在上篇文章中,系统的讲解了python中的代码性能分析和优化,今天我们将深入探讨如何利用高级工具py-spy进行同样的分析和优化操作。
为什么选择py-spy?
py-spy是一个Python性能分析器,可以在生产环境中对运行中的Python程序进行实时分析,而不会对程序性能产生显著影响。它提供了许多强大的功能,包括:
- 实时性能分析:可以在程序运行时对其性能进行监控,帮助定位性能瓶颈;
- 性能数据的可视化:生成火焰图等可视化报告,直观地展示性能问题;
- 低开销:对被分析程序的性能影响极小,适合在生产环境中使用;
- 易于使用:简单易用的命令行工具,快速上手。
这些特性使得py-spy成为开发者进行性能调优的利器。
安装py-spy
首先,我们需要安装py-spy,可以通过pip进行安装:
pip install py-spy
安装完成后,可以通过命令行工具py-spy进行使用。
使用py-spy进行实时性能分析
py-spy可以在程序运行时对其进行实时性能分析。假设我们有一个名为example.py的Python脚本:
import time
def slow_function():
time.sleep(2)
print("Slow function completed")
def fast_function():
print("Fast function completed")
def main():
slow_function()
fast_function()
slow_function()
if __name__ == "__main__":
main()
我们可以使用py-spy对其进行分析(pgrep命令是类Linux,比如macOS、linux操作系统下的命令,如果是windows,需要用其他方式获取py文件的进程号,比如python的psutil库等):
# 首先,启动example.py脚本
python example.py
# 在另一个终端中运行以下命令,获取example.py的进程ID,并对其进行实时性能分析
py-spy top --pid $(pgrep -f example.py)
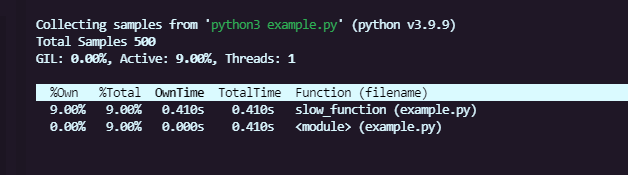
该命令将显示当前Python程序中最耗时的函数,并动态更新,这对于定位性能瓶颈非常有用:
生成火焰图
火焰图是一种非常直观的性能分析工具,可以帮助我们理解程序的性能瓶颈,使用py-spy,我们可以轻松生成火焰图:
# 首先,启动example.py脚本
python example.py
# 在另一个终端中运行以下命令,生成火焰图
py-spy record -o profile.svg --pid $(pgrep -f example.py)
该命令将在当前目录下生成一个名为profile.svg的文件,打开这个文件即可查看火焰图:

从上面火焰图可以看出,slow_function耗时很久,fast_function()的耗时忽略不计了。
高级功能
采样间隔
py-spy默认每10毫秒进行一次采样,这对于大多数应用程序已经足够;但在一些高性能应用中,我们可能需要调整采样间隔,可以使用--rate参数来调整采样频率:
py-spy top --pid $(pgrep -f example.py) --rate 1
跟踪Python程序启动
如果需要从程序启动时就开始性能分析,可以使用py-spy的spawn功能:
py-spy top -- python example.py
查看GIL锁争用情况
在多线程Python程序中,GIL(全局解释器锁)可能会成为性能瓶颈,py-spy可以帮助我们查看GIL的争用情况:
py-spy gil --pid $(pgrep -f example.py)
该命令将显示各个线程获取GIL的情况,帮助我们优化多线程程序的性能。
实战示例:优化数据处理程序
让我们通过一个实际的示例,演示如何使用py-spy进行性能分析和优化,假设我们有一个数据处理程序:
import time
import numpy as np
def process_data(data):
result = []
for item in data:
result.append(item * 2)
return result
def main():
data = np.random.rand(1000000)
start_time = time.time()
process_data(data)
print(f"Processing took {time.time() - start_time} seconds")
if __name__ == "__main__":
main()
我们可以使用py-spy生成火焰图来分析性能瓶颈:
# 运行数据处理脚本,并生成火焰图
py-spy record -o profile.svg -- python data_processing.py

通过查看生成的火焰图,我们发现process_data函数中的循环操作是性能瓶颈,可以通过使用NumPy的向量化操作进行优化:
def process_data(data):
return data * 2
def main():
data = np.random.rand(1000000)
start_time = time.time()
process_data(data)
print(f"Processing took {time.time() - start_time} seconds")
if __name__ == "__main__":
main()
优化后再次运行程序,处理时间显著减少,除了第三方库的处理时间长点,自己写的代码本身没有运行时间很长的函数了:

从实际运行时间的输出,也能看出,优化之后的代码,速度几乎提升了500倍:

结语
通过本文的介绍,我们学习了如何利用py-spy对Python代码进行性能分析和优化,同时也说明了性能优化是一个持续分析和改进的过程!希望这些技巧能帮助你在实际项目中编写出高效、稳定的代码!如果你对计算机相关技术有更多的兴趣,想要持续的探索,请关注我的公众号哟!

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 利用py-spy进行性能分析和优化

发表评论 取消回复