Python学习从0开始——Kaggle计算机视觉001
一、卷积分类器
神经网络如何很好地“理解”自然图像以解决人类视觉系统可以解决的相同类型的问题,在这项任务中表现最好的神经网络被称为卷积神经网络(有时我们称之为convnet或CNN)。
卷积是一种数学运算,它赋予了convnet的各层独特的结构。
训练计算机可以从照片中识别植物种类的应用程序,就是一个图像分类器。
1.分类器
用于图像分类的卷积神经网络由两个部分组成:卷积基和密集头。
基库用于从图像中提取特征。它主要由执行卷积操作的层组成,但通常也包括其他类型的层。头部用于确定图像的类别。它主要由致密层组成,但可能包括其他层,如dropout。我们所说的视觉特征是什么意思?特征可以是一条线、一种颜色、一种纹理、一种形状、一种图案——或者是一些复杂的组合。
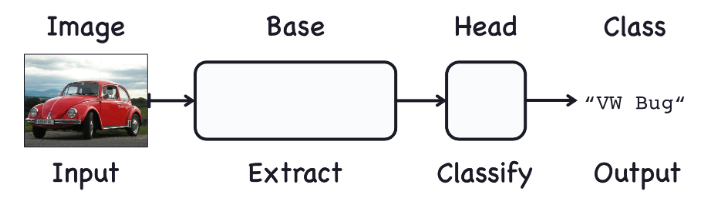
2.训练分类器
在训练过程中,网络的目标是学习两件事:从图像中提取哪些特征(基),哪个类与哪些特征(头)相匹配。如今,convnet很少接受从零开始的培训。更常见的是,我们重用预训练模型的基础。在预训练的基座上,我们接一个未经训练的头部。换句话说,我们重用了网络中已经学会做1的部分来提取特征,然后添加一些新的图层来学习2分类。
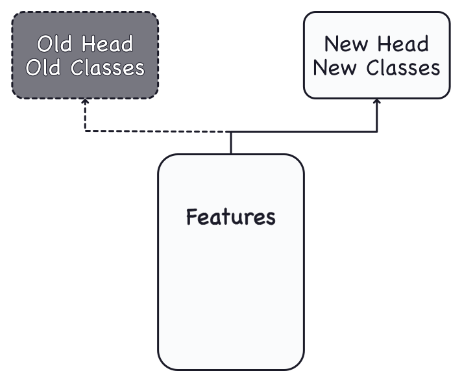
因为头部通常只由几个密集的层组成,所以可以从相对较少的数据中创建非常准确的分类器。
重用预训练模型是一种称为迁移学习的技术。它非常有效,现在几乎所有的图像分类器都会使用它。
3.使用
定义管道:
# Imports
import os, warnings
import matplotlib.pyplot as plt
from matplotlib import gridspec
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# Reproducability
def set_seed(seed=31415):
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
set_seed(31415)
# 设置Matplotlib默认值
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # 清理输出单元格
# 加载训练和验证集
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# Data Pipeline
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
最常用的预训练数据集是ImageNet,这是一个包含多种自然图像的大型数据集。Keras在其应用程序模块中包括在ImageNet上预训练的各种模型。我们将使用的预训练模型称为VGG16。
定义预训练库:
pretrained_base = tf.keras.models.load_model(
'../input/cv-course-models/cv-course-models/vgg16-pretrained-base',
)
pretrained_base.trainable = False
接下来,连接分类器头部,本例使用隐藏单元层(第一个Dense层),然后使用另一个层将输出转换为类别1 Truck的概率分数。Flatten层将基座的二维输出转换为头部所需的一维输入。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
pretrained_base,
layers.Flatten(),
layers.Dense(6, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
最后,训练模型。由于这是一个二分类问题,我们将使用crossentropy 和 accuracy的二进制版本。adam优化器通常表现良好,所以选择它。
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=30,
verbose=0,
)
在训练神经网络时,检查损失图和度量图。历史对象在字典history.history中包含这些信息。我们可以使用Pandas将该字典转换为数据框,并使用内置方法绘制。
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();
二、卷积和RELU
1.特征提取
三个操作:
- 过滤图像的特定特征(卷积)
- 在过滤图像(ReLU)中检测该特征
- 压缩图像以增强特征(最大池化)

2.带卷积的过滤器定义
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
# More layers follow
])
在训练过程中,卷积神经网络学习到的权重主要包含在卷积层中。这些权重我们称之为“核”(kernels),可以将它们表示为小数组。内核通过扫描图像并产生像素值的加权和来操作。通过这种方式,内核就像一个偏光透镜,强调或弱化某些信息模式。
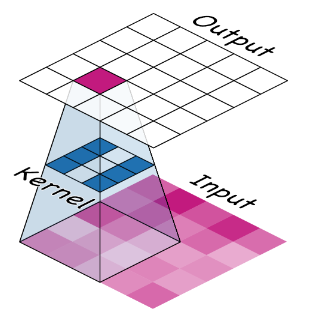
核定义了卷积层如何连接到后面的层。上面的核将输出中的每个神经元连接到输入中的九个神经元。通过使用kernel_size设置内核的维度,可以设置convnet如何形成这些连接。大多数情况下,内核的维数为奇数——比如kernel_size=(3,3)或(5,5)——这样单个像素就会位于中心,但这不是必需的。卷积层中的核决定了它创建的特征类型。在训练过程中,convnet试图学习解决分类问题所需要的特征。这意味着找到它的核的最佳值。
3.激活:
网络中的激活我们称之为特征映射。它们是当我们对图像应用过滤器时产生的结果;它们包含内核提取的视觉特征。下面是一些内核和他们制作的特征图。
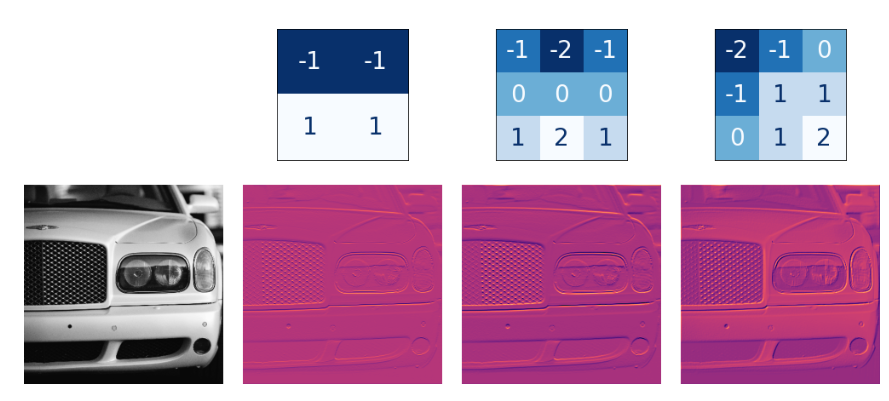
从内核中的数字模式中,你可以知道它创建的特征映射的类型。一般来说,卷积在其输入中强调的内容将与核中的正数的形状相匹配。上面左边和中间的核都将过滤水平形状。使用filters参数设置卷积层创建多少个特征映射作为输出。
4.用ReLU检测
特征映射经过过滤后,通过激活函数。带有整流器的神经元称为整流线性单元。因此也将整流函数称为ReLU激活,ReLU函数。ReLU激活可以在它自己的激活层中定义,但多数情况下,只将它作为Conv2D的激活函数包含进去。
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3, activation='relu')
# More layers follow
])
ReLU激活表示负值不重要,因此将它们设置为0。与其他激活函数一样,ReLU函数也是非线性的。从本质上讲,这意味着网络中所有层的总效果与你仅仅将效果加在一起所得到的效果是不同的——这与你只使用一个层所获得的效果是一样的。非线性确保了特征会以有趣的方式结合在一起,随着它们深入到网络中。
5.使用
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
image_path = '../input/computer-vision-resources/car_feature.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image)
#原图
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image), cmap='gray')
plt.axis('off')
plt.show();
#定义kernel
kernel = tf.constant([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
])
plt.figure(figsize=(3, 3))
#kernel数组
show_kernel(kernel)
#过滤器
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
strides=1,
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_filter))
plt.axis('off')
plt.show();
#ReLU检测
image_detect = tf.nn.relu(image_filter)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.show();
三、最大池化
1.最大池压缩
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
layers.MaxPool2D(pool_size=2),
# More layers follow
])
MaxPool2D层与Conv2D层非常相似,除了它使用简单的maximum函数而不是kernel,其pool_size参数类似于kernel_size。然而,MaxPool2D层在其kernel中不像卷积层那样具有任何可训练的权重。
