小罗碎碎念
本期推文主题:人工智能在头颈癌中的最新研究进展
头颈癌是一组发生在头部和颈部区域的恶性肿瘤的统称,主要包括以下几种类型的癌症:
- 喉癌(Laryngeal Cancer):发生在喉部,包括声带癌和非声带癌。
- 口腔癌(Oral Cancer):发生在口腔内,如唇癌、舌癌等。
- 鼻咽癌(Nasopharyngeal Cancer):发生在鼻咽部位,即鼻腔后部和咽喉上部。
- 口咽癌(Oropharyngeal Cancer):发生在口咽部位,包括扁桃体癌和舌根癌。
- 下咽癌(Hypopharyngeal Cancer):发生在下咽部位,即食道入口处。
- 鼻窦癌(Sinonasal Cancer):发生在鼻腔和鼻窦的恶性肿瘤。
- 唾液腺癌(Salivary Gland Cancer):发生在唾液腺组织中的癌症,包括腮腺、颌下腺和舌下腺。
- 甲状腺癌(Thyroid Cancer):虽然甲状腺位于颈部,但有时也被归类于头颈癌。
头颈癌的常见风险因素包括吸烟、饮酒、病毒感染(如人乳头状瘤病毒HPV)、长期暴露于有害化学物质和遗传因素等。头颈癌的治疗通常包括手术、放疗、化疗或这些方法的组合。早期诊断和治疗对提高患者的生存率和生活质量至关重要。

一、仅依赖于诊断标签训练AI,大规模筛查巴雷特食管

文献概述
这篇文章是关于使用
弱监督深度学习技术在组织病理学中大规模筛查巴雷特食管(Barrett’s esophagus, BE)的研究。
巴雷特食管是食道腺癌(esophageal adenocarcinoma, EAC)的癌前状况,及时检测可以提高患者的生存率。
目前,CytospongeTFF3测试是一种非内镜的微创程序,用于诊断巴雷特食管中的肠上皮化生(intestinal metaplasia, IM),但它依赖于病理学家对H&E染色和免疫组化生物标记TFF3的评估。这种资源密集型的临床工作流程限制了在高危人群中进行大规模筛查。
为了提高筛查能力,研究者提出了一种基于深度学习的方法,直接从常规H&E染色切片中检测巴雷特食管。这种方法仅依赖于诊断标签,消除了昂贵的局部专家注释的需求。
研究者在两个临床试验数据集上训练并独立验证了他们的方法,总共涉及1866名患者。在发现和外部测试数据集上,H&E模型的AUROC(接受者操作特征曲线下面积)分别达到了91.4%和87.3%,与TFF3模型相当。研究者提出的半自动化临床工作流程可以将病理学家的工作量减少到48%,而不会牺牲诊断性能,使病理学家能够优先处理高风险病例。
文章还讨论了早期癌症检测的重要性,以及如何通过深度学习提高筛查覆盖率。研究者使用了一种基于多实例学习(MIL)范式的弱监督深度学习方法,利用现有的数据集和病理学家的常规诊断报告进行训练,包括同一患者的多个相邻切片的标签。这种方法可以扩展到更大的样本量,以训练更有效和健壮的深度学习模型。
研究者还进行了模型输出的定性、定量和故障模式分析,以确保模型的可解释性,并提出了两种半自动化的机器学习辅助临床工作流程,可以显著减少病理学家的手动工作量,而不会损失诊断性能。
