
欢迎来到技术探索的奇幻世界
个人主页:@一伦明悦-CSDN博客
作者简介: C++软件开发、Python机器学习爱好者
️ 互动与支持:评论 点赞 收藏 关注+
如果文章有所帮助,欢迎留下您宝贵的评论,
点赞加收藏支持我,点击关注,一起进步!
引言
线性回归和支持向量机(SVM)是常见的机器学习算法,用于回归和分类任务。以下是它们的介绍与区别:
线性回归(Linear Regression):
介绍:
- 线性回归是一种用于建立输入特征与连续输出之间关系的线性模型。
- 通过拟合一个线性函数来预测目标变量的数值。
- 目标是找到使模型预测值与实际值之间误差的平方和最小化的最优参数。
特点:
- 简单且直观,易于理解和实现。
- 适用于连续数值预测任务。
- 可以考虑多个特征对目标变量的影响。
适用场景:
- 预测房价、销售量等连续值问题。
- 理解特征对目标变量的影响。
支持向量机(Support Vector Machine,SVM):
介绍:
- SVM是一种用于分类和回归的监督学习算法。
- 在特征空间中找到一个最优的超平面来分隔不同类别的样本。
- 可以通过核技巧处理非线性分类任务。
特点:
- 适用于小样本、高维度的数据集。
- 具有较好的泛化能力,适用于解决非线性可分问题。
- 引入核函数可扩展到处理复杂数据集。
适用场景:
- 二分类、多分类问题。
- 处理非线性分类问题。
- 图像识别、文本分类等领域。
区别:
目标:
- 线性回归旨在建立输入特征与连续输出之间的线性关系。
- SVM旨在找到一个最优的超平面来分隔不同类别的样本。
任务:
- 线性回归解决的是回归问题,预测连续数值。
- SVM可用于分类和回归任务,主要应用于分类问题。
拟合方式:
- 线性回归通过拟合直线或超平面来逼近数据。
- SVM通过寻找间隔最大化的超平面来分隔不同类别的样本。
处理非线性问题:
- 线性回归适用于线性关系,不擅长处理非线性数据。
- SVM可以通过核技巧处理非线性分类问题。
正文
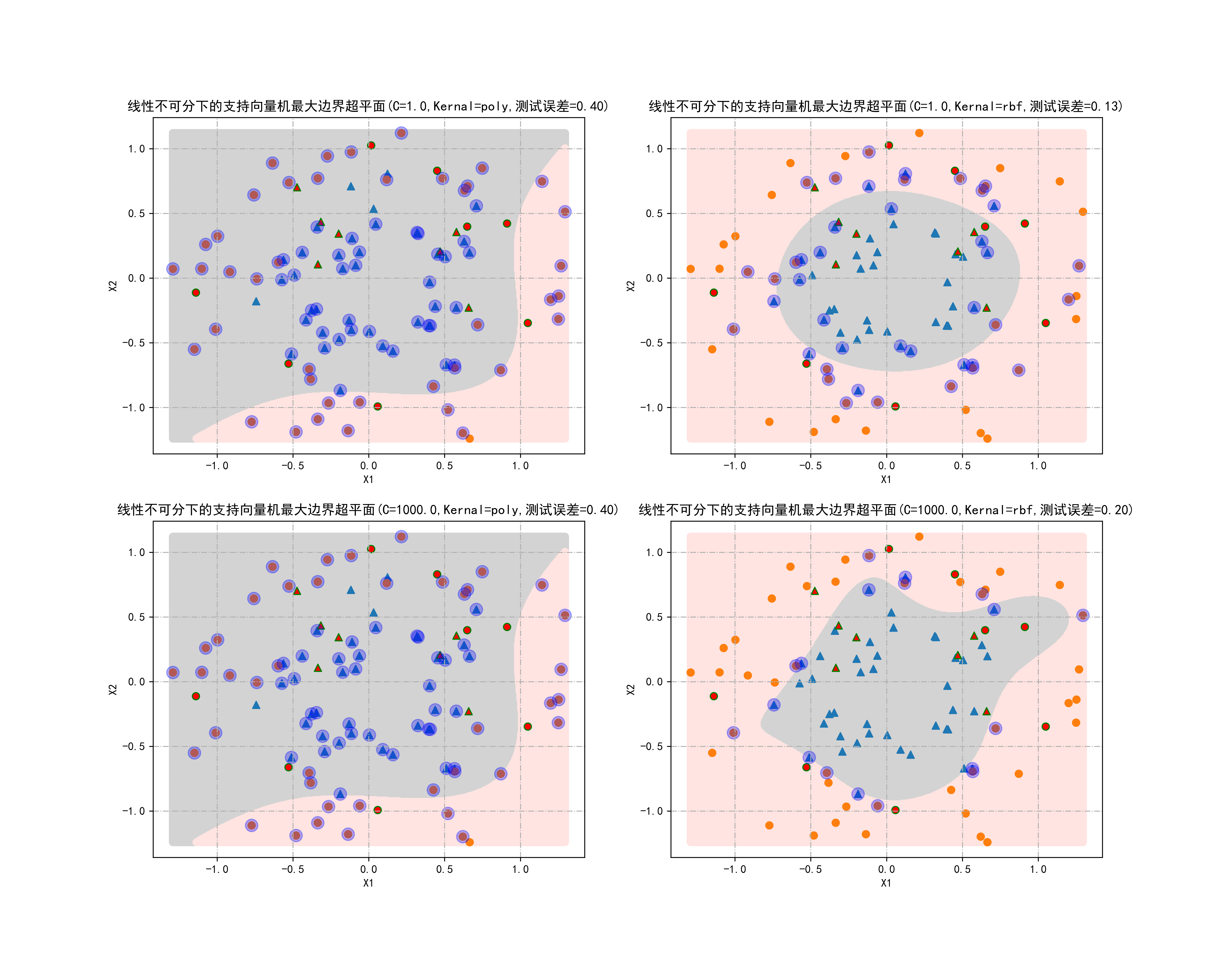
01-线性不可分下的支持向量机最大边界超平面
这段代码是用于生成和绘制一个支持向量机(SVM)模型的图示。它使用scikit-learn库中的
make_circles函数生成了一个具有两个特征的数据集,该数据集由两个同心圆组成,这代表了两个类别。然后,它将数据集分为训练集和测试集,并使用支持向量机模型进行训练和预测。最后,它绘制了训练集、测试集、支持向量以及模型决策边界的图示。下面是这段代码的详细解释:
- 导入必要的模块:
%matplotlib inline import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import numpy as np from sklearn.datasets import make_circles from sklearn.model_selection import train_test_split from sklearn import svm
- 生成数据集:
N = 100 X, Y = make_circles(n_samples=N, noise=0.2, factor=0.5, random_state=123)
make_circles函数生成了一个具有两个特征的数据集,其中包含两个同心圆,代表两个类别。noise参数用于控制圆上的点与圆中心的距离,factor参数用于控制两个圆之间的距离。
- 划分训练集和测试集:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.85, random_state=1)
train_test_split函数将数据集分为85%的训练集和15%的测试集。
- 创建网格以展示决策边界:
