DDP算法反向传播
在DDP(Differential Dynamic Programming)算法中,反向传播(Backward Pass)是关键步骤之一。这个步骤的主要目的是通过动态规划递归地计算每个时间步上的值函数和控制策略,以便在前向传播(Forward Pass)中使用。
反向传播的目标
反向传播的主要目标是通过线性二次近似计算值函数的梯度和Hessian矩阵,从而更新控制策略。具体步骤如下:
1. 初始化终端条件
从终端时间步 ?开始,初始化值函数 V?(x) 的梯度和Hessian矩阵:
其中,ϕ(x?) 是终端代价函数。
梯度和Hessian矩阵初始化为:
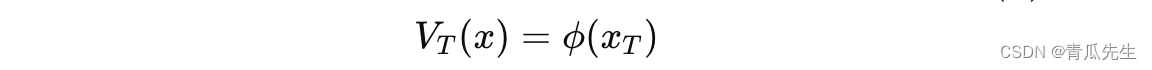
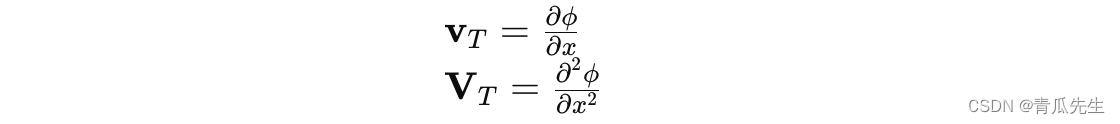
2. 递归计算值函数梯度和Hessian矩阵
对于每个时间步 ?(从 T−1 到 0),执行以下步骤:
2.1 计算当前步的Q函数
Q函数表示在给定当前状态和控制输入下的值函数。定义为:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » DDP算法之反向传播(Backward Pass)

发表评论 取消回复