最后,文章通过外部数据集验证了训练模型的泛化能力,并讨论了将深度学习模型整合到当前临床工作流程中的潜力,以及如何通过半自动化工作流程减少病理学家的工作量,使他们能够专注于高风险病例,从而促进巴雷特食管的大规模筛查。
此外,这种方法不需要额外的努力来创建局部专家注释,意味着未来的模型可以随着新的诊断数据的生成而不断实时训练,会导致训练模型性能的进一步提高。
重点关注
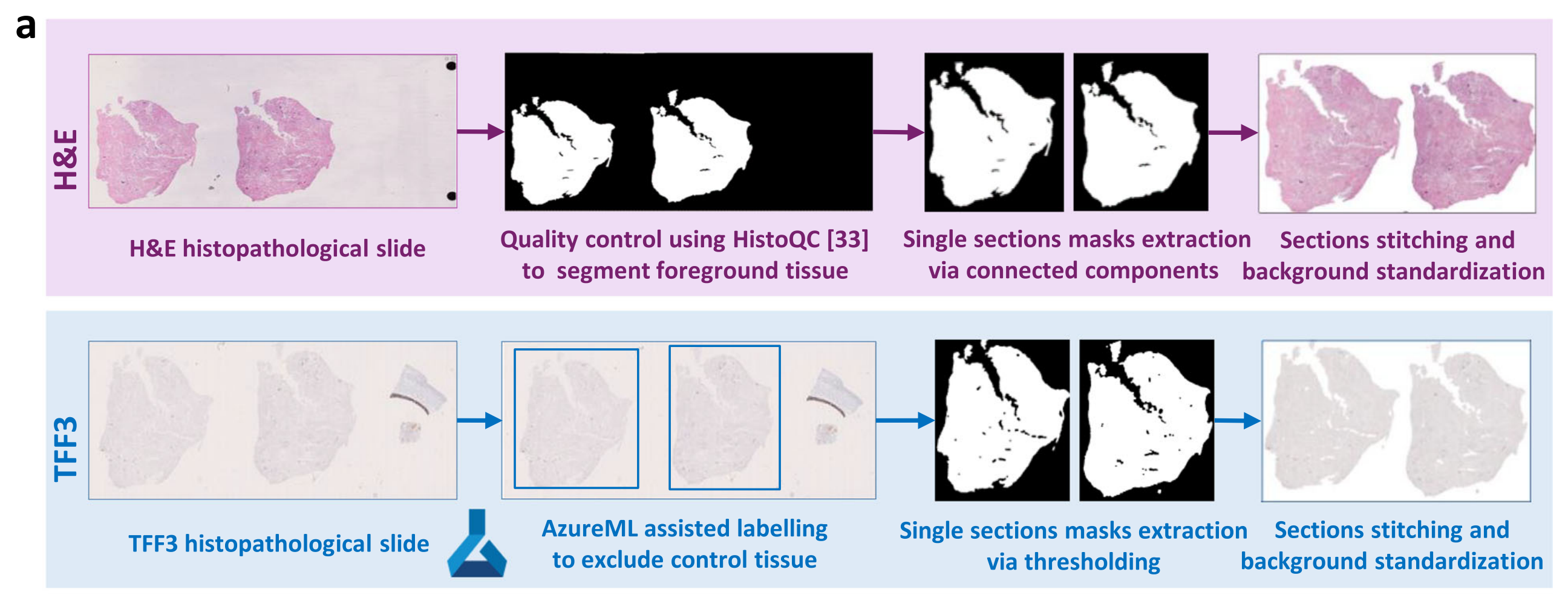
Fig. 1 提供了从H&E(苏木精-伊红染色)和TFF3染色的组织病理学切片中自动检测巴雷特食管(BE)的方法概览,包括数据集预处理、模型训练以及研究中使用的数据。
该方法分为以下几个步骤:
-
切片扫描与预处理:
- a部分说明H&E和TFF3染色的组织病理学切片是从相邻的组织切片扫描得来的。
- 针对H&E和TFF3染色,分别使用不同的预处理流程,这些流程分别用紫色和蓝色的框表示。
-
预处理流程:
- H&E染色的切片预处理包括去除如气泡、阴影、笔迹等不希望的伪影,标准化背景效果,并从TFF3染色的切片中去除控制组织。
- TFF3染色的切片预处理涉及低染色对比度的改善,以及自动或半自动的方式来获取组织区域的前景掩膜。
-
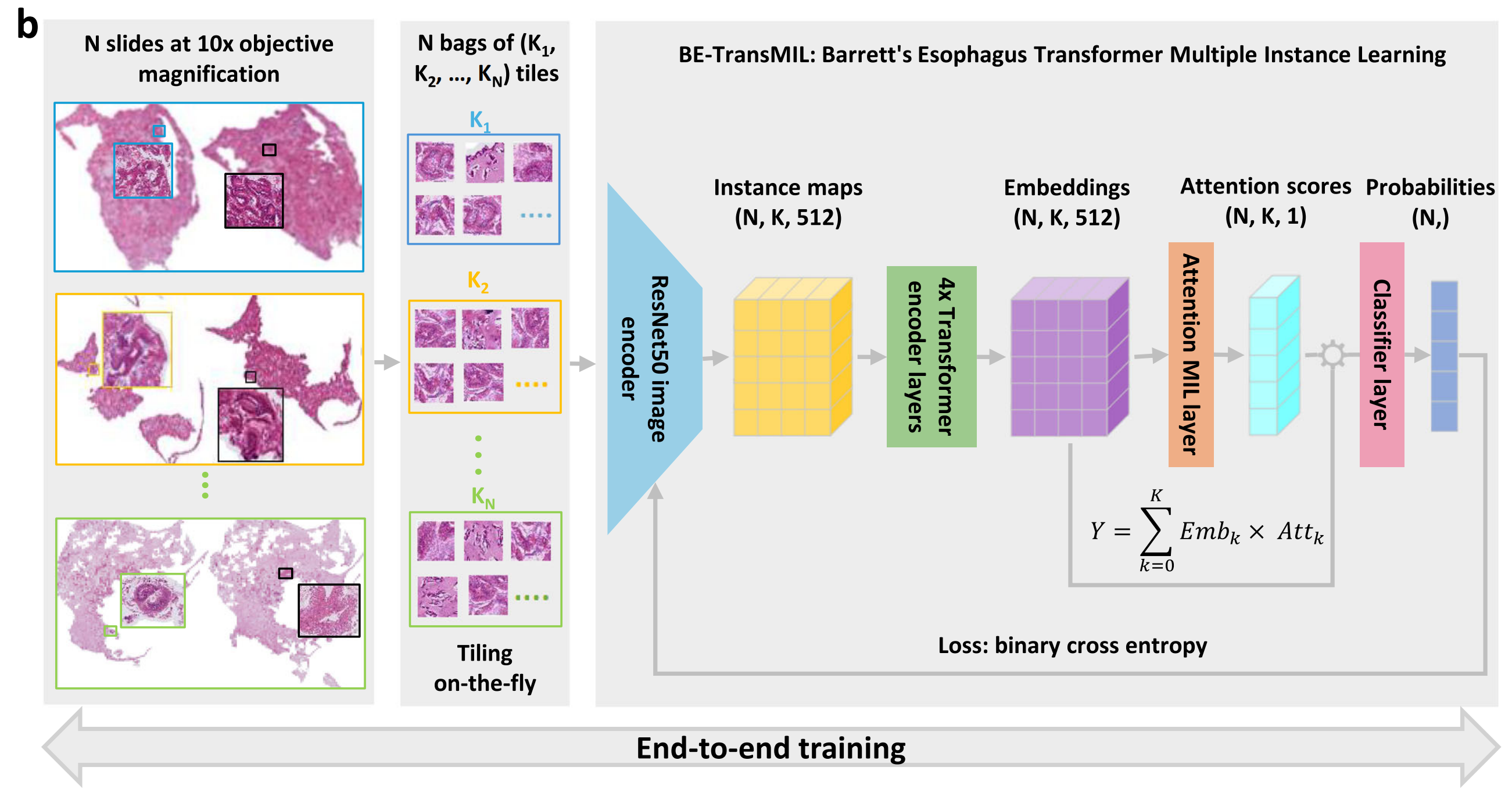
切片分割:
- b部分描述了预处理后的切片会在运行时被动态分割成不重叠的小图块(tiles),这些小图块用于后续的模型训练。
-
模型训练:
- 使用弱监督学习(weakly supervised learning)的BE-TransMIL模型,分别从H&E和TFF3染色的切片中端到端(end-to-end)训练。
- 两种染色的切片采用类似的训练过程,意味着它们会遵循相同的训练协议和参数。
-
模型训练细节:
- 模型训练时,会使用来自全切片图像(whole-slide images, WSIs)的图块。
- 由于单个切片的像素数量巨大(达到千兆像素级别),无法一次性处理整个切片,因此需要将其分割成小块以便计算机视觉编码器处理。
-
模型架构:
- 模型架构包括特征提取器(用于将每个图像图块编码为低维特征图)、依赖性模块(用于捕获切片中各个图块之间的空间依赖性)、注意力MIL池化模块以及全连接分类器层。
-
训练与推理:
- 在训练期间,由于GPU内存大小的限制,只有切片的一个子集(K个图块)被用来训练。
- 在评估时,使用切片中的所有前景组织图块来计算模型输出。
Fig. 1 展示了一个自动化的流程,从原始的染色切片到分割和训练深度学习模型,最终用于检测巴雷特食管。这个过程减少了对专家手动注释的依赖,并且提高了病理诊断的效率和可扩展性。
二、AI赋能“磁共振+质谱”,揭示特征性代谢组图谱并优化食管鳞状细胞癌的早期检测

文献概述