在应用ReLU函数(Detect)之后,特征映射最终会产生大量的“死区”,即只包含0的大块区域(图像中的黑色区域)。在整个网络中携带这些0个激活会增加模型的大小,而不会增加很多有用的信息。相反,我们想要压缩特征映射,只保留最有用的部分——特征本身。
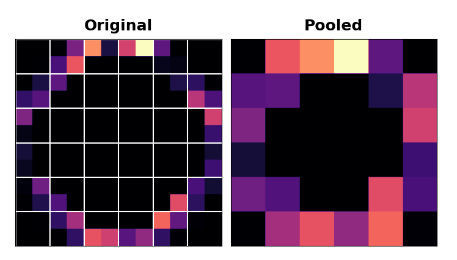
这实际上就是最大池化所做的。最大池取原始特征映射中的一个激活补丁,并用该补丁中的最大激活替换它们。在ReLU激活后使用,具有“强化”功能的效果。池化步骤将活动像素的比例增加到零像素。
2.使用
#接二、卷积和ReLU的使用代码
import tensorflow as tf
image_condense = tf.nn.pool(
input=image_detect, # 图像在上面的检测步骤
window_shape=(2, 2),
pooling_type='MAX',
strides=(2, 2),
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_condense))
plt.axis('off')
plt.show();
3.平移不变性
我们称零像素为“不重要”。这是否意味着它们根本不携带任何信息?事实上,零像素携带位置信息。空白仍然将特征定位在图像中。当MaxPool2D删除其中一些像素时,它会删除特征映射中的一些位置信息。这给了一个convnet一个叫做平移不变性的属性。这意味着具有最大池化的convnet将倾向于不通过图像中的位置来区分特征。(“平移”是在不旋转或改变物体形状或大小的情况下改变物体的位置。)
对下面的特性映射重复应用最大池化:

经过多次池化,原始图像中的两个点变得无法区分。换句话说,池化破坏了它们的一些位置信息。由于网络不再能够在特征映射中区分它们,它也不能在原始图像中区分它们:它对位置的差异变得不变性。实际上,池化只在网络中创建小距离的平移不变性,就像图像中的两个点一样。开始时相距很远的特征在池化之后仍然明显;只有部分位置信息丢失了,但不是全部。
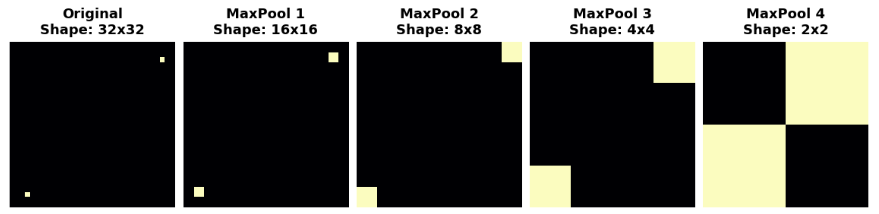
对于图像分类器来说,这种对特征位置微小差异的不变性是一个很好的属性。仅仅因为视角或框架的不同,相同的特征可能会被定位在原始图像的不同部分,但我们仍然希望分类器能够识别出它们是相同的。因为这种不变性是内置在网络中的,我们可以使用更少的数据进行训练:我们不再需要教它忽略这种差异。这使得卷积网络比只有密集层的网络具有很大的效率优势。
四、滑动窗口
1.介绍
卷积和池化操作有一个共同的特点:它们都是在滑动窗口上执行的。对于卷积,这个“窗口”是由内核的维度,参数kernel_size给出的。对于池化,它是池化窗口,由pool_size给出。
还有两个额外的参数会影响卷积层和池化层——它们是窗口的步长和是否在图像边缘使用填充。strides参数表示在每一步中窗口应该移动多远,padding参数描述我们如何处理输入边缘的像素。
有了这两个参数,定义这两个层就变成了:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64,
kernel_size=3,
strides=1,
padding='same',
activation='relu'),
layers.MaxPool2D(pool_size=2,
strides=1,
padding='same')
# More layers follow
])
2.步长
窗口在每一步移动的距离被称为步长(stride)。我们需要在图像的两个维度上指定步长:一个用于从左到右的移动,另一个用于从上到下的移动。
当步长在任一方向上大于1时,滑动窗口将在每一步跳过输入中的某些像素。因为我们想要使用高质量的特征来进行分类,卷积层通常会有步长(strides)为(1, 1)。增加步长意味着我们在总结时会错过一些可能有价值的信息。然而,最大池化层(Max Pooling layers)几乎总是会有大于1的步长值,如(2, 2)或(3, 3),但不会大于窗口本身。
最后,请注意,当步长在两个方向上的值相同时,你只需要设置那个数字;例如,代替strides=(2, 2),你可以在参数设置中使用strides=2。
3.边界
在进行滑动窗口计算时,有一个问题是关于在输入边界处如何处理。完全保持在输入图像内部意味着窗口永远不会像输入中的其他像素那样正好覆盖这些边界像素。既然我们没有将所有像素完全平等地处理,那么会不会有问题?
