目录

以上是mac硬件配置
1、下载安装包
网盘:
Flink 安装包 https://pan.baidu.com/s/1IN62_T5JUrnYUycYMwsQqQ?pwd=gk4e
Flink 已配置好的包 https://pan.baidu.com/s/1j05iID60YBGeGgR8d5e2eA?pwd=k2pd
2、解压及配置
# 解压安装包
mv ~/Download/flink-1.16.3-bin-scala_2.12.tgz /opt/module
cd /opt/module
tar -zxvf flink-1.16.3-bin-scala_2.12.tgz
mv flink-1.16.3 flink
cd flink
# 将运行flinksql读取jdbc和hive相关的jar添加到lib中去
cp /opt/module/hive/lib/antlr-runtime-3.5.2.jar ./lib
cp /opt/module/hive/lib/hive-exec-3.1.3.jar ./lib
cp ~/Download/mysql-connector-java-8.0.11.jar ./lib
cp ~/Download/flink-sql-connector-hive-3.1.3_2.12-1.19.0.jar ./lib
cp ~/Download/flink-connector-jdbc-1.16.3.jar ./lib
# 修改配置,本地调试只需关注下面的配置,根据实际情况修改
vim conf/flink-conf.yamljobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.bind-host: localhost
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: localhost
taskmanager.host: localhost