这篇文章是一项关于食管鳞状细胞癌(ESCC)早期检测的研究,标题为“NMR和MS揭示特征性代谢组图谱并优化食管鳞状细胞癌的早期检测”。
研究背景:
食管癌(EC)是一个全球性的重大公共卫生问题,尤其在中国,超过全球年发病率和死亡率的一半。由于早期症状不明显以及缺乏早期诊断的生物标志物,大多数患者在晚期才被诊断,导致5年生存率仅为21%。
目前诊断ESCC的标准方法依赖于内窥镜结合组织病理学,但这种方法具有侵入性,降低了患者的依从性。因此,迫切需要开发可靠、非侵入性、易于获取且负担得起的ESCC早期检测工具。
研究方法和发现:
研究团队采用了核磁共振(NMR)和质谱(MS)技术,对来自三家医院的560名参与者的1,153个匹配的ESCC组织、正常粘膜、术前和术后一周的血清和尿液样本进行了代谢组学分析。
通过机器学习和加权基因共表达网络分析(WGCNA),研究发现**“丙氨酸、天冬氨酸和谷氨酸代谢”在ESCC发展过程中普遍存在异常,并且在16个血清和10个尿液代谢特征中得到一致的识别**。
研究结果:
NMR基础的简化小组,包括任何五个血清或尿液代谢物,表现出比临床血清肿瘤标志物更高的性能(AUC分别为0.984和0.930),并且在测试集中有效地区分了早期ESCC(血清准确度=0.994,尿液准确度=0.879)。
研究结果表明,基于NMR的生物流体筛查可以揭示ESCC的特征性代谢事件,并且对于早期检测是可行的。
研究意义:
这项研究为ESCC的早期诊断提供了新的生物标志物,并展示了一种基于NMR的生物流体筛查方法,这种方法不仅能够准确反映组织代谢变化的特征,而且还具有足够的临床敏感性,可用于ESCC的早期诊断和筛查。这对于改善ESCC患者的治疗结果和提高生存率具有重要意义。
重点关注
图1展示了整体研究设计的框架图。在这个研究中,共有来自三个中心的560名参与者。
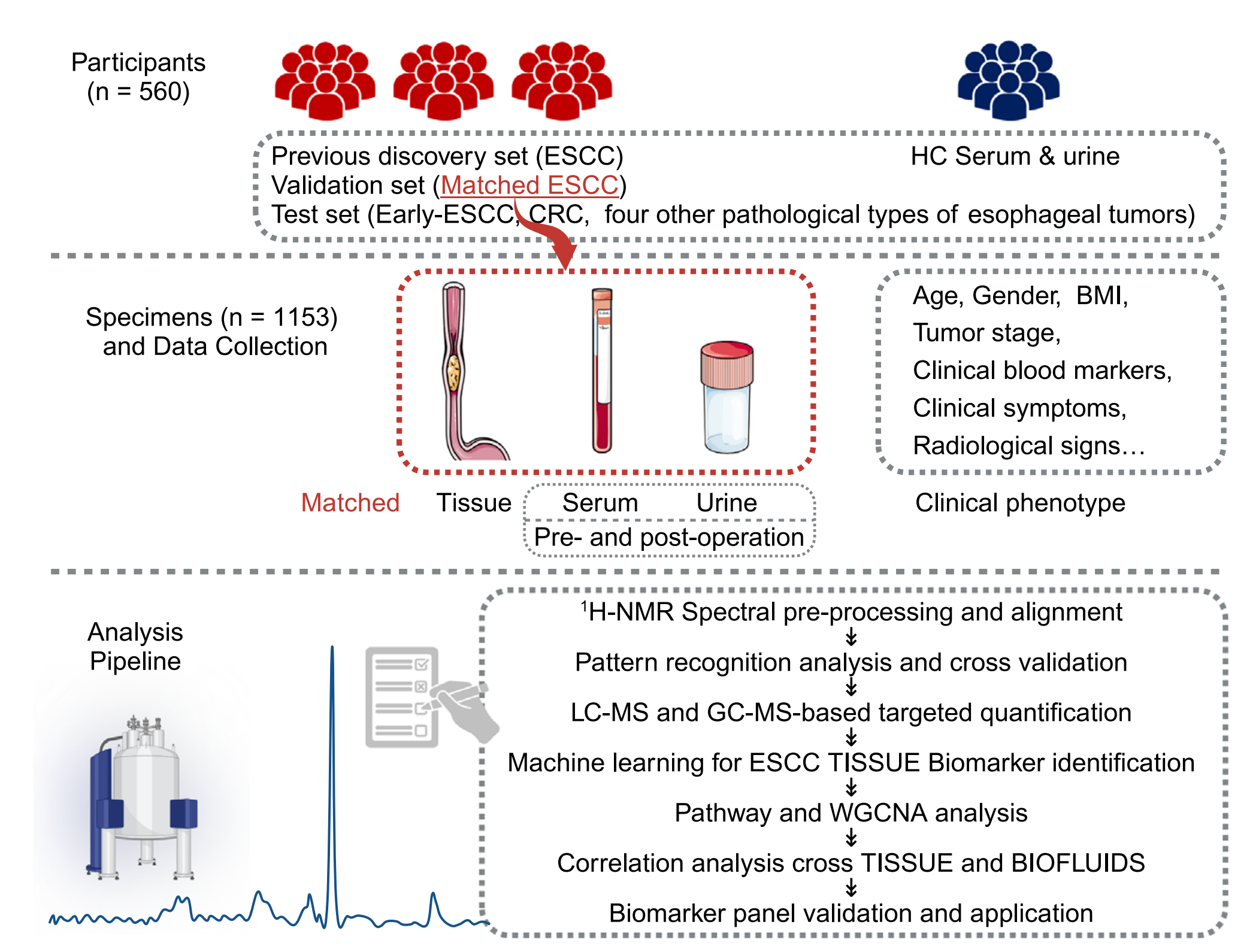
研究过程如下:
- 样本收集:从所有参与者那里收集了组织、血清和尿液样本。
- 代谢组学分析:
- 1H-NMR:即质子核磁共振,一种分析生物样本中代谢物的技术。
- MS-based metabolomics:基于质谱的代谢组学,另一种用于代谢物分析的技术。
- 数据分析:
- Pattern recognition:模式识别,用于在数据中识别和分类不同的模式或特征。
- Machine learning:机器学习,应用算法和统计模型让计算机系统利用数据来做出预测或决策。
- WGCNA:加权基因共表达网络分析(Weighted Gene Co-expression Network Analysis),一种用于描述基因集之间关系的系统生物学方法,虽然最初是为基因表达数据设计的,但也可适用于代谢物数据。
整个研究设计的目的是通过综合使用1H-NMR和MS技术来分析生物样本,然后利用模式识别、机器学习和WGCNA等分析方法来揭示食管鳞状细胞癌(ESCC)的代谢特征,并优化早期检测方法。通过这种多中心、多平台的研究方法,研究者能够更全面地理解ESCC的代谢变化,并识别出用于早期诊断的生物标志物。
