1. 引言
1.1. NLP研究的背景
随着人工智能技术的飞速发展,智能助手、聊天机器人和虚拟客服的需求正呈现出爆炸性增长。这些技术不仅为人们提供了极大的生活便利,如日程管理、信息查询和情感陪伴,还在工作场景中显著提高了效率。聊天机器人凭借自然语言处理技术的进步,能够更准确地理解用户需求,并在多元化应用场景中提供个性化的服务。而虚拟客服则通过降低企业运营成本、提升服务效率以及提供数据分析与优化功能,成为企业不可或缺的服务工具。总之,智能助手、聊天机器人和虚拟客服正逐渐成为现代社会中不可或缺的一部分,满足着人们对于便捷、高效和个性化服务的需求。
在现代信息技术中,自然语言处理(NLP)在搜索引擎、推荐系统和内容过滤等多个领域扮演着至关重要的角色。在搜索引擎中,NLP技术通过理解用户查询的意图和语义,优化搜索查询,并提供个性化的搜索结果,从而提高了搜索的准确性和效率。在推荐系统中,NLP技术则通过分析用户的评价、评论等文本数据,挖掘用户需求和兴趣,为用户提供更为精准和符合其偏好的推荐内容。而在内容过滤方面,NLP不仅支持关键词过滤,还能基于文本的深层含义和上下文分析,进行更为准确和高效的内容过滤,确保用户获得高质量和符合预期的信息。因此,NLP技术的应用极大地提升了搜索引擎、推荐系统和内容过滤的性能和用户体验。
自然语言处理(NLP)技术在分析文本中的情感倾向方面扮演着关键角色,满足了多个领域对于理解用户情感的需求。随着社交媒体、在线评论和用户生成内容的爆炸性增长,企业和组织越来越需要能够自动识别和评估文本中情感倾向的工具。NLP技术通过识别文本中的关键词、短语和上下文信息,能够准确判断文本的情感倾向,如积极、消极或中性,甚至更细粒度的情感分类。这种情感分析在市场营销、客户服务、社交媒体监控、金融分析和舆情预警等领域具有广泛的应用,帮助企业了解客户满意度、调整市场策略、提高客户服务质量、监测公众舆论和预测市场走势,为决策者提供有价值的信息支持。随着NLP技术的不断发展和创新,情感分析的准确性和效率将得到进一步提升。
1.2. 浅析文本多标签分类
文本多标签分类是自然语言处理(NLP)领域中的一个重要任务,其目标是为每个输入文本分配多个标签或类别,而不仅仅是一个唯一的标签或类别。
1.2.1.概念与背景
- 定义:文本多标签分类是一种文本分类任务,旨在将文本数据划分为多个相关的类别或标签。与单标签分类不同,多标签分类允许一个文本同时属于多个类别。
- 应用场景:多标签分类广泛应用于电子邮件垃圾邮件分类、社交媒体内容分类、医学记录分类及图像标注等多个领域。
1.2.2.技术挑战
- 高维稀疏问题:由于每个文本可能具有多个标签,这导致样本数量相对较少而特征空间较大,从而引发高维稀疏问题。为了解决这个问题,可以采用降维技术(如主成分分析、线性判别分析等)、特征选择技术和特征压缩技术(如奇异值分解)来减少特征空间的维度。
- 标签之间的依赖性:在多标签文本分类中,标签之间往往存在依赖关系。为了更好地处理这种依赖关系,可以采用图模型、条件随机场和层次分类等技术。
1.2.3.解决方法
- 传统方法:传统的机器学习方法如逻辑回归、支持向量机和决策树等通常需要对标签进行二值化处理,然后训练多个二分类模型。然而,这种方法存在局限性,如无法捕获标签之间的相关性,模型复杂度随标签数量呈指数级增长等。
- 深度学习方法:近年来,基于深度学习的多标签分类方法如卷积神经网络(CNN)、循环神经网络(RNN)等得到了广泛应用。这些方法通过学习文本的深层特征表示,能够更好地处理高维稀疏问题和标签之间的依赖性。
- 特定算法:研究人员还提出了一些特定的多标签分类算法,如基于分类树的方法、基于二元关系的方法和基于矩阵分解的方法等。这些算法针对多标签分类的特点进行了优化,提高了分类的准确性和效率。
1.2.4.未来发展
随着深度学习技术的不断发展和计算能力的提升,多标签分类的准确性和效率将得到进一步提升。同时,随着跨语言分类技术的发展,多标签分类也将逐渐应用于不同语言之间的文本分类任务中。此外,多标签分类技术在自然语言处理的其他任务中也有着广泛的应用前景,如情感分析、实体识别等。
综上而言,文本多标签分类是自然语言处理领域中的一个重要研究方向,具有广泛的应用前景。随着技术的不断发展和创新,相信多标签分类将在更多领域发挥重要作用。
1.3.探讨的内容
本文旨在开发一个能够实现多标签文本分类的模型,其主要目标是预测arXiv上论文的主题领域。这项技术对于像OpenReview这样的学术会议提交平台来说极其重要,因为它可以为提交的论文推荐最相关的领域分类。
我们的数据集是通过arXiv Python库获取的,这个库为arXiv的原始API提供了一个用户友好的接口。如果您对数据收集的详细过程感兴趣,可以参考我们提供的笔记本文档。此外,该数据集也可以在Kaggle平台上找到。
2.文本分类
2.1.设置
# 导入 TensorFlow Keras 的层模块
from tensorflow.keras import layers
# 导入 TensorFlow Keras 的主模块
from tensorflow import keras
# 导入 TensorFlow 模块
import tensorflow as tf
# 从 sklearn.model_selection 模块中导入 train_test_split 函数,用于划分训练集和测试集
from sklearn.model_selection import train_test_split
# 从 ast 模块中导入 literal_eval 函数,通常用于安全地评估一个字符串表达式,但在此示例中可能不是必需的
# 如果你的数据集中没有需要 literal_eval 处理的字符串,可以移除此导入
from ast import literal_eval
# 导入 matplotlib.pyplot 模块,用于数据可视化
import matplotlib.pyplot as plt
# 导入 pandas 模块,用于数据处理和分析
import pandas as pd
# 导入 numpy 模块,用于数值计算
import numpy as np
2.2.数据预处理
在本节中,我们将数据集导入至Pandas DataFrame,并开展基础的探索性数据分析(EDA)。文本特征位于摘要列,而相应的标签则以术语形式呈现。可以观察到,单个条目可能与多个类别相关联。现实世界的数据往往包含噪声,其中最常见的噪声源是数据重复。我们发现,初始数据集中约有13000条重复记录。在继续之前,我们将这些重复记录排除在外。
进一步观察显示,在3157种独特的术语组合中,有2321条记录的出现频率最低。为了准备具有分层的训练集、验证集和测试集,我们需要移除这些出现频率最低的术语。
2.2.1.清洗数据
import pandas as pd
# 读取数据
arxiv_data = pd.read_csv(
"https://github.com/soumik12345/multi-label-text-classification/releases/download/v0.2/arxiv_data.csv"
)
# 打印原始数据集的行数
print(f"There are {len(arxiv_data)} rows in the dataset.")
