前言
本文分享使用Stable Diffusion 3实现文本生成图像,可以通过在线网页中免费使用的,也有API等方式访问。
同时结合论文和开源代码进行分析,理解其原理。
Stable Diffusion 3是Stability AI开发的最新、最先进的文本生成图像模型,在图像保真度、多主体处理和文本匹配方面取得了显著进步。
利用新的多模态扩散变换器(MMDiT)架构,它具有单独的图像和语言表示的Stable Diffusion 3权重。

目录
1、在线体验Stable Diffusion 3
官网地址:https://stablediffusion3.net/zh-CN
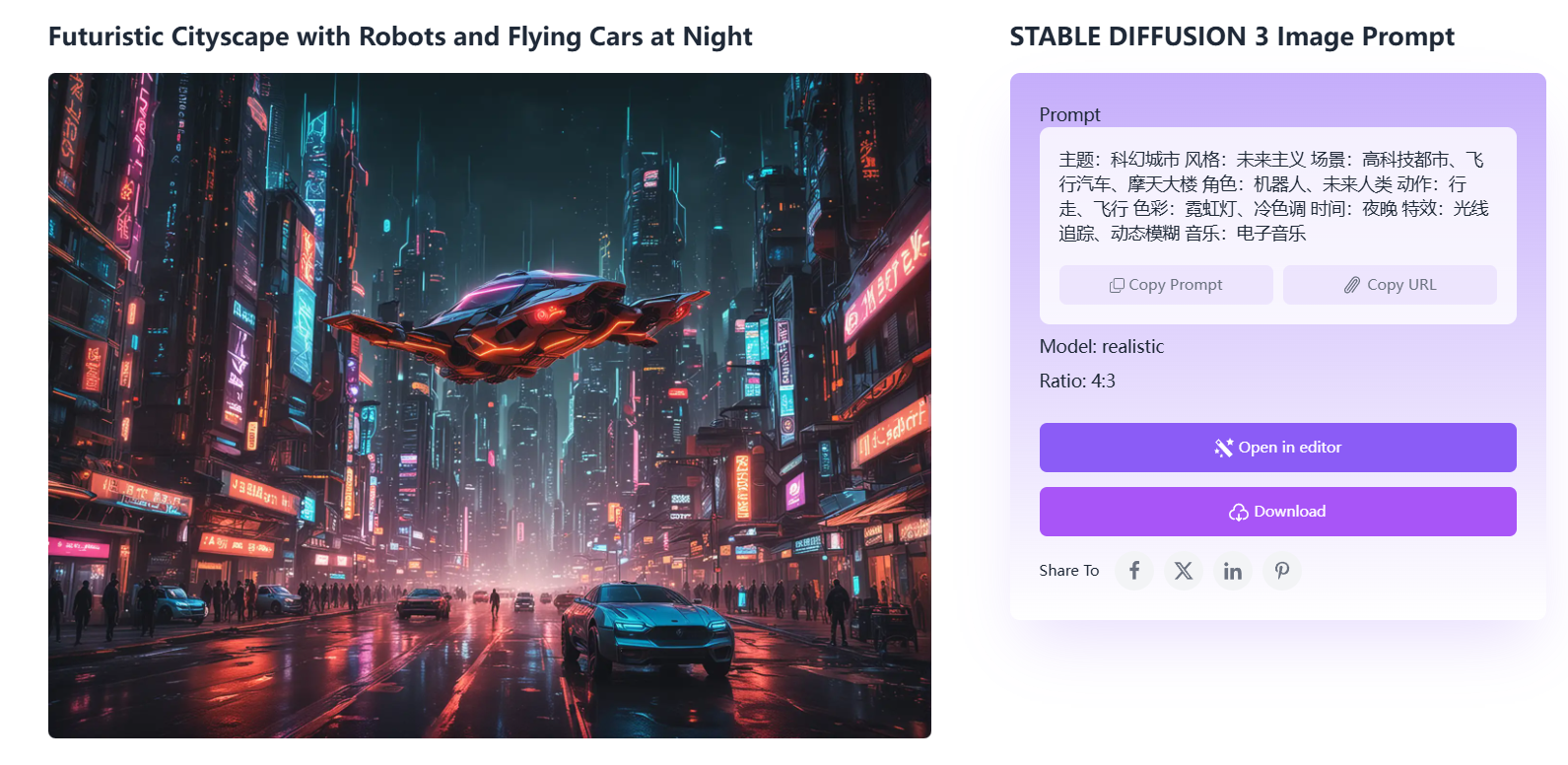