三、用于甲状腺扫描的全自动化机器人超声系统

文献概述
这篇文章是关于一个全自动化的机器人超声系统,用于甲状腺扫描。
这个系统能够在没有人为帮助的情况下扫描甲状腺区域,并识别恶性结节。它使用了人体骨架点识别、强化学习以及力反馈技术来解决定位甲状腺目标的难题。超声探头的方向通过贝叶斯优化动态调整。
在人体参与者的实验结果显示,该系统能够执行高质量的超声扫描,接近临床医生手动扫描的质量。此外,它还有潜力检测甲状腺结节并提供美国放射学会甲状腺影像报告和数据系统(ACR TI-RADS)计算所需的结节特征数据。
文章详细介绍了系统的设计与实现,包括机器人扫描过程的四个阶段:
- 甲状腺搜索(TS)
- 平面内扫描(IPS)
- 平面外扫描(OPS)
- 多视图扫描(MVS)
系统由一个六自由度的UR3机械臂组成,携带线性超声探头、探头固定装置和六轴力/扭矩传感器。系统还包括一个Kinect相机,用于追踪人体骨骼关节的3D视图,并提供操作者监督机器人系统的2D视觉反馈。
研究者还开发了深度学习网络,用于实时分割甲状腺叶和结节,这对于全自动化的机器人甲状腺扫描至关重要。他们使用了两个独立的网络分别进行甲状腺叶和结节的分割任务,并采用了UNet架构生成从提取特征中生成掩模。
文章还讨论了甲状腺搜索和探头定位优化的问题,提出了一种从粗到细的甲状腺定位方法,并使用了深度Q网络(DQN)学习来确定甲状腺的位置。
最后,文章提到了使用FARUS系统对19名患者进行的结节分类研究,并将FARUS生成的分类与专业医生的评估进行了比较。研究还涉及了对图像质量的评估,包括使用置信度图、中心误差、方向误差和图像熵等指标。
文章的结论是,尽管FARUS系统在检测和数据收集方面显示出了可行性和潜力,但仍需要进一步的临床研究来评估其作为筛查工具的安全性。作者指出,未来的工作需要改进FARUS系统,特别是针对小尺寸和低对比度结节的检测能力。
重点关注
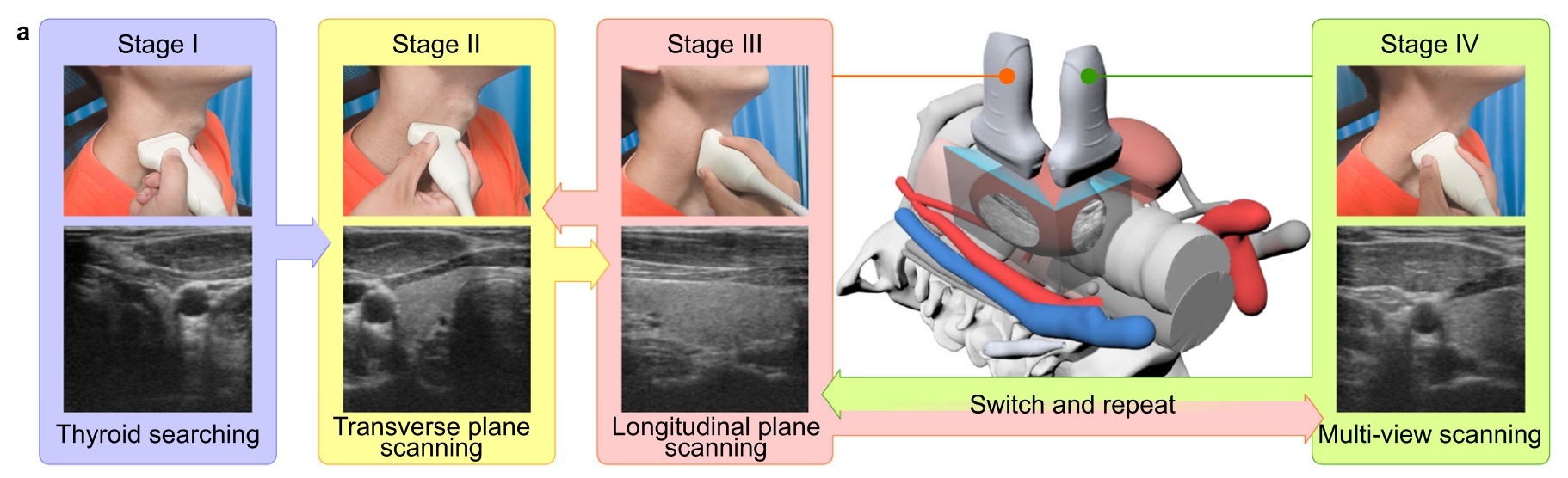
Fig. 1 描述了甲状腺扫描过程和提出的全自动化机器人超声系统(FARUS)。
a 展示了临床医生使用的四阶段甲状腺扫描程序:
- Stage I:医生在甲状腺软骨下方放置超声探头,并在超声图像中找到甲状腺叶。
- Stage II:医生执行从胸骨到舌骨的平面内扫描(IPS),并反向扫描。
- Stage III:医生执行平面外扫描(OPS)以筛查甲状腺疾病。
- Stage IV:医生检查甲状腺的多视图。
b-d 展示了全自动化控制策略的控制架构,用于机器人甲状腺超声成像:
- 初始阶段,通过人体骨骼规划初步扫描路径。
- 然后使用强化学习和甲状腺分割完成甲状腺搜索过程。
- 使用预训练的腺体分割模型和弱监督的结节分割模型分别进行腺体和结节的识别。
- 在整个扫描过程中,使用贝叶斯优化来调整扫描角度。
- 另外,结合IPS和OPS对疑似结节区域执行多角度扫描。