# 计算重复标题的数量
total_duplicate_titles = sum(arxiv_data["titles"].duplicated())
print(f"There are {total_duplicate_titles} duplicate titles.")
# 删除重复的标题(保留第一次出现的标题)
arxiv_data = arxiv_data[~arxiv_data["titles"].duplicated()]
print(f"There are {len(arxiv_data)} rows in the deduplicated dataset.")
# 注意:'terms' 列可能是一个包含多个术语的字符串,需要先分割
# 这里我们假设 'terms' 列已经是逗号分隔的字符串列表(如果是字符串,需要先进行分割)
# 由于我们不知道 'terms' 列的确切格式,这里我们仅打印唯一术语的数量(如果它们已经是列表)
# 如果不是列表,则需要先进行处理(例如,使用 str.split(','))
print(f"Unique terms count: {arxiv_data['terms'].nunique()}")
# 要计算出现次数为1的术语数量,我们需要先拆分 'terms' 列并计算每个术语的出现次数
# 这里为了简化,我们仅展示如何计算(假设 'terms' 列已经是列表)
# 实际上,你需要先遍历所有行并将术语添加到 Counter 中
# 由于我们不能直接对 'terms' 列使用 value_counts(),这里我们省略了这部分代码
# ...
# 过滤稀有术语需要更复杂的逻辑,因为 'terms' 列可能包含多个术语
# 这里我们省略了这部分代码,因为它取决于你如何定义“稀有”术语
# 注意:下面的代码是错误的,因为它试图根据整个 'terms' 列的值进行分组,而不是单个术语
# arxiv_data_filtered = arxiv_data.groupby("terms").filter(lambda x: len(x) > 1)
# ...
# 由于我们无法直接提供一个完整的过滤稀有术语的示例(因为不知道具体的数据结构),
# 这里我们仅打印去重后数据集的形状作为示例
print(f"Deduplicated dataset shape: {arxiv_data.shape}")
上述代码主要执行了以下功能:
-
导入Pandas库:使用
import pandas as pd语句导入Pandas库,这是Python中用于数据分析的一个强大工具。 -
读取数据:通过
pd.read_csv函数从提供的URL读取CSV文件到Pandas DataFrame中,存储在变量arxiv_data中。 -
打印数据集行数:使用
len(arxiv_data)函数打印原始数据集的行数,以了解数据集的大小。 -
计算重复标题数量:通过
arxiv_data["titles"].duplicated()找出重复的标题,并用sum函数计算这些重复标题的总数。 -
删除重复标题:使用布尔索引
~arxiv_data["titles"].duplicated()删除重复的标题,只保留第一次出现的记录。 -
打印去重后的数据集行数:再次使用
len(arxiv_data)打印去重后的数据集行数,以确认去重操作的效果。 -
打印唯一术语数量:使用
arxiv_data['terms'].nunique()函数打印术语列中唯一术语的数量。这里假设术语列已经是列表形式,如果是字符串,则需要先分割。 -
注释说明:代码中有几段注释,说明如何处理’terms’列,如果它包含的是逗号分隔的字符串,则需要先进行分割处理。同时,注释指出了如何计算出现次数为1的术语数量,但实际代码被省略了。
-
过滤稀有术语的逻辑:注释中提到了过滤稀有术语需要更复杂的逻辑,并且这部分代码被省略了,因为具体的过滤逻辑取决于如何定义“稀有”术语。
-
错误的分组过滤示例:注释中指出了尝试根据整个’terms’列的值进行分组的错误示例,并说明了正确的逻辑应该基于单个术语。
-
打印去重后数据集的形状:最后,使用
arxiv_data.shape打印去重后数据集的形状,作为数据预处理的一个总结。
整体来看,这段代码的目的是清洗数据集,移除重复记录,并进行初步的数据探索,为后续的数据分析或建模做准备。
2.2.2.将标签转换为字符串
初始的标签是以原始字符串的形式表示的。在这里,我们将它们转换为字符串列表(List[str])以进行更紧凑的表示。
换句话说,如果你有一个数据集,其中某些特征(例如“标签”或“术语”)是以单个字符串的形式存储的,但这些字符串实际上包含多个由逗号或其他分隔符分隔的值,那么将这些字符串转换为列表(其中每个元素都是原始字符串中的一个值)可以使数据处理和后续分析更加方便。
下面的代码功能是对arxiv_data_filtered DataFrame中的terms列进行处理,将其中的字符串转换为Python列表。这里使用了apply函数和一个lambda表达式来应用literal_eval函数,该函数能够将字符串形式的Python列表或元组安全地转换为实际的Python对象。
# 导入 literal_eval 函数,它能够安全地将字符串解析为Python的字面量表达式
from ast import literal_eval
# 应用 literal_eval 函数到 'terms' 列的每个元素,将字符串转换为列表
arxiv_data_filtered["terms"] = arxiv_data_filtered["terms"].apply(
lambda x: literal_eval(x) # 对每个元素应用 literal_eval 函数
)
# 打印转换后的 'terms' 列的前5个值,以验证转换是否成功
print(arxiv_data_filtered["terms"].values[:5])
代码主要功能如下:
- 导入模块:首先导入了
ast模块中的literal_eval函数,该函数用于将字符串安全地解析为Python字面量。 - 转换数据类型:使用
apply方法和lambda表达式对arxiv_data_filteredDataFrame中的terms列进行遍历,将每个条目从字符串格式转换为Python列表。 - 验证转换结果:通过打印转换后的
terms列的前5个值,来检查转换是否按预期进行。
这种转换通常在数据预处理阶段非常有用,特别是当数据集中的某些列以字符串形式存储了列表或元组,而这些数据在后续的分析或模型训练中需要以实际的列表形式使用时。
2.2.3.数据分层抽样
当数据集存在类别不平衡问题时,使用分层抽样(stratified sampling)来划分训练集和测试集是一个很好的策略。分层抽样确保每个类别的样本在训练集和测试集中的比例与原始数据集中的比例大致相同,这有助于防止模型在训练时过度偏向于多数类,从而提高对少数类的预测能力。
下面的代码功能是对数据集进行分层抽样,以创建训练集、验证集和测试集。分层抽样确保了每个数据集中各类别的分布与原始数据集保持一致,这对于多标签分类问题尤其重要。
from sklearn.model_selection import train_test_split
# 设置测试集占总数据集的比例为10%
test_split = 0.1
# 进行初始的训练集和测试集的分层抽样
# stratify参数确保分层抽样,使测试集中各类别的分布与原数据集一致
train_df, test_df = train_test_split(
arxiv_data_filtered, # 待分割的数据集
test_size=test_split, # 测试集占总数据集的比例
stratify=arxiv_data_filtered["terms"].values # 根据'terms'列的值进行分层
)
# 进一步将测试集分割为验证集和新的测试集
# 随机选取测试集中50%的数据作为验证集
val_df = test_df.sample(frac=0.5)
