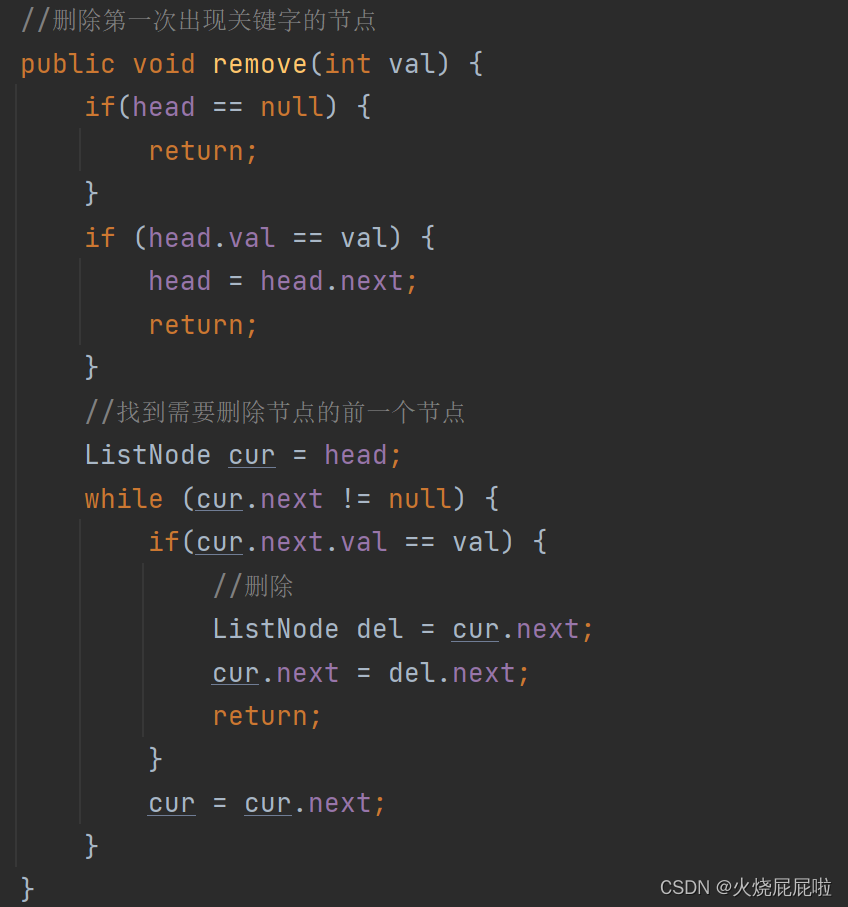
测试类:

11,删除链表里面所有的key
要求:对其本身就行修改
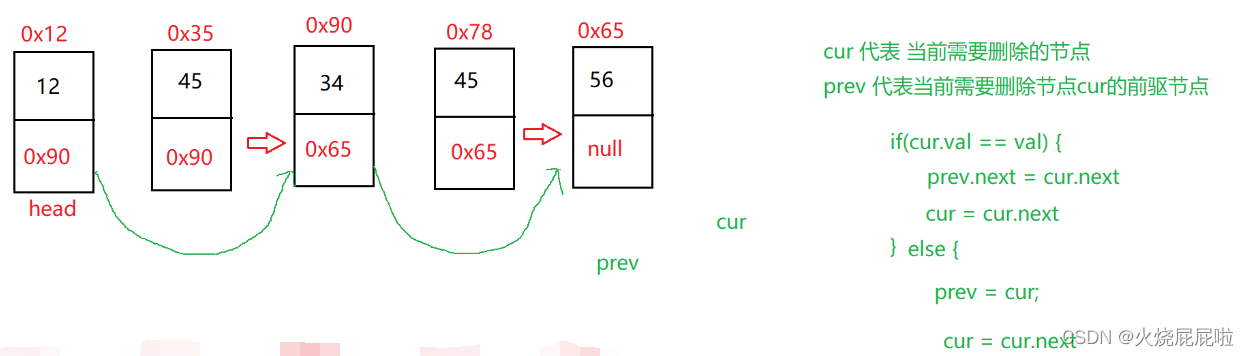
首先定义两个引用cur(代表当前需要删除的节点)prev(代表cur节点的前驱节点),判断if(cur.val==key),如果成立,让prev.next 等于cur节点的下一个节点(cur.next),再让cur往后走(cur = cur.next),prev还不能走,因为永远要保持是cur的前驱。然后继续判断,如果if条件不成立,则需判断else的情况,因为cur不是你要删除的key,需要让perv走到cur(perv = cur),再让cur走向下一个节点(cur = cur.next)。
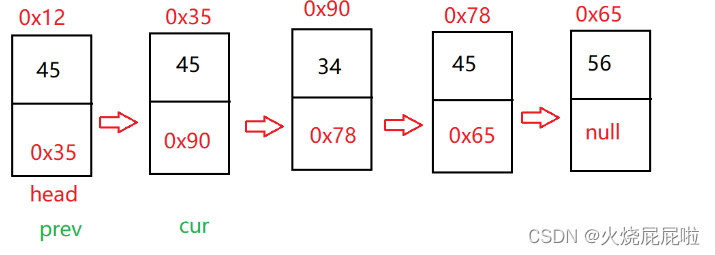
但是这种情况没有考虑到头节点也需要删除。我们只需要判断一下头节点是否是你需要删除的key,如果是,删除头节点(head = head.next),如果下个一个头节点还是你要删除的key,则循环判断即可,或者先让上面的代码走完在判断即可。