卷积如何处理这些边界值是由其填充参数(padding parameter)决定的。在TensorFlow中,你有两个选择:要么设置padding=‘same’,要么设置padding=‘valid’。每种方式都有其利弊。
当我们设置padding='valid’时,卷积窗口将完全保持在输入内部。缺点是输出会缩小(失去像素),而且内核越大,输出缩小得越多。这将限制网络可以包含的层数,尤其是当输入尺寸较小时。
另一种选择是使用padding=‘same’。这里的技巧是在输入的边界周围填充0,只填充足够的0以使输出的尺寸与输入的尺寸相同。然而,这可能会削弱边界像素的影响。
4.使用
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
image = circle([64, 64], val=1.0, r_shrink=3)
image = tf.reshape(image, [*image.shape, 1])
# kernel
kernel = tf.constant(
[[-1, -2, -1],
[0, 0, 0],
[1, 2, 1]],
)
show_kernel(kernel)
show_extraction(
image, kernel,
# 窗口参数,步长1
conv_stride=1,
pool_size=2,
pool_stride=2,
subplot_shape=(1, 4),
figsize=(14, 6),
)
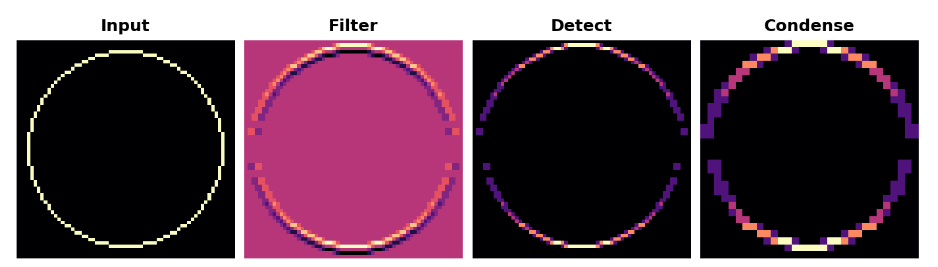
show_extraction(
image, kernel,
# 步长3
conv_stride=3,
pool_size=2,
pool_stride=2,
subplot_shape=(1, 4),
figsize=(14, 6),
)
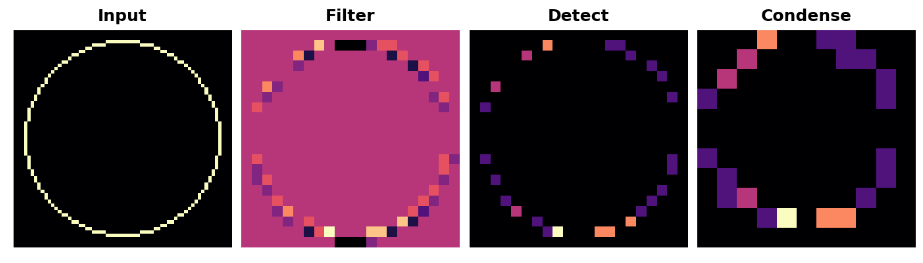
这似乎降低了特征提取的质量。我们的输入圈非常“精细”,只有1像素宽。步长为3的卷积过于粗糙,无法从中生成良好的特征图。有时,模型将在其初始层中使用具有较大步幅的卷积。这通常还需要一个更大的内核。
五、自定义Convnet
1.由浅到深
卷积网络通过三种操作来执行特征提取:过滤、检测和压缩。单轮特征提取只能从图像中提取相对简单的特征,比如简单的线条或对比。这些方法太简单,无法解决大多数分类问题。相反,convnets会一遍又一遍地重复这种提取,因此,随着特征在网络中的深入,它们变得更加复杂和精细。
2.卷积块
卷积神经网络通过将它们传递给一长串的卷积块来实现这种特征提取。这些卷积块是Conv2D和MaxPool2D层的堆叠,每个块代表一轮特征提取,通过组合这些块,卷积神经网络可以组合和重新组合产生的特征,使它们增长并适应当前的问题。现代卷积神经网络的深层结构使得这种复杂的特征工程得以实现,并在很大程度上决定了它们优越的性能。
3.设计
# Imports
import os, warnings
import matplotlib.pyplot as plt
from matplotlib import gridspec
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# 复用函数
def set_seed(seed=31415):
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
set_seed()
# 设置Matplotlib默认值
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# 加载训练和验证集
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# 数据管道
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
现在定义模型,看看模型是如何由Conv2D和MaxPool2D层(基础)的三个块组成的,然后是密集层的头部。我们可以通过填充适当的参数或多或少直接将这个图转换为Keras Sequential模型。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# 第一个卷积块
layers.Conv2D(filters=32, kernel_size=5, activation="relu", padding='same',
# give the input dimensions in the first layer
# [height, width, color channels(RGB)]
input_shape=[128, 128, 3]),
layers.MaxPool2D(),
# 第二个卷积块
layers.Conv2D(filters=64, kernel_size=3, activation="relu", padding='same'),
layers.MaxPool2D(),
# 第三个卷积块
layers.Conv2D(filters=128, kernel_size=3, activation="relu", padding='same'),
layers.MaxPool2D(),
# 分类器头
layers.Flatten(),
layers.Dense(units=6, activation="relu"),
layers.Dense(units=1, activation="sigmoid"),