# 从原始测试集中移除验证集的数据,剩下的作为最终的测试集
test_df.drop(val_df.index, inplace=True)
# 打印各个数据集的行数
print(f"训练集的行数: {len(train_df)}")
print(f"验证集的行数: {len(val_df)}")
print(f"测试集的行数: {len(test_df)}")
功能总结:
- 设置测试集比例:定义了一个变量
test_split,用于设置测试集占总数据集的比例。 - 分层抽样:使用
train_test_split函数从arxiv_data_filtered中分割出训练集和测试集,并通过stratify参数确保测试集中的类别分布与原始数据集一致。 - 进一步分割测试集:从测试集中随机选取50%的数据作为验证集,使用
sample函数实现。 - 更新测试集:将验证集的数据从原始测试集中移除,以形成最终的测试集。
- 打印数据集大小:打印训练集、验证集和测试集的行数,以供进一步分析或记录。
分层抽样是一种重要的数据预处理步骤,特别是在类别不平衡或多标签分类问题中,它有助于确保模型训练和评估的公正性和有效性。
2.2.4.多标签二值化
在机器学习和深度学习中,特别是在处理多标签分类问题时,我们经常需要将标签(通常是字符串或整数)转换为模型可以理解的格式。对于多标签分类,一个样本可能属于多个类别,这需要我们进行特殊处理,而不仅仅是简单的单标签分类。
StringLookup 是 TensorFlow(一个流行的深度学习库)中的一个层,它允许你将字符串或整数映射到唯一的整数索引。这对于将标签转换为模型可以使用的格式非常有用。然而,在多标签分类的情况下,你可能还需要进行额外的步骤,即所谓的“多标签二值化”(Multi-label binarization)。
多标签二值化是将多标签输出转换为二值矩阵的过程,其中矩阵的每一行对应于一个样本,每一列对应于一个可能的类别。如果样本属于某个类别,则相应的矩阵元素为1,否则为0。
以下是一个使用 TensorFlow 的 StringLookup 层和手动多标签二值化的基本步骤:
- 收集标签:首先,你需要收集你的数据集中所有唯一的标签。
- 创建 StringLookup 层:使用 TensorFlow 的
StringLookup层来映射这些标签到唯一的整数索引。你需要将mask_token设置为None,因为你可能不需要这个,并且确保num_oov_indices设置为 0(或适当的值,如果你希望为未知标签保留空间)。 - 转换标签:使用
StringLookup层将你的标签转换为整数索引。 - 多标签二值化:接下来,你需要将这些整数索引转换为一个二值矩阵。这通常可以通过创建一个与类别数量相同长度的零向量,并将与样本标签对应的索引位置设置为1来完成。你可以使用 Python 的列表推导式或 NumPy 的函数来轻松完成这一步。
- 作为模型输入/输出:最后,你可以将这个二值矩阵作为模型的输入(在某些情况下,如多标签分类的某些变体)或输出(在大多数多标签分类任务中)。
注意:如果你正在使用 Keras(TensorFlow 的高级 API),那么可能有更高级的方法来自动处理多标签分类,例如使用 MultiLabelBinarizer(这是 scikit-learn 中的一个工具,而不是 TensorFlow/Keras 的内置功能,但你可以很容易地将它与 TensorFlow/Keras 一起使用)或自定义的损失函数和评估指标。
下面的代码功能是使用TensorFlow框架来处理文本数据的标签编码,并将标签从多热编码(multi-hot encoding)转换回原始词汇。
import tensorflow as tf
import numpy as np
# 将训练数据集中的'terms'列转换为RaggedTensor
terms = tf.ragged.constant(train_df["terms"].values)
# 创建一个字符串查找层,用于将字符串转换为多热编码
lookup = tf.keras.layers.StringLookup(output_mode="multi_hot")
# 适配数据,构建词汇表
lookup.adapt(terms)
# 获取词汇表
vocab = lookup.get_vocabulary()
# 定义一个函数,用于将多热编码的标签转换回词汇表中的词汇
def invert_multi_hot(encoded_labels):
"""将单个多热编码的标签转换为词汇表中的词汇元组。"""
# 找出多热编码中值为1的位置索引
hot_indices = np.argwhere(encoded_labels == 1.0)[..., 0]
# 使用索引从词汇表中取出对应的词汇
return np.take(vocab, hot_indices)
# 打印词汇表
print("词汇表:\n")
print(vocab)
代码主要实现以下功能:
- 创建RaggedTensor:使用
tf.ragged.constant将训练数据集中的terms列转换为一个RaggedTensor,这是因为terms列包含的是可以变化长度的序列数据。 - 字符串查找层:创建一个
tf.keras.layers.StringLookup层,设置output_mode为"multi_hot",这样每个唯一的字符串标签都会被转换为一个多热编码的向量。 - 适配数据:调用
adapt方法来适配提供的RaggedTensor数据,构建一个词汇表。 - 获取词汇表:通过
get_vocabulary方法获取构建的词汇表,这个词汇表将用于后续的编码和解码过程。 - 定义解码函数:定义了一个名为
invert_multi_hot的函数,它接受一个多热编码的标签,然后将其转换回原始的词汇表中的词汇。 - 打印词汇表:打印出构建的词汇表,以便了解模型是如何将标签编码为多热编码的。
这种处理方式在处理多标签分类问题时非常有用,因为它允许模型学习每个标签的独立表示,同时保持标签之间的独立性。多热编码是一种常见的标签编码方式,特别是在使用神经网络处理分类问题时。
这里我们正在从标签池中分离出可用的各个唯一类别,然后使用这些信息来用0和1表示给定的标签集。以下是一个例子。以下代码的功能是演示如何使用TensorFlow的StringLookup层将文本标签转换为多热编码的二进制表示形式。
# 从训练数据集中选取第一个样本的'terms'标签
sample_label = train_df["terms"].iloc[0]
# 打印原始标签
print(f"原始标签: {sample_label}")
# 使用StringLookup层将原始标签转换为多热编码表示
# 注意:这里假设sample_label是一个列表形式的标签集合
label_binarized = lookup([sample_label])
# 打印多热编码后的标签表示
print(f"标签的多热编码表示: {label_binarized}")
上述代码主要实现以下功能:
- 选择样本标签:从
train_dfDataFrame中选取索引为0的样本的terms列作为示例标签。 - 打印原始标签:输出这个样本的原始标签,以便与后续的编码表示进行比较。
- 转换为多热编码:使用之前适配好的
lookup层将原始标签转换为多热编码的格式。这里将标签放在列表中,因为lookup层预期接收一个序列。 - 打印编码表示:输出转换后的多热编码表示,这通常是一个二维数组,其中每一行代表一个标签的编码,每一列代表词汇表中的一个唯一项。
多热编码是一种将分类数据转换为机器学习算法可以处理的格式的方法,它特别适用于处理具有多个类别标签的多标签分类问题。在这种编码中,每个类别标签都被表示为一个二进制向量,向量的长度等于类别的总数,其中对应类别标签的位置为1,其余为0。
Original label: ['cs.LG', 'cs.CV', 'eess.IV']
Label-binarized representation: [[0. 1. 1. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0.]]