X1, X2 = np.meshgrid(np.linspace(X_train[:, 0].min(), X_train[:, 0].max(), 500), np.linspace(X_train[:, 1].min(), X_train[:, 1].max(), 500)) X0 = np.hstack((X1.reshape(len(X1) * len(X))))
#本章需导入的模块
import numpy as np
from numpy import random
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.model_selection import train_test_split,KFold
import sklearn.neural_network as net
import sklearn.linear_model as LM
from scipy.stats import multivariate_normal
from sklearn.metrics import r2_score,mean_squared_error,classification_report
from sklearn import svm
import os
N=100
X,Y=make_circles(n_samples=N,noise=0.2,factor=0.5,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.85, random_state=1)
X1,X2= np.meshgrid(np.linspace(X_train[:,0].min(),X_train[:,0].max(),500),np.linspace(X_train[:,1].min(),X_train[:,1].max(),500))
X0=np.hstack((X1.reshape(len(X1)*len(X2),1),X2.reshape(len(X1)*len(X2),1)))
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(15,12))
for C,ker,H,L in [(1,'poly',0,0),(1,'rbf',0,1),(1000,'poly',1,0),(1000,'rbf',1,1)]:
modelSVC=svm.SVC(kernel=ker,random_state=123,C=C)
modelSVC.fit(X_train,Y_train)
Y0=modelSVC.predict(X0)
axes[H,L].scatter(X0[np.where(Y0==1),0],X0[np.where(Y0==1),1],c='lightgray')
axes[H,L].scatter(X0[np.where(Y0==0),0],X0[np.where(Y0==0),1],c='mistyrose')
for k,m in [(1,'^'),(0,'o')]:
axes[H,L].scatter(X_train[Y_train==k,0],X_train[Y_train==k,1],marker=m,s=40)
axes[H,L].scatter(X_test[Y_test==k,0],X_test[Y_test==k,1],marker=m,s=40,c='r',edgecolors='g')
axes[H,L].scatter(modelSVC.support_vectors_[:,0],modelSVC.support_vectors_[:,1],marker='o',c='b',s=120,alpha=0.3)
axes[H,L].set_xlabel("X1")
axes[H,L].set_ylabel("X2")
axes[H,L].set_title("线性不可分下的支持向量机最大边界超平面(C=%.1f,Kernal=%s,测试误差=%.2f)"%(C,ker,1-modelSVC.score(X_test,Y_test)))
axes[H,L].grid(True,linestyle='-.')