taskmanager.memory.process.size: 4096m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
# webui的端口,这里修改是因为与其他应用的端口冲突了
rest.port: 8090
# webui的端口可选范围
rest.bind-port: 8090-8990
# 页面上提交任务
web.submit.enable: true
# 页面上取消任务
web.cancel.enable: truevim bin/config.sh
# 在顶部添加如下配置
# 因为我按照了多个版本的java虚拟机
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk8/Contents/Home
# 我在全局环境变量中配置了,但是运行flinksql时还是报错说找不到hadoop相关jar里面的类,故在此添加
export HADOOP_CLASSPATH=`hadoop classpath`3、启动&测试
./bin/start-cluster.sh
# 到log目录查看启动日志,如有报错则需根据提示进行解决
tail -999f log/flink-shenxiang-standalonesession-0-*.local.log
# 启动成功可以看看webui,在浏览器中访问http://localhost:8090/
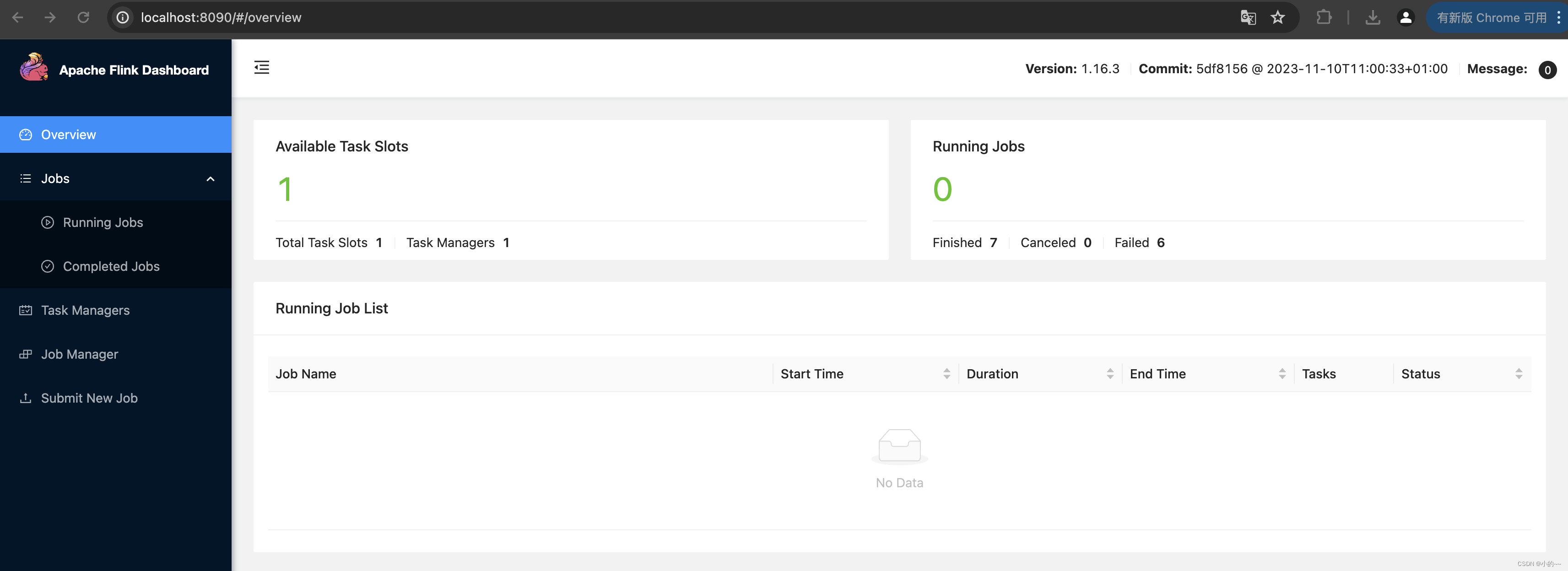