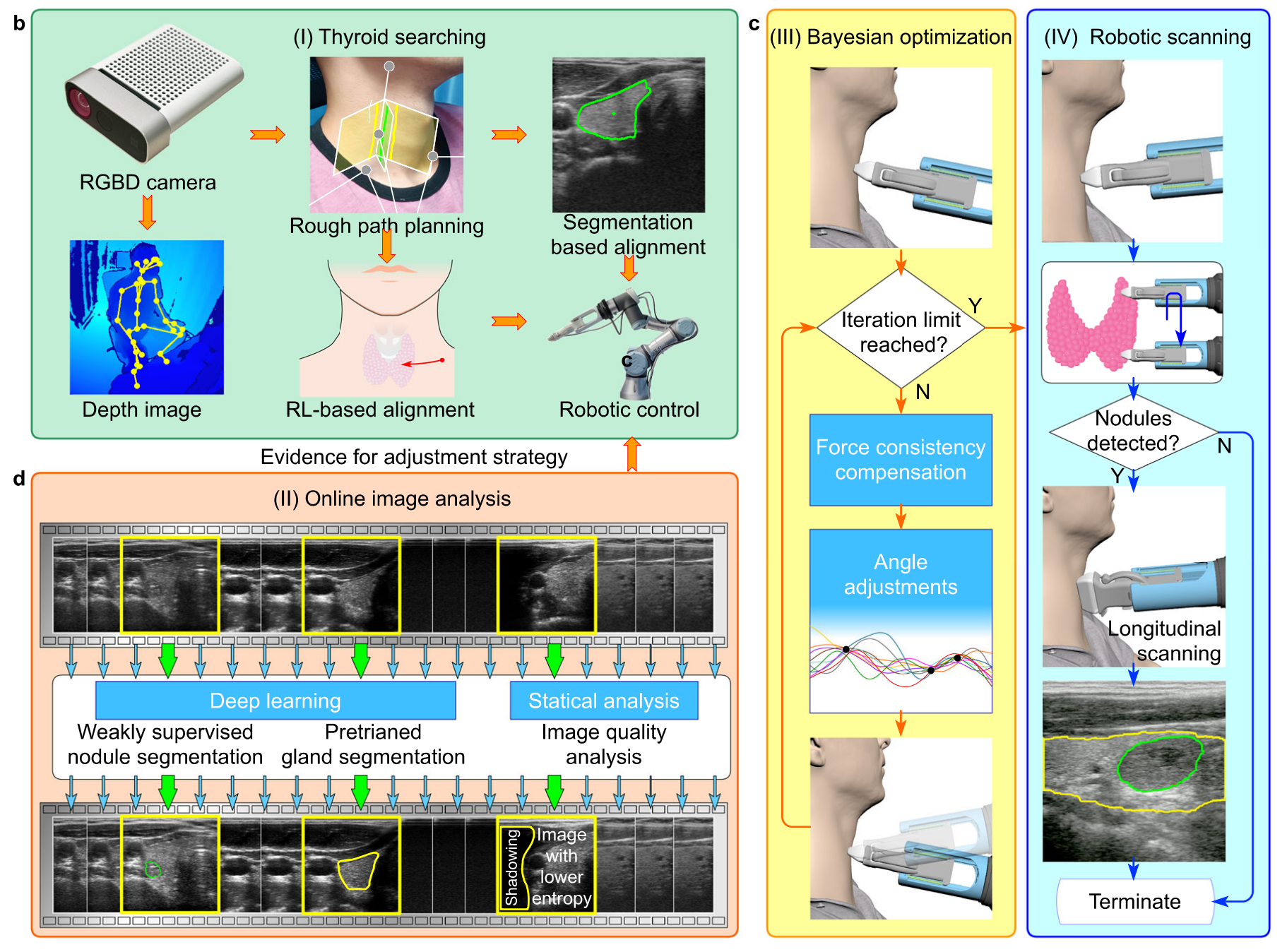
e 提供了实验设置的概览。
f 展示了FARUS系统能够根据结节的关键特征估计TI-RADS等级。
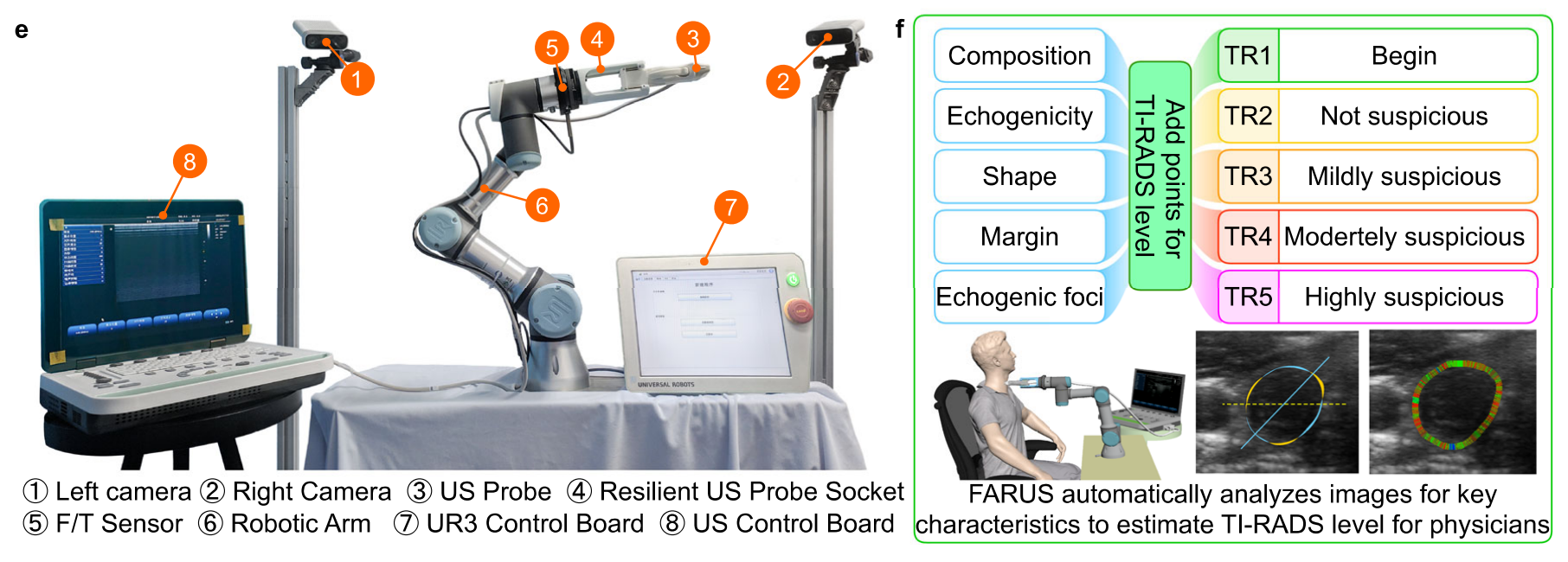
整体而言,Fig. 1 强调了FARUS系统的自动化程度,从扫描路径的规划到甲状腺的搜索、识别和结节的评估,整个过程尽可能地模仿了医生的扫描程序,并通过融合先进的算法和技术,如强化学习、贝叶斯优化和多视图扫描,以提高扫描的准确性和效率。此外,FARUS系统还能够评估结节的TI-RADS等级,这是评估甲状腺结节恶性风险的一个标准化系统。
四、基于蛋白质的个性化预后模型,用于对乳头状甲状腺癌患者的复发风险进行分层

文献概述
这篇文章是一项关于儿童乳头状甲状腺癌(Pediatric Papillary Thyroid Carcinoma, PPTC)的研究,提出了一个基于蛋白质的个性化预后模型,用于对PPTC患者的复发风险进行分层。
研究团队通过机器学习方法,对83名儿童良性甲状腺结节(PB)、85名儿童恶性甲状腺结节(PM)和66名成人恶性甲状腺结节(AM)的临床因素和蛋白质组进行了回顾性收集和评估。通过质谱技术量化了10,426种蛋白质,并发现了在PM与PB和PM与AM之间分别有243和121种显著失调的蛋白质。
研究发现,与其他人相比,PM患者的炎症和免疫系统激活增强。通过机器学习模型,研究者选择了19种蛋白质来预测复发,该模型的准确率达到了88.24%。这项研究生成的基于蛋白质的个性化预后预测模型能够将PPTC患者分为高复发风险和低复发风险组,为临床决策和个体化治疗提供了参考。
文章还讨论了PPTC与成人PTC在临床表现上的差异,指出儿童患者的肿瘤更大,淋巴结转移更多,并且复发率更高,但总体死亡率较低。目前,儿童甲状腺癌的诊断、治疗和预后评估策略尚存在缺陷,特别是与成人相比,儿童患者没有年龄分层和个体化治疗,而是采用统一的治疗策略。
此外,研究还发现PPTC的蛋白质表达具有独特性,与儿童良性结节和成人PTC都不同。通过对失调蛋白的分析,发现PPTC的发展与免疫系统功能的改变有关。研究还利用CIBERSORTx工具分析了儿童样本中的免疫细胞浸润情况,并发现CD8+ T细胞、巨噬细胞、树突细胞和Treg细胞的比例有显著变化。
最后,研究通过随机森林算法选择了19种蛋白质作为模型的特征,并建立了一个预测模型来评估患者的复发风险。模型在训练集和独立测试集上均表现出强大的泛化能力。研究还对19种特征蛋白进行了分析,发现其中一些蛋白质已经报道与甲状腺癌有关,如galectin-3 (LGALS3)、chromogranin-A (CHGA)等,而其他13种蛋白质尚未与甲状腺疾病相关联。
文章强调了这项研究的局限性,包括它是在单个中心进行的回顾性研究,并且需要在未来的研究中对模型进行验证。尽管如此,研究展示了使用蛋白质组学数据对PPTC患者进行分层和预后预测的可行性和重要性。