plt.savefig("../4.png", dpi=500) 运行结果如下图所示:
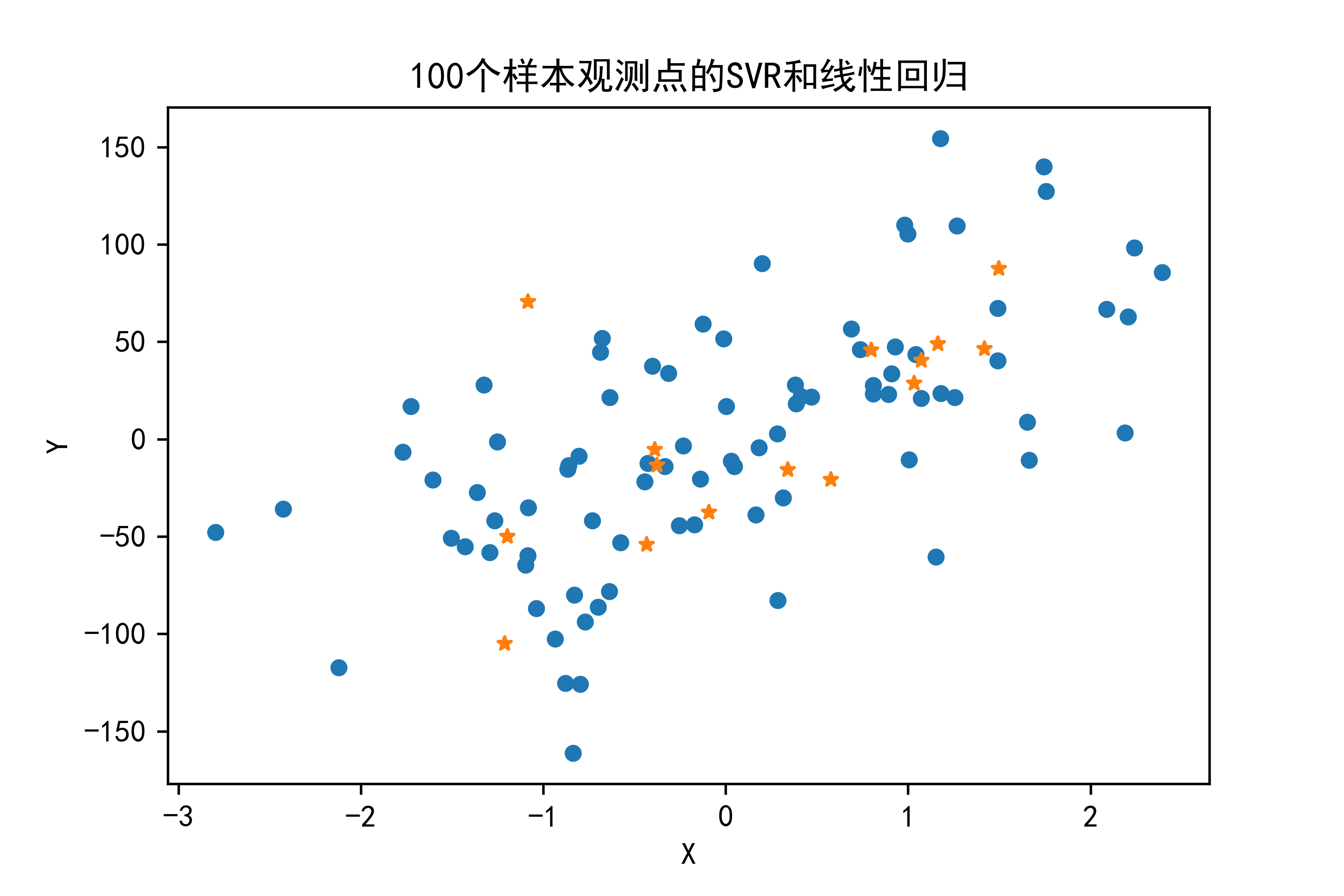
02-100个样本观测点的SVR和线性回归
这段代码是一个完整的数据分析和可视化流程,主要使用了Python中常用的数据科学和机器学习库。让我逐步解释每部分的作用和含义:
模块导入:
import numpy as np from numpy import random import pandas as pd import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import warnings warnings.filterwarnings(action='ignore') %matplotlib inline
- 导入了常用的科学计算库(如NumPy、Pandas、Matplotlib)、三维绘图模块和警告处理。
%matplotlib inline用于在Jupyter Notebook中直接显示Matplotlib生成的图形。中文显示设置:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示乱码问题 plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题数据生成与划分:
N = 100 X, Y = make_regression(n_samples=N, n_features=1, random_state=123, noise=50, bias=0) X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.85, random_state=123)
- 使用
make_regression生成具有噪声的回归数据,然后将数据划分为训练集和测试集。第一个图形绘制:
plt.scatter(X_train, Y_train, s=20) plt.scatter(X_test, Y_test, s=20, marker='*') plt.title("100个样本观测点的SVR和线性回归") plt.xlabel("X") plt.ylabel("Y") plt.savefig("../3.png", dpi=500)
- 绘制散点图,展示训练集和测试集数据点。
- 设置图标题和坐标轴标签,并保存图形为 “…/3.png”。
线性回归模型拟合:
modelLM = LM.LinearRegression() modelLM.fit(X_train, Y_train)
- 使用线性回归模型拟合训练数据。
多个SVR模型绘制:
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 9)) for C, E, H, L in [(1, 0.1, 0, 0), (1, 100, 0, 1), (100, 0.1, 1, 0), (10000, 0.01, 1, 1)]: modelSVR = svm.SVR(C=C, epsilon=E) modelSVR.fit(X_train, Y_train) axes[H, L].scatter(X_train, Y_train, s=20) axes[H, L].scatter(X_test, Y_test, s=20, marker='*') axes[H, L].scatter(X[modelSVR.support_], Y[modelSVR.support_], marker='o', c='b', s=120, alpha=0.2) axes[H, L].plot(X, modelSVR.predict(X), linestyle='-', label="SVR") axes[H, L].plot(X, modelLM.predict(X), linestyle='--', label="线性回归", linewidth=1) axes[H, L].legend() ytrain = modelSVR.predict(X_train) ytest = modelSVR.predict(X_test) axes[H, L].set_title("SVR(C=%d,epsilon=%.2f,训练MSE=%.2f,测试MSE=%.2f)" % (C, E, mean_squared_error(Y_train, ytrain), mean_squared_error(Y_test, ytest))) axes[H, L].set_xlabel("X") axes[H, L].set_ylabel("Y") axes[H, L].grid(True, linestyle='-.')