])
model.summary()
注意,在这个定义中,过滤器的数量是如何逐块加倍的:32,64,128。这是一种常见的模式。由于MaxPool2D层减少了特征映射的大小,我们得以增加创建的数量。
#训练
model.compile(
optimizer=tf.keras.optimizers.Adam(epsilon=0.01),
loss='binary_crossentropy',
metrics=['binary_accuracy']
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=40,
verbose=0,
)
#生成图像
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();
六、数据增强
1.假数据的有用性
提高机器学习模型性能的最好方法是在更多的数据上训练它。模型需要学习的例子越多,它就越能识别出图像中哪些差异是重要的,哪些是不重要的。更多的数据有助于模型更好地泛化。获取更多数据的一个简单方法是使用你已经拥有的数据。如果我们可以以保留类的方式转换数据集中的图像,我们可以教分类器忽略这些类型的转换。例如,无论一辆车在照片中是朝左还是朝右,都不会改变它是一辆车而不是一辆卡车的事实。因此,如果我们用翻转的图像来增强训练数据,我们的分类器将学习到“左或右”是一个应该忽略的差异。这就是数据增强背后的整个思想:添加一些看起来很像真实数据的额外假数据,分类器就会得到改进。
2.使用数据增强
通常,在扩充数据集时会使用多种转换。这些可能包括旋转图像,调整颜色或对比度,扭曲图像或许多其他事情,通常组合应用。下面是一张图片可能被变换的不同方式的例子:

数据增强通常是在线完成的,也就是说,当图像被输入网络进行训练时。回想一下,训练通常是在小批量数据上完成的。这是使用数据增强时一批16张图像的样子:

每次在训练中使用图像时,应用一个新的随机变换。通过这种方式,模型总是看到一些与之前不同的东西。训练数据中的这种额外方差有助于模型处理新数据。重要的是要记住,并不是每个转换都对给定的问题有用。最重要的是,无论使用什么转换,都不应该混淆这些类。
3.使用
Keras允许两种方式扩展数据。第一种方法是使用ImageDataGenerator之类的函数将其包含在数据管道中。第二种方法是通过使用Keras的预处理层将其包含在模型定义中。这就是我们要采取的方法。对我们来说,主要的优势是图像转换将在GPU而不是CPU上计算,这可能会加快训练速度。
下面通过数据增强来改进一中的分类器。
# Imports
import os, warnings
import matplotlib.pyplot as plt
from matplotlib import gridspec
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
def set_seed(seed=31415):
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#os.environ['TF_DETERMINISTIC_OPS'] = '1'
set_seed()
# 参数
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# 加载数据集和验证集
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# 管道
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
定义模型:
from tensorflow import keras
from tensorflow.keras import layers
# 这是TF 2.2中的一个新特性
from tensorflow.keras.layers.experimental import preprocessing
pretrained_base = tf.keras.models.load_model(
'../input/cv-course-models/cv-course-models/vgg16-pretrained-base',
)
pretrained_base.trainable = False
model = keras.Sequential([
# 预处理
preprocessing.RandomFlip('horizontal'), # 左右翻转
preprocessing.RandomContrast(0.5), # 对比度变化50%
pretrained_base,
# 头部
layers.Flatten(),
layers.Dense(6, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
测试评估:
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=30,
verbose=0,
)
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();
该模型的学习曲线能够保持在一起,并且我们在验证损失和准确性方面取得了一些适度的改进。这表明数据集确实从增强中受益。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python学习从0开始——Kaggle计算机视觉001

发表评论 取消回复