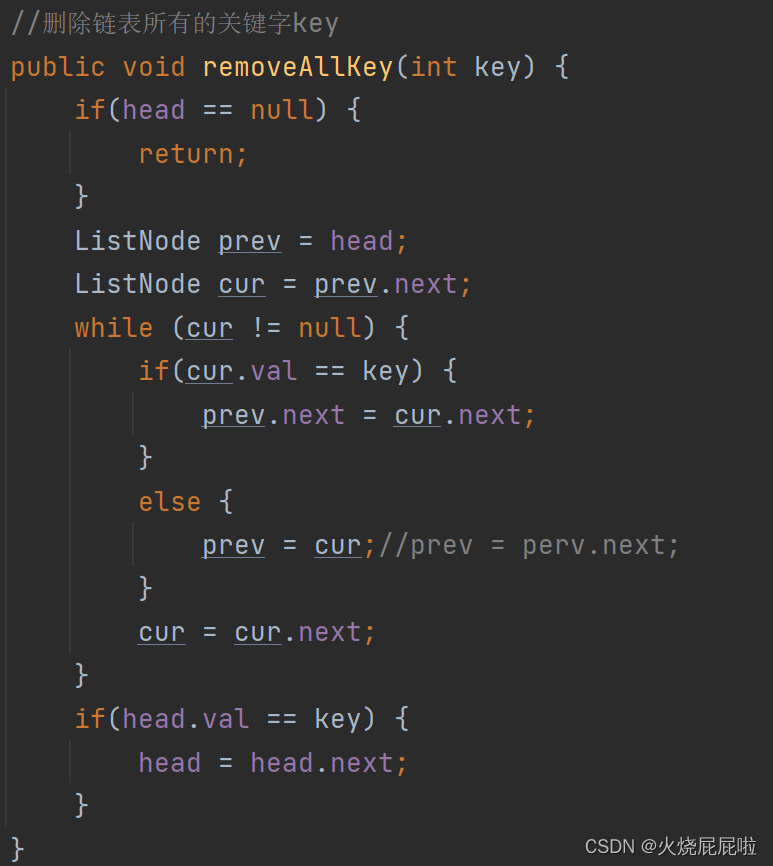
测试类:
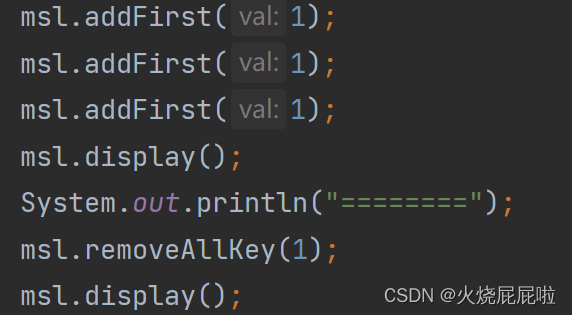
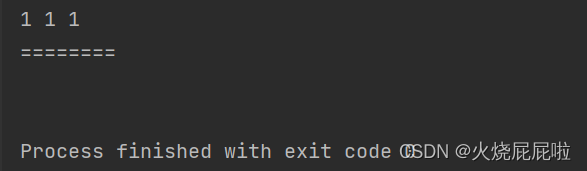
12,清空链表
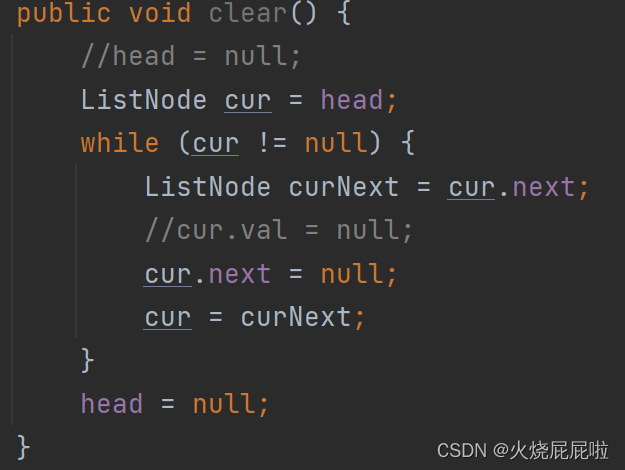
让每一个节点都被回收掉,最直接的方式将head置为空,意味着head不在引用这个对象,即所有节点都会被回收。还要一种做法,定义cur,将cur.val置为空,将cur.next置为空,cur再往后走。但是要考虑头节点的val
3,LinkedList的模拟实现
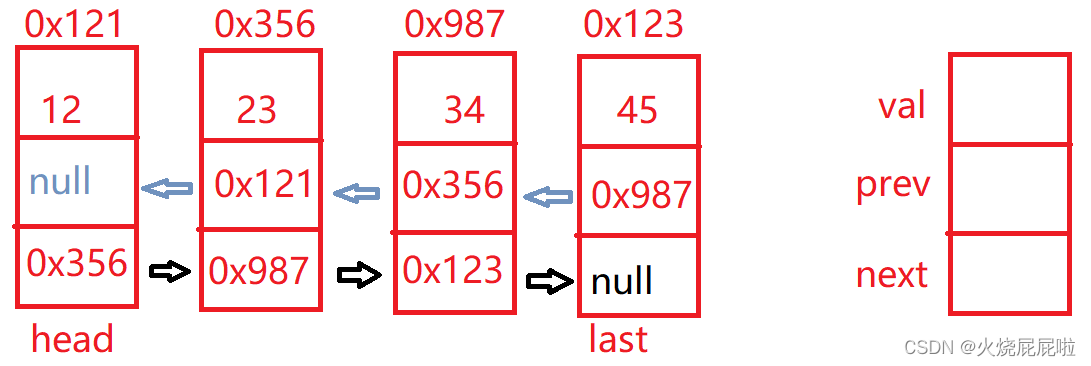
LinkedList是Java的一个集合类,这个类可以当作链表来使用。前提是这个链表是一个双向链表