- 创建一个包含四个子图的图形布局。
- 对每个子图,使用不同的参数C和epsilon训练SVR模型,并绘制训练集和测试集数据点,支持向量,SVR和线性回归模型的拟合曲线。
- 设置图标题,显示训练和测试集的均方误差(MSE)。
保存第二个图形:
plt.savefig("../4.png", dpi=500)
- 将包含四个子图的图形保存为 “…/4.png”,分辨率为500 dpi。
这段代码展示了如何使用Python进行回归分析和可视化,比较了SVR和线性回归模型在不同参数设置下的效果,并通过图形直观地展示了数据点、拟合曲线以及模型的评估结果。
#本章需导入的模块
import numpy as np
from numpy import random
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.model_selection import train_test_split,KFold
import sklearn.neural_network as net
import sklearn.linear_model as LM
from scipy.stats import multivariate_normal
from sklearn.metrics import r2_score,mean_squared_error,classification_report
from sklearn import svm
import os
N=100
X,Y=make_regression(n_samples=N,n_features=1,random_state=123,noise=50,bias=0)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.85, random_state=123)
plt.scatter(X_train,Y_train,s=20)
plt.scatter(X_test,Y_test,s=20,marker='*')
plt.title("100个样本观测点的SVR和线性回归")
plt.xlabel("X")
plt.ylabel("Y")
plt.savefig("../3.png", dpi=500)
modelLM=LM.LinearRegression()
modelLM.fit(X_train,Y_train)
X[:,0].sort()
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(12,9))
for C,E,H,L in [(1,0.1,0,0),(1,100,0,1),(100,0.1,1,0),(10000,0.01,1,1)]:
modelSVR=svm.SVR(C=C,epsilon=E)
modelSVR.fit(X_train,Y_train)
axes[H,L].scatter(X_train,Y_train,s=20)
axes[H,L].scatter(X_test,Y_test,s=20,marker='*')
axes[H,L].scatter(X[modelSVR.support_],Y[modelSVR.support_],marker='o',c='b',s=120,alpha=0.2)
axes[H,L].plot(X,modelSVR.predict(X),linestyle='-',label="SVR")
axes[H,L].plot(X,modelLM.predict(X),linestyle='--',label="线性回归",linewidth=1)
axes[H,L].legend()
ytrain=modelSVR.predict(X_train)
ytest=modelSVR.predict(X_test)
axes[H,L].set_title("SVR(C=%d,epsilon=%.2f,训练MSE=%.2f,测试MSE=%.2f)"%(C,E,mean_squared_error(Y_train,ytrain),
mean_squared_error(Y_test,ytest)))
axes[H,L].set_xlabel("X")
axes[H,L].set_ylabel("Y")
axes[H,L].grid(True,linestyle='-.')