这段代码的功能是创建用于训练、验证和测试的TensorFlow数据集,并对文本数据进行一些预处理。以下是代码的中文注释和功能总结:
####1.3.5.划分数据集
当我们处理文本数据时,序列长度是一个重要的考虑因素。首先,我们通常会获取序列长度的百分位估计值,这样做的目的是为了了解数据集中序列长度的分布情况。比如,如果50%的摘要(abstracts)长度约为154个单词(这个数字可能因数据集的不同而有所变化),那么接近这个数值的长度就可以作为最大序列长度的一个合理近似值。
有了这个近似值,我们就可以在准备数据集时采取适当的策略。例如,对于长于这个近似值的序列,我们可以选择截断它们以符合最大长度;对于短于这个长度的序列,我们可能需要填充它们以避免在模型训练时造成维度不匹配的问题。
接下来,我们会实现一些工具或方法来准备数据集。这些工具可能会涉及文本清洗、分词、编码等步骤,确保数据符合模型的输入要求。同时,我们还会使用这些工具来处理序列长度,确保它们都在我们设定的最大序列长度范围内。
最后,我们会利用TensorFlow的tf.data API来创建tf.data.Dataset对象。这个对象将包含预处理后的数据,并且已经按照我们设定的策略处理了序列长度。通过这个数据集对象,我们可以轻松地将数据提供给模型进行训练,而无需担心序列长度的问题。
import tensorflow as tf
# 设置最大序列长度、批量大小、填充标记和自动调整选项
max_seqlen = 150
batch_size = 128
padding_token = "<pad>"
auto = tf.data.AUTOTUNE
# 计算摘要列中句子的平均长度、标准差、最小值、25%、50%、75%和最大值
print(train_df["summaries"].apply(lambda x: len(x.split(" "))).describe())
# 定义一个函数来创建数据集
def make_dataset(dataframe, is_train=True):
# 将'terms'列的标签转换为RaggedTensor
labels = tf.ragged.constant(dataframe["terms"].values)
# 使用StringLookup层将标签转换为多热编码
label_binarized = lookup(labels).numpy()
# 从摘要和标签创建一个TensorFlow数据集
dataset = tf.data.Dataset.from_tensor_slices(
(dataframe["summaries"].values, label_binarized)
)
# 如果是训练数据集,则进行洗牌操作
dataset = dataset.shuffle(batch_size * 10) if is_train else dataset
# 将数据集分批,并使用自动调整选项
return dataset.batch(batch_size, drop_remainder=is_train)
# 使用make_dataset函数创建训练、验证和测试数据集
train_dataset = make_dataset(train_df, is_train=True)
validation_dataset = make_dataset(val_df, is_train=False)
test_dataset = make_dataset(test_df, is_train=False)
代码主要功能如下:
- 设置参数:定义了最大序列长度
max_seqlen、批量大小batch_size、填充标记padding_token和自动调整选项auto。 - 统计摘要长度:计算训练数据集中摘要的长度,并打印出摘要长度的描述性统计信息,如平均值、标准差等。
- 创建数据集函数:定义了一个名为
make_dataset的函数,它接受一个DataFrame和一个布尔值is_train作为参数,用于创建数据集。 - 标签转换:使用
tf.ragged.constant将DataFrame中的terms列转换为RaggedTensor,然后使用之前适配好的lookup层将标签转换为多热编码。 - 数据集创建:使用
tf.data.Dataset.from_tensor_slices从摘要和标签创建TensorFlow数据集。 - 洗牌和分批:如果是训练数据集,则进行洗牌操作以随机化数据,然后使用
batch方法将数据集分批处理。 - 创建特定数据集:使用
make_dataset函数分别创建训练集、验证集和测试集。
这种数据集的创建方式适用于深度学习模型的训练和评估,特别是在处理文本数据和多标签分类问题时。通过洗牌和分批处理,可以提高模型训练的稳定性和效率。
2.2.5.数据集预览
在数据预处理和模型训练之前,预览数据集是一个非常重要的步骤。预览数据集可以帮助我们了解数据的结构、内容和特点,以便做出更好的预处理决策和模型设计选择。
下面代码的功能是从训练数据集中取出一个批次(batch)的数据,然后打印出该批次前5条摘要及其对应的标签。
import numpy as np
# 从训练数据集中获取一个批次的数据
text_batch, label_batch = next(iter(train_dataset))
# 遍历这个批次的前5条摘要
for i, text in enumerate(text_batch[:5]):
# 将对应标签转换为NumPy数组,并增加一个维度以匹配多热编码的格式
label = label_batch[i].numpy()[None, ...]
# 打印摘要文本
print(f"摘要: {text}")
# 使用之前定义的invert_multi_hot函数将多热编码的标签转换回原始词汇
print(f"标签: {invert_multi_hot(label[0])}")
# 打印空行以分隔不同的摘要和标签
print(" ")
执行以上代码,实施以下功能:
- 获取批次数据:使用
iter(train_dataset)获取训练数据集的迭代器,并通过next函数取出第一个批次的数据。 - 遍历摘要:遍历取出的批次数据中的前5条摘要。
- 标签转换:将每个摘要对应的标签从Tensor转换为NumPy数组,并增加维度以适应多热编码的格式。
- 打印摘要:打印每条摘要的文本。
- 标签解码:使用
invert_multi_hot函数将多热编码的标签转换回原始词汇表中的词汇。 - 打印标签:打印每条摘要对应的标签集合。
- 空行分隔:在每条摘要和标签打印后打印一个空行,以提高可读性。
这段代码是一个很好的示例,展示了如何在深度学习模型训练过程中检查和验证数据。通过打印摘要和解码后的标签,可以确保数据预处理和加载的步骤是正确的,并且标签编码和解码的过程是可逆的。这对于调试和理解模型输入和输出非常有用。
Abstract: b"In this paper we show how using satellite images can improve the accuracy of\nhousing price estimation models. Using Los Angeles County's property assessment\ndataset, by transferring learning from an Inception-v3 model pretrained on\nImageNet, we could achieve an improvement of ~10% in R-squared score compared\nto two baseline models that only use non-image features of the house."
Label(s): ['cs.LG' 'stat.ML']
Abstract: b'Learning from data streams is an increasingly important topic in data mining,\nmachine learning, and artificial intelligence in general. A major focus in the\ndata stream literature is on designing methods that can deal with concept\ndrift, a challenge where the generating distribution changes over time. A\ngeneral assumption in most of this literature is that instances are\nindependently distributed in the stream. In this work we show that, in the\ncontext of concept drift, this assumption is contradictory, and that the\npresence of concept drift necessarily implies temporal dependence; and thus\nsome form of time series. This has important implications on model design and\ndeployment. We explore and highlight the these implications, and show that\nHoeffding-tree based ensembles, which are very popular for learning in streams,\nare not naturally suited to learning \\emph{within} drift; and can perform in\nthis scenario only at significant computational cost of destructive adaptation.\nOn the other hand, we develop and parameterize gradient-descent methods and\ndemonstrate how they can perform \\emph{continuous} adaptation with no explicit\ndrift-detection mechanism, offering major advantages in terms of accuracy and\nefficiency. As a consequence of our theoretical discussion and empirical\nobservations, we outline a number of recommendations for deploying methods in\nconcept-drifting streams.'