首先这种链表的节点,至少包含3个域,其中val是你存放的值,next是下一个节点的地址,prev是上一个节点的地址。同时LinkedList底层实现的时候,还加了一个last,代表永远指向链表的尾巴
3.1 无头双向链表实现
首先创建MyListedList类用来实现双向链表,在定义一个内部类来创建一个节点,在创建出head,last。

1,实现双向链表的长度
定义一个cur来遍历链表,定义一个count用来记录链表长度。

2,打印链表的val
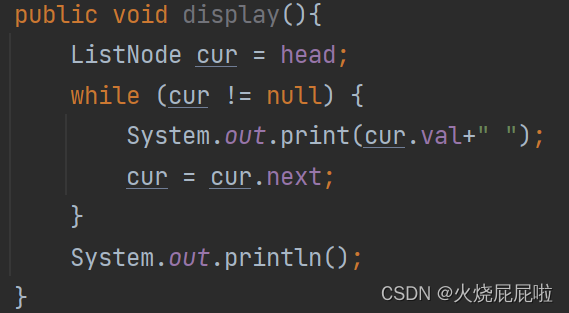
3,查找链表是否包含关键key

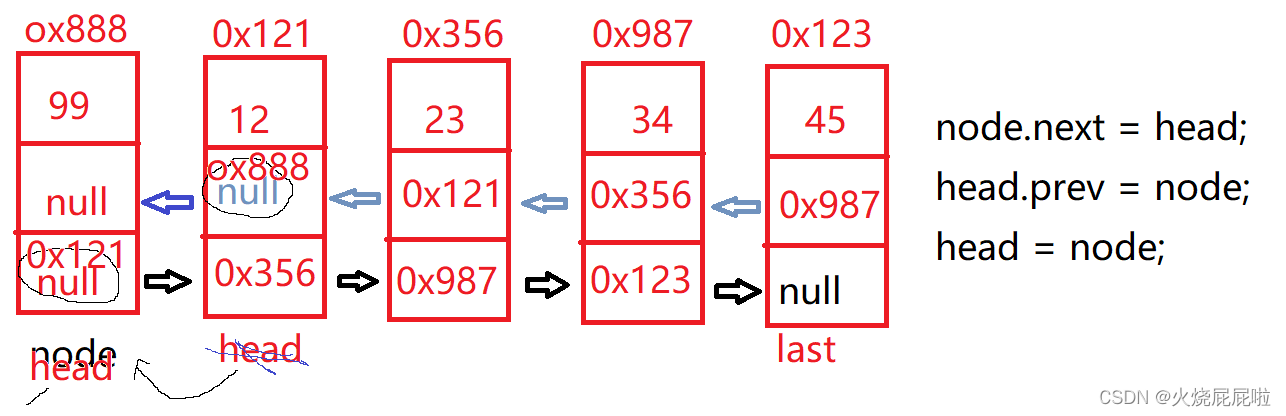
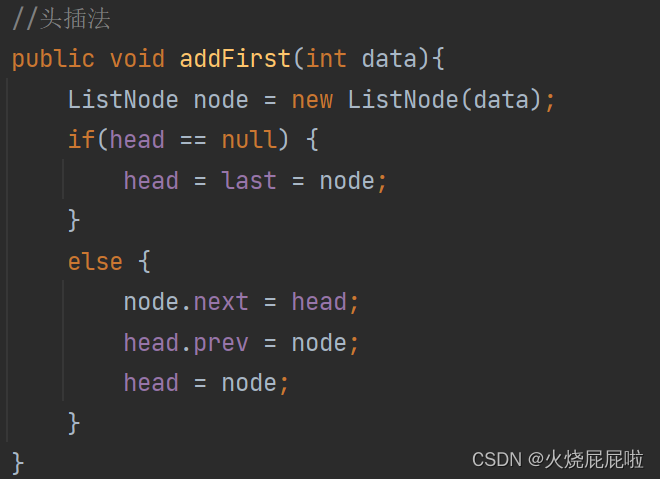
4,头插法
首先new一个节点,将这个节点插入到当前链表的头部,修改head.prve,node.next和head=node即可。
还有可能一个节点都没有,即head和last都为空,让head和last同时指向node即可
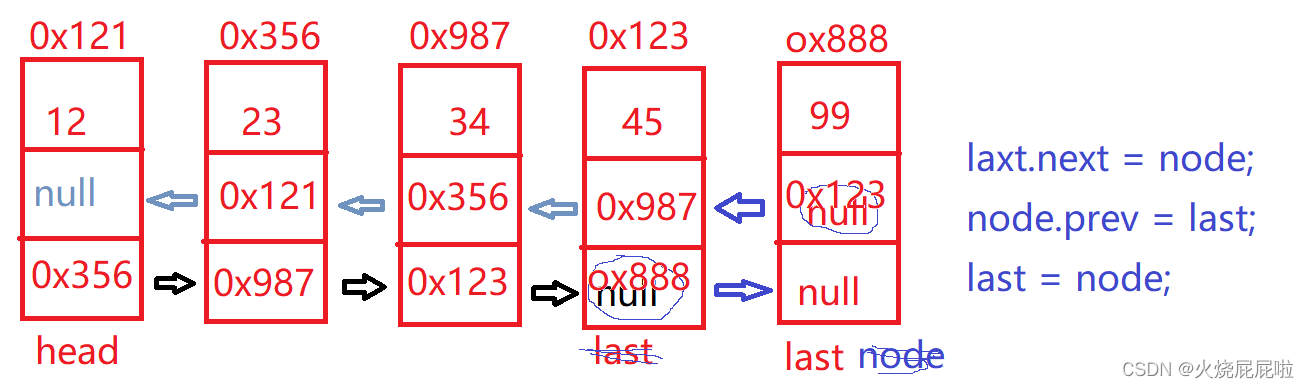
5,尾插法