plt.savefig("../4.png", dpi=500) 运行结果如下图所示:
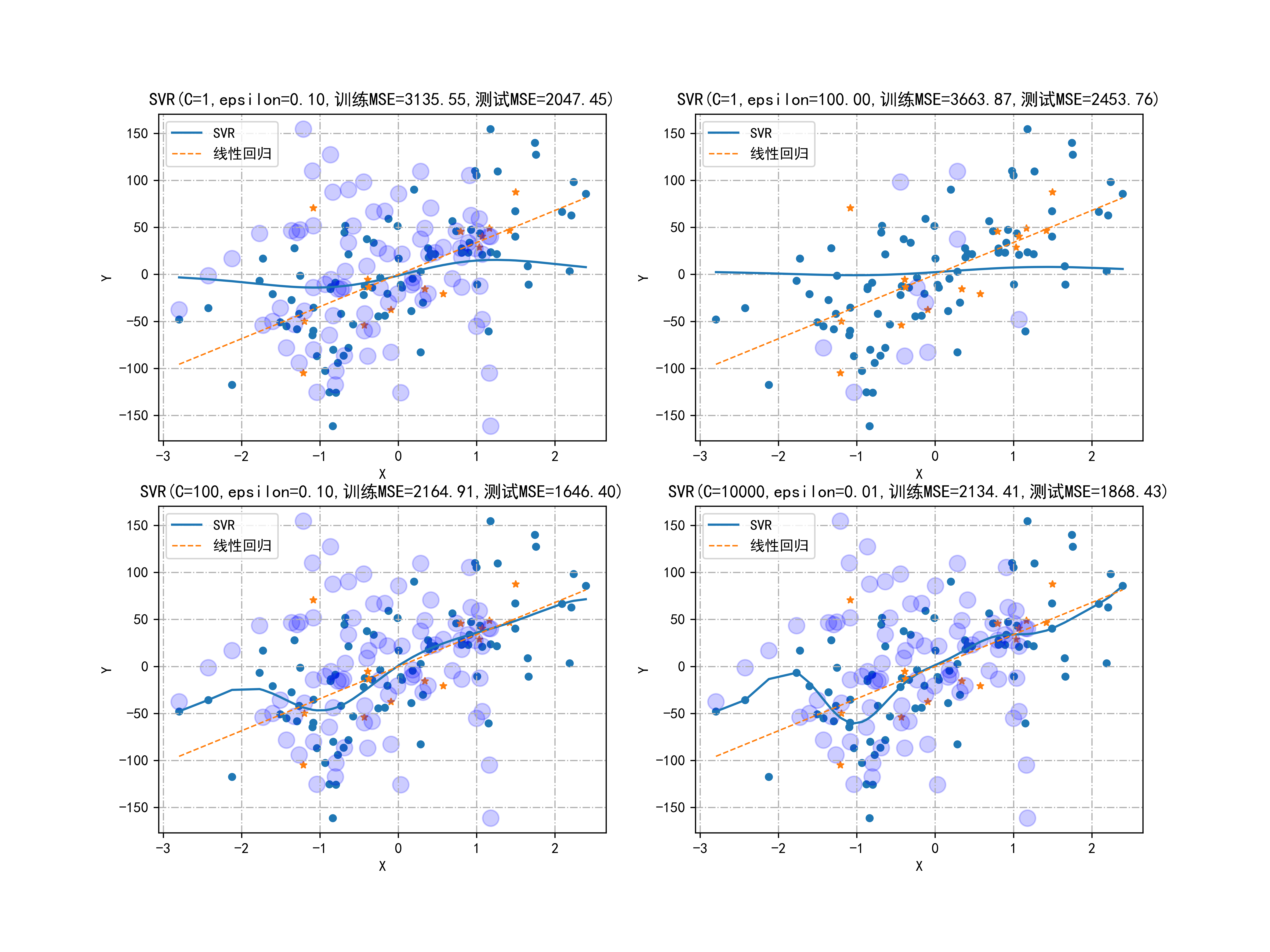
03-老人的活动进行统计
这段代码主要实现了以下功能:
导入必要的模块:
- 导入 numpy 库,并从中导入 random 模块。
- 导入 pandas 库,并重命名为 pd。
- 导入 matplotlib.pyplot 库,并重命名为 plt。
- 导入 mpl_toolkits.mplot3d 库中的 Axes3D 模块。
- 使用 warnings 库来过滤警告信息。
- 设置 matplotlib 图表显示中文。
- 导入 sklearn 中的一些模块和函数。
- 导入 scipy.stats 中的 multivariate_normal 函数。
- 导入 sklearn.metrics 中的一些评估指标函数。
- 导入 os 模块。
定义文件路径 path,并列出该路径下的所有文件名。
创建空的 DataFrame data 用于存储数据,包括列:‘TimeStamp’, ‘frontal’, ‘vertical’, ‘lateral’, ‘SensorID’, ‘RSSI’, ‘Phase’, ‘Frequency’, ‘Activity’, ‘ID’, ‘Gender’。
遍历文件名列表,逐个读取文件中的数据,并将每个文件的数据添加到 data 中,同时为数据添加 ‘ID’ 和 ‘Gender’ 两列。
根据 ‘Activity’ 列中的不同活动类型统计数量,并绘制柱状图展示老人的体位状态,其中1表示’坐在床上’,2表示’坐在椅子上’,3表示’躺在床上’,4表示’行走’。
将 ‘Activity’ 映射为二分类标签 ‘ActivityN’,分为0(‘坐在床上’或’坐在椅子上’)和1(‘躺在床上’或’行走’),统计并绘制体位状态的饼状图。
将绘制的体位状态图保存为文件’4.png’,并显示在输出中。
综上所述,这段代码的作用是读取多个文件中的数据,对老人的活动进行统计,并通过可视化展示老人不同体位状态的情况,最终将结果保存为一幅图片。
#本章需导入的模块
import numpy as np
from numpy import random
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.model_selection import train_test_split,KFold
import sklearn.neural_network as net
import sklearn.linear_model as LM
from scipy.stats import multivariate_normal
from sklearn.metrics import r2_score,mean_squared_error,classification_report
from sklearn import svm
import os
#path='C:/Users/xuewe/《Python机器学习:数据建模与分析》代码/健康物联网/'
path='D:/代码与数据/健康物联网/'
#print(os.path.dirname(path)) 返回文件路径
#cwd=os.getcwd() 得到当前目录
#os.path.join(dirname, filename)
#os.walk(path)