Label(s): ['cs.LG' 'stat.ML']
Abstract: b"As reinforcement learning (RL) achieves more success in solving complex\ntasks, more care is needed to ensure that RL research is reproducible and that\nalgorithms herein can be compared easily and fairly with minimal bias. RL\nresults are, however, notoriously hard to reproduce due to the algorithms'\nintrinsic variance, the environments' stochasticity, and numerous (potentially\nunreported) hyper-parameters. In this work we investigate the many issues\nleading to irreproducible research and how to manage those. We further show how\nto utilise a rigorous and standardised evaluation approach for easing the\nprocess of documentation, evaluation and fair comparison of different\nalgorithms, where we emphasise the importance of choosing the right measurement\nmetrics and conducting proper statistics on the results, for unbiased reporting\nof the results."
Label(s): ['cs.LG' 'stat.ML' 'cs.AI' 'cs.RO']
Abstract: b'Estimating dense correspondences between images is a long-standing image\nunder-standing task. Recent works introduce convolutional neural networks\n(CNNs) to extract high-level feature maps and find correspondences through\nfeature matching. However,high-level feature maps are in low spatial resolution\nand therefore insufficient to provide accurate and fine-grained features to\ndistinguish intra-class variations for correspondence matching. To address this\nproblem, we generate robust features by dynamically selecting features at\ndifferent scales. To resolve two critical issues in feature selection,i.e.,how\nmany and which scales of features to be selected, we frame the feature\nselection process as a sequential Markov decision-making process (MDP) and\nintroduce an optimal selection strategy using reinforcement learning (RL). We\ndefine an RL environment for image matching in which each individual action\neither requires new features or terminates the selection episode by referring a\nmatching score. Deep neural networks are incorporated into our method and\ntrained for decision making. Experimental results show that our method achieves\ncomparable/superior performance with state-of-the-art methods on three\nbenchmarks, demonstrating the effectiveness of our feature selection strategy.'
Label(s): ['cs.CV']
Abstract: b'Dense reconstructions often contain errors that prior work has so far\nminimised using high quality sensors and regularising the output. Nevertheless,\nerrors still persist. This paper proposes a machine learning technique to\nidentify errors in three dimensional (3D) meshes. Beyond simply identifying\nerrors, our method quantifies both the magnitude and the direction of depth\nestimate errors when viewing the scene. This enables us to improve the\nreconstruction accuracy.\n We train a suitably deep network architecture with two 3D meshes: a\nhigh-quality laser reconstruction, and a lower quality stereo image\nreconstruction. The network predicts the amount of error in the lower quality\nreconstruction with respect to the high-quality one, having only view the\nformer through its input. We evaluate our approach by correcting\ntwo-dimensional (2D) inverse-depth images extracted from the 3D model, and show\nthat our method improves the quality of these depth reconstructions by up to a\nrelative 10% RMSE.'
Label(s): ['cs.CV' 'cs.RO']
2.2.6.数据向量化
在向模型输入数据之前,我们需要对数据进行向量化,即将其转换为数值形式。为了实现这一点,我们将使用 TextVectorization 层。该层可以集成到主模型中,使得预处理逻辑与模型本身分离,这大大减少了在推理过程中出现训练/部署偏差的可能性。
首先,我们需要计算摘要中存在的唯一单词数量。接下来,我们将创建 TextVectorization 层,并将其应用于之前创建的 tf.data.Datasets。当一批原始文本数据通过 TextVectorization 层时,该层会生成它们的整数表示。在内部,TextVectorization 层首先将序列转换为双词短语(bigrams),然后使用 TF-IDF(词频-逆文档频率)来表示这些短语。最终,这些整数表示将被传递给负责文本分类的模型。
要深入了解 TextVectorization 的其他配置选项,请查阅官方文档。
请注意,虽然可以将 max_tokens 参数设置为预计算的词汇表大小,但这并不是必需的。TextVectorization 层可以自动管理词汇表的大小,根据需要进行调整。
以下代码的功能是使用TensorFlow的TextVectorization层来向量化文本数据,同时计算词汇表的大小,并在训练、验证和测试数据集上应用这个向量化过程。
import tensorflow as tf
import pandas as pd
# 从训练数据集中构建词汇表
vocabulary = set()
# 将摘要列中的文本转换为小写,并分割成单词,更新词汇表
train_df["summaries"].str.lower().str.split().apply(vocabulary.update)
# 计算词汇表的大小
vocabulary_size = len(vocabulary)
print(vocabulary_size)
# 创建TextVectorization层,设置最大词汇数为词汇表大小,使用二元语法(ngrams=2),输出模式为TF-IDF
text_vectorizer = layers.TextVectorization(
max_tokens=vocabulary_size, ngrams=2, output_mode="tf_idf"
)
# 在CPU上适应TextVectorization层,以避免GPU上的内存问题
with tf.device("/CPU:0"):