如下图所示,生成的图片还挺清晰的,不错不错 :

点击图片,能看到“提示器”,图像比例,还能下载原图:
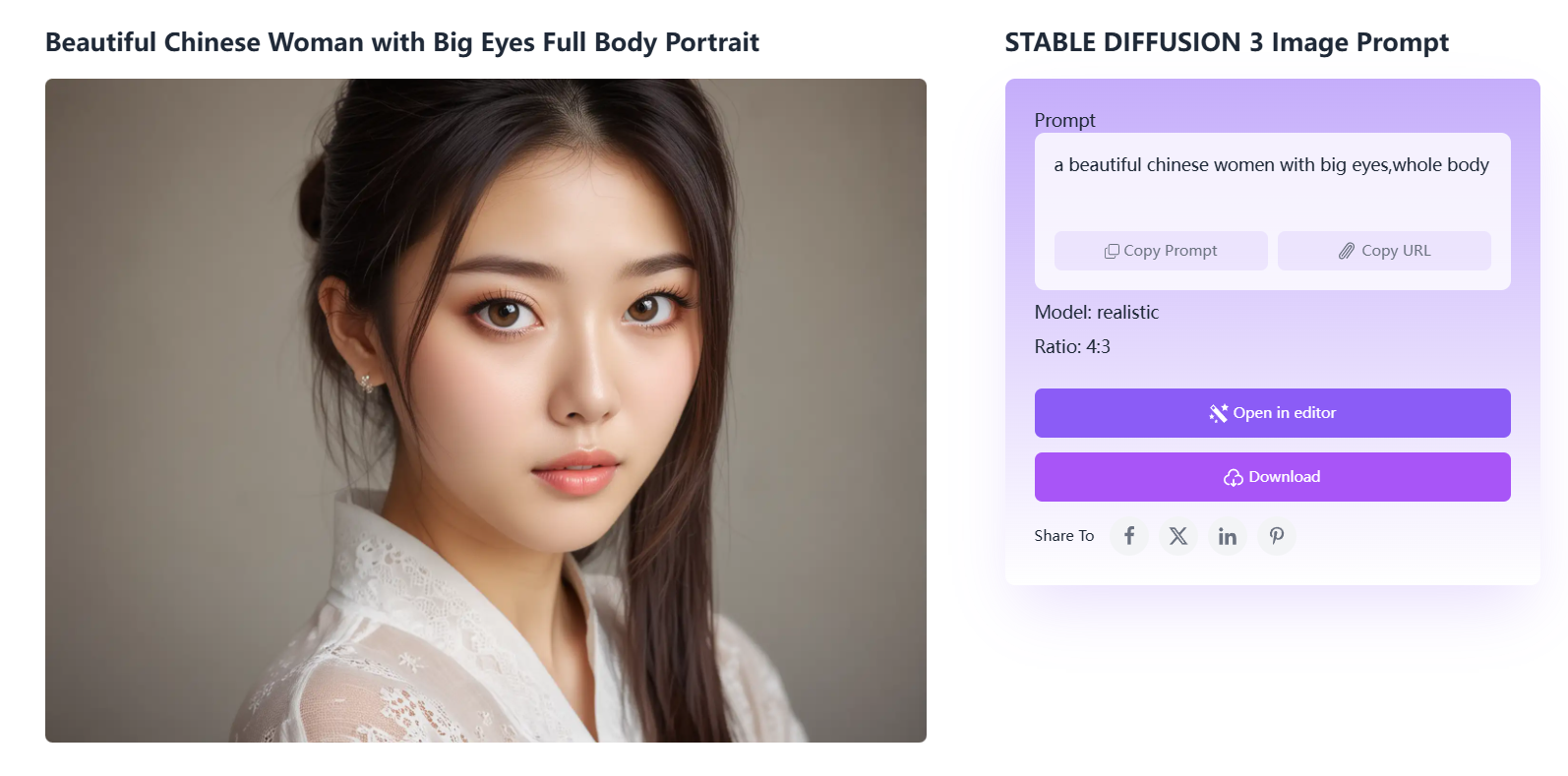
当然用中文作为提示词,也是可以的,效果也很不错
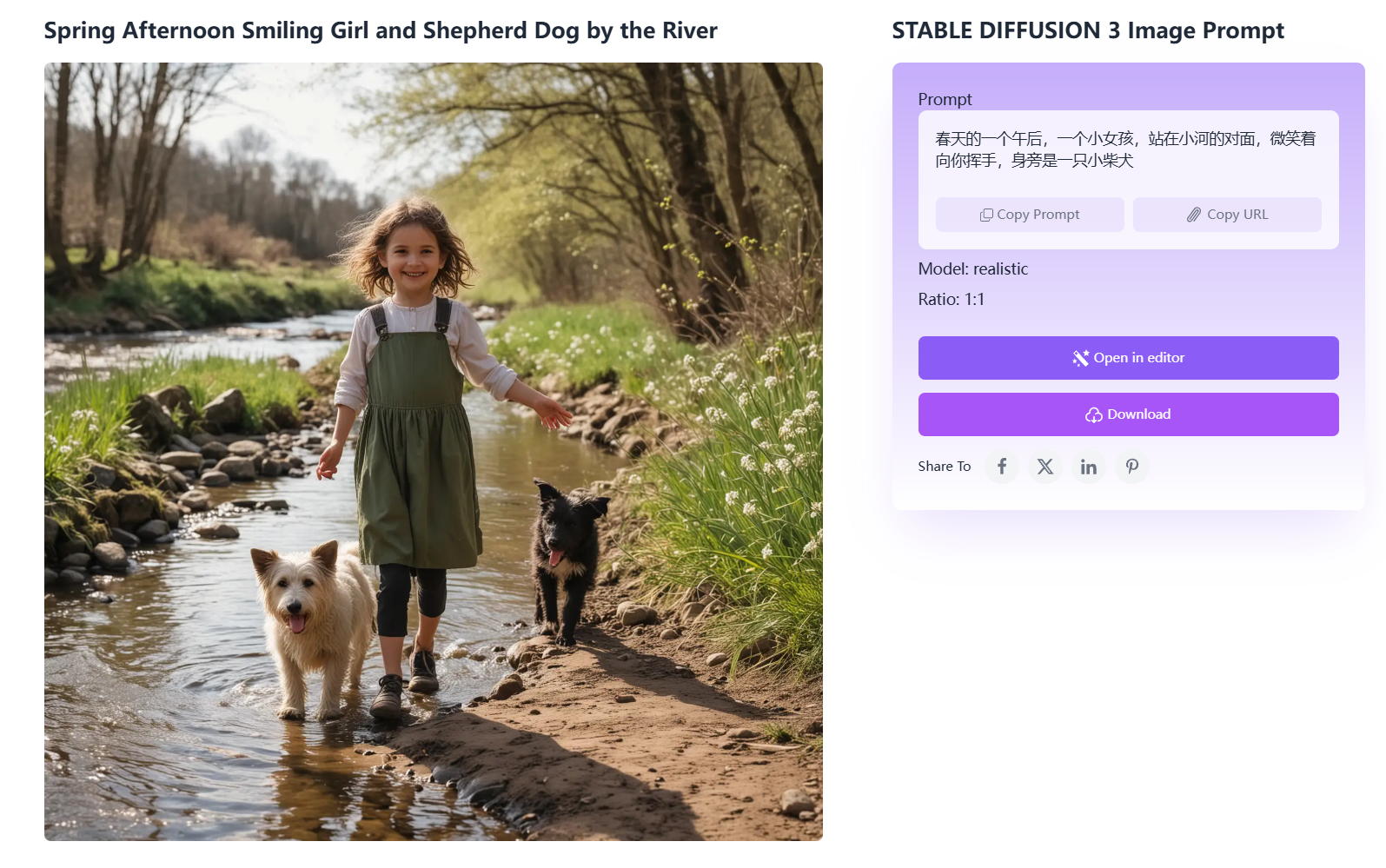
不同的画风和场景:
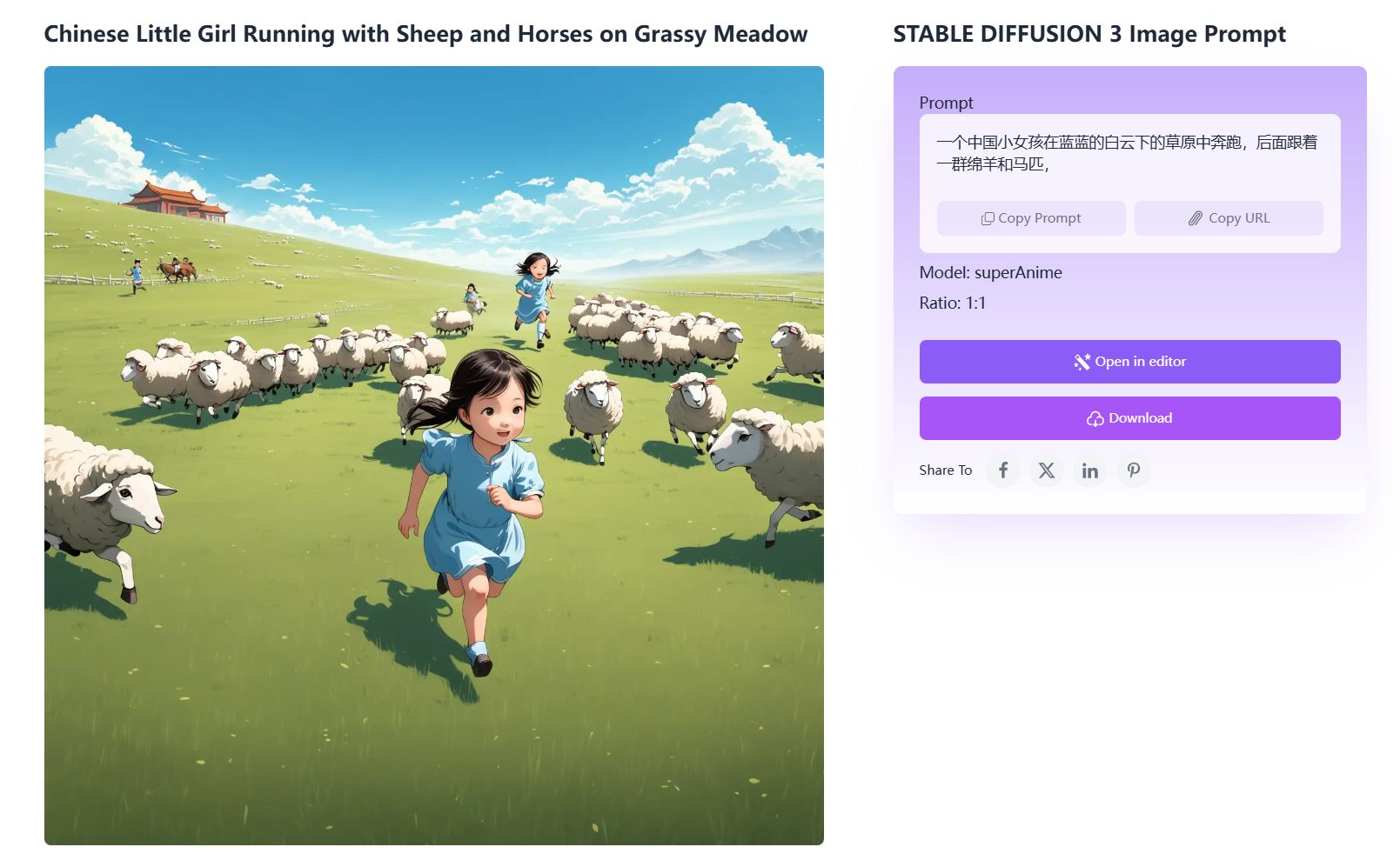
感觉生成图像很接近真实:
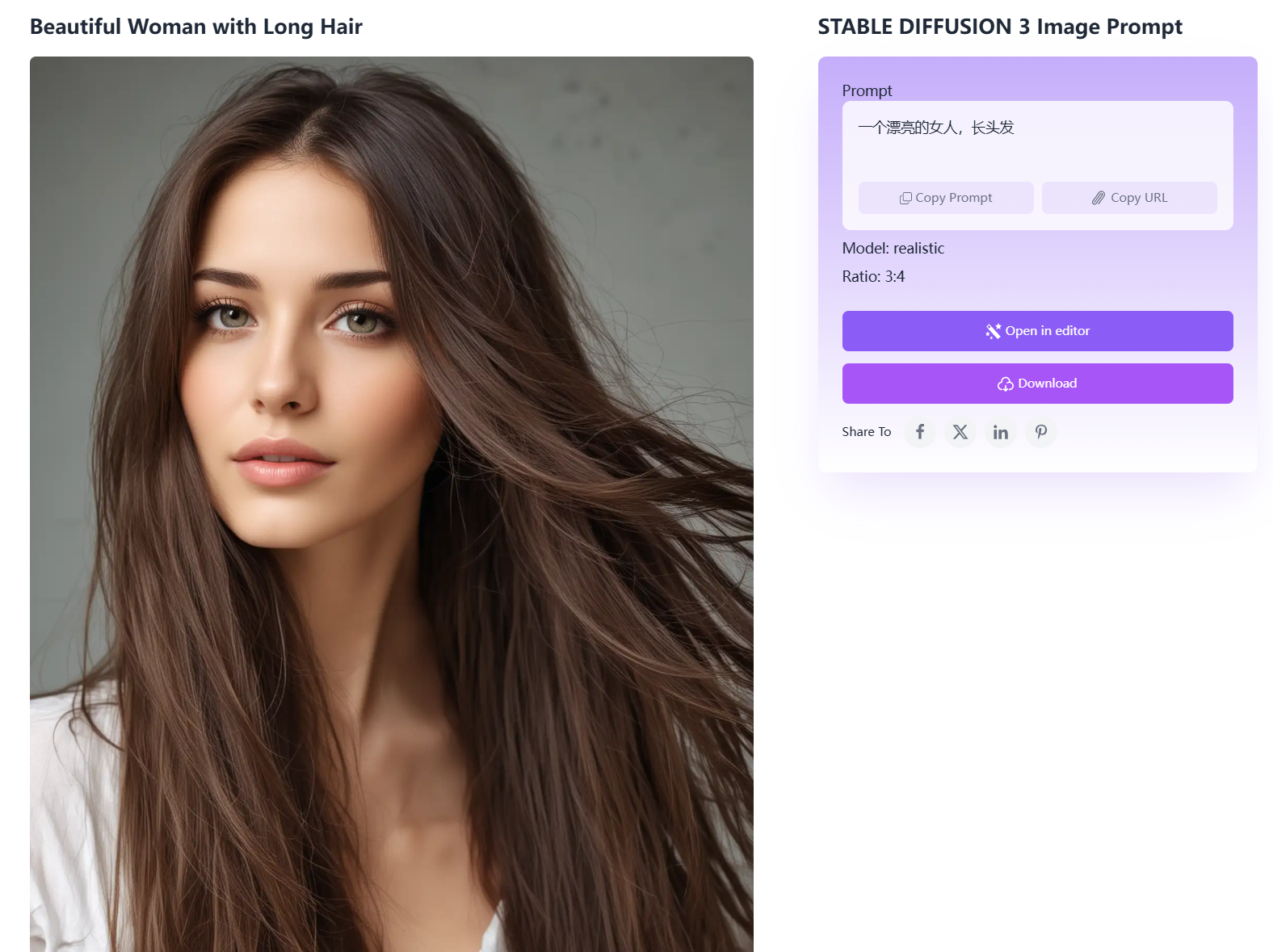
“提示词”描述得更详细,会生成更多细节:
2、Stable Diffusion 3生成图像
思路流程:
- 输入提示词,可以中文或英文