filenames=os.listdir(path=path)
data=pd.DataFrame(columns=['TimeStamp', 'frontal', 'vertical', 'lateral', 'SensorID', 'RSSI','Phase', 'Frequency', 'Activity', 'ID', 'Gender'])
i=1
for filename in filenames:
tmp=pd.read_csv(path+filename)
tmp['ID']=i
tmp['Gender']=filename[-5]
i+=1
data=data.append(tmp)
label=['坐在床上','坐在椅子上','躺在床上','行走']
countskey=data['Activity'].value_counts().index
plt.bar(np.unique(data['Activity']),data['Activity'].value_counts())
plt.xticks([1,2,3,4],[label[countskey[0]-1],label[countskey[1]-1],label[countskey[2]-1],label[countskey[3]-1]])
plt.title("老人的体位状态")
plt.show()
data['ActivityN']=data['Activity'].map({3:0,1:0,2:1,4:1})
plt.bar([1,2],data['ActivityN'].value_counts())
plt.xticks([1,2],['安全体位','风险体位'])
plt.title("老人的体位状态")
plt.savefig("../4.png", dpi=500)
plt.show()

Y=data['Activity'].astype(int)
X=data[['frontal', 'vertical', 'lateral', 'RSSI']]
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=1)
for ker in ['poly','rbf']:
modelSVC=svm.SVC(kernel=ker,random_state=123)
modelSVC.fit(X_train,Y_train)
print("测试误差=%f(%s)"%(1-modelSVC.score(X_test,Y_test),ker))
print(classification_report(Y_test,modelSVC.predict(X_test)))
测试误差=0.056962(poly)
precision recall f1-score support
1 0.57 0.71 0.63 368
2 0.00 0.00 0.00 170
3 0.97 1.00 0.98 6147
4 0.00 0.00 0.00 109
accuracy 0.94 6794
macro avg 0.38 0.43 0.40 6794
weighted avg 0.91 0.94 0.93 6794
测试误差=0.095231(rbf)
precision recall f1-score support
1 0.00 0.00 0.00 368
2 0.00 0.00 0.00 170