重点关注
Fig. 1提供了这项研究的概览,包括研究设计和实验工作流程,以及儿童乳头状甲状腺癌(PTC)、儿童良性甲状腺结节和成人PTC患者的纳入和排除标准。
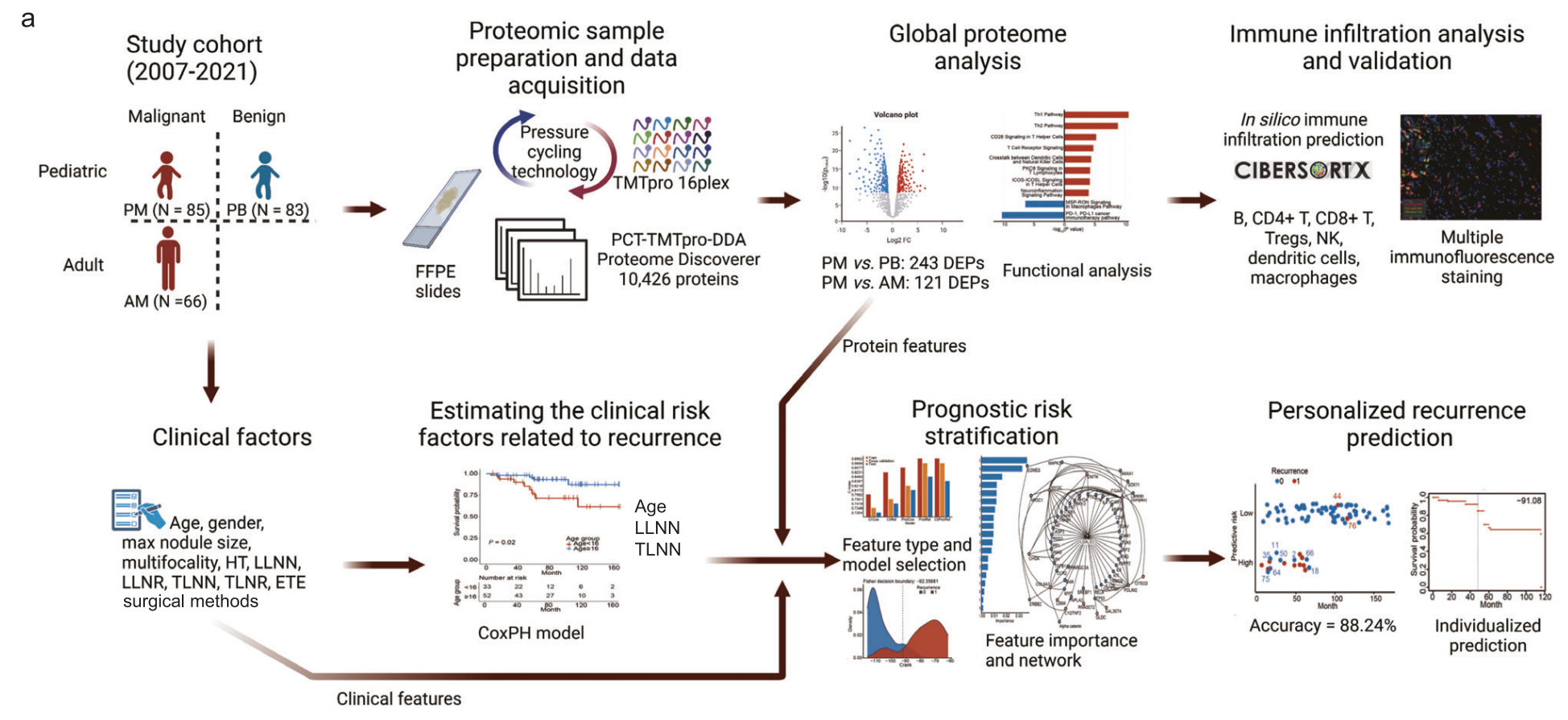
a部分 - 研究设计和实验工作流程:
- 该图展示了研究的步骤,从患者纳入、样本收集、蛋白质组学分析到数据分析和模型建立。
- 使用了Biorender.com这个在线工具来创建图表,它是一个常用于科学插图制作的平台。
- 研究设计包括了对患者群体的详细分层和对实验方法的描述,例如如何收集和评估临床因素和蛋白质组。
b部分 - 纳入和排除标准:
- 这一部分详细说明了研究对象的入选条件和排除条件。
- 对于儿童乳头状甲状腺癌(PTC)患者,纳入标准包括确诊年龄(通常为18岁以下)、组织学证实的乳头状甲状腺癌等。
- 排除标准涉及既往有辐射暴露史、家族史、非乳头状甲状腺癌的恶性肿瘤、随访数据不完整或失去随访的患者。
- 对于儿童良性结节,可能排除了那些不确定恶性潜能的结节。
- 成人PTC患者的纳入和排除标准可能与儿童PTC类似,但年龄限制会不同,通常为18岁以上。
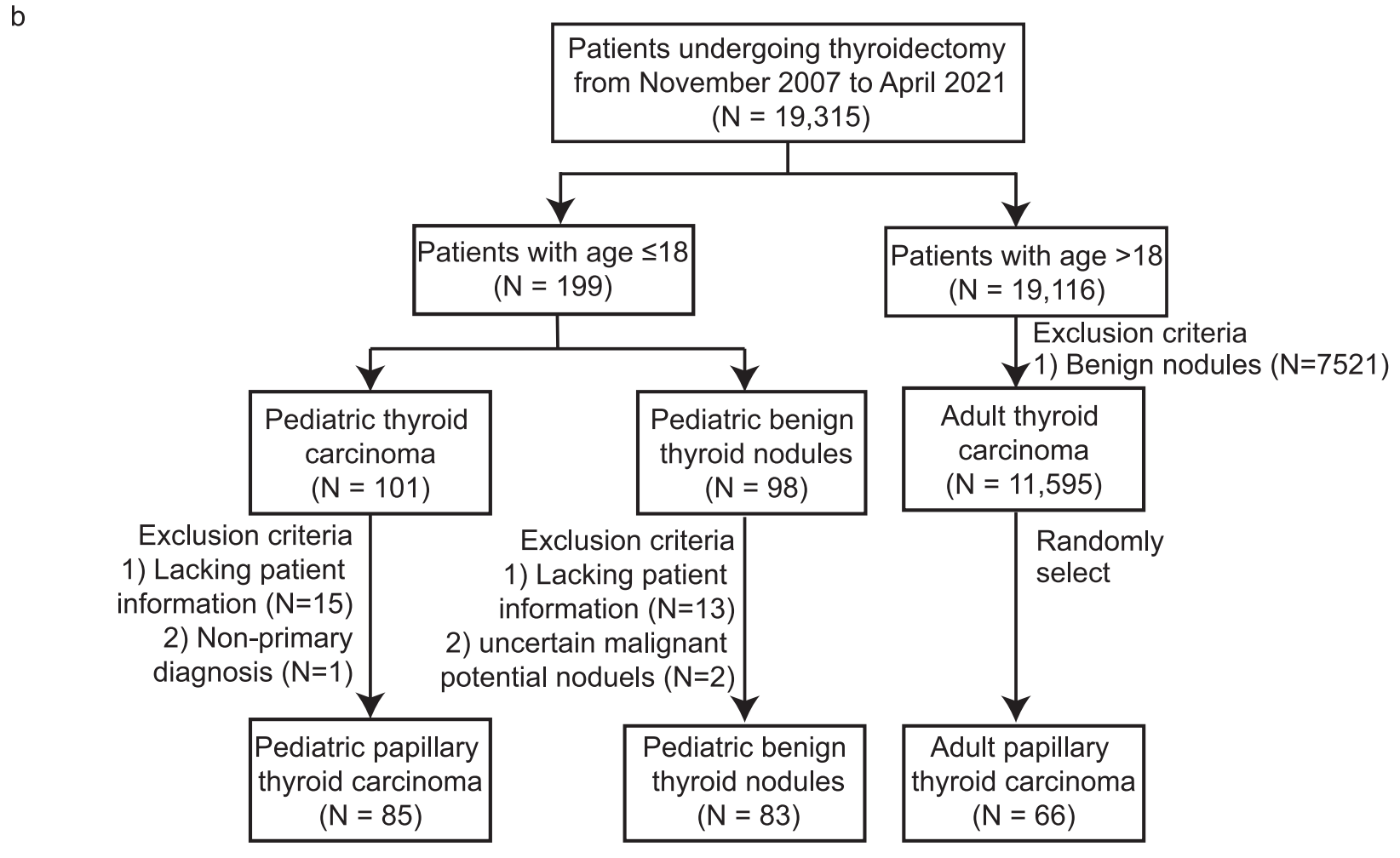
整个Fig. 1是研究方法论的关键组成部分,它帮助读者理解研究的组织结构和如何选择合适的研究对象进行分析。
五、DeepDOF-SE:新型深度学习显微镜平台,为无需载玻片的组织学提供一种经济实惠的解决方案

文献概述
这篇文章介绍了一种名为DeepDOF-SE的新型深度学习显微镜平台,它为无需载玻片的组织学提供了一种经济实惠的解决方案。
DeepDOF-SE通过结合三个关键特性,使得在资源受限的环境中快速扫描完整组织成为可能,这些特性包括:使用廉价的活性荧光染料直接对组织样本进行染色、利用紫外线激发实现光学层析、以及应用深度学习算法扩展焦深,从而快速获取大面积组织的聚焦图像。此外,该平台还采用了半监督生成对抗网络(CycleGAN)来虚拟染色,使荧光图像呈现出类似苏木精-伊红(H&E)染色的外观,便于病理学家进行图像解释,而无需额外的培训。
DeepDOF-SE的开发采用了数据驱动方法,并通过对口腔肿瘤手术切除样本的成像验证了其性能。研究结果表明,DeepDOF-SE能够提供具有诊断重要性的组织学信息,为术中肿瘤边缘评估和低资源环境中的快速、经济的无载玻片组织学平台提供了可能。
文章还讨论了DeepDOF-SE与常规组织学工作流程相比的优势,包括减少了准备时间、基础设施要求和对技术人员的专业培训需求。DeepDOF-SE的构建成本低廉(不到7000美元),使用简便,并且能够快速染色和成像大面积组织样本。此外,文章还详细介绍了DeepDOF-SE显微镜的设置、光学和数字层的实现、网络训练细节、显微镜校准和网络微调、分辨率特性、组织处理和成像方法、虚拟H&E方法以及CycleGAN虚拟染色的网络架构和训练细节。