如果是空的来链表,让head和last同时指向node即可
若不空,只需要修改last.next,node.prev和last=node
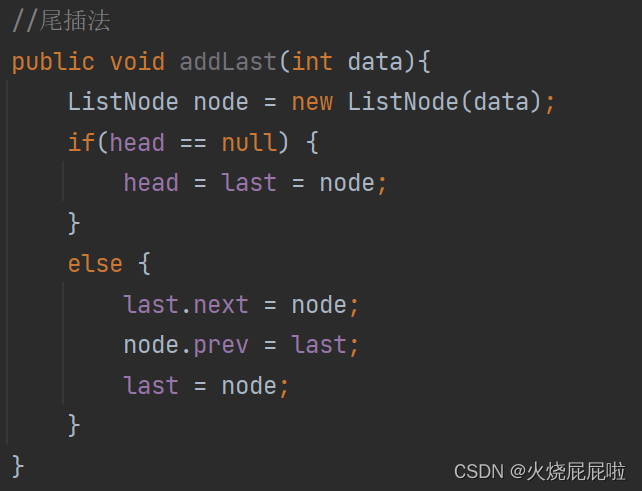
6,任意位置插入
现在不用在定义一个cur走到需要插入位置的前一个,因为现在的节点里面包含next和prev,直接走到所插入位置即可。
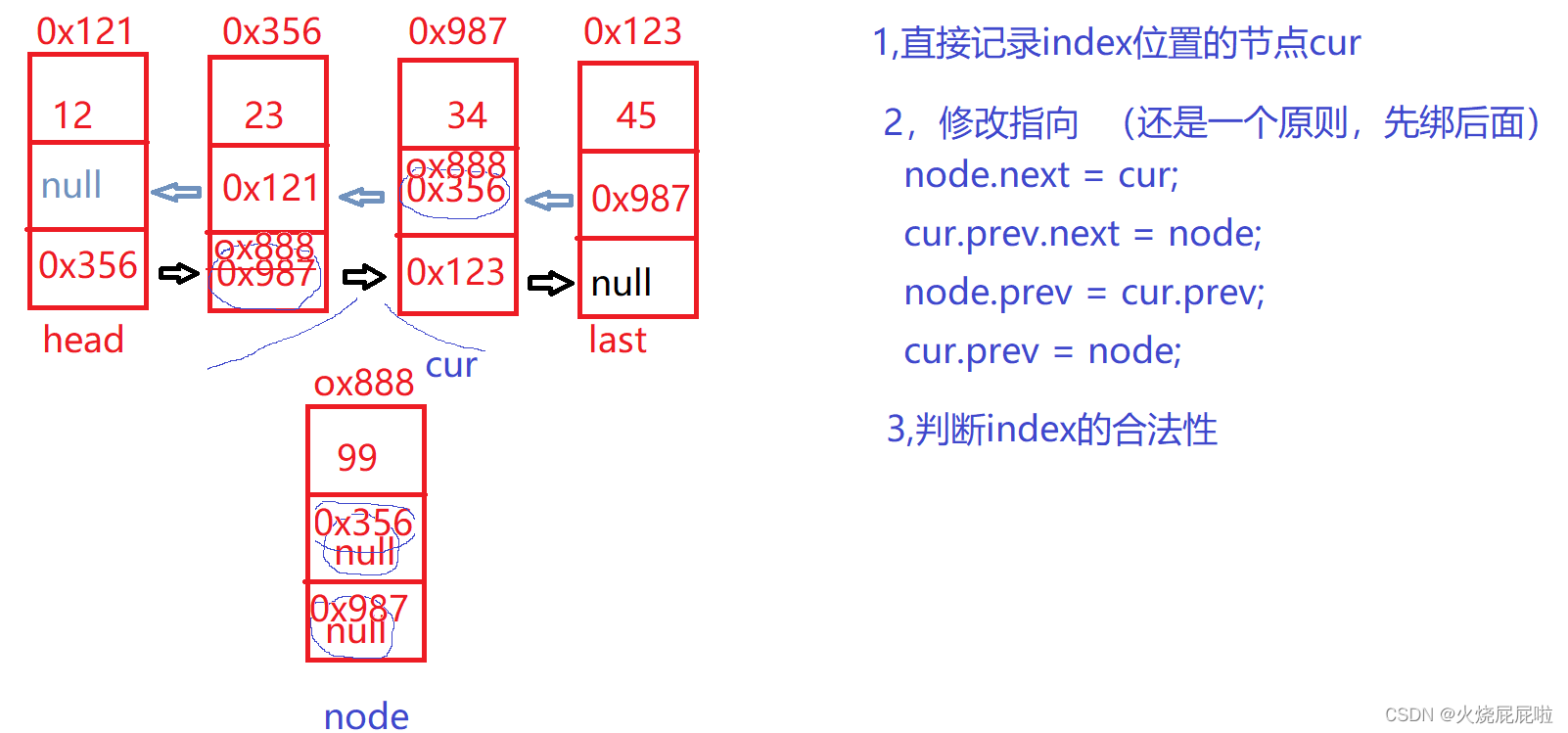
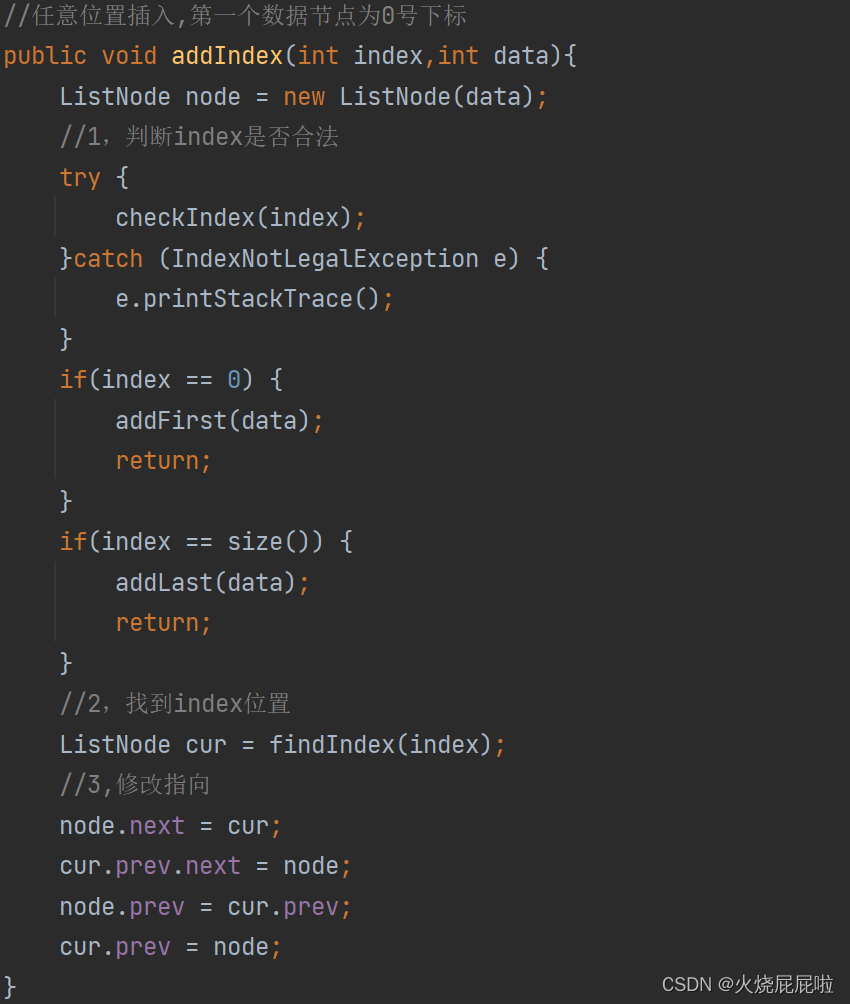
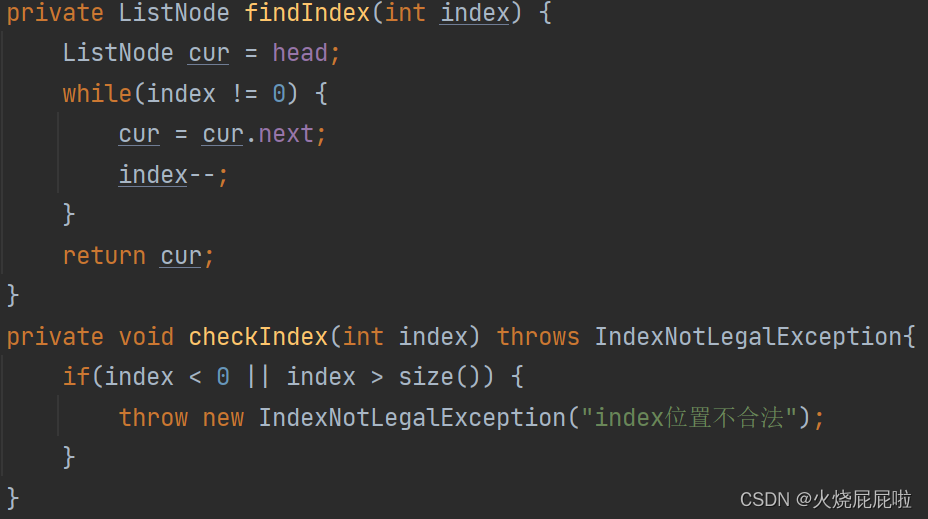
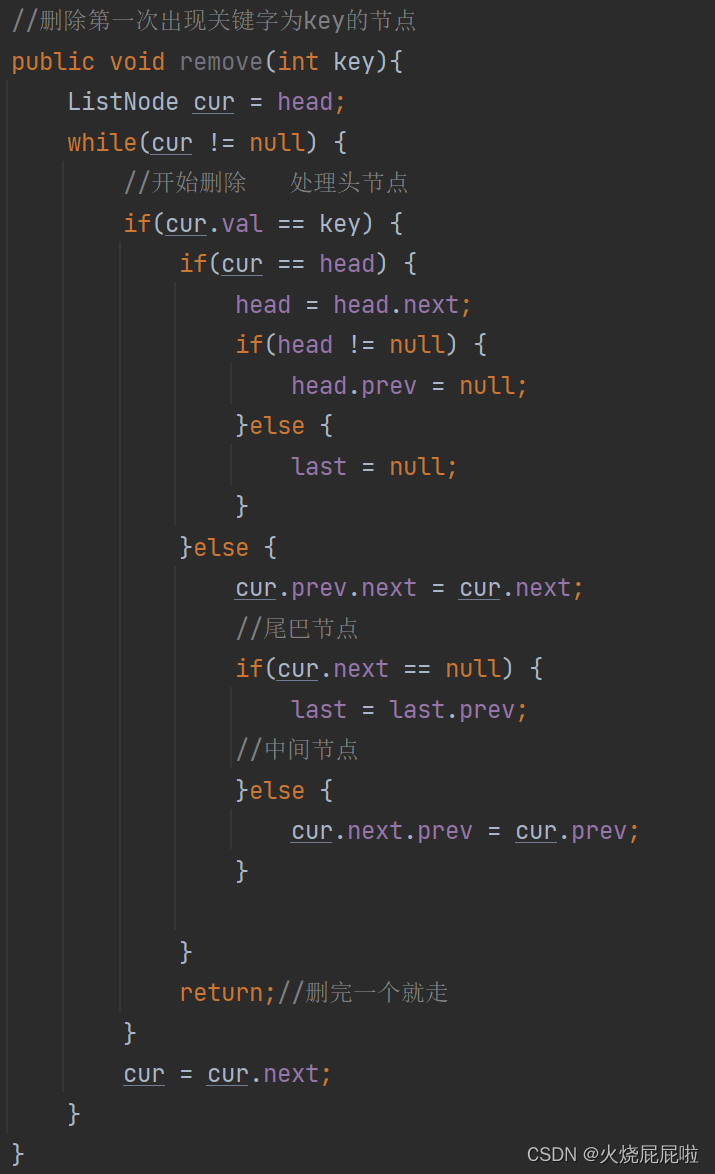
7,删除关键字key
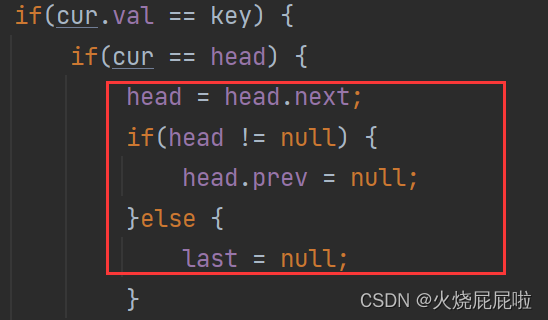
首先找到当前节点,只需要将cur的前一个节点的next等于cur的后一个节点,cur后一个节点的perv等于cur前的一个节点即可
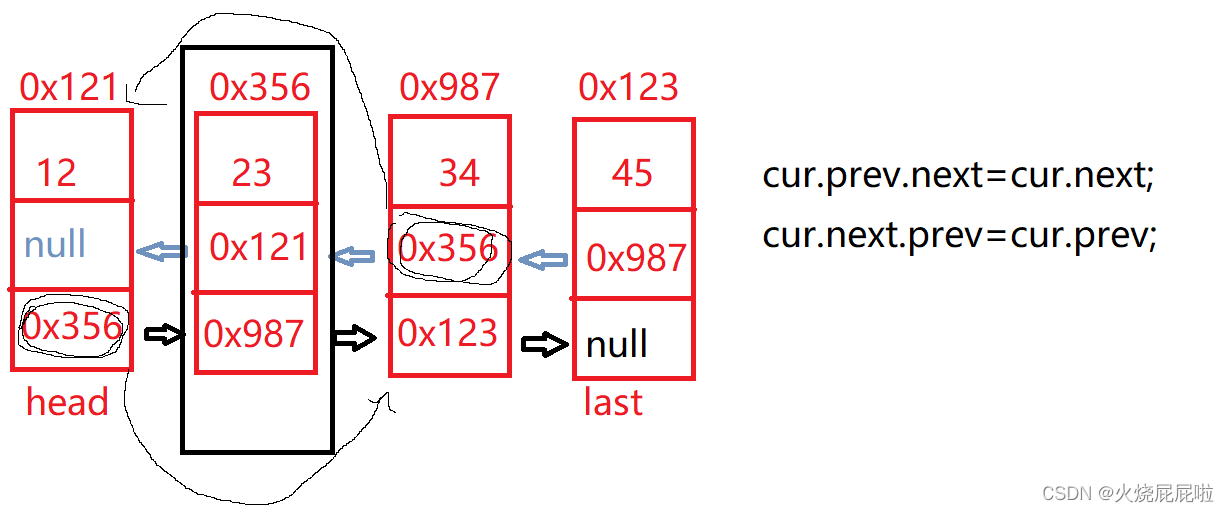