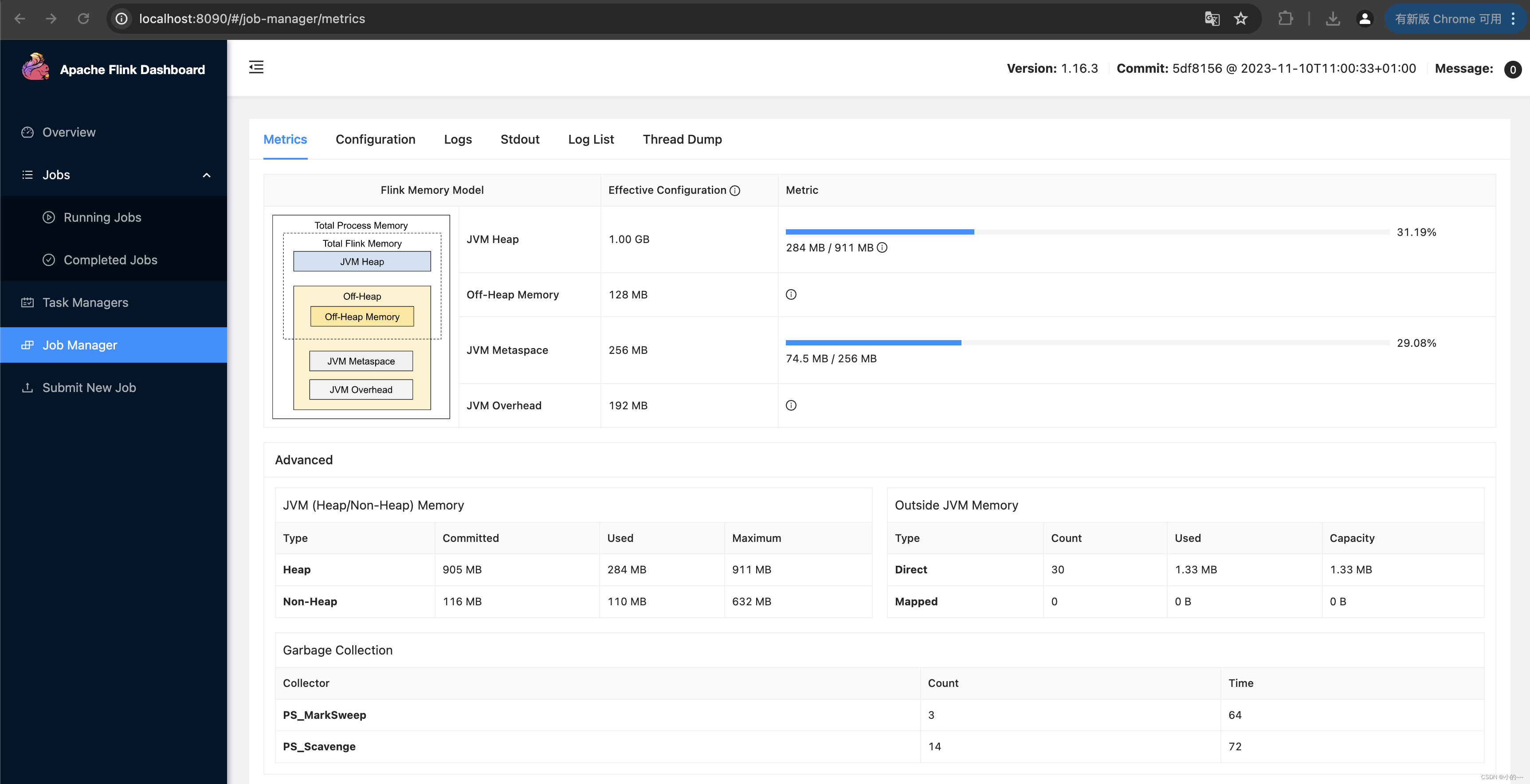
# 跑一下测试的jar,出现如下图则表示成功
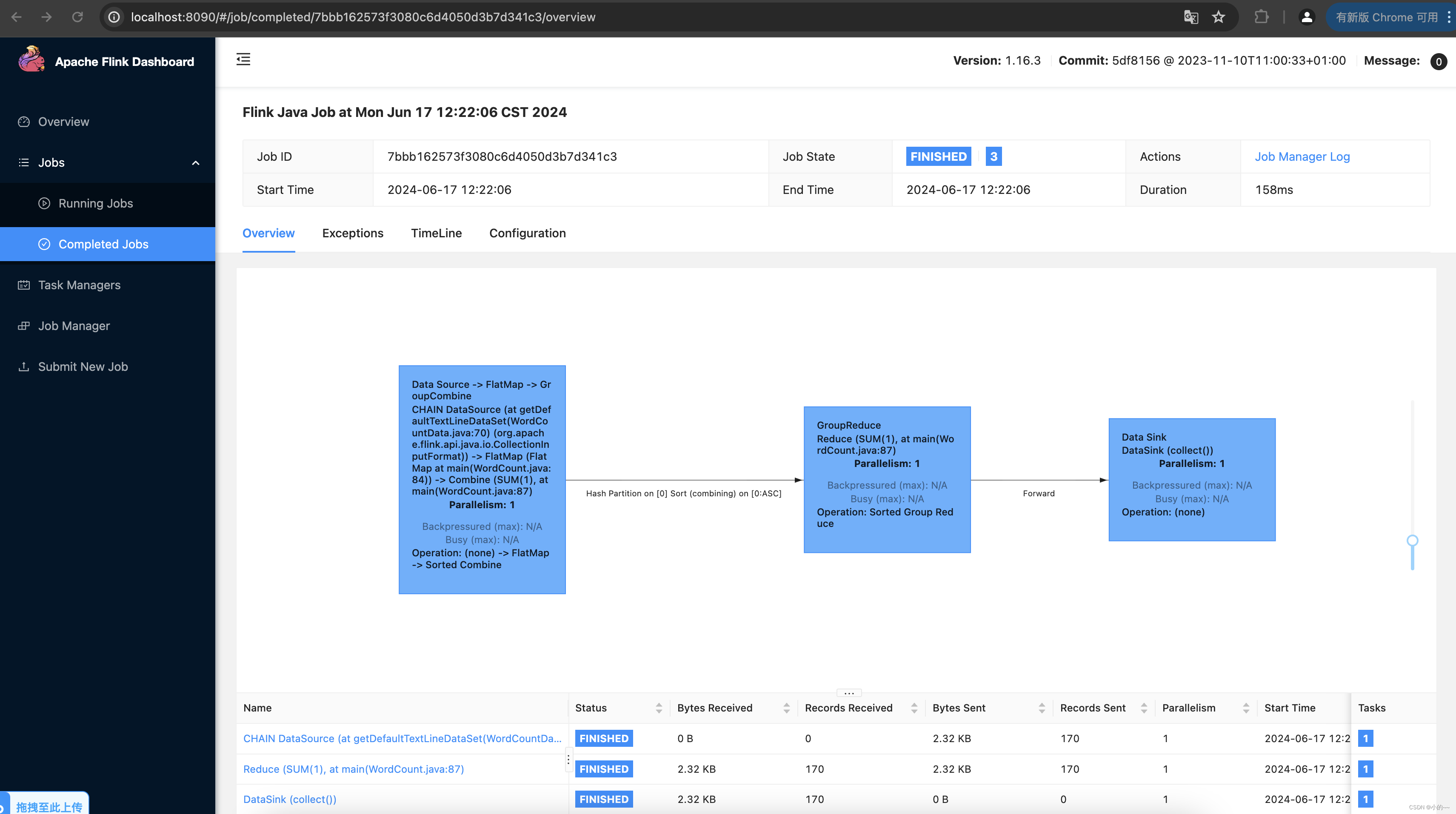
# 批任务
./bin/flink run examples/batch/WordCount.jar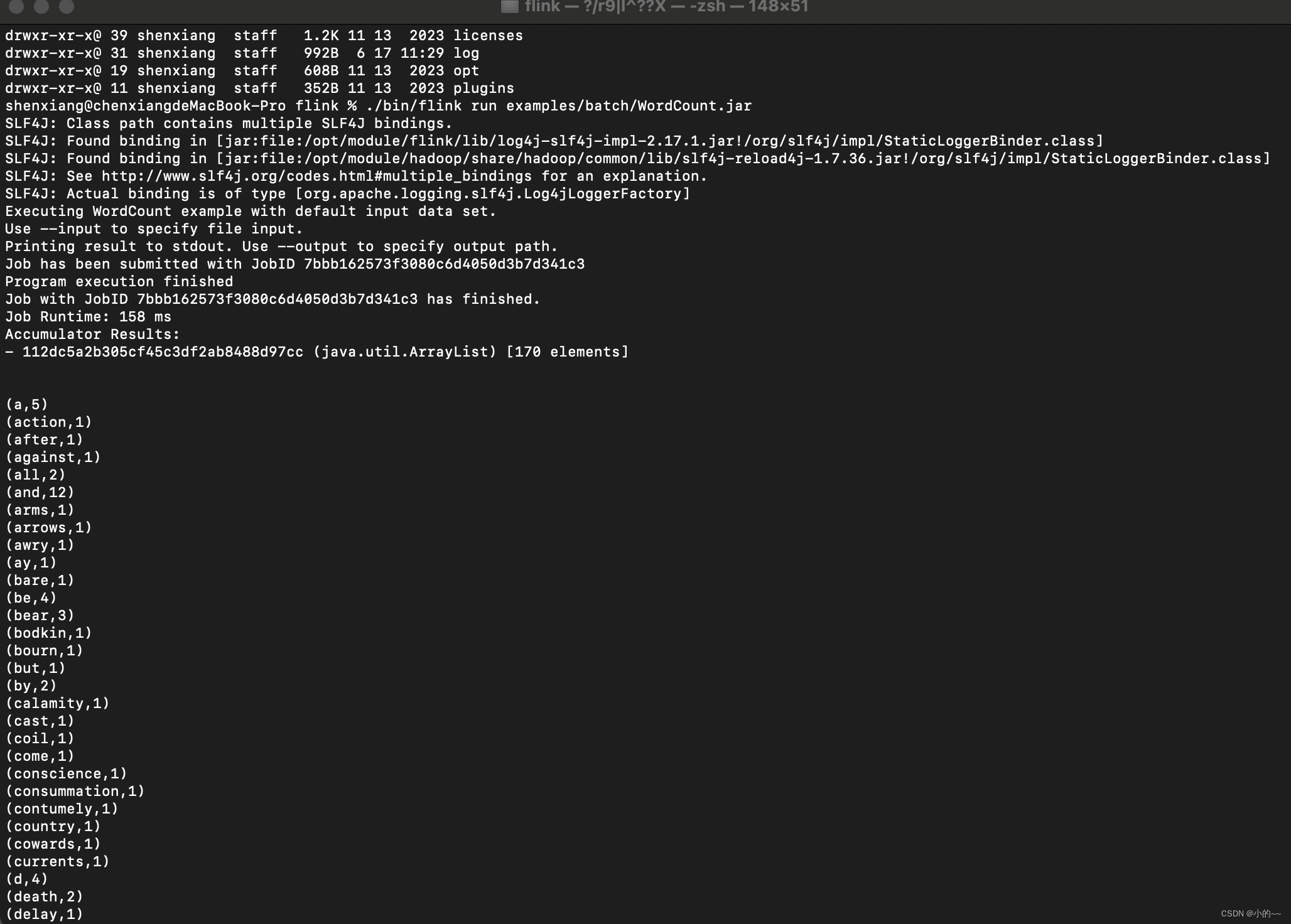
# 流任务
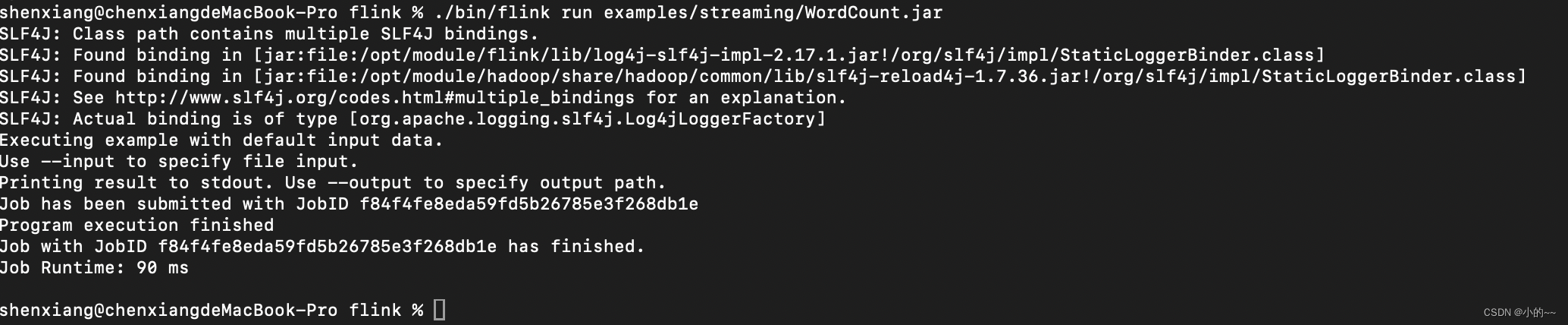
./bin/flink run examples/streaming/WordCount.jar