最后,文章指出DeepDOF-SE作为一种快速、易于使用且成本低廉的组织学替代方法,将进一步在临床环境中进行评估,特别是在术中肿瘤边缘评估和缺乏标准或冷冻切片组织学资源的地区。
重点关注
Fig. 1 提供了 DeepDOF-SE 平台的概览,该平台是一种用于新鲜组织样本无载玻片组织学的设备。
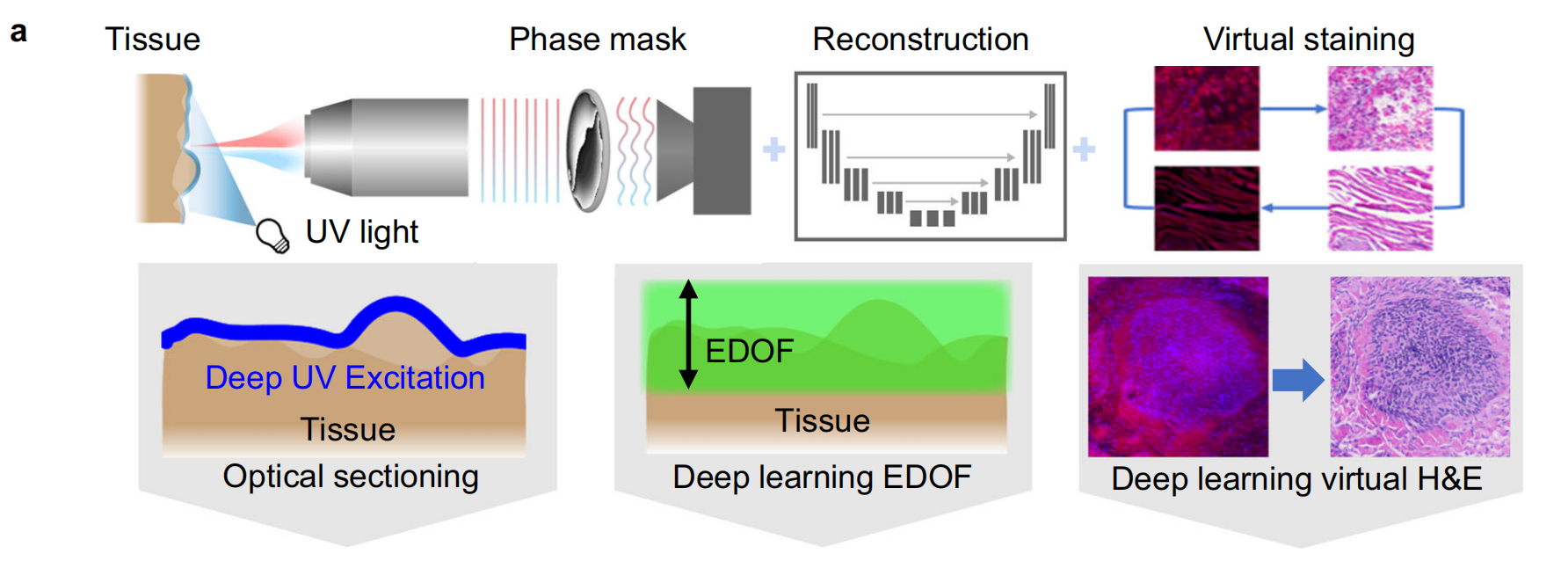
a. DeepDOF-SE 平台是基于一个简单的荧光显微镜构建的,包括三个主要组成部分:
- 表面紫外线激发(UV excitation):为用活性染料染色的新鲜组织提供光学层析,有助于减少来自组织深层的散射光,从而获得更清晰的表面图像。
- 深度学习基础的相位掩模和重建网络:扩展了焦深(depth-of-field, DOF),使得即使组织表面不平整,也能获得聚焦的图像。
- CycleGAN:一种生成对抗网络,用于虚拟染色,将荧光图像转化为类似苏木精-伊红(H&E)染色的图像,便于病理学家解读。
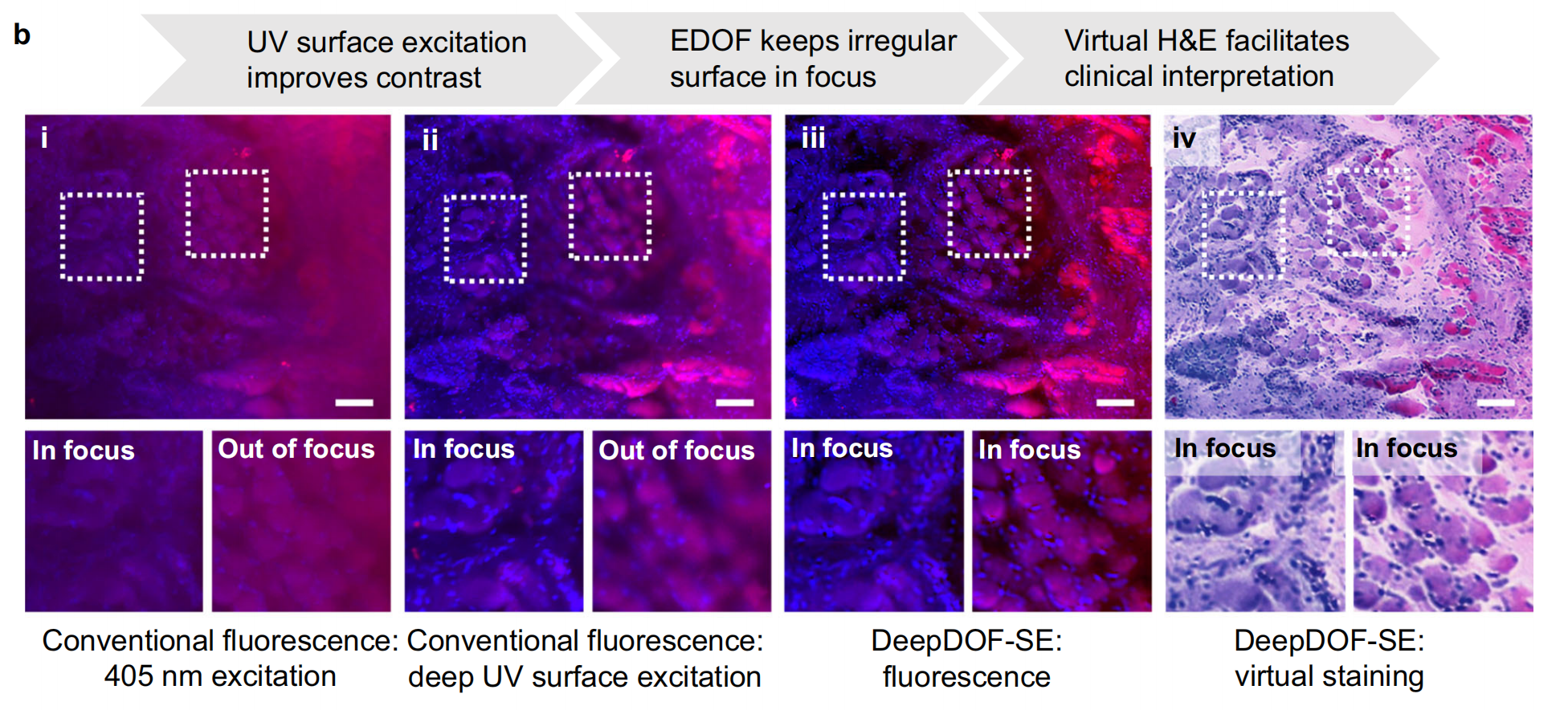
b. 与常规荧光显微镜相比,DeepDOF-SE 能够获得高对比度、聚焦且经过虚拟染色的组织学图像。示例图像展示了使用以下不同方法获取的离体猪舌样本图像:
- (i) 使用405 nm激发的常规荧光显微镜。
- (ii) 使用280 nm激发的常规荧光显微镜,这种深紫外线激发可以提供更好的对比度并减少散射。
- (iii) DeepDOF-SE 在荧光模式下获取的图像,展示了扩展焦深和表面激发的优势。
- (iv) 使用 DeepDOF-SE 并经过虚拟染色的图像,展示了如何通过 CycleGAN 获得类似传统 H&E 染色的效果。
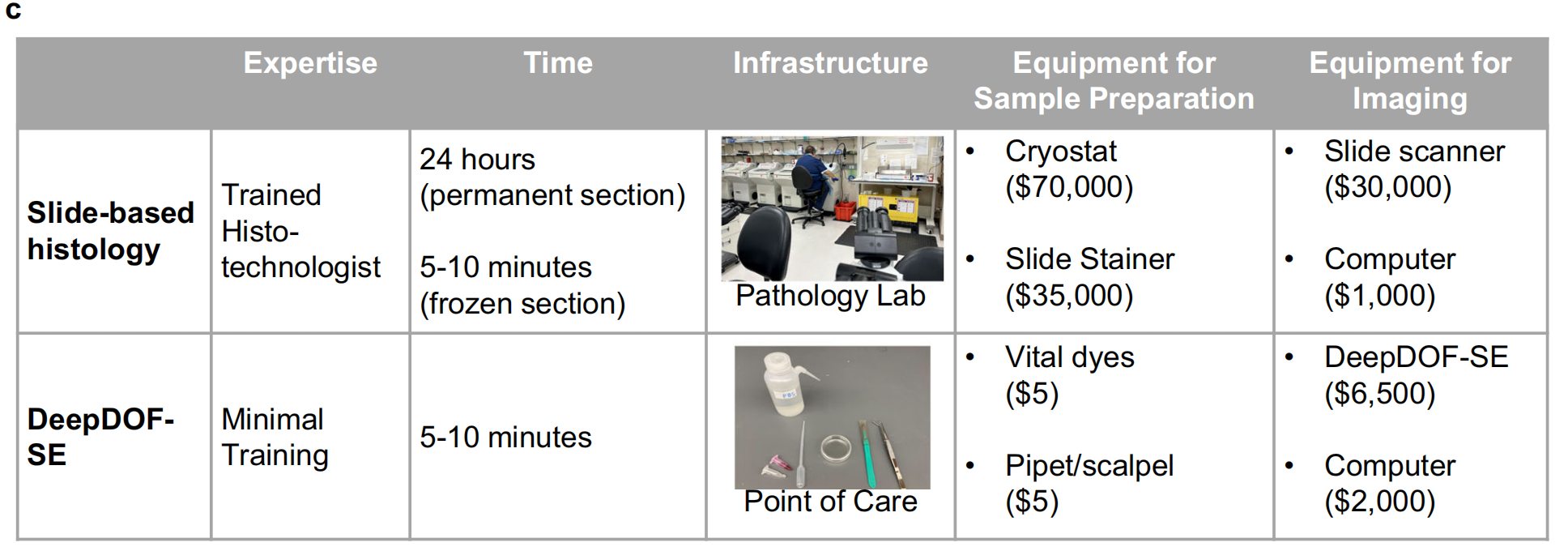
c. 与常规组织病理学相比,DeepDOF-SE 显著减少了准备组织样本所需的时间、基础设施和专业知识。图示强调了 DeepDOF-SE 如何通过简单的设备和流程,实现快速、经济的组织样本处理和成像。
整体而言,Fig. 1 展示了 DeepDOF-SE 平台的主要优势和特点,包括光学层析、扩展焦深和虚拟染色技术,这些技术共同提供了一种快速、简便且成本效益高的组织学成像解决方案。
六、分析循环细胞外免疫相关微核糖核酸(cf-IRmiRNAs)的表达模式,实现癌症早期检测

文献概述
这篇文章是关于一种新型的癌症早期检测方法的研究,特别是通过分析循环细胞外免疫相关微核糖核酸(cf-IRmiRNAs)的表达模式。
- 目的:建立一种创新的cf-IRmiRNAs特征标记,用于早期癌症检测。
- 方法:研究分析了15,832名参与者的循环miRNA图谱,包括患有13种癌症类型的个体和对照组。数据被随机分为训练集、验证集和测试集(比例为7:2:1),并增加了一个外部测试集,共有684名参与者。
