1.前言
- 有声小说相信大家都不陌生了, 里面的音频基本都是一些声优录制的
- 其实除了录制音频, 咱们可以利用百度免费的api接口使用python语言在线合成语音
- 制作属于自己的有声小说, 一睹为快吧!!
2.爬取小说网站
爬取的网站http://www.xbiquge.la/10/10489/
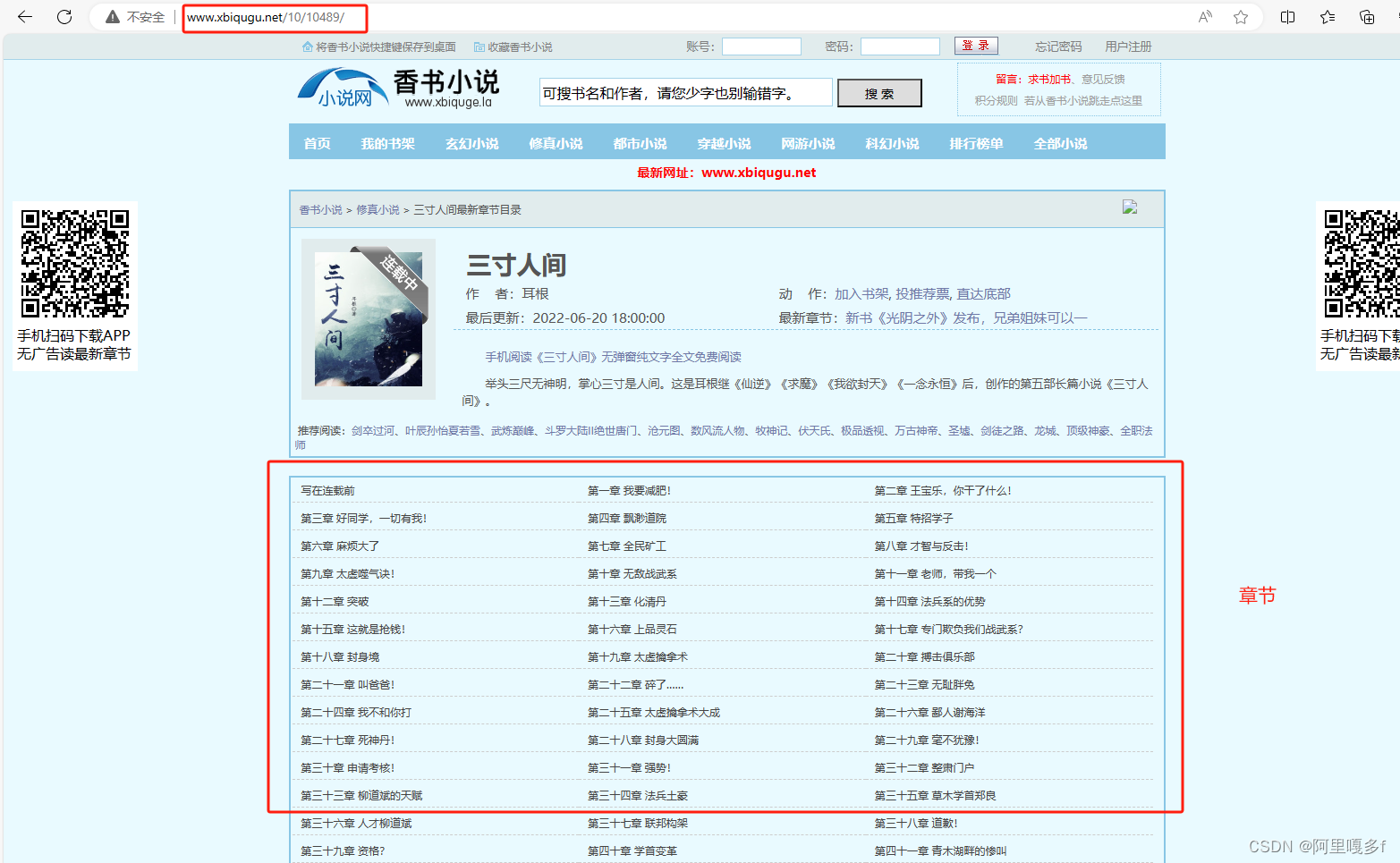
代码示例:
# -*- coding: utf-8 -*-
# @File : 爬取文本内容.py
# @Time : 2024/6/20 15:35
# @Author : syq
# @Email : 1721169065@qq.com
# @Software: PyCharm
import requests # 数据请求模块 ,第三方模块
import re # 内置模块
def get_chapter(number):
'''
:param number: 该参数是你要爬取的哪一章
:return:
'''
# 1.确定数据的url链接地址
url = 'http://www.xbiquge.la/10/10489/'