# 通过下面的日志查看运行结果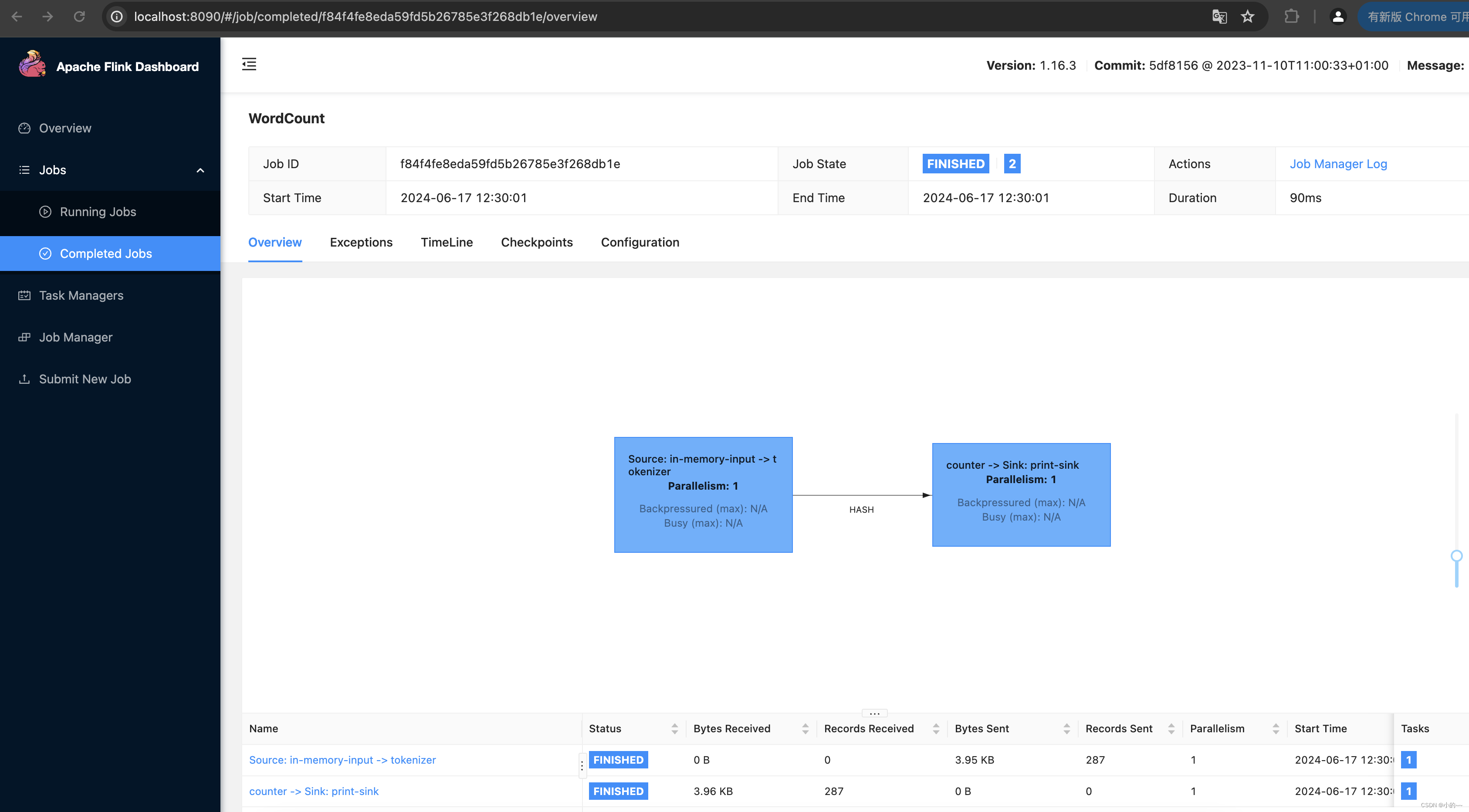

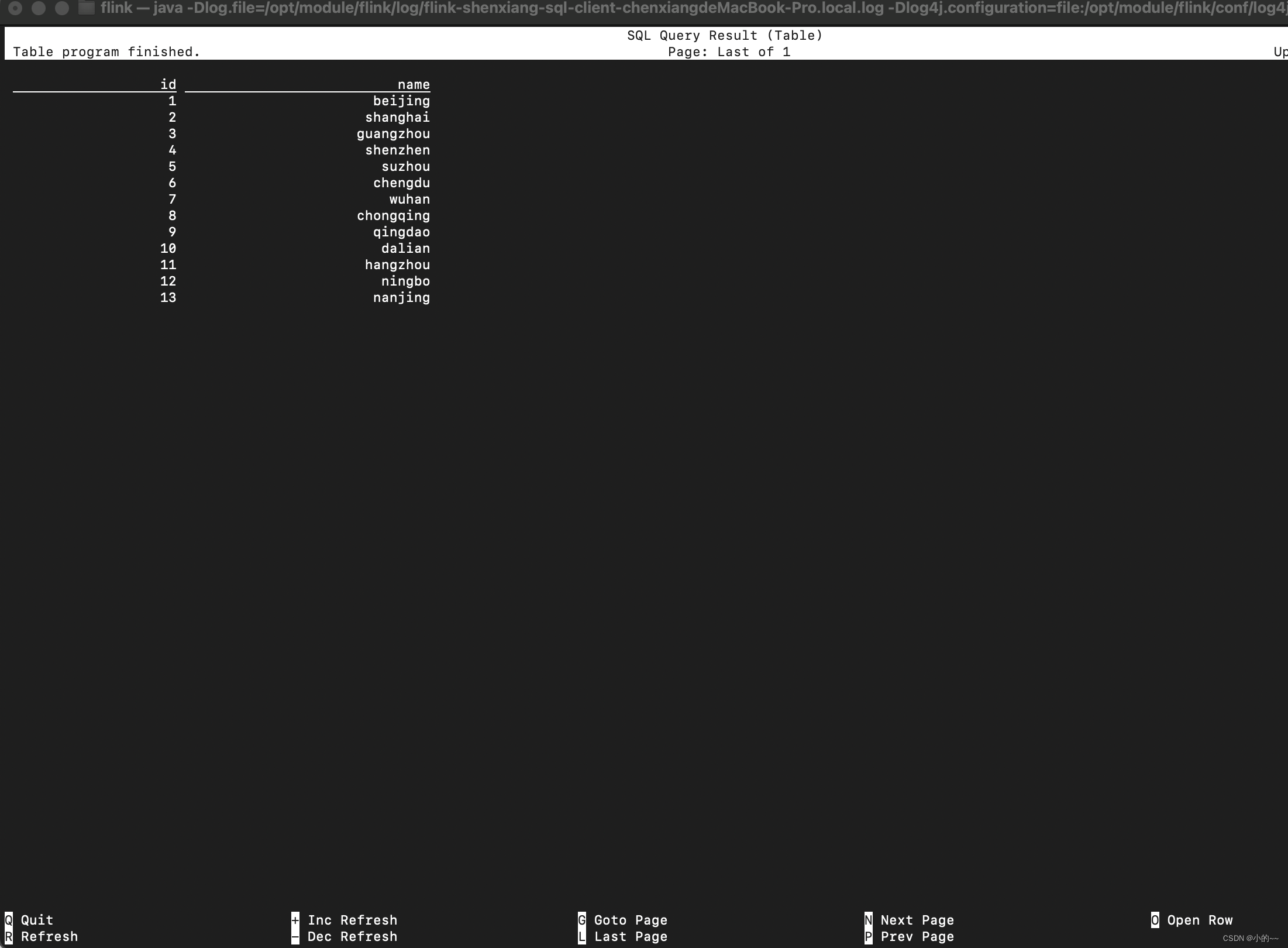
4、测试FlinkSQL读取hive数据
# 打开sql-client模式
./bin/sql-client.sh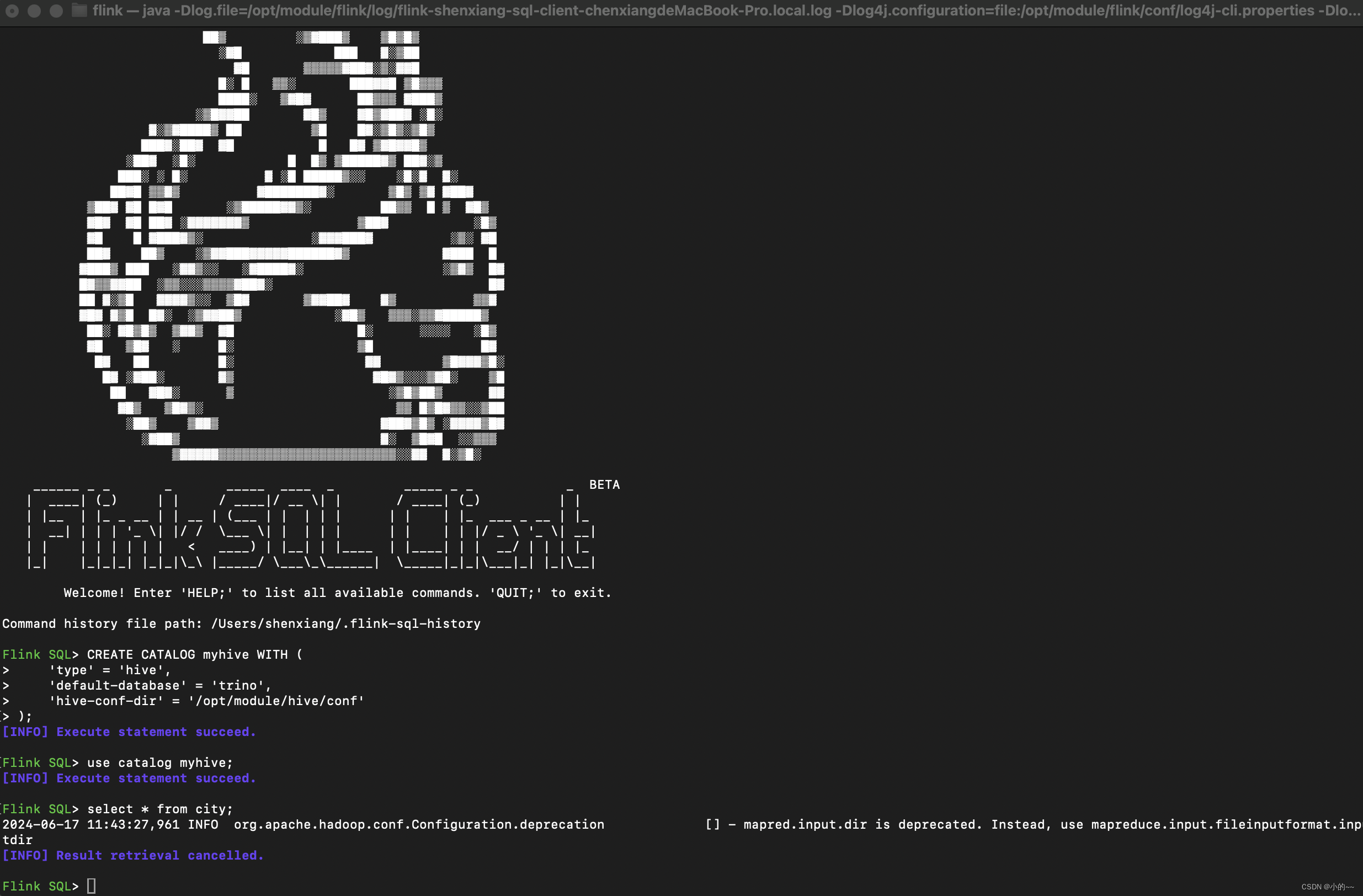
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Mac M3 Pro 部署Flink-1.16.3

发表评论 取消回复