- 选择模型,包括:Realistic 写实、Tamarin 插画风格、Super Anime 超级动漫、visiCanvas 可视画布、Realistic 写实、Anime 动漫、3D Animation 3D动画
- 选择生成图像的数量,默认是1张,可以选择2张或4张
- 选择图像的比例,包括1:1、3:4、4:3
比如,如下图所示,选择了Super Anime模型,同时生成两张图像,图像比例是1:1

3、Stable Diffusion 3原理分析
Stable Diffusion3利用扩散变压器(DiT)架构,结合噪声预测和采样技术,生成高质量图像。
- 该模型使用不同的Stable Diffusion3权重进行图像和语言表示,确保图像内文本生成的精确和连贯。
- Stable Diffusion3提供从800M到8B参数的模型,以满足各种硬件能力和性能需求。
- 利用Stable Diffusion3 API,用户可以输入文本提示,模型将其转换为详细准确的图像,严格遵循提供的描述。
开源地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium
论文地址:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
模型的关键结构,如下图所示:
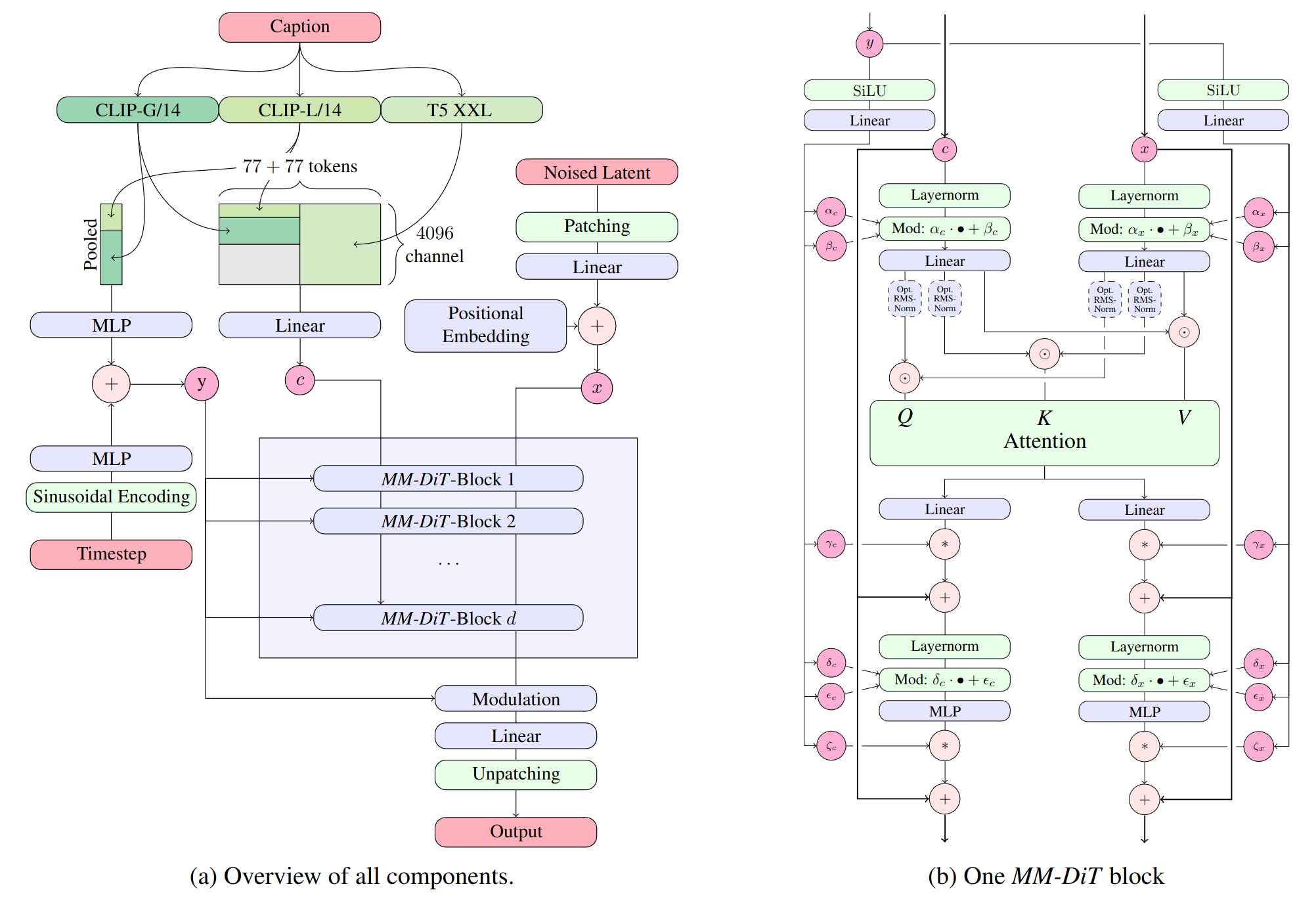
主要包括(a)多模态数据的扩散模型框架的组件、(b)MM-DiT块的细节,
(a)多模态数据的扩散模型框架的组件
-
