python爬虫之异步爬虫之线程池的基本使用
高性能异步爬虫
目的:在爬虫中使用异步实现高性能的数据爬取操作。
异步爬虫的方式:
1、多线程,多进程(不建议):
好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步执行。
弊端:无法无限制的开启多线程或者多进程。
2、线程池、进程池(适当的使用):
好处:我们可以降低系统对进程或者线程创建和销毁的一个频率,从而很好的降低系统的开销。
弊端:池中进程或线程的数量是有上限的。
使用单线程串行方式执行代码和运行结果如下:
import time
#使用单线程串行方式执行
def get_page(str):
print("正在下载:",str)
time.sleep(2)
print("下载成功:",str)
name_list = ['xiaozi','aa','bb','cc']
start_time = time.time()
for i in range(len(name_list)):
get_page(name_list[i])
end_time = time.time()
print('%d second'%(end_time-start_time))
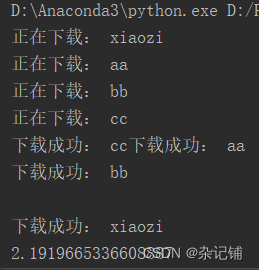
导入线程池模块执行代码和运行结果如下:

import time
#导入线程池模块对应的类
from multiprocessing.dummy import Pool
#使用线程池方式执行
start_time = time.time()
def get_page(str):
print("正在下载:",str)
time.sleep(2)
print("下载成功:",str)
name_list = ['xiaozi','aa','bb','cc']
#实例化一个线程池对象
pool = Pool(4)
#将列表中每一个列表元素传递给get_page进行处理
pool.map(get_page,name_list)
end_time = time.time()
print(end_time-start_time)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » python爬虫之异步爬虫之线程池的基本使用

发表评论 取消回复