- 发现:在发现阶段,研究者通过最小绝对收缩和选择算子(LASSO)方法,从100个差异表达的cf-IRmiRNAs中筛选出39个。利用五种机器学习算法构建了基于cf-IRmiRNAs的诊断分类器,其中基于XGBoost算法的分类器在验证集中显示出卓越的癌症检测性能(AUC:0.984)。
- 验证:在测试集和外部测试集中进一步评估,证实了分类器的可靠性和有效性(AUC:0.980至1.000)。该分类器成功检测了早期癌症,特别是肺癌、前列腺癌和胃癌,并且能够区分良性和恶性肿瘤。
- 结论:这项研究代表了迄今为止最大规模和最全面的cf-IRmiRNAs泛癌分析,为早期癌症检测提供了一种有前景的非侵入性诊断生物标记物,可能对临床实践产生影响。
文章还讨论了癌症作为严重的公共卫生问题,以及早期检测对改善预后的重要性。研究强调了cf-miRNAs作为液体活检标记的潜力,以及它们在癌症发展中的免疫抑制微环境作用。此外,文章还提到了研究的局限性,包括其回顾性设计,并指出需要在大规模前瞻性和多中心试验中进一步验证。
重点关注
Fig. 1 展示了在癌症和非癌症状态之间循环细胞外免疫相关miRNAs(cf-miRNAs)的概况。
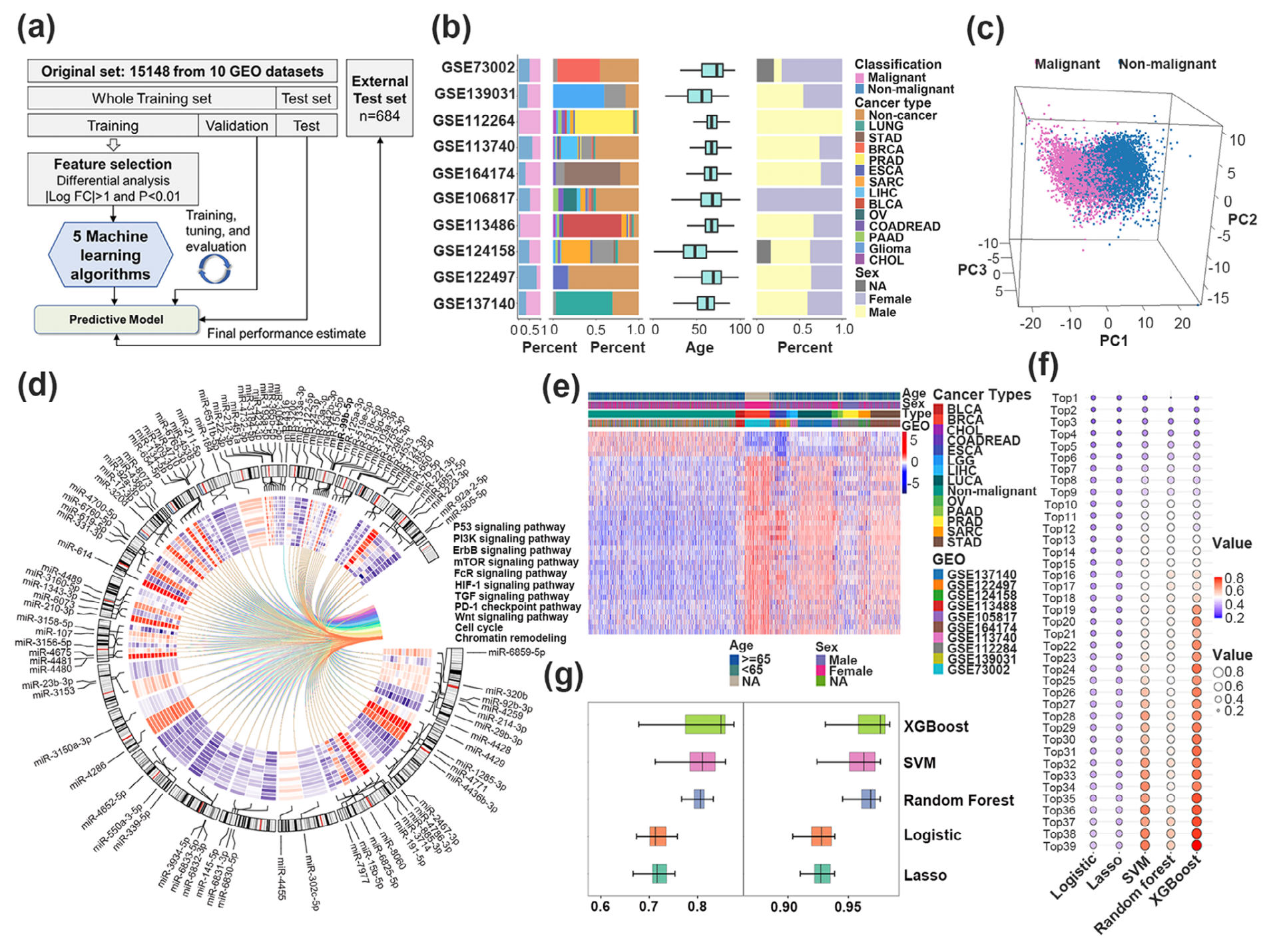
(a) 研究流程图:这部分描述了研究的整体设计和步骤,从样本收集、数据分割到分析方法和结果验证。
(b) 样本分布:提供了10个基因表达数据库(GEO datasets)中样本的分布情况,包括不同癌症类型(如肺癌、食管癌、胃癌等)和非癌症个体(健康、其他疾病和良性肿瘤)的样本数量、组织类型、年龄和性别。例如,肺癌样本有1606个,非癌症个体样本有7516个。
© 主成分分析(PCA):PCA用于分析基于差异表达miRNAs的癌症和非癌症样本。PCA可以帮助识别数据中的模式和关系,通过减少数据的维度来可视化样本之间的差异。
(d) Circos图:这是一种可视化工具,显示了在癌症中差异表达的miRNAs的免疫途径。内圈的热图显示了不同癌症类型中miRNAs的表达情况。
(e) 热图:展示了在验证集中基于39个cf-miRNAs的癌症和非癌症样本之间的显著差异。热图通过颜色的不同深浅来表示miRNAs表达水平的高低。
(f) 优登指数(Youden index):这是一种衡量诊断测试性能的指标,结合了灵敏度和特异性。X轴表示五种机器学习算法,Y轴表示优登值,颜色越红表示值越高,即分类器的性能越好。
(g) 优登指数和曲线下面积(AUC):左侧展示了每种分类器的优登指数,右侧展示了每种分类器的AUC值,AUC值接近1表示分类器的性能优秀,能够很好地区分癌症和非癌症样本。
总的来说,Fig. 1 通过不同的统计和可视化方法,展示了cf-miRNAs在癌症检测中的潜力,以及不同机器学习算法在构建诊断分类器中的性能。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 人工智能在头颈癌中的最新研究进展|顶刊速递·24-06-25

发表评论 取消回复