在处理大文件上传时,切片上传是提高效率与用户体验的关键技术之一。下面将详细介绍如何在前端利用Vue框架与Node.js后端配合,实现这一功能。
大体流程
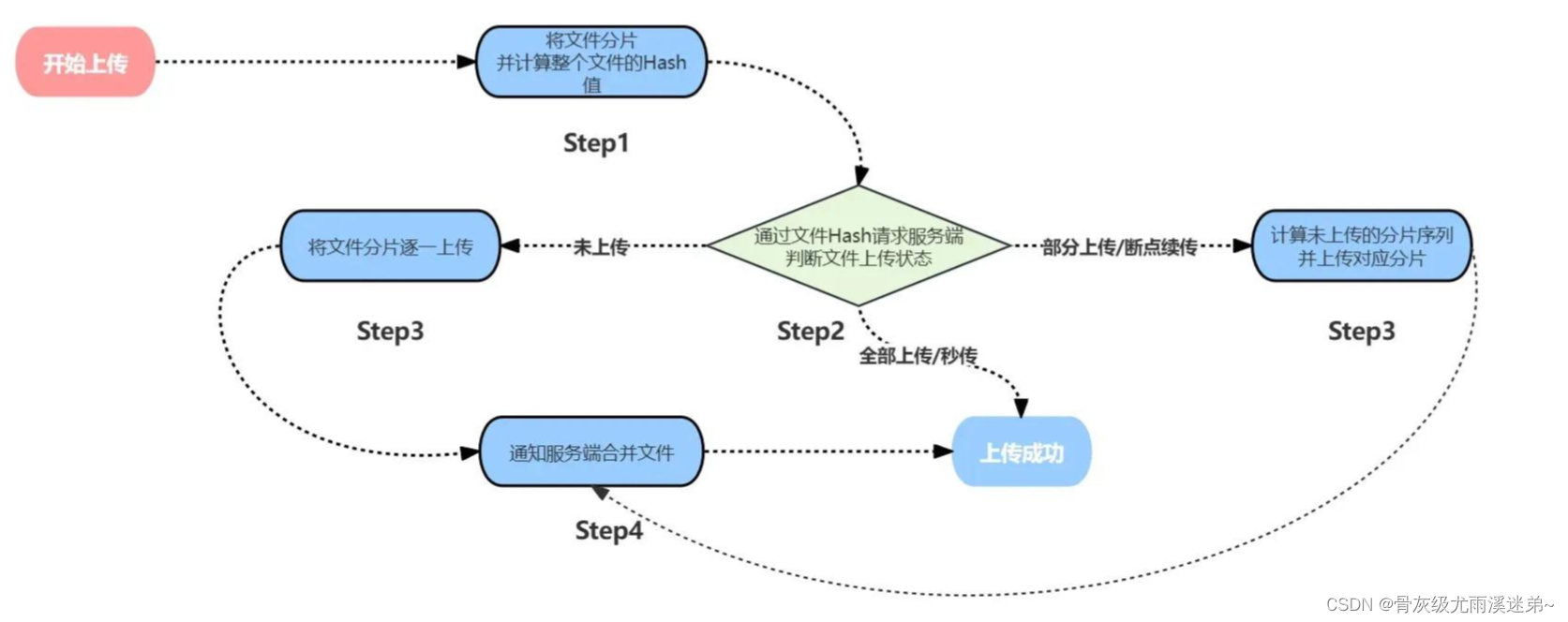
一、文件切片上传
- 通过文件选择器获取用户选择文件
<template>
<div>
<input label="选择附件" type="file" @change="handleFileChange" />
<div @click="handleUpload">上传附件</div>
</div>
</template>
<script>
handleFileChange(e) {
this.container.file = e.target.files;
}
</script>
- 设定分片大小,将文件切片成多个文件块
<script>
const SIZE = 10 * 1024 * 1024; // 切片大小
// 生成文件切片
createFileChunk(file, size = SIZE) {
const fileChunkList = [];
let cur = 0;
while (cur < file.size) {
fileChunkList.push({ file: file.slice(cur, cur + size) });
cur += size;
}
return fileChunkList;
},
</script>
- 通过 spark-md5插件以及借助 web-worker 来并行生成文件的唯一Hash标识
<script>
//入参:fileChunkList ,对应 的文件切片数组
calculateHash(fileChunkList) {
return new Promise(resolve => {
this.container.worker = new Worker("/hash.js");
//将 fileChunkList 通过 postMessage 发送给 web-worker
this.container.worker.postMessage({ fileChunkList });
//接收 web-worker 返回的消息
this.container.worker.onmessage = e => {
const { hash } = e.data;
if (hash) {
resolve(hash);
}
};
});
}
</script>
工具函数 hash.js
// 导入脚本
self.importScripts("/spark-md5.min.js");
// 生成文件 hash 代码
self.onmessage = e => {
const { fileChunkList } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
let count = 0;
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(fileChunkList[index].file);
reader.onload = e => {
count++;
spark.append(e.target.result);
if (count === fileChunkList.length) {
self.postMessage({
hash: spark.end()
});
self.close();
}
// 递归计算下一个切片
loadNext(count);
};
};
loadNext(0);
};
- 点击上传附件按钮 开始对大文件进行切片
// 调用后端接口上传切片
async uploadChunks() {
const requestList = this.data
.map(({ chunk,hash }) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("hash", hash);
formData.append("filehash", this.container.hash);
return { formData };
})
.map(async ({ formData }) =>
//发起后端请求
axios.post({
url: "XXXXXXXX",
data: formData
})
);
await Promise.all(requestList); // 并发请求后端api
}
const async handleUpload() {
if (!this.container.file) return;
const fileChunkList = this.createFileChunk(this.container.file);
this.container.hash = await this.calculateHash(fileChunkList);