# 使用训练数据集中的文本对TextVectorization层进行适应
text_vectorizer.adapt(train_dataset.map(lambda text, label: text))
# 使用TextVectorization层处理训练数据集中的文本,并进行预取
train_dataset = train_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
# 同上,处理验证数据集
validation_dataset = validation_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
# 同上,处理测试数据集
test_dataset = test_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
通过以上代码,实现了功能:
- 构建词汇表:通过遍历训练数据集的摘要列,将所有不重复的单词添加到一个集合中,形成一个词汇表。
- 计算词汇表大小:打印出构建的词汇表中唯一单词的数量。
- 创建TextVectorization层:初始化一个
TextVectorization层,设置最大词汇数为词汇表的大小,使用二元语法来捕捉两个连续词的组合,并设置输出模式为TF-IDF,这是一种反映单词重要性的权重。 - 适应TextVectorization层:在CPU上运行,使用训练数据集中的文本数据来适应
TextVectorization层,这样它就可以了解所有可能的词汇。 - 文本向量化:对训练、验证和测试数据集中的文本应用
TextVectorization层,将文本转换为数值形式。 - 预取处理:使用
prefetch方法提高数据加载的效率。
使用TextVectorization层是一种常见的文本预处理方法,它可以将文本数据转换为模型可以理解的数值形式,同时还可以应用诸如TF-IDF等权重,以增强模型对文本数据的理解。
2.3.建立分类模型
我们将构建一个简洁的模型架构——它采用一系列全连接层堆叠而成,并使用ReLU作为激活函数来引入非线性。这种设计旨在保持模型的简洁性,易于训练、调试和理解。一旦基础模型表现良好,我们可以根据需要进一步扩展和优化其架构。
以下代码定义了一个简单的多层感知器(MLP)模型构建函数,用于构建一个用于多标签分类的神经网络。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
def make_model():
# 创建一个Sequential模型,这是一个线性堆叠的层次模型
shallow_mlp_model = keras.Sequential(
[
# 第一层是具有512个神经元的全连接层,使用ReLU激活函数
layers.Dense(512, activation="relu"),
# 第二层是具有256个神经元的全连接层,也使用ReLU激活函数
layers.Dense(256, activation="relu"),
# 第三层是输出层,神经元数量等于词汇表的大小,使用Sigmoid激活函数
# Sigmoid函数将输出压缩到0和1之间,适合多标签分类问题
layers.Dense(lookup.vocabulary_size(), activation="sigmoid"),
]
)
# 返回构建的模型
return shallow_mlp_model
通过上述代码实现了以下功能:
- 定义模型构建函数:
make_model函数用于创建并返回一个神经网络模型。 - Sequential模型:使用
keras.Sequential来创建一个线性的层序列。 - 添加隐藏层:模型包含两个隐藏层,第一层有512个神经元,第二层有256个神经元,都使用ReLU激活函数。ReLU激活函数有助于在训练过程中缓解梯度消失问题,并加速收敛。
- 输出层:最后一个层是输出层,其神经元数量由
lookup.vocabulary_size()决定,这应该是标签集合中唯一类别的数量。输出层使用Sigmoid激活函数,这是因为Sigmoid函数能够输出一个介于0和1之间的概率值,适用于多标签分类,其中每个标签可以独立地被视为一个二分类问题。 - 返回模型:函数返回构建的模型,这个模型随后可以被编译和训练。
使用Sigmoid激活函数在多标签分类中是常见的选择,因为它为每个标签提供了一个概率估计,可以解释为标签存在的置信度。这与二元交叉熵损失函数(binary crossentropy)结合使用,是处理多标签分类问题的标准做法。
2.4.训练模型
我们将使用二元交叉熵损失函数来训练我们的模型,因为标签之间并非互斥,一个摘要可能属于多个类别。因此,我们将预测任务分解为多个独立的二元分类问题,这也是我们在模型分类层选择sigmoid作为激活函数的原因。除了这种配置外,研究人员还采用了其他损失函数和激活函数的组合。例如,在《探索弱监督预训练的极限》一文中,Mahajan等人使用了softmax激活函数和交叉熵损失来训练他们的模型。
在多标签分类任务中,有多种评估指标可供选择。为了简化这个代码示例,我们决定使用二元准确率作为评估指标。关于为何选择这个指标,可以参考相关的讨论或文档。当然,对于多标签分类任务,还有其他合适的评估指标,如F1分数或汉明损失。
以下代码演示了如何使用Keras构建、编译、训练一个简单的多层感知器(MLP)模型,并绘制训练和验证过程中的损失和二元准确率曲线。
import matplotlib.pyplot as plt # 导入matplotlib库用于绘图
# 定义训练轮数
epochs = 20
# 调用make_model函数创建模型
shallow_mlp_model = make_model()
# 编译模型,使用二元交叉熵损失函数,Adam优化器,以及二元准确率作为评估指标
shallow_mlp_model.compile(
loss="binary_crossentropy",
optimizer="adam",
metrics=["binary_accuracy"]
)
# 训练模型,使用训练数据集和验证数据集,训练指定的轮数
history = shallow_mlp_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=epochs
)
# 定义一个绘图函数,用于绘制训练和验证过程中的特定指标
def plot_result(item):
plt.plot(history.history[item], label=item) # 绘制训练指标
plt.plot(history.history["val_" + item], label="val_" + item) # 绘制验证指标
plt.xlabel("Epochs") # X轴标签
plt.ylabel(item) # Y轴标签
plt.title("Train and Validation {} Over Epochs".format(item), fontsize=14) # 图片标题
plt.legend() # 显示图例
plt.grid() # 显示网格
plt.show() # 显示图表
# 使用plot_result函数绘制损失和二元准确率曲线
plot_result("loss")
plot_result("binary_accuracy")
代码的主要功能:
- 设置训练轮数:定义变量
epochs来设置训练模型的轮数。 - 创建模型:调用之前定义的
make_model函数来创建MLP模型。 - 编译模型:使用
compile方法编译模型,指定损失函数为binary_crossentropy,优化器为adam,评估指标为binary_accuracy。 - 训练模型:使用
fit方法训练模型,传入训练数据集和验证数据集,以及训练轮数。 - 定义绘图函数:定义
plot_result函数,用于绘制模型训练和验证过程中指定指标的变化曲线。 - 绘制损失曲线:调用
plot_result函数绘制损失值的变化曲线。 - 绘制准确率曲线:再次调用
plot_result函数绘制二元准确率的变化曲线。
这种绘图方法可以帮助我们直观地了解模型在训练过程中的性能变化,包括是否出现过拟合(即在训练集上表现良好,但在验证集上表现不佳)或欠拟合(即在训练集和验证集上都表现不佳)的情况。通过观察损失和准确率曲线,我们可以调整模型结构或训练参数,以优化模型性能。
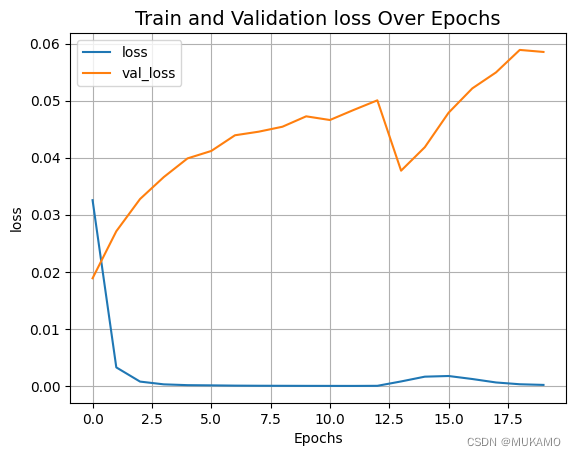
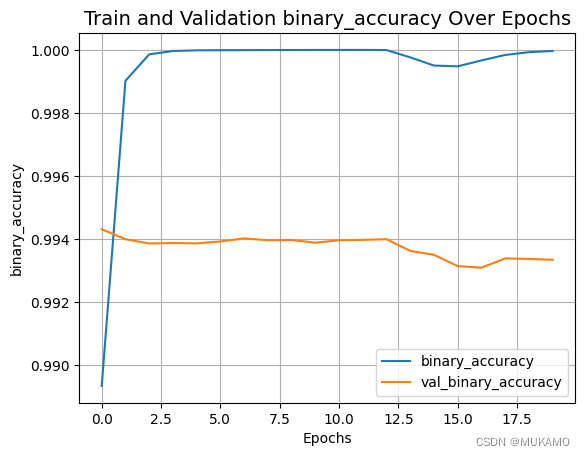
2.5.评估模型
以下代码的功能是评估训练好的MLP模型在测试数据集上的性能,并打印出二元准确率。
# 使用test_dataset评估模型性能
_, binary_acc = shallow_mlp_model.evaluate(test_dataset)
# 打印测试集上的二元分类准确率,并转换为百分比形式
# round函数用于四舍五入到小数点后两位
print(f"测试集上的二元分类准确率: {round(binary_acc * 100, 2)}%.")
功能总结:
- 模型评估:使用
evaluate方法对模型进行评估,传入测试数据集test_dataset。 - 获取准确率:
evaluate方法返回一个包含多个评估指标的列表,其中第一个值通常是损失值,第二个值是准确率。这里使用下划线_来忽略损失值,只获取准确率。 - 打印准确率:将准确率乘以100,然后使用
round函数四舍五入到小数点后两位,最后以百分比的形式打印出来。
二元准确率是衡量模型在二元分类任务上性能的一个指标,它表示模型正确预测的样本数占总样本数的比例。在多标签分类问题中,每个标签可以被视为一个独立的二元分类问题,因此二元准确率可以作为评估模型整体性能的一个指标。然而,需要注意的是,在多标签问题中,可能还需要考虑其他指标,如精确度、召回率、F1分数等,以获得更全面的模型性能评估。
15/15 [==============================] - 3s 196ms/step - loss: 0.0580 - binary_accuracy: 0.9933
Categorical accuracy on the test set: 99.33%.