# 2.发送请求
response = requests.get(url=url)
response.encoding = response.apparent_encoding # 自动识别响应对象的编码
html_data = response.text
# print(html_data)
# 3.解析数据(只解析小说,获取每一章节小说的链接)
chapter_list_url = re.findall("<dd><a href='(.*?)' >.*?</a></dd>", html_data, re.S) #看自己要哪些数据
print(chapter_list_url)
# 爬取指定章节的小说
chapter = chapter_list_url[number]
print(chapter)
# 构建小说的全部地址
all_url = 'http://www.xbiquge.la' + chapter
response_2 = requests.get(url=all_url)
response_2.encoding = response_2.apparent_encoding # 自动识别响应对象的编码
html_data_2 = response_2.text
#print(html_data_2)
"""
<div id="content">(.*?)<p>.*</p></div>
"""
# 解析小说文本数据
result = re.findall('<div id="content">(.*?)<p>.*</p></div>', html_data_2, re.S)
# print(result)
# 4.保存数据
with open('a.txt', mode='w', encoding='utf-8') as f:
f.write(result[0].replace(' ', '').replace('<br />', ''))
number = int(input('请输入你想要爬取的章节(输入数字):'))
get_chapter(number)
运行后,生成了a.txt文件
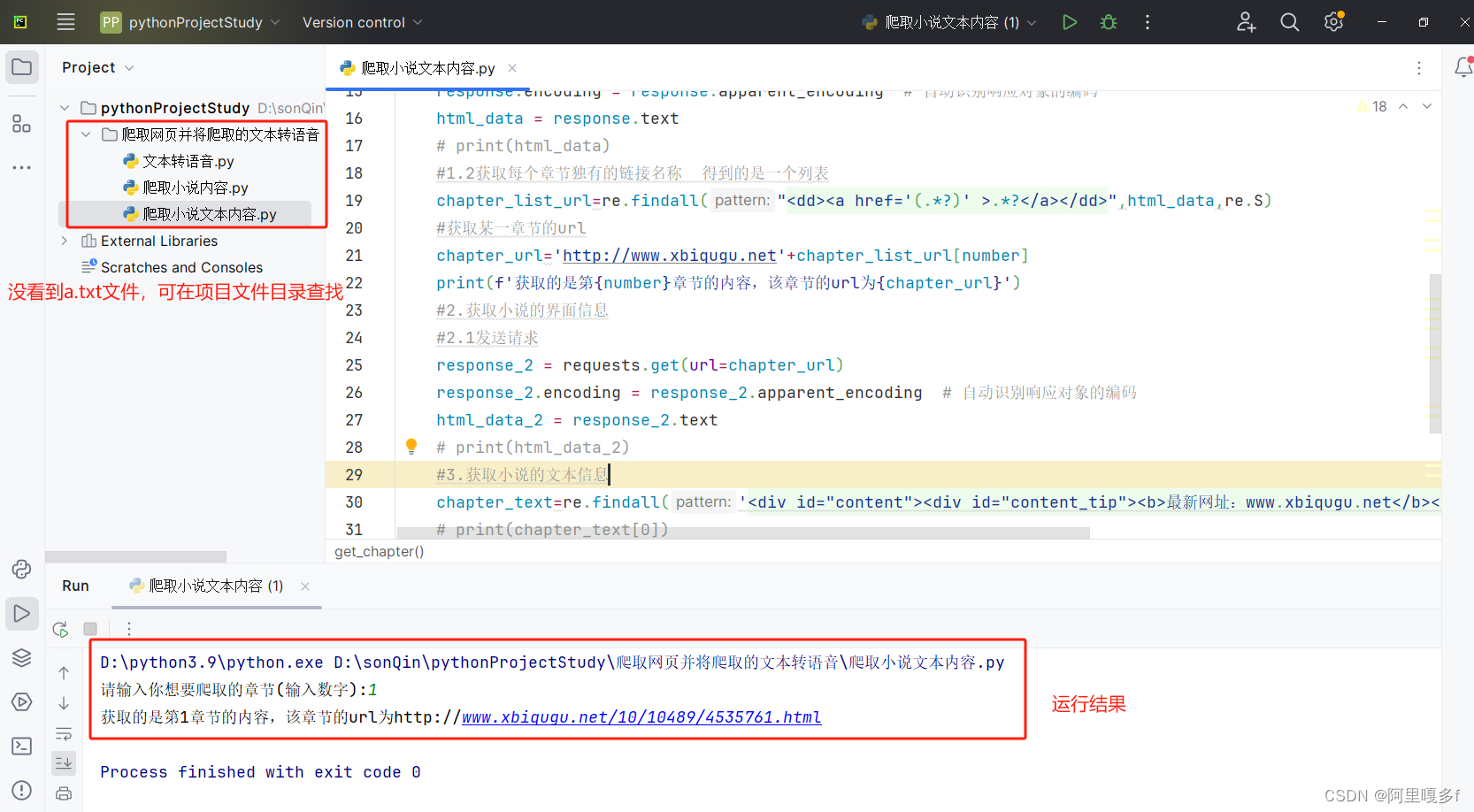
项目文件中有生成的文件,但是pycharm中没有,解决方法,如下图:
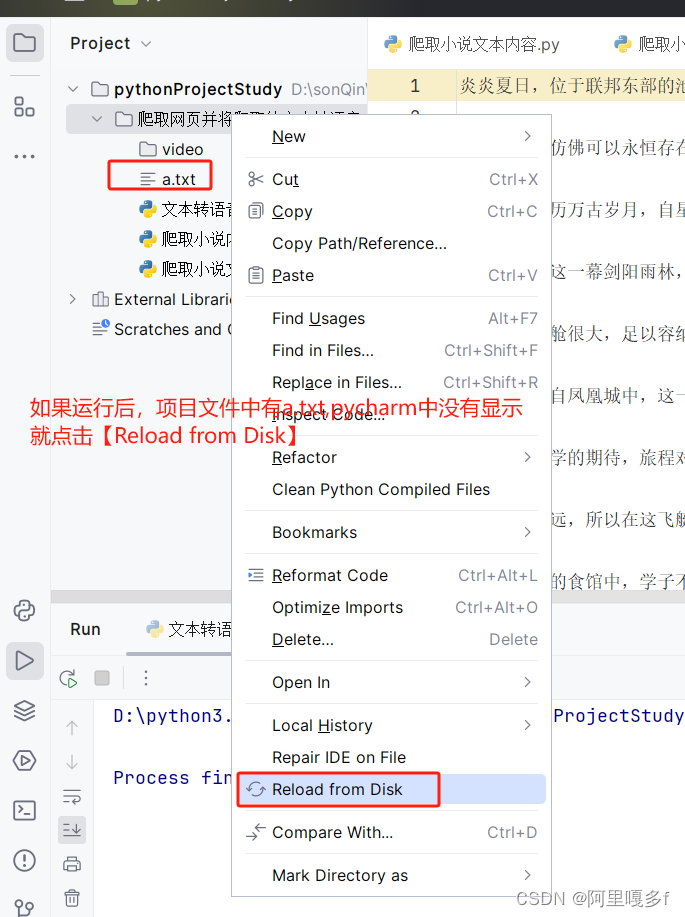
查看a.txt文件的内容

代码分析:
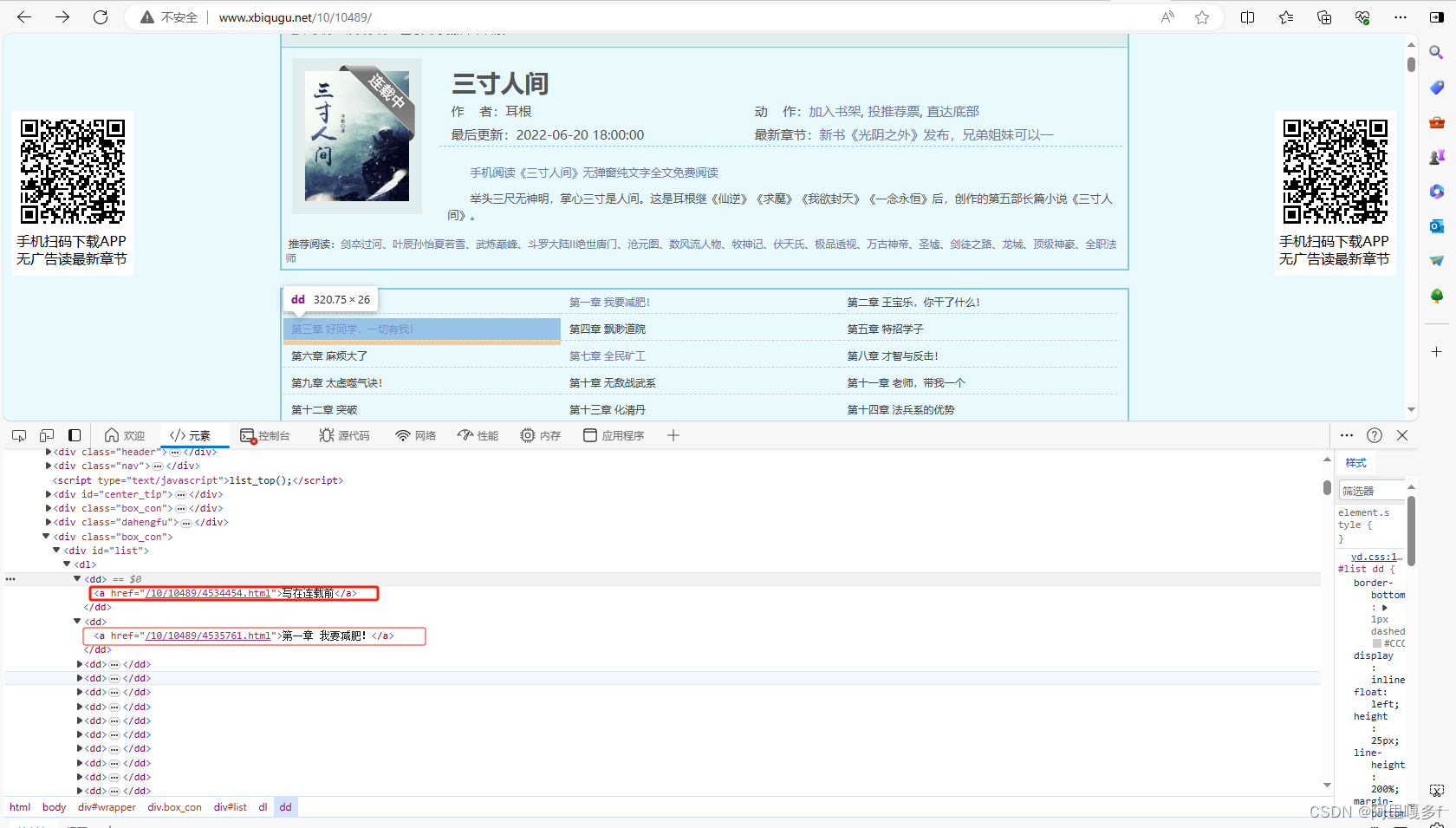
(1)代码的#1.2获取每个章节独有的链接名称 得到的是一个列表
正则表达式的写法,是根据如下图来的:
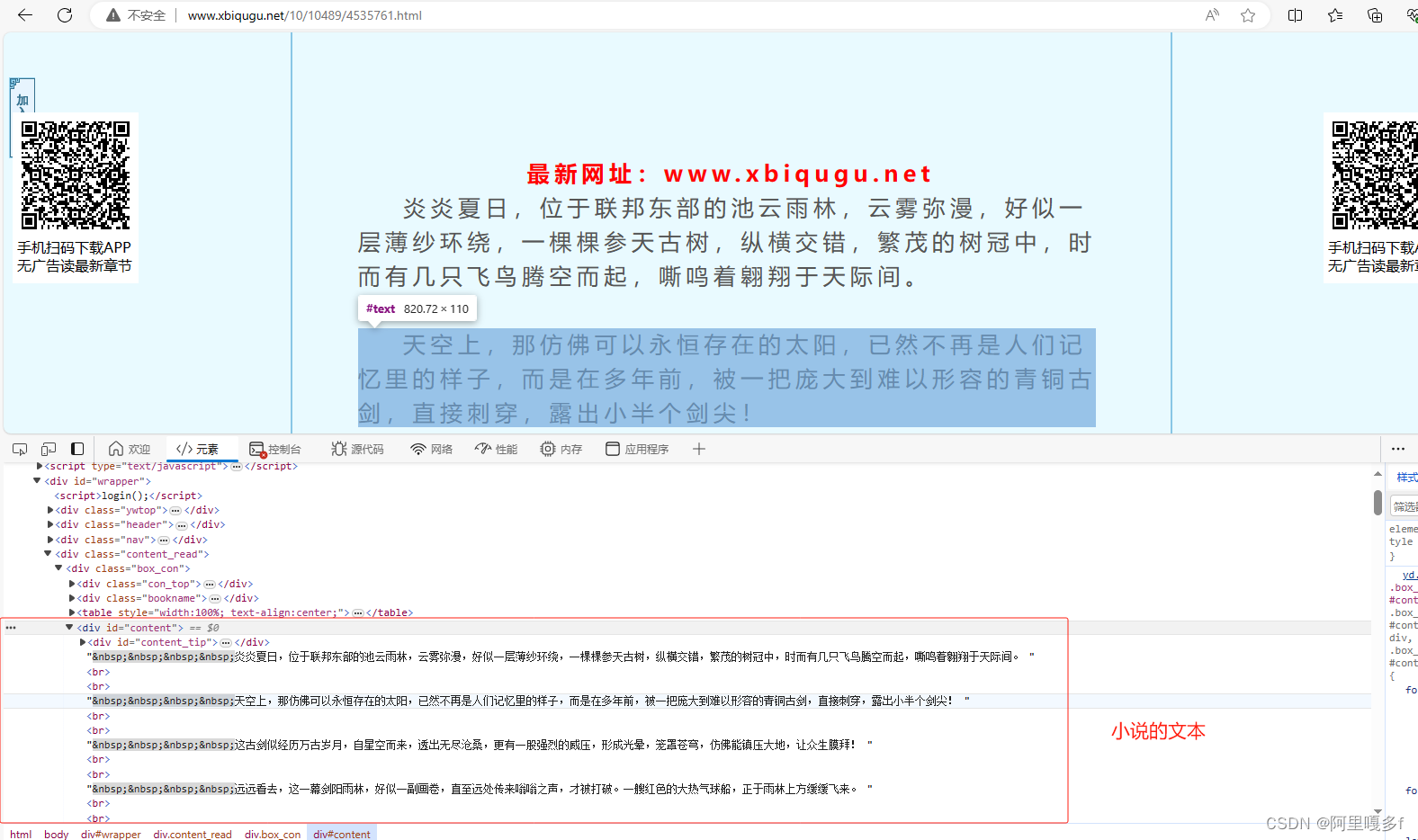
(2)代码的#3.获取小说的文本信息
正则表达式的写法,是根据如下图来的:
3.把爬取的小说文本转换为语音
调用百度AI的免费接口,参考如下链接(要从百度AI中获取3个参数值)
百度AI-语音合成(python代码练习-把文本转换为语音)-CSDN博客
代码:
# -*- coding: utf-8 -*-
# @File : 文本转语音.py
# @Time : 2024/6/21 9:26
# @Author : syq
# @Email : 1721169065@qq.com
# @Software: PyCharm
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '84493676'
API_KEY = '4dXEGpehJRDWYvvZI6ewNoL9'
SECRET_KEY = 'bbWB7DG2GHUuBLkU6XOMQbwL3TS4AUPf'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取数据, 处理文本的长度
with open('a.txt', mode='r', encoding='utf-8') as f:
# text = f.read()
# print(text)
flag = 0
while True:
flag += 1
text = f.read(512) # 每次去取512字节
if not text:
break
# print(text)
# print('*' * 100)
result = client.synthesis(text, 'zh', 1, {
'vol': 5,
# 'spd': 4,
# 'pit': 9,
# 'per': 1
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open(f'video\\{flag}.mp3', 'wb') as file:
if flag<=3: #因为a.txt的文字有点多,所以不让他全部生成
print(f'正在生成第 {flag} 个语音...')