但是呢,这个代码是存在问题的。如果说我们在这要删除头节点12,if条件成立,走if里面的代码,发现cur.prev是null,会出现空指针异常。

那么我们在删除头节点时,只需要将head往后走,在将head的prev置为null即可。
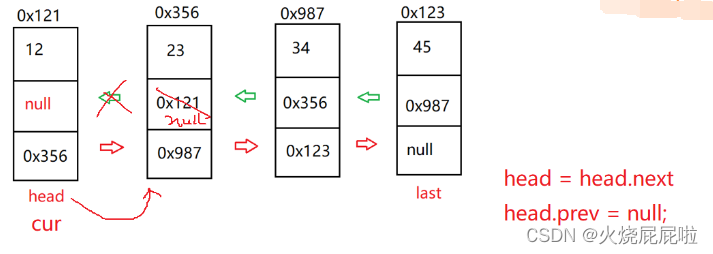
那么此时又会出现一个问题,如果说cur等于last(删除尾巴节点),上面else里面的代码,第一条是没有问题的,将cur的前驱的next置为null。
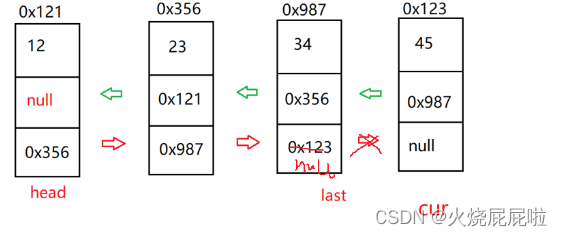
但是第二行代码就有问题,cur的next为空,空的前驱就会空指针异常。
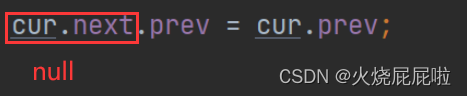
所以在这种情况下就可以不执行这条代码,让cur的前驱的next置为null以后,让last等于last的前驱即可!!!
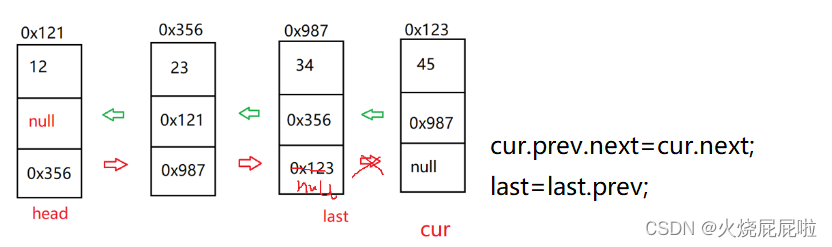

还有一个问题,当前链表只有一个节点!
