
- 这是ICLR2023一篇world model的论文,提出了一个称为IRIS的world model方法
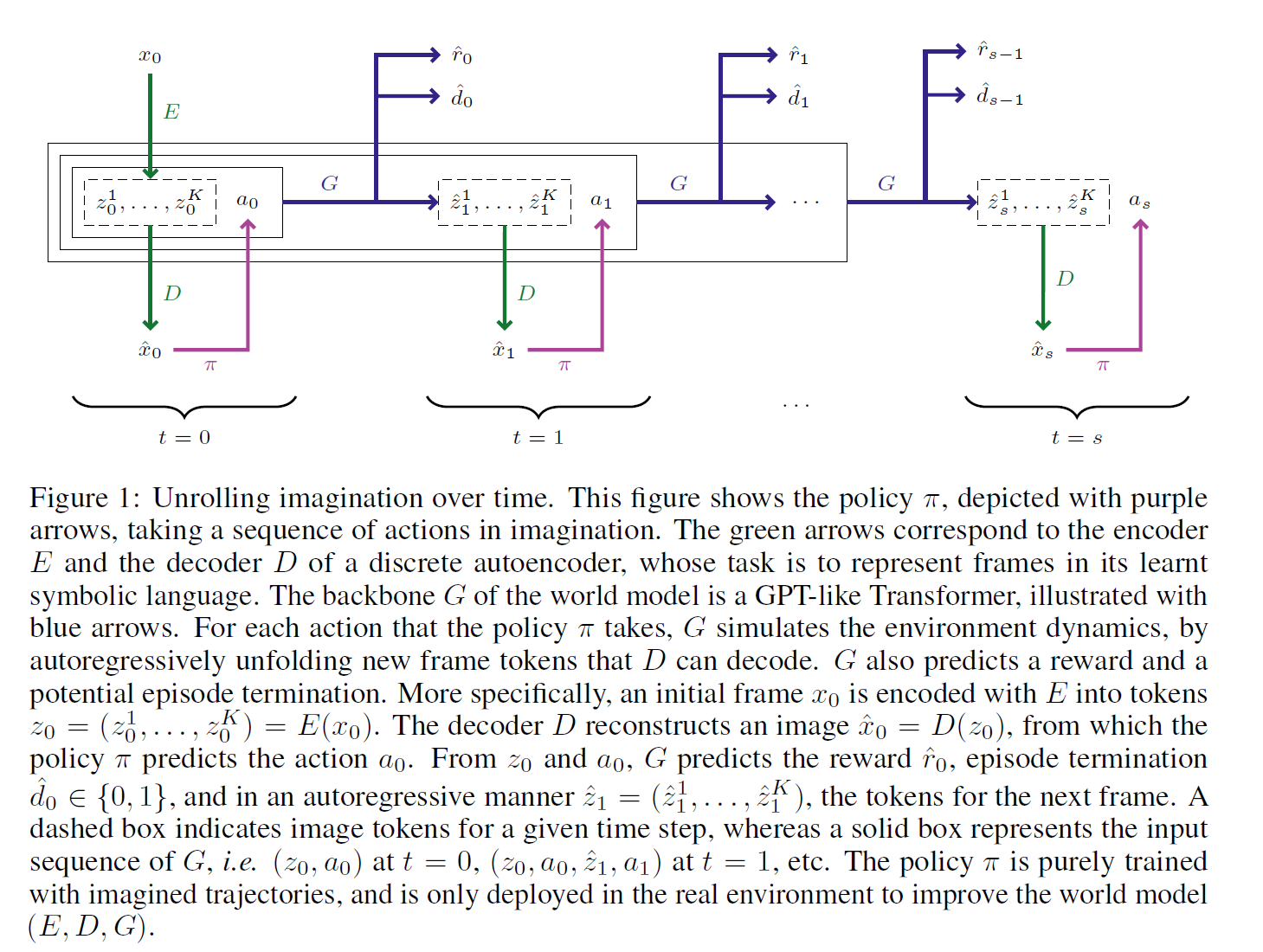
- 模型仍然是分为两部分,一部分是模拟世界的world model,包括预测下一帧的观测,预测当前reward,预测是否terminate的三个输出;第二部分是强化学习的模型,输出policy和value,可以用于AC算法。
- 模型的训练是重复以下三步:
- 利用当前的policy模型,去和真实环境交互,获得一组观测序列。
- 利用上述观测数据,train world model
- 利用world model,train RL model
world model
- world model 包含几部分,首先是一个VQ-VAE (下图的E和D)用于从图像观测中提取token,然后是一个GPT (下图的G)用于预测下一帧和当前的reward和termination。
- 可以看到,每个时刻,G的输入不仅包含当前时刻的tokens和action,还包含之前的tokens和actions。也就是说,假设每个image最终由16个token表征,action由一个token表征,则t=0时transformer的输入是17个token,t=1时transformer的输入就是34个token了。注意,train world model的时候,是在已经采样好的数据上train的,也就是说此时已经有序列了,不需要交互什么的。我已经采样好一个17n的序列了,只需要对这个序列仅需mask prediction即可,即根据17t的输入,预测17*(t+1)的输出即可,并且使用gt而非预测结果作为下一个t的输入。
- 另一个需要注意的点是,用的是GPT的框架,即transformer decoder结构,所以是token是一个个预测的,也就是说,预测t=1时刻的token并不是一次性全预测出来的,而是先用t=0时刻的17个token作为输入,预测t=1时刻的第一个token,然后把这18个token作为输入,预测第二个token,以此类推。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » IRIS论文阅读笔记

发表评论 取消回复