3 0.90 1.00 0.95 6147
4 0.00 0.00 0.00 109
accuracy 0.90 6794
macro avg 0.23 0.25 0.24 6794
weighted avg 0.82 0.90 0.86 6794
04-基于线性回归以及支持向量机对汽车MPG与自重进行回归预测
这段代码实现了以下功能:
导入必要的模块:
- 导入 numpy 库,并从中导入 random 和 math 模块。
- 导入 pandas 库,并重命名为 pd。
- 导入 matplotlib.pyplot 库,并重命名为 plt。
- 导入 mpl_toolkits.mplot3d 库中的 Axes3D 模块。
- 使用 warnings 库来过滤警告信息。
- 设置 matplotlib 图表显示中文。
- 导入 sklearn 中的一些模块和函数。
- 导入 scipy.stats 中的 multivariate_normal 函数。
- 导入 sklearn.metrics 中的一些评估指标函数。
- 导入 sklearn 中的支持向量回归模型 svm。
- 导入 os 模块。
读取名为 ‘汽车MPG.csv’ 的数据文件,并丢弃缺失值。
选择数据中的 ‘weight’ 和 ‘horsepower’ 列作为特征 X,‘MPG’ 列作为目标变量 Y。初始化一个测试点 X0 和对应的预测目标值 Y0。
建立线性回归模型 modelLM 和支持向量回归模型 modelSVR。
创建用于绘图的子图,设置子图的大小为 2x2。
使用 KFold 进行两折交叉验证,分别在训练集上训练线性回归模型和支持向量回归模型,并对测试点进行预测。
在每个子图中绘制:
- 左上角:训练数据点的散点图;
- 右上角:线性回归和支持向量回归的预测结果;
- 左下角:在训练数据上的 MPG 与自重 的关系散点图以及测试点的预测结果;
- 右下角:线性回归和支持向量回归在测试点上的预测结果。
保存绘制的图像为文件’4.png’。
综上所述,这段代码的主要作用是使用线性回归和支持向量回归模型预测汽车的燃油效率(MPG),并通过交叉验证和可视化展示模型在训练集上的拟合情况和在测试点上的预测效果。
#本章需导入的模块
import numpy as np
from numpy import random,math
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.model_selection import train_test_split,KFold
import sklearn.neural_network as net
import sklearn.linear_model as LM
from scipy.stats import multivariate_normal
from sklearn.metrics import r2_score,mean_squared_error,classification_report
from sklearn import svm
import os
data=pd.read_csv('汽车MPG.csv')
data=data.dropna()
data.head()
X=data[['weight','horsepower']]
X0=[[X.max()[0],X.max()[1]]]
Y0=data['MPG'].mean()
