复制
复制管理和维护
确定主备是否一致
在理想情况下,备库和主库的数据应该是完全一样的。但事实上备库可能发生错误并导致数据不一致。即使没有明显的错误,备库同样可能因为MySQL自身的特性导致数据不一致,例如MySQL的Bug、网络中断、服务器崩溃,非正常关闭或者其他一些错误。(如果你正在使用非事务型存储引擎,不首先调用STOP SLAVE就关闭服务器是很不妥当的)。
按照经验来看,主备一致应该是一种规范,而不是例外,也就是说,检查你的主备一致性应该是一个日常工作,特别是当使用备库来做备份时尤为重要,因为你肯定不希望从一个已经损坏的备库里获得备份数据。MySQL并没有内建的方法来比较一台服务器与别的服务器的数据是否相同。它提供了一些组建来为表和数据生成校验值,例如CHECKSUM TABLE。但当复制正在进行时,这种方法是不可行的。
Percona Toolkit里的pt-table-checksum能够解决上述几个问题。其主要特性是用于确认备库与主库的数据是否一致。工作方式是通过在主库执行INSERT …SELECT查询。这些查询对数据进行校验并将结果插入到一个表中。这些语句通过复制传递到备库,并在备库执行一遍,然后可以比较主备上的结果是否一样。由于该方法是通过复制工作的。它能够给出一致的结果而无须同时把主备上的表都锁上。
通常情况下可以在主库上运行该工具,参数如下:
$ pt-table-checksum --replicate=test.checksum <master_host>
该命令将检查所有的表,并将结果插入到test.checksum表中。当查询在备库执行完后,就可以简单地比较主备之间的不同了。pt-table-checksum能够发现服务器所有的备库,在每台备库上运行查询,并自动地输出结果。
从主库重新同步备库
在职业生涯中,也许会不止一次需要去处理未被同步的备库。可能是使用校验工具发现了数据不一致,或是因为已经知道是备库忽略了某条查询或者有人在备库上修改了数据。传统的修复不一致的办法是关闭备库,然后重新从主库复制一份数据。当备库数据不一致的问题可能导致严重后果时,一旦发现就应该将备库停止并从生产环境移除,然后再从一个备份中克隆或恢复备库。
这种方法的缺点是不太方便,特别是数据量很大时。如果能够找出并修复不一致的数据,要比从其他服务器上重新克隆数据要有效得多。如果发现的不一致并不严重,就可以保持备库在线,并重新同步受影响的数据。最简单的办法是使用mysqldump转储受影响的数据并重新导入。在整个过程中,如果数据没有发生变化,这种方法会很好。你可以在主库上简单地锁住表然后进行转储,再等备库赶上主库,然后将数据导入到备库中。(需要等待备库赶上主库,这样就不至于为其他表引入新的不一致,例如那些可能通过和失去同步的表做join后进行数据更新的表)。
虽然这种方法再许多场景下是可行的。但在一个繁忙的服务器上有可能行不通。另外一个缺点是在备库上通过非复制的方式改变数据。通过复制改变备库数据(通过在主库上执行更新)通常是一种安全的技术,因为它避免了竞争条件和其他意料外的事情。如果表很大或者网络带宽首先,转储和重载数据的代价依然很高。当在一个有一百万行的表上只有一千行不同的数据呢?转储和重载表的数据是非常浪费资源的。
pt-table-sync是Percona Toolkit中的另外一个工具,可以解决该问题。该工具能够高效地查找并解决表之间的不同。它同样通过复制工作,在主库上执行查询,在备库上重新同步,这样就没有竞争条件。它是结合pt-table-checksum生成的checksum表来工作的。所以只能操作那些已知不同步的表的数据块。但该工具不是在所有场景下都有效。为了正确地同步主库和备库,该工具要求复制是正常地,否则就无法工作。pt-table-sync设计得很搞笑,但当数据量非常大时效率还是会很低。比较主库和备库上1TB的数据不可避免地会带来额外的工作。尽管如此,在那些合适的场景中,该工具依然能节约大量的时间和工作
改变主库
迟早会有把备库指向一个新的主库的需求。也许是为了更迭升级服务器,或者是主库出现问题时需要把一台备库转换成主库,或者只是希望重新分配容量。不管处于什么原因,都需要告诉其他的备库新主库的信息。如果这是计划内的操作,会比较容易(至少比紧急情况下要容易)。只需在备库简单地使用CHNAGE MASTER TO命令,并指定合适的值。大多数值都是可选的。只需要指定需要改变的项即可。备库将抛弃之前的配置和中继日志并从新的主库开始复制。同样新的参数会被更新到master.info文件中,这样就算重启,备库配置信息也不会丢失。
整个过程中最难的是获取新主库上合适的二进制日志文职,这样备库才可以从和老主库相同的逻辑位置开始复制。把备库提升为主库要更困难一点。有两种场景需要将备库替换为主库,一种是计划内的提升,一种是计划外的提升。