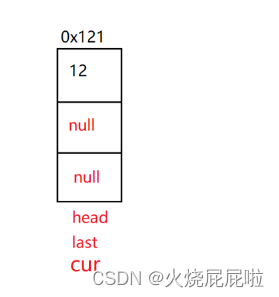
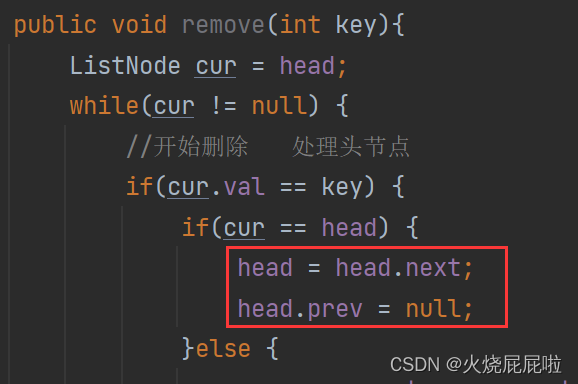
此时的代码对于当前链表是无法执行的,走到红色框框里面的时候,head的next为null,即head等于null,然后head的prev就会空指针异常!!!
所以如果只有一个节点的情况下,走到head = head.next 的时候(head为null),说明只有一个节点,让head的前驱置为null,否则让last置为null。
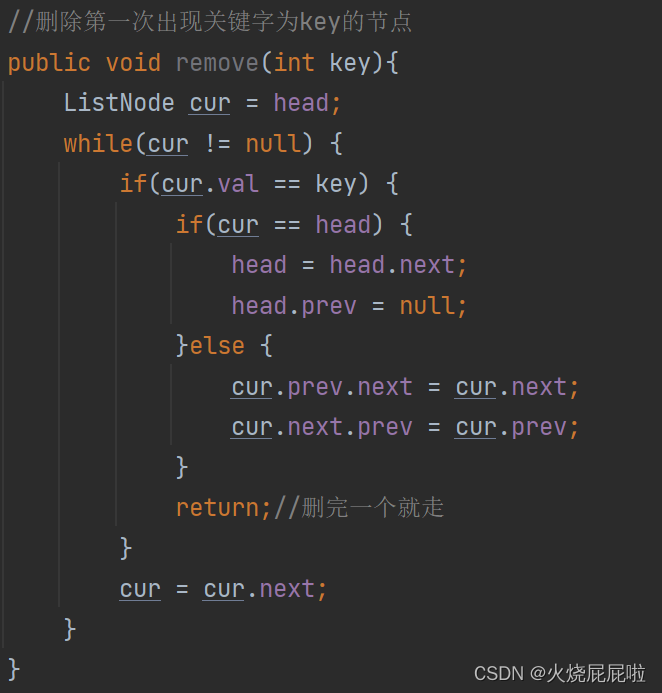
8,删除所有的值为key的节点
在remove方法中,我们删除一个节点以后直接return出去,我们只需要删完一个之后继续判断即可,不return出去!!!
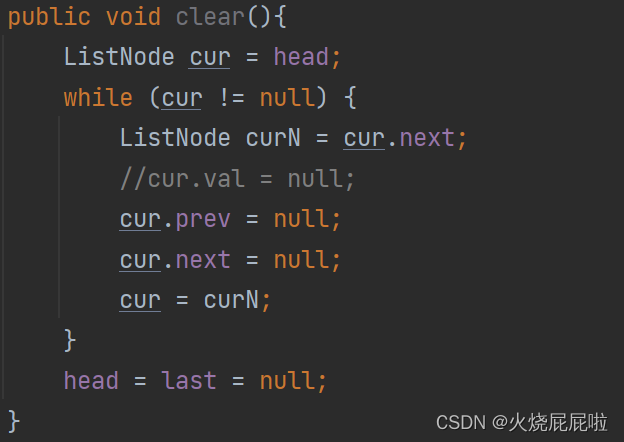
9,清空()回收每一个节点
方法一:直接将head和last置为null
方法二:将每一个节点的val,prev,next(假如都是引用类型)置为null,再将head和last置为null,因为把每一个节点置为null后,head和last都还引用着对应的节点
到此,我们自己实现了一个双向链表
4,LinkedList的使用
4.1 什么是LinkedList
LinkedList的底层是双向链表结构,由于链表没有将元素存储在连续的空间中,元素存储在单独的节点中,然后通过引用将节点连接起来了,因此在在任意位置插入或者删除元素时,不需要搬移元素,效率比较高。
【说明】:
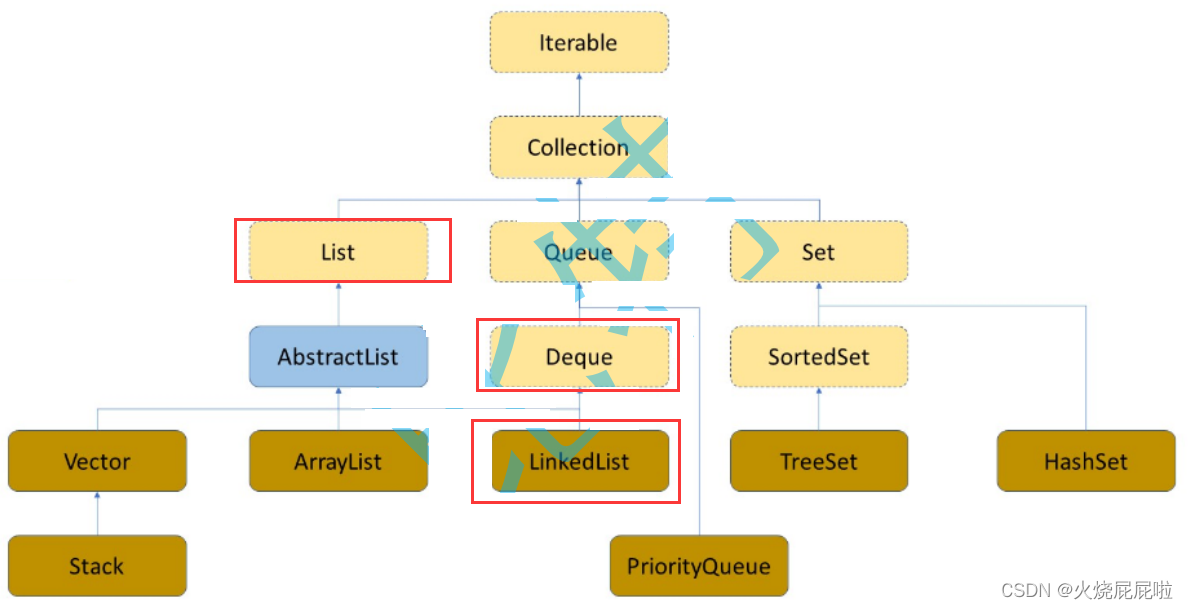
1. LinkedList实现了List接口