this.data = fileChunkList.map(({ file },index) => ({
chunk: file,
hash: this.container.hash + "-" + index // hash + 数组下标
}));
await this.uploadChunks();
}
二、文件秒传
第一步:和文件切片前几步骤相同,先获取 改文件对应的文件切片 以及 hash 值
第二步:调用后端接口查询已经成功上传的文件hash值,如果都已经上传过该文件,前端显示上传完成
三、断点续传
第一步:和文件切片前几步骤相同,先获取 改文件对应的文件切片 以及 hash 值
第二步:调用后端接口查询已经成功上传的文件hash值,前端将已经上传过的hash值过滤得到未上传的文件hash值
第三步:将未上传的文件hash值列表,调用上传接口上传
四、关于后端实现(Node版)
- 接收切片
const http = require("http");
const path = require("path");
const fse = require("fs-extra");
const multiparty = require("multiparty");
const server = http.createServer();
const UPLOAD_DIR = path.resolve(__dirname, "..", "target"); // 大文件存储目录
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
// 使用 multiparty 包处理前端传来的 FormData
// 在 multiparty.parse 的回调中,files 参数保存了 FormData 中文件,fields 参数保存了 FormData 中非文件的字段
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
return;
}
const [chunk] = files.chunk;
const [hash] = fields.hash;
const [filehash] = fields.filehash;
const chunkDir = path.resolve(UPLOAD_DIR, filehash);
// 切片目录不存在,创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
// fs-extra 专用方法,类似 fs.rename 并且跨平台
// fs-extra 的 rename 方法 windows 平台会有权限问题
await fse.move(chunk.path, `${chunkDir}/${hash}`);
res.end("received file chunk");
});
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
- 合并切片
//通过readStream流读文件
const pipeStream = (path, writeStream) =>
new Promise(resolve => {
const readStream = fse.createReadStream(path);
readStream.on("end", () => {
fse.unlinkSync(path);
resolve();
});
readStream.pipe(writeStream);
});
//合并切片
const mergeFileChunk = async (filePath, filehash, size) => {
const chunkDir = path.resolve(UPLOAD_DIR, filehash);
const chunkPaths = await fse.readdir(chunkDir);
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
await Promise.all(
chunkPaths.map((chunkPath, index) =>
pipeStream(
path.resolve(chunkDir, chunkPath),
// 指定位置创建可写流
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
)
);
fse.rmdirSync(chunkDir); // 合并后删除保存切片的目录
};
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于Vue3.0 & Node.js 的 大文件切片上传、秒传、断点续传实现方案梳理

发表评论 取消回复