计划内的提升
把备库提升为主库理论上是很简单的。简单来说,有以下步骤:
- 1.停止向老的主库ieru
- 2.让备库追赶上主库(可选的,会简化下面的步骤)
- 3.将一台备库配置为新的主库
- 4.将备库和写操作指向新的主库,然后开启主库的写入
但这其中还隐藏着很多细节。一些场景可能依赖于复制的拓扑结构。例如,主-主结构和主-备结构的配置就有所不同。
更深入一点,下面是大多数配置需要的步骤:
- 1.停止当前主库上的所有写操作。如果可以,最好能将所有的客户端程序关闭(除了复制连接)。为客户端程序建立一个"do not run"这样的类似标记可能会有所帮助。如果正在使用虚拟IP地址,也可以简单地关闭虚拟IP,然后断开所有地客户端连接以关闭其打开地事务
- 2.通过FLUSH TABLES WITH READ LOCK在主库上停止所有活跃的写入,这一步是可选的。也可以在主库上设置read_only选项。从这一刻开始,应该禁止向即将备替换的主库做任何写入。因为一旦它不是主库,写入就意味着数据丢失。注意,即使设置read_only也不会阻止当前已存在的事务继续提交。为了更好地保证这一点,可以"kill"所有打开的事务,这将会真正地结束所有写入
- 3.选择一个备库作为新的主库,并确保它已经完全跟上主库(例如,让他执行完所有从主库获得的中继日志)
- 4.确保新主库和旧主库的数据是已知的。可选
- 5.在新主库上执行STOP SLAVE
- 6.在新主库上执行CHANGE MASTER TO MASTER_HOST=‘’,然后再执行RESET SLAVE,使其断开与老主库的连接,并丢弃master.info里记录的信息(如果连接信息记录在my.cnf里,会无法正确工作,这也是建议不要把复制连接信息写到配置文件里的原因之一)
- 7.执行SHOW MASTER STATUS记录新主库的二进制日志坐标
- 8.确保其他备库已经追赶上
- 9.关闭旧主库
- 10.在MySQL5.1及以上版本中,如果需要,激活新主库上事件
- 11.将客户端连接到新主库
- 12.在每台备库上执行CHANGE MASTER TO语句,使用之前通过SHOW MASTER STATUS获得的二进制日志坐标,来指向新的主库。
当将备库提升为主库时,要确保备库上任何特有的数据库、表和权限已经备移除。可能还需要修改备库特有的配置选项,例如innodb_flush_log_at_trx_commit选项,同样的,如果是把主库降级为备库,也要保证需要的配置。如果主备的配置相同,就不需要做任何改变。
计划外的提升
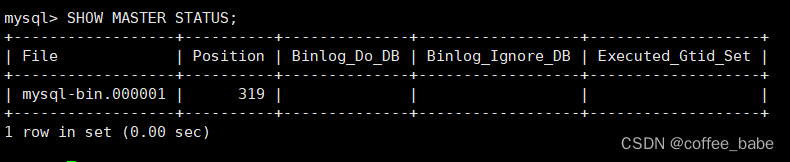
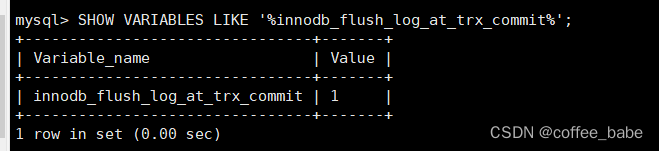
当主库崩溃时,需要提升一台备库来代替它,这个过程可能就不太容易。如果只有一台备库,可以直接使用这台备库。但如果有超过一台的备库,就需要做一些额外的工作。另外,还有潜在的丢失复制事件的问题。可能有主库上已经发生了修改还没有更新到它的任何一台备库上的情况。甚至还可能一条语句在主库上执行了回滚,但在备库上没有回滚,这样备库可能超过主库的逻辑复制位置(这是有可能的,即使MySQL在事务提交前并不记录任何事件。另外一种场景是主库崩溃后恢复,但没有设置innnodb_flush_log_at_trx_commit的值为1,所以可能会丢失一些更新)。如果能在某一点恢复主库的数据,也许就可以取得丢失的语句并手动执行它们。在以下的步骤中,需要确保在计算中使用Master_Log_File和Read_Master_Log_Pos的值。以下是对主备拓扑结构中的备库进行提升的过程:
- 1.确定哪台备库的数据最新。检查每台备库上的SHOW SLAVE STATUS命令的输出,选择其中Master_Log_File/read_Master_Log_Pos的值最新的那个。
- 2.让所有哦备库执行完所有其从崩溃前的旧主库那获得的中继日志。如果在未完成前修改备库的主库,它会抛弃剩下的日志事件,从而无法获知该备库在什么地方停止
- 3.执行前面的5~7步
- 4.比较每台备库和新主库上的Master_Log_File/Read_Master_Log_Pos的值
- 5.执行前面的10~12步
正如开始推荐的,假设已经在所有的备库上开启了log_bin和log_slave_updates,这样可以帮助你将所有的备库恢复到一个一致的时间点,如果没有开启这两个选项,则不能可靠地做到这一点。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » MySQL之复制(九)

发表评论 取消回复