1、Caption 输入:
- “Caption”是输入的文本描述,用来指导生成的图像内容。
-
2、特征提取模型:
- CLIP-G/14 和 CLIP-L/14:这是两种处理文本和图像的模型,它们将文本和图像转化为向量表示。
- T5 XXL:一个处理文本的模型,把输入的文字转换成向量。
-
3、合并特征:
- 从这些模型中提取的特征被合并在一起,形成一个大的向量,包含了输入信息的多个方面。
-
4、噪声潜在变量(Noised Latent):
- 这是模型生成图像的起点,是一个初始的噪声图像。
-
5、位置编码(Positional Embedding):
- 给输入数据添加位置信息,以便模型知道每个数据的位置。
-
6、MM-DiT 块:
- 这些是模型的核心部分,通过多层处理将噪声图像一步步转换成目标图像。
-
7、输出处理:
- 最后,将处理后的特征向量转换回图像,输出最终的生成图像。
(b)MM-DiT块(Multimodal Diffusion Transformer)
-
1、输入:
- 输入为 y 和 x 两个特征向量。
-
2、SiLU 激活函数和线性层:
- 使用 SiLU(Sigmoid Linear Unit)激活函数和线性层对输入特征进行变换。
-
3、Layernorm 和调制(Modulation):
- 使用 Layernorm 进行层归一化。
- 调制(Modulation)部分通过 α 和 β 参数进行特征调整。
-
4、Attention 机制:
- 采用 Q(Query)、K(Key)、V(Value)三个矩阵进行注意力计算。
-
5、MLP(多层感知器):
- 通过多层感知器对特征进行非线性变换。
-
6、残差连接(Residual Connections):
- 使用残差连接来保持信息的流动,避免梯度消失问题。
这个框架通过融合文本和图像特征,使用扩散模型逐步生成高质量的图像。
关键在于多模态 Transformer 块(MM-DiT block),通过注意力机制和非线性变换对特征进行处理,从而在生成过程中保持了数据的复杂性和一致性。

分享完成~
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Stable Diffusion 3 文本生成图像 在线体验 原理分析

发表评论 取消回复