2.6.模型推理
在构建推理模型时,Keras的预处理层提供了一种方便的方式,它们可以无缝地集成到tf.keras.Model中。为了创建一个可以直接在原始字符串上运行的推理模型,我们会在基础模型shallow_mlp_model之上包含text_vectorization层。
值得注意的是,尽管预处理层可以包含在模型中,但在训练阶段,最佳实践是将它们作为数据输入管道的一部分使用,而不是作为模型的一部分。这样做可以避免在硬件加速器上产生性能瓶颈,并允许异步数据处理,从而提高训练效率。
以下代码演示了如何使用训练好的模型进行推理(inference),即对新的数据进行预测。
from tensorflow import keras
# 创建一个用于推理的模型,将文本向量化层和MLP模型串联起来
model_for_inference = keras.Sequential([text_vectorizer, shallow_mlp_model])
# 创建一个小型数据集,仅用于演示推理过程
inference_dataset = make_dataset(test_df.sample(100), is_train=False)
# 从推理数据集中获取一个批次的数据
text_batch, label_batch = next(iter(inference_dataset))
# 使用模型进行预测,得到每个标签的概率
predicted_probabilities = model_for_inference.predict(text_batch)
# 执行推理过程
for i, text in enumerate(text_batch[:5]):
# 将标签转换为NumPy数组
label = label_batch[i].numpy()[None, ...]
print(f"摘要: {text}")
print(f"真实标签: {invert_multi_hot(label[0])}")
# 从预测概率中提取对应文本的概率
predicted_proba = [proba for proba in predicted_probabilities[i]]
# 获取概率最高的前3个标签
top_3_labels = [
x for _, x in sorted(
zip(predicted_probabilities[i], lookup.get_vocabulary()),
key=lambda pair: pair[0],
reverse=True,
)
][:3]
# 打印预测的标签
print(f"预测标签: {', '.join(top_3_labels)}")
print(" ")
通过以上代码,主要实现了功能:
- 创建推理模型:将文本向量化层
text_vectorizer和之前训练的MLP模型shallow_mlp_model串联起来,形成一个新的模型,用于推理。 - 创建推理数据集:使用
make_dataset函数创建一个包含100个样本的小型测试数据集,用于演示推理过程。 - 获取批次数据:从推理数据集中取出一个批次的数据,包括文本和标签。
- 进行预测:使用
predict方法对文本批次进行预测,得到每个标签的概率分布。 - 遍历文本:打印出批次中前5个文本摘要及其真实标签。
- 预测标签:对于每个文本,从预测概率中找到概率最高的前3个标签,并打印出来。
这段代码展示了如何将文本向量化和模型预测结合起来进行推理,并如何解释模型的输出。通过这种方式,可以对新的文本数据进行分类,并预测其最可能的标签。这对于实际应用中的文本分类任务非常有用。
3.总结和展望
在本文中,我们深入探讨了自然语言处理(NLP)中一个关键领域——多标签文本分类。从背景介绍到模型的构建、训练、评估,再到实际的模型推理应用,本文提供了一个全面的指南。我们首先认识到了NLP技术在智能助手、聊天机器人、搜索引擎、推荐系统和内容过滤等多个领域的广泛应用,并强调了多标签文本分类在这些应用中的重要性。在数据预处理阶段,我们通过清洗、去重和转换标签等步骤,确保了数据的质量和一致性,为模型训练打下了坚实的基础。
模型构建部分,我们设计了一个简洁的多层感知器(MLP)模型,利用ReLU激活函数引入非线性,并采用Sigmoid函数作为输出层,以适应多标签分类的需求。在模型训练过程中,我们使用了二元交叉熵损失函数和Adam优化器,通过监控损失和准确率曲线,我们能够实时了解模型的学习进度和性能。此外,模型评估环节在独立的测试集上进行,二元准确率作为主要指标,为我们提供了模型泛化能力的量化度量。
在模型推理部分,我们将文本向量化层与MLP模型结合,创建了一个完整的推理流程,能够对新的文本数据进行有效分类和标签预测。本文的探索不仅展示了多标签文本分类技术的实用性,也揭示了其在不断发展中的NLP领域的应用潜力。
展望未来,我们预见多标签文本分类技术将继续进化,通过模型优化、多任务学习、跨语言分类等方向的探索,以及深度学习技术的融合,将进一步提升模型的性能和应用范围。同时,我们也强调了提高模型可解释性和公平性的重要性,确保技术发展的同时,其预测过程的透明度和公正性也得到保障。随着技术的不断突破和创新,我们对多标签文本分类技术在更广泛领域的应用充满期待。
参考文献
[1]Sayak Paul ,Soumik Rakshit. (2020/12/23). Multi-label classification. Retrieved from https://keras.io/examples/nlp/multi_label_classification/
实验代码
"""
## 导入必要的库
"""
from tensorflow.keras import layers
from tensorflow import keras
import tensorflow as tf
from sklearn.model_selection import train_test_split
from ast import literal_eval
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
"""
## 执行探索性数据分析(EDA)
在本节中,我们首先将数据集加载到 pandas DataFrame 中,然后执行一些基础的探索性数据分析。
"""
# 加载数据集
arxiv_data = pd.read_csv(
"https://github.com/soumik12345/multi-label-text-classification/releases/download/v0.2/arxiv_data.csv"
)
# 查看数据集的前几行
print(arxiv_data.head())
"""
## 数据清洗
我们的特征文本位于 'summaries' 列,相应的标签在 'terms' 列。可以注意到,单个条目可能与多个类别相关联。
"""
# 打印数据集的行数
print(f"数据集中有 {len(arxiv_data)} 行。")
# 计算重复标题的数量并打印
total_duplicate_titles = sum(arxiv_data["titles"].duplicated())
print(f"有 {total_duplicate_titles} 个重复的标题。")
# 删除重复的标题,并打印去重后的数据集行数
arxiv_data = arxiv_data[~arxiv_data["titles"].duplicated()]
print(f"去重后的数据集有 {len(arxiv_data)} 行。")
# 计算出现次数为1的术语数量并打印
print(arxiv_data["terms"].value_counts() == 1).sum())
# 打印唯一术语的数量
print(arxiv_data["terms"].nunique())
"""
## 数据分层抽样
由于数据集中存在类别不平衡问题,为了确保评估结果的公平性,我们需要进行分层抽样。
"""
# 设置测试集的比例
test_split = 0.1
# 进行初始的训练集和测试集的分层抽样
train_df, test_df = train_test_split(
arxiv_data,
test_size=test_split,
stratify=arxiv_data["terms"].values, # 确保分层抽样
)
# 将测试集进一步分割为验证集和新的测试集
val_df = test_df.sample(frac=0.5)
test_df.drop(val_df.index, inplace=True)
# 打印不同数据集的行数
print(f"训练集的行数: {len(train_df)}")
print(f"验证集的行数: {len(val_df)}")
print(f"测试集的行数: {len(test_df)}")
"""
## 多标签二值化
现在我们使用 `StringLookup` 层预处理标签。
"""
# 创建RaggedTensor存储术语
terms = tf.ragged.constant(train_df["terms"].values)
# 创建StringLookup层,设置为多热编码模式
lookup = tf.keras.layers.StringLookup(output_mode="multi_hot")
# 适配数据并构建词汇表
lookup.adapt(terms)
vocab = lookup.get_vocabulary()
# 定义函数,将多热编码标签转换回词汇表中的词汇
def invert_multi_hot(encoded_labels):
"""将多热编码标签转换为词汇表中的词汇元组。"""
hot_indices = np.argwhere(encoded_labels == 1.0)[..., 0]
return np.take(vocab, hot_indices)
# 打印词汇表
print("词汇表:\n")