modelLM=LM.LinearRegression()
modelSVR=svm.SVR(C=1000,epsilon=0.01)
yhat1=[]
yhat2=[]
fig,axes=plt.subplots(nrows=2,ncols=2,figsize=(12,10))
kf = KFold(n_splits=2,shuffle=True,random_state=123) # K折交叉验证法
H=0
for train_index, test_index in kf.split(X):
sample=data.iloc[train_index,]
X=sample[['weight','horsepower']]
#Y=sample['MPG'].map(lambda x:math.log(x))
Y=sample['MPG']
modelLM.fit(X,Y)
modelSVR.fit(X,Y)
yhat1.append(modelLM.predict(X0))
yhat2.append(modelSVR.predict(X0))
axes[H,0].scatter(sample['weight'],sample['MPG'],s=20,label="训练点")
axes[H,0].set_title("MPG与自重(训练集%d)"%(H+1))
axes[H,0].set_xlabel("自重")
axes[H,0].set_ylabel("MPG")
axes[H,0].scatter(X0[0][0],Y0,c='r',s=40,marker='*',label="新数据点")
axes[H,0].legend()
axes[H,1].scatter(sample['weight'],modelLM.predict(X),s=15,marker='*',c='orange',label="线性回归预测")
axes[H,1].scatter(sample['weight'],modelSVR.predict(X),s=15,marker='o',c='blue',label="SVR预测")
axes[H,1].set_title("MPG与自重(训练集%d)"%(H+1))
axes[H,1].set_xlabel("自重")
axes[H,1].set_ylabel("MPG")
axes[H,1].scatter(X0[0][0],modelLM.predict(X0),c='r',s=40,marker='<',label="新数据点的线性回归预测")
axes[H,1].scatter(X0[0][0],modelSVR.predict(X0),c='r',s=40,marker='>',label="新数据点的SVR预测")
axes[H,1].legend()
H+=1
plt.savefig("../4.png", dpi=500) 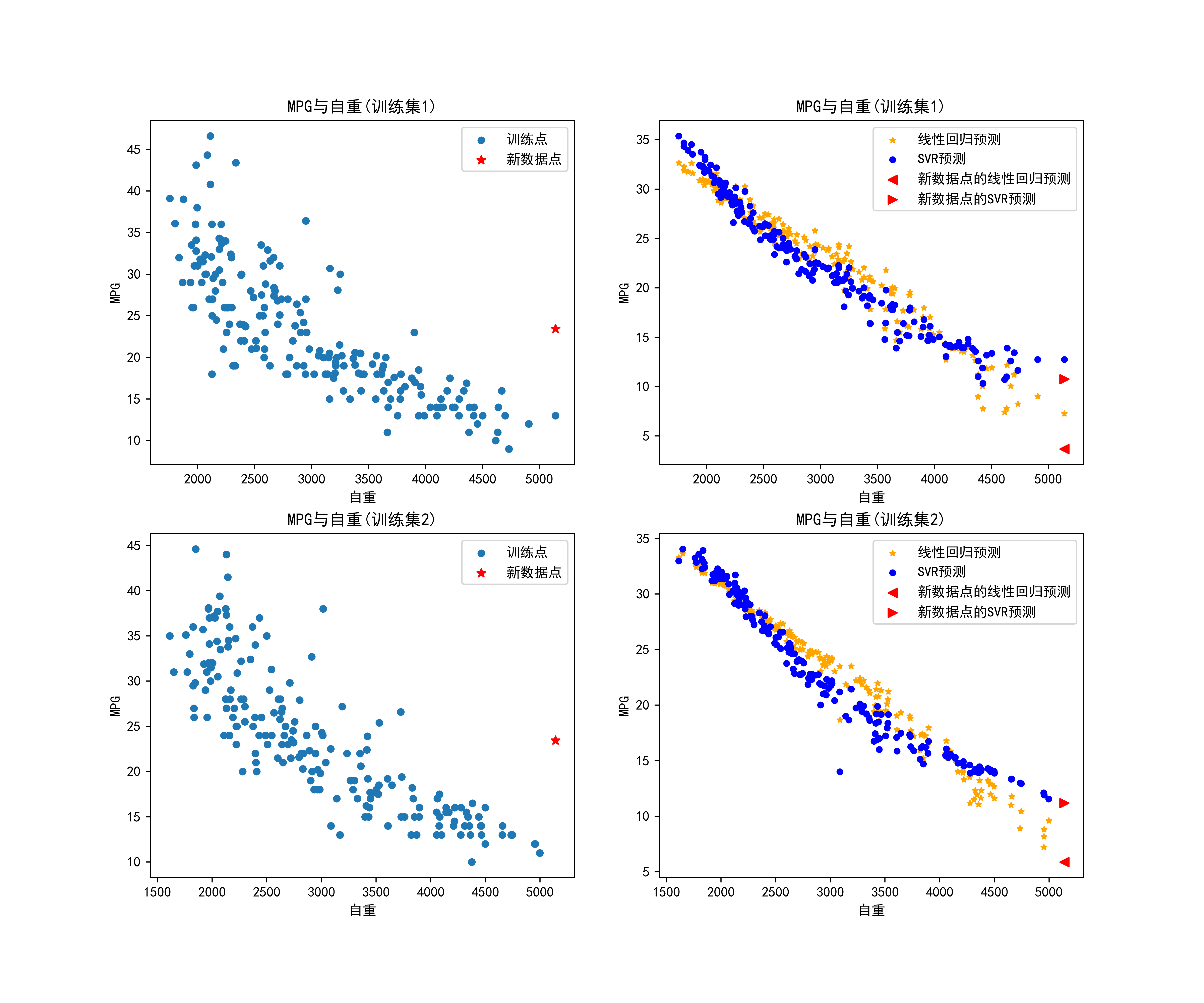
总结
总的来说,线性回归适用于预测连续数值,而支持向量机适用于处理分类问题,并且能够处理非线性分类任务。选择适当的算法取决于数据类型、任务需求和模型复杂度。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Python机器学习实战】 | 基于线性回归以及支持向量机对汽车MPG与自重进行回归预测

发表评论 取消回复