
kafka前置知识在上一章讲过了 不再复述
kafka进阶
1. server.properties配置文件
server.properties是Kafka服务器的配置文件,它用于配置Kafka服务的各个方面,包括网络设置、日志存储、消息保留策略、安全认证
#broker的全局唯一编号,不能重复
broker.id=0
#端口号
port=9092
#处理网络请求的线程数量
#接收线程会将接收到的消息放到内存中,然后再从内存中写入磁盘。
num.network.threads=3
#用来处理磁盘IO的线程数量
#消息从内存中写入磁盘是时候使用的线程数量。
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=./logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#每个topic的分区数
offsets.topic.replication.factor=1
#每个topic的副本数
transaction.state.log.replication.factor=1
#每个topic的最小副本数
transaction.state.log.min.isr=1
#日志保留时间,单位小时 168就是7天
log.retention.hours=168
#定期检查日志是否过期的间隔,单位毫秒
log.retention.check.interval.ms=300000
#日志清理器是否启用
log.cleaner.enable=true
#zookeeper地址
zookeeper.connect=localhost:2181
#zookeeper连接超时时间
zookeeper.connection.timeout.ms=18000
#zookeeper会话超时时间
group.initial.rebalance.delay.ms=0
2.producer.properties配置文件
producer.properties是Kafka生产者客户端的配置文件,用于配置Kafka生产者的行为和属性。当你使用Kafka生产者API发送消息到Kafka集群时,可以使用该配置文件哟
#配置生产者的broker列表 可以配置多个,以逗号隔开 也就是做集群的
#来获取每一个topic的分片数等元数据信息。
bootstrap.servers=localhost:9092
# 配置数据压缩方式 有none,gzip,snappy,lz4,zstd
compression.type=none
#客户端等待请求的响应的最长时间 超时时间
#request.timeout.ms=
#定期发送消息的时间间隔,一般配合batch.size使用,例如设置了50ms,那么每50ms就会发送一次消息合集
#linger.ms=
#每次发送给Kafka服务器请求消息的最大大小
#max.request.size=
#批量发送消息比如说设置了值16KB,那么消息内容凑够16KB就会被发送出去,否则就不会发送,这样可以避免单条消息太大导致的发送失败
#batch.size=
#约束producer缓存池的大小,默认是32MB,可以根据实际情况调整
#buffer.memory=
3.consumer.properties配置文件
用于配置Kafka消费者的属性。它包含了一系列用于定义消费者行为的参数和数值
#定义Kafka的Broker列表 可以配置多个,以逗号隔开 也就是做集群的
bootstrap.servers=localhost:9092
#定义消费者组的ID
group.id=test-consumer-group
#用于指定当消费者加入一个消费者组但没有可用的消费位移时的行为
#有三种选项 earliest/latest/none
#earliest:表示消费者将从最早的可用消费位移开始消费。消费者将从主题的最早消息开始消费,即使这些消息已经过期。
#latest:表示消费者将从最新的可用消费位移开始消费。消费者将从主题的最新消息开始消费,即跳过已经过期的消息。
#none:表示如果没有可用的消费位移,消费者将抛出异常。这样可以确保消费者只消费已经提交的消费位移。
#auto.offset.reset=