print(vocab)
"""
## 数据预处理和创建 `tf.data.Dataset` 对象
首先获取序列长度的百分位估计值,稍后将说明其用途。
"""
# 获取摘要长度的描述性统计
print(train_df["summaries"].apply(lambda x: len(x.split(" "))).describe())
"""
注意到50%的摘要长度为154(根据数据集的不同,您可能会得到不同的数字)。因此,接近该数值的任何数字都是最大序列长度的合理近似值。
现在,我们实现工具来准备数据集。
"""
# 设置最大序列长度、批量大小、填充标记和自动调整选项
max_seqlen = 150
batch_size = 128
padding_token = "<pad>"
auto = tf.data.AUTOTUNE
# 定义函数创建数据集
def make_dataset(dataframe, is_train=True):
labels = tf.ragged.constant(dataframe["terms"].values)
label_binarized = lookup(labels).numpy()
dataset = tf.data.Dataset.from_tensor_slices(
(dataframe["summaries"].values, label_binarized)
)
if is_train:
dataset = dataset.shuffle(batch_size * 10) # 如果是训练数据集,则进行洗牌
return dataset.batch(batch_size)
# 准备训练、验证和测试的 `tf.data.Dataset` 对象
train_dataset = make_dataset(train_df, is_train=True)
validation_dataset = make_dataset(val_df, is_train=False)
test_dataset = make_dataset(test_df, is_train=False)
"""
## 数据集预览
查看训练数据集中的前5个摘要和标签。
"""
# 获取批次数据
text_batch, label_batch = next(iter(train_dataset))
# 打印前5个摘要和标签
for i, text in enumerate(text_batch[:5]):
label = label_batch[i].numpy()[None, ...]
print(f"摘要: {text}")
print(f"标签: {invert_multi_hot(label[0])}")
print(" ")
"""
## 向量化
在将数据输入模型之前,我们需要对其进行向量化(以数值形式表示)。
为此,我们将使用 `TextVectorization` 层。
"""
# 从stackoverflow获取的代码,用于统计Pandas DataFrame中不同单词的数量(不包含停用词)
# 构建词汇表
vocabulary = set()
train_df["summaries"].str.lower().str.split().apply(vocabulary.update)
# 计算词汇表大小
vocabulary_size = len(vocabulary)
print(vocabulary_size)
# 创建TextVectorization层,设置最大词汇数为词汇表大小,使用二元语法,输出模式为TF-IDF
text_vectorizer = layers.TextVectorization(
max_tokens=vocabulary_size, ngrams=2, output_mode="tf_idf"
)
# 适配TextVectorization层,根据训练集中的词汇进行适配
with tf.device("/CPU:0"):
text_vectorizer.adapt(train_dataset.map(lambda text, label: text))
# 使用TextVectorization层处理数据集
train_dataset = train_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
validation_dataset = validation_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
test_dataset = test_dataset.map(
lambda text, label: (text_vectorizer(text), label), num_parallel_calls=auto
).prefetch(auto)
"""
## 创建文本分类模型
我们将保持模型的简洁性——它将由几个全连接层堆叠而成,使用ReLU作为非线性激活函数。
"""
# 定义构建模型的函数
def make_model():
shallow_mlp_model = keras.Sequential(
[
layers.Dense(512, activation="relu"), # 第一层全连接层,512个神经元
layers.Dense(256, activation="relu"), # 第二层全连接层,256个神经元
layers.Dense(lookup.vocabulary_size(), activation="sigmoid"), # 输出层,神经元数量等于词汇表大小
]
)
return shallow_mlp_model
"""
## 训练模型
我们将使用二元交叉熵损失函数来训练模型,因为标签不是互斥的。对于一个给定的摘要,我们可能有多个类别。因此,我们将预测任务分解为多个独立的二元分类问题。这也是我们在模型的分类层中选择Sigmoid作为激活函数的原因。
"""
# 设置训练轮数
epochs = 20
# 创建模型
shallow_mlp_model = make_model()
# 编译模型,使用二元交叉熵损失函数,Adam优化器,二元准确率作为评估指标
shallow_mlp_model.compile(
loss="binary_crossentropy", optimizer="adam", metrics=["binary_accuracy"]
)
# 训练模型
history = shallow_mlp_model.fit(
train_dataset, validation_data=validation_dataset, epochs=epochs
)
# 定义绘图函数,绘制训练和验证过程中的损失和准确率
def plot_result(item):
plt.plot(history.history[item], label=item)
plt.plot(history.history["val_" + item], label="val_" + item)
plt.xlabel("轮数")
plt.ylabel(item)
plt.title(f"训练和验证 {item} 随轮数的变化", fontsize=14)
plt.legend()
plt.grid()
plt.show()
# 绘制损失和准确率曲线
plot_result("loss")
plot_result("binary_accuracy")
"""
### 评估模型
"""
# 在测试集上评估模型性能
_, binary_acc = shallow_mlp_model.evaluate(test_dataset)
# 打印测试集上的分类准确率,并转换为百分比形式
print(f"测试集上的分类准确率: {round(binary_acc * 100,2)}%.")
"""
## 推理
Keras 提供的预处理层可以包含在 `tf.keras.Model` 中。我们将通过在 `shallow_mlp_model` 上包含 `text_vectorization` 层来导出一个推理模型。这将允许我们的推理模型直接处理原始字符串。
"""
# 创建推理模型
model_for_inference = keras.Sequential([text_vectorizer, shallow_mlp_model])
# 创建一个小型数据集,仅用于演示推理过程
inference_dataset = make_dataset(test_df.sample(100), is_train=False)
# 获取批次数据
text_batch, label_batch = next(iter(inference_dataset))
# 使用模型进行预测
predicted_probabilities = model_for_inference.predict(text_batch)
# 执行推理过程
for i, text in enumerate(text_batch[:5]):
label = label_batch[i].numpy()[None, ...]
print(f"摘要: {text}")
print(f"标签: {invert_multi_hot(label[0])}")
# 获取概率最高的前3个标签
top_3_labels = sorted(
zip(predicted_probabilities[i], lookup.get_vocabulary()),
key=lambda pair: pair[0],
reverse=True,
)[:3]
print(f"预测标签: {', '.join([label for label in top_3_labels])})")
print(" ")
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【机器学习】对大规模的文本数据进行多标签的分类处理

发表评论 取消回复