2. LinkedList的底层使用了双向链表
3. LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问
4. LinkedList的任意位置插入和删除元素时效率比较高,时间复杂度为O(1)
这里时间复杂度O(1)指的是删除的时候不需要移动元素,但是在找删除元素位置的时候,需要遍历链表,时间复杂度为O(N)。
5. LinkedList比较适合任意位置插入的场景
4.2 LinkedList的使用
写法:
进入LinkedList的源码:实现了这些接口


代表此时我们是以双向链表的形式去使用的
如果是Queue去引用LinkedList,是当作队列去使用(后序会讲的)
1,LinkedList的构造

带参数的构造方法:
在顺序表中讲过,这个?称为通配符,要么为E,要么为E的子类。这个E就是你当前List所指定的泛型类型
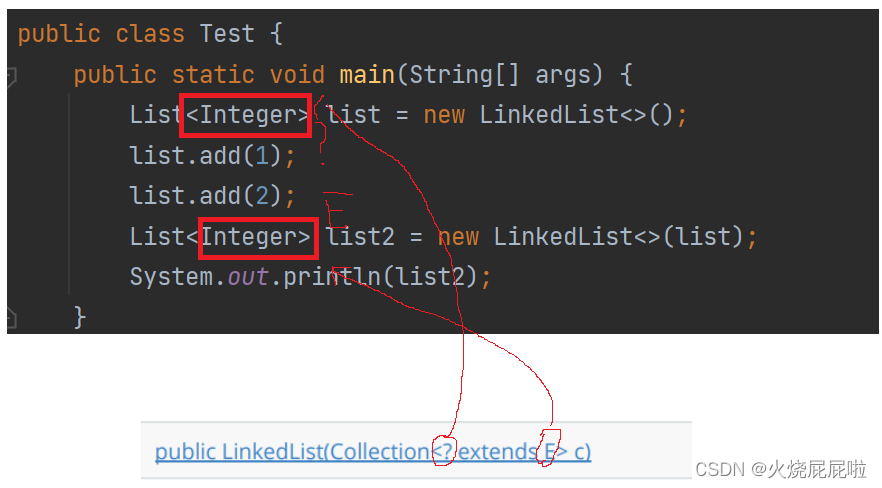
还可以用ArrayList来进行传递,因为ArrayList,LinkedList都实现了Collection接口

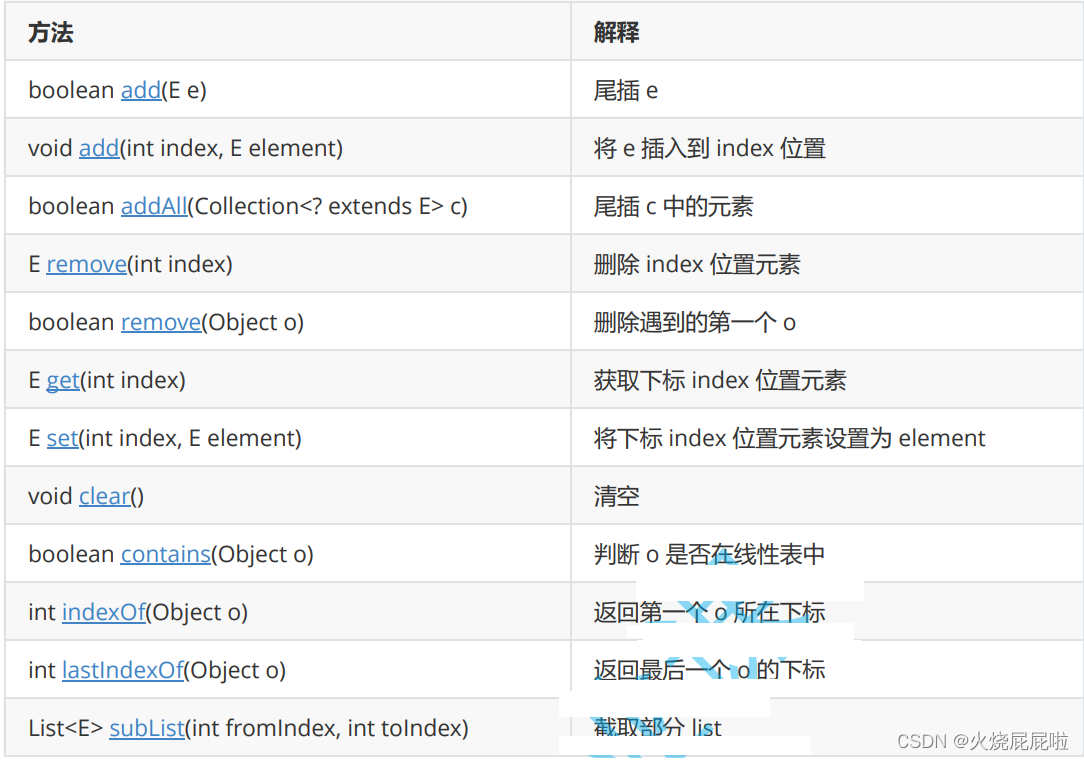
2. LinkedList的其他常用方法介绍
add:进入add的源码
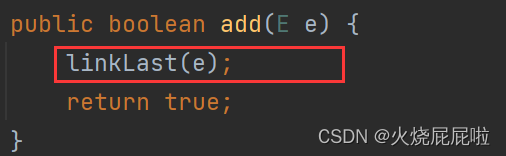
默认是一个尾插法
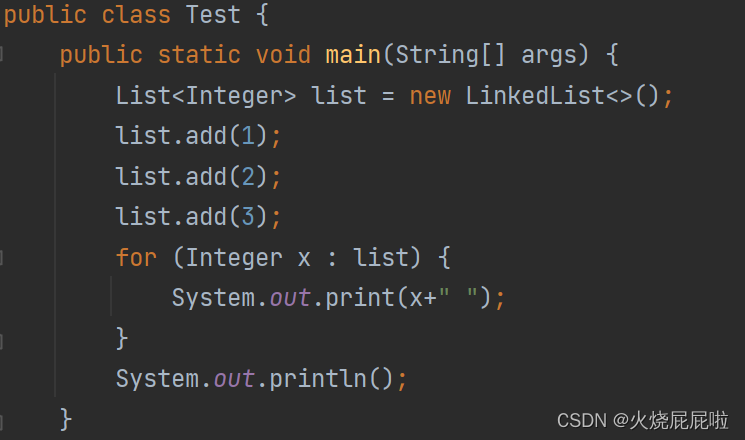
3,LinkedList的遍历
foreach循环:
for循环:
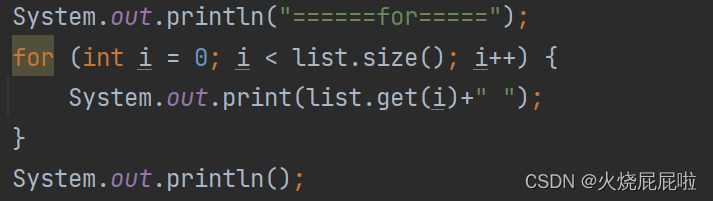
有一个问题:如果说是在此时打印一个删除一个,打印一个删除一个,会输出什么?