file.write(result)
else:
break
else:
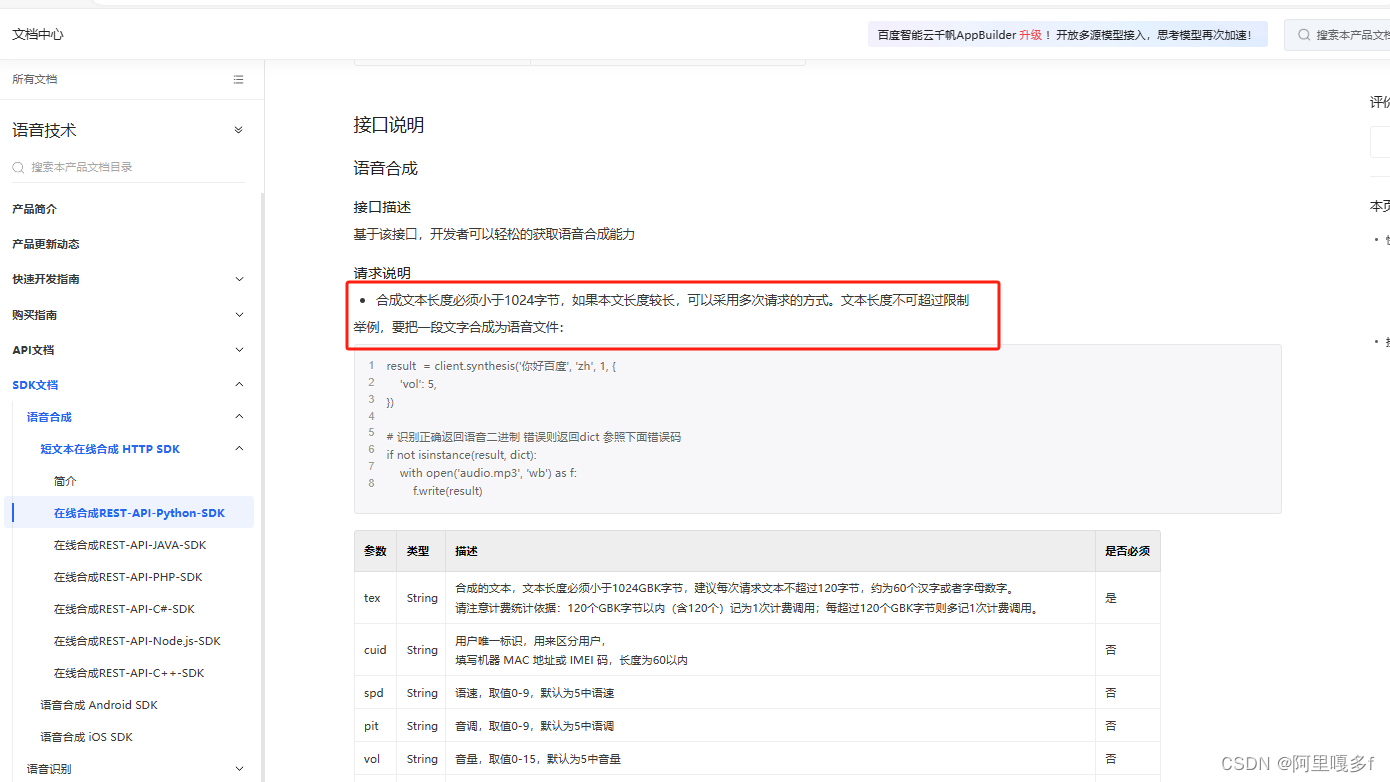
print(result)注意:text = f.read(512) # 每次去取512字节
这样写的原因:
运行结果:
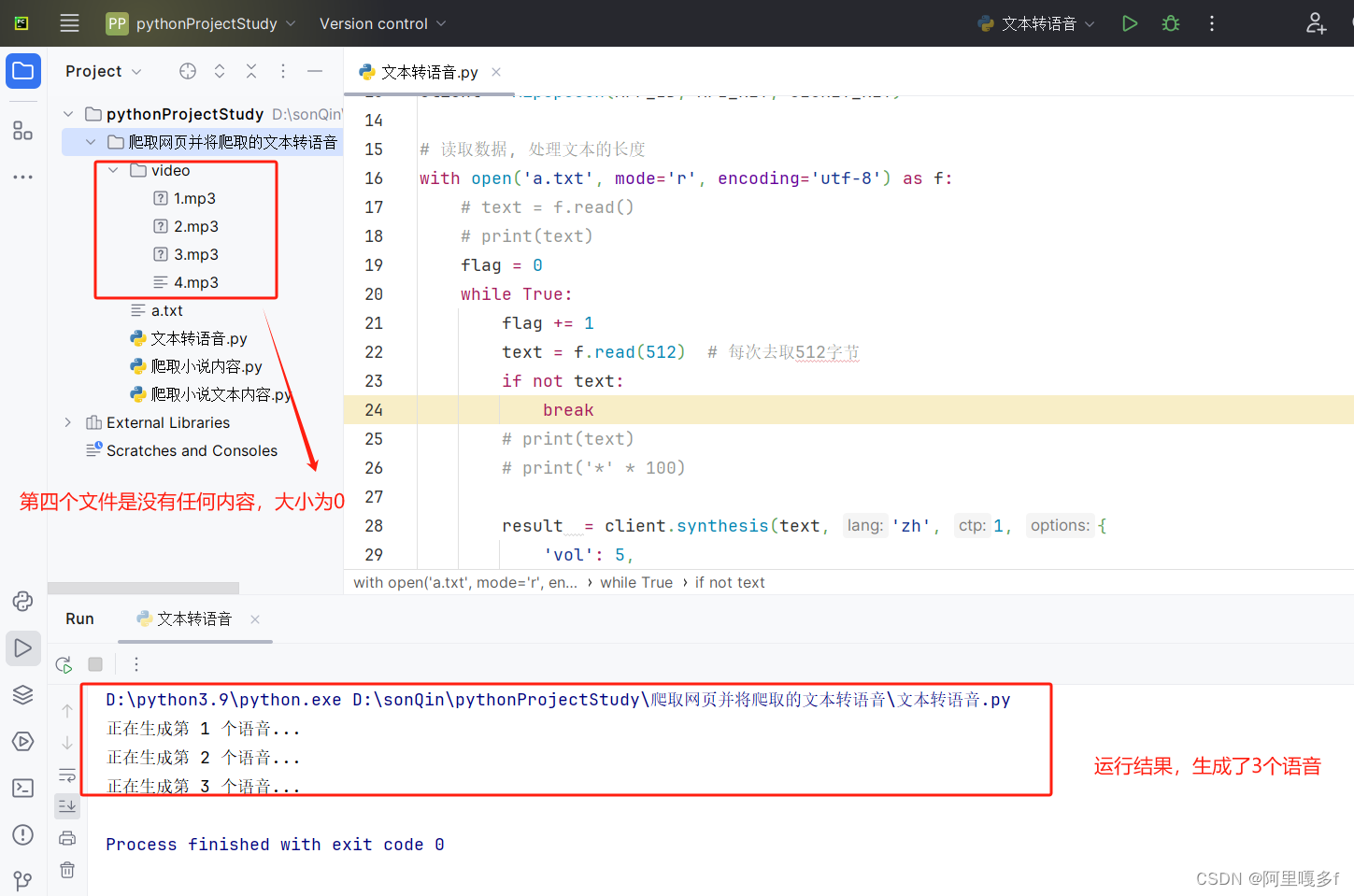
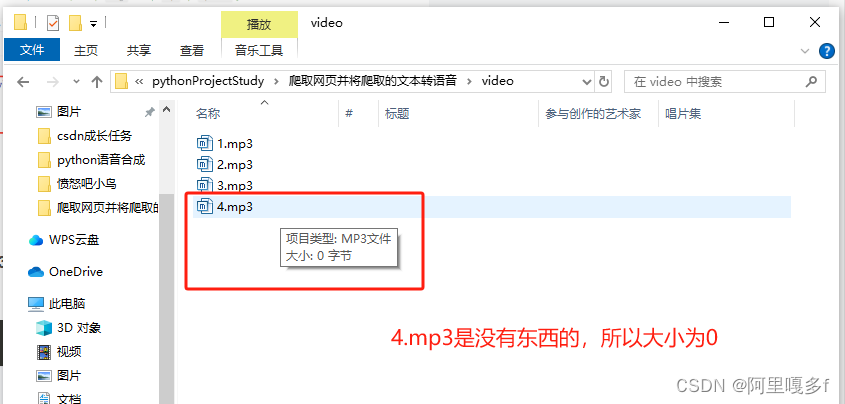
如果运行完成后,video中没有看到生成的mp3文件,但是本地磁盘的项目目录有,就右键点一下Reload from Disk
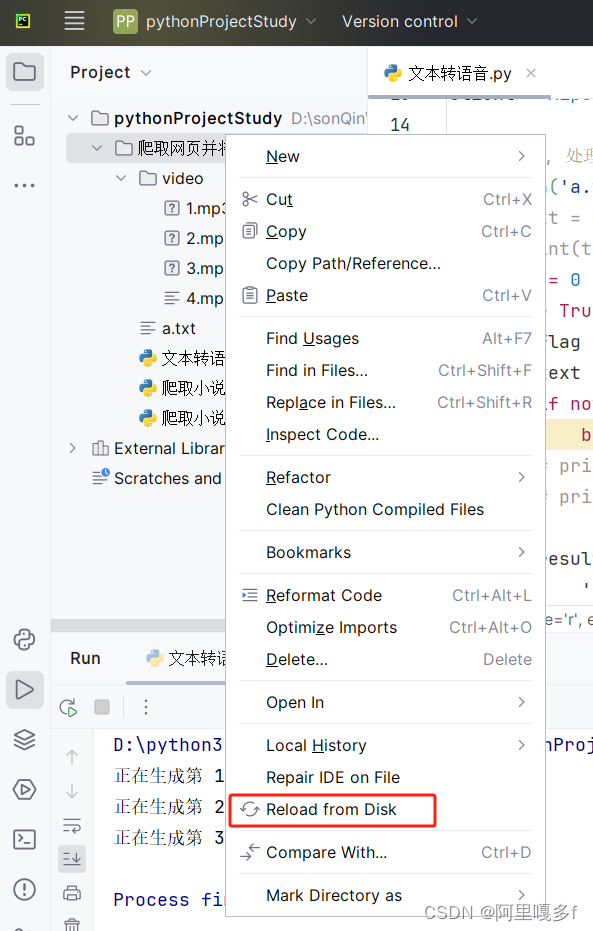
注:爬取小说内容.py模块可删除!!!
如有需要代码,可在资源中自行下载
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » python实战(爬取一个小说网站,将爬取的文本转换为语音)

发表评论 取消回复