#心跳间隔用于保持消费者活跃状态
#session.timeout.ms
#指定消费者一次性获取最大的消息数量,如果为0表示不限制
#fetch.max.bytes=1048576
#指定消费者一次性获取的最大等待时间,如果为0表示不限制
#fetch.max.wait.ms=500
消息模式
kafka同样支持发布订阅的方式发送消息 我们来编写一下案例
官方文档 https://kafka.js.org/docs/getting-started
1. 压缩
引入CompressionTypes 选择压缩模式 GIZP LZ4 zSTD
import { Kafka,CompressionTypes } from 'kafkajs'
await producer.send({
topic: 'xiaoman',
compression: CompressionTypes.GZIP,
messages: [
{
value: '测试数据1',
headers: {
'name': Buffer.from('小满')
}
},
{ value: Buffer.from('测试数据2') },
],
})
2. 标头
允许使用标头传递对象元数据,把需要传递的数据放在headers即可数据将一起被发送过去
await producer.send({
topic: 'xiaoman',
messages: [
{
value: '测试数据1',
headers: {
'name': Buffer.from('小满')
}
},
{ value: Buffer.from('测试数据2') },
],
})
消费者获取headers 元数据
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
console.log({
topic,
partition,
value: message.value.toString(),
headers: message.headers?.name?.toString(),
})
},
})
3. 多主题派发
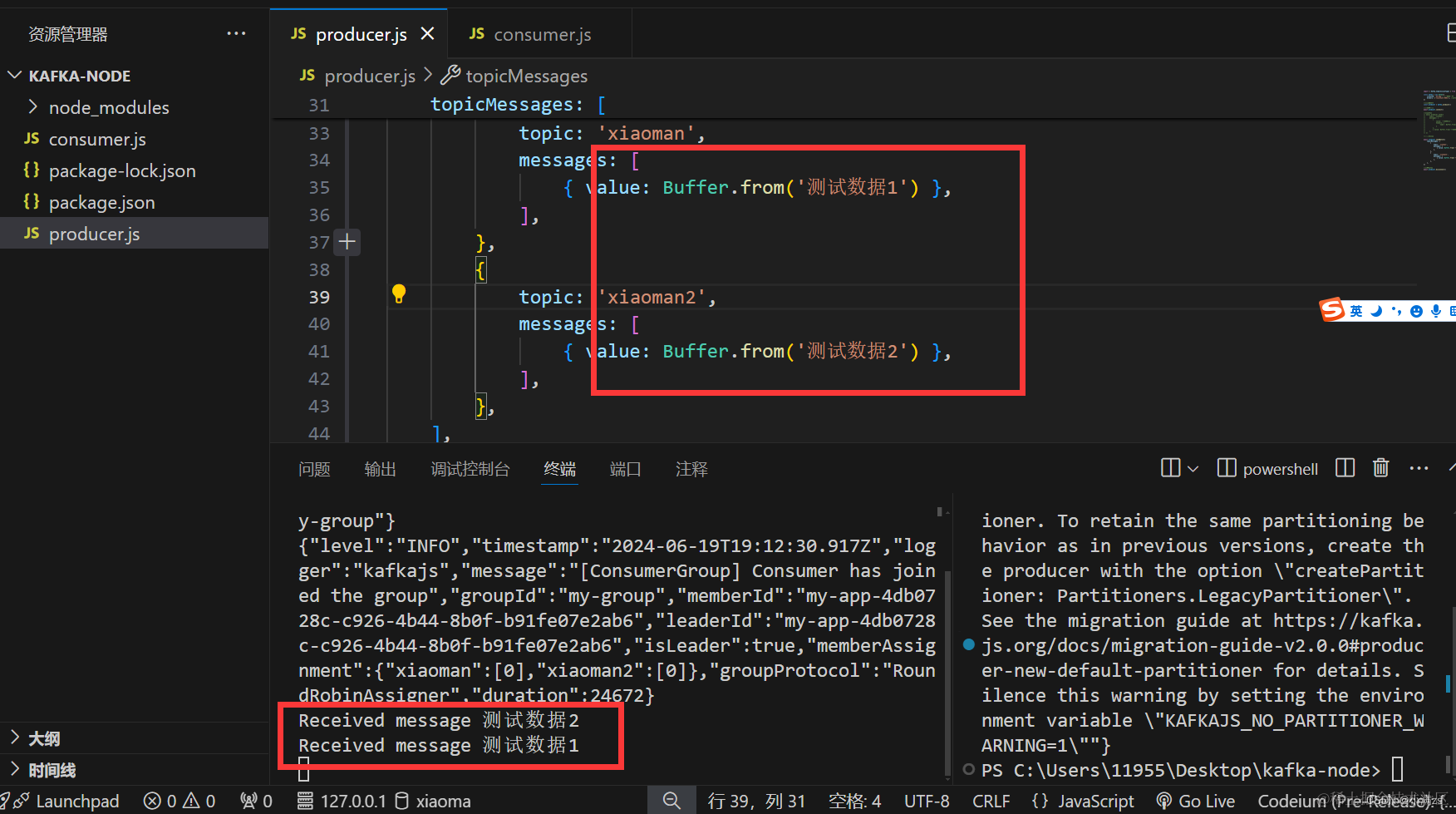
send 发方法换成 sendBatch 增加 topicMessages 是个数组
await producer.sendBatch({
topicMessages: [
{
topic: 'xiaoman',
messages: [
{ value: Buffer.from('测试数据1') },
],
},
{
topic: 'xiaoman2',
messages: [
{ value: Buffer.from('测试数据2') },
],
},
],
})
消费多个消息时候的时候可以根据业务自由选择模式
-
逐条处理
-
批量处理(批量处理可以减少网络开销)
await consumer.subscribe({ topic: 'xiaoman', fromBeginning: true })
await consumer.subscribe({ topic: 'xiaoman2', fromBeginning: true })
//逐条处理
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
console.log({
topic,
partition,
value: message.value.toString(),
headers: message.headers?.name?.toString(),
})
},
})
//批量处理
await consumer.run({
eachBatch: async ({ batch }) => {
batch.messages.forEach( (message) => {
console.log('Received message', message.value.toString())
})
},
})
案例演示
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Nodejs 第七十九章(Kafka进阶)

发表评论 取消回复