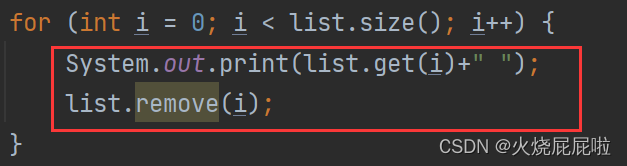
是不可以的,因为size一直在变化,把1打印之后,有删掉1,只剩下2和3两个元素,且size变成2了,再次打印的时候, i 等于1,就是打印3,即输出1和3。
如果把size变成一个固定的
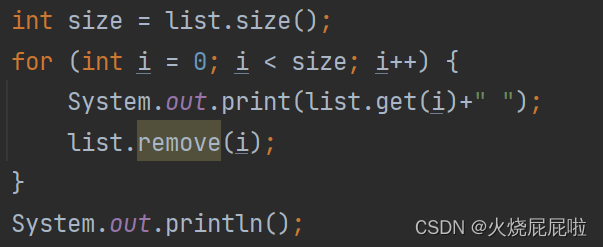
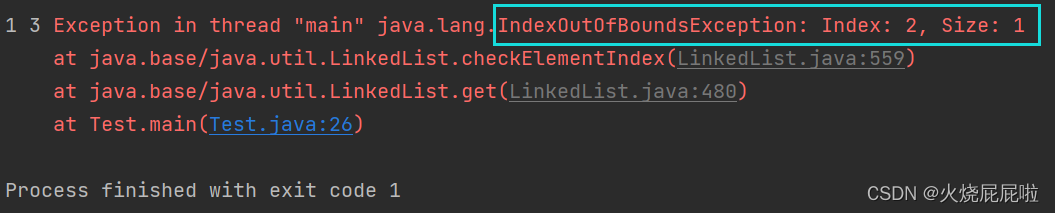
我们发现,出现了下标越界异常。
所以,一边遍历一遍删,必然会出现问题。当打印完0下标的元素时,删掉0下标的元素,0下标就会指向2元素位置,当 i 等于2时,要打印2下标的元素,此时就会下标越界!!!
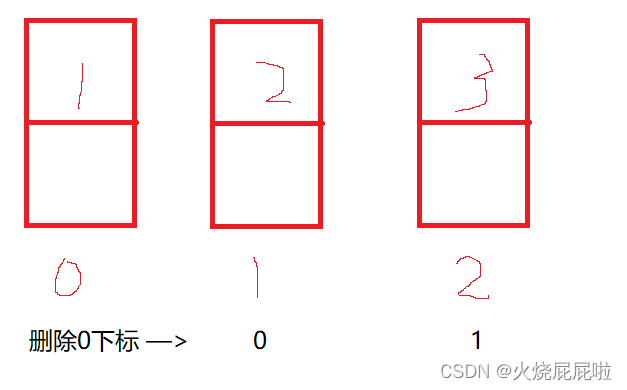
使用迭代器遍历:
iterator:
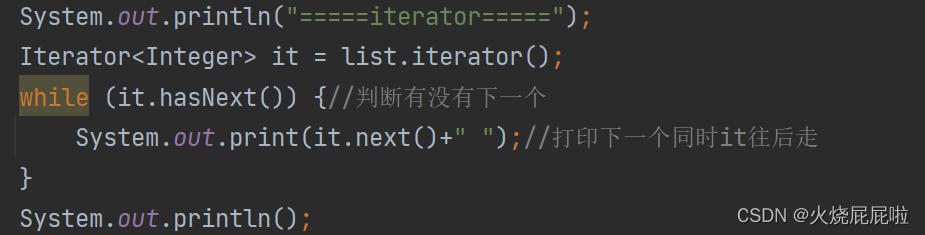
Listiterator:
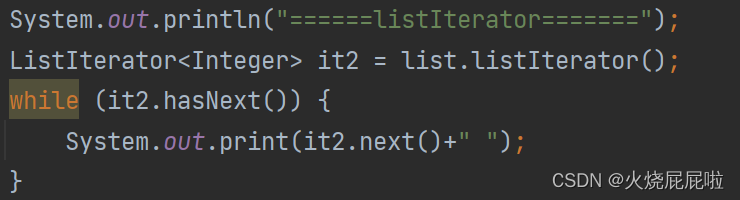

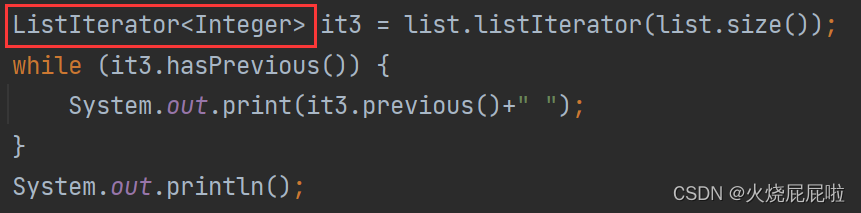
iterator和Listiterator没有区别,他们是父子关系,只是Listiterator可以倒着打印
Iterator是不具备Previous这个类的,要使用ListIterator
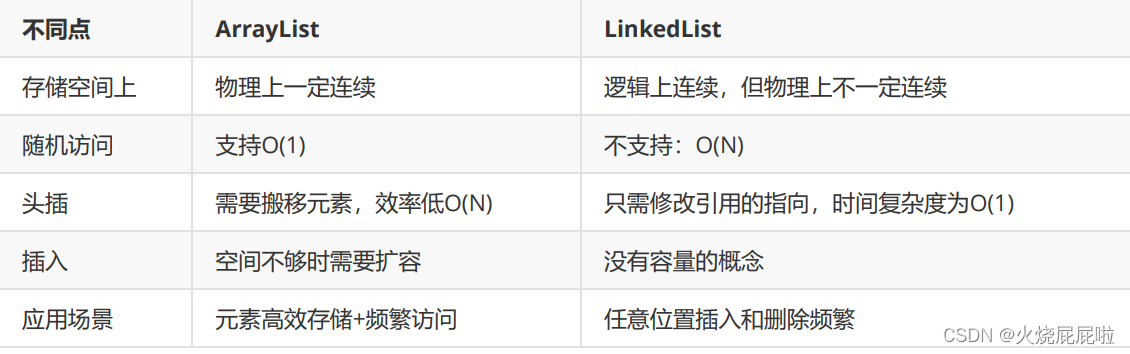
5,ArrayList和LinkedList的区别
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【LinkedList与链表